

高通CEO克里斯蒂亚诺·安蒙。图片经由AI处理
美国当地时间6月25日,高通在纽约举办2026年投资者日活动。
高通宣布了一套面向数据中心AI基础设施的完整路线图,发布Dragonfly C1000 CPU、AI300推理加速器和高带宽计算(HBC)技术,同时公布了与Meta的多代合作、与Hugging Face的深化合作,以及对AI软件公司Modular的收购。
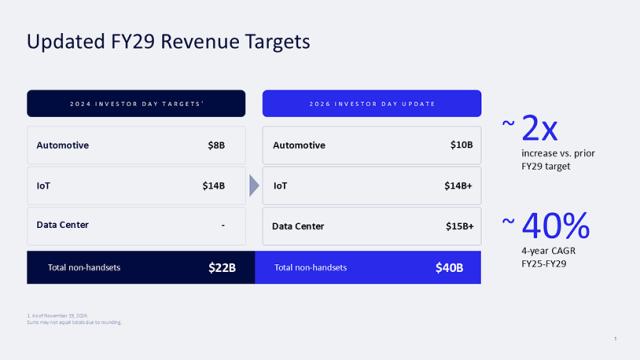
高通公布的2029财年非手机业务营收目标
财务方面,高通把2029财年的非手机业务收入目标上调到400亿美元,几乎是此前长期目标的两倍。其中,数据中心业务在该财年的营收将超过150亿美元。
盘后交易中,高通股价一度上涨16%。
01、数据中心营收要超150亿美元
高通CFO阿卡什·帕尔希瓦拉在活动中预测,2027财年,高通数据中心业务将产生“数十亿”美元收入。而到2029财年,该业务年收入将超过150亿美元。
从公司整体收入结构来看,到2029财年,QCT(半导体)部门的非手机业务收入将达到400亿美元,而2024年给这个数字定下的长期目标是220亿美元。
2029财年,高通手机业务将只占QCT收入的三分之一左右。
剩下的部分由几个增长引擎分担:汽车业务营收100亿美元,物联网业务超过140亿美元。其中,物联网业务包含工业、网络和机器人(80亿美元),以及个人AI和计算(60亿美元)。
利润端的指引同样进行了上调。
分析师对高通2029财年调整后每股收益的平均预期是15.26美元,而高通自己给出的目标超过18美元,这个差距是股价在盘后跳涨的直接原因。
CEO克里斯蒂亚诺·安蒙解释增长逻辑时,把焦点放在了AI使用方式的变化上。他认为AI正在从简单问答转向智能体应用,也就是能自主执行多步骤任务的模型。这类工作负载对低功耗计算的需求更大,而高通在移动芯片上积累的正是这方面的能力。
安蒙还称,AI计算正在进入汽车、日常电子设备和机器人,这些领域的芯片需求将持续“打开”。
02、Dragonfly C1000亮相,Meta成为首个客户
硬件发布的重头戏是Dragonfly C1000,一款高通为数据中心专门设计的CPU。

Dragonfly C1000基于定制设计的Oryon核心,采用多芯粒(Chiplet)架构,集成超过250个核心,运行频率在5GHz以上。高通给出的性能测试显示,其每瓦性能比现有服务器CPU竞品基准高出两倍以上。
Dragonfly C1000支持PCIe Gen 7和CXL连接,内存系统使用低功耗内存技术,内置ECC、故障隔离和错误恢复等RAS功能。散热方案同时兼容风冷和液冷,机架符合OCP ORv3标准。
搭载Dragonfly C1000的机架配置也一并公布:配备43TB DRAM,预计2026财年出样。
高通为这款CPU规划了三个细分方向:
第一类是智能体CPU,面向高吞吐量的智能体编排和低延迟的交互式AI任务。
第二类是通用CPU,兼顾两种需求:运行第一方工作负载时,追求最优的TCO(总拥有成本)性能;面向第三方弹性使用时,追求最优的vCPU(虚拟中央处理器)性能。
第三类是AI头节点CPU,作用是以低开销完成主机处理,让XPU在生成式AI计算中尽可能跑满。
真正让Dragonfly C1000有了分量的,是Meta的站台。
高通宣布双方签订了一份“多年期、多代际”协议,Meta将把Dragonfly C1000用于下一代服务器集群,芯片计划在2028年下半年量产。后续迭代的CPU也在合作范围之内。
高通CFO帕尔希瓦拉表示,通过手机芯片和其他已有产品,高通已经跟几乎所有超大规模企业都有业务往来,“这不是新建立的关系。”这句话意味着Meta大概率不是唯一的谈判对象,更多客户可能还在接洽中。
针对外界“高通入局数据中心是否太晚”的疑问,高通CEO安蒙的回应是:“当人们问现在进入数据中心是否太晚时,你应该想想规模和执行能力、工程能力,或者运营和供应链。”
他的意思是,高通在手机时代积累的大规模系统工程能力,在这个市场依然有效。
03、AI加速器加上HBC,要拆“内存墙”
CPU之外,高通也更新了AI加速器的路线图。
继此前发布的AI200和AI250之后,AI300推理加速器在本次投资者日亮相,三款产品按年度节奏迭代。

这套平台的核心逻辑是“解耦式机架级AI推理”。高通的数据中心业务执行副总裁兼总经理Tony Pialis解释说,智能体工作负载需要CPU、AI加速器和连接技术协同,而不是靠单一芯片完成。高通现在做的事,是把计算、AI、内存和连接整合到一个统一的机架级平台里。
在这个平台里,内存问题是绕不过去的一环,而高通拿出的方案就是高带宽计算(HBC)。
这是一项用来打破“内存墙”的技术。所谓内存墙,指的是AI计算中数据在处理器和内存之间搬运的带宽瓶颈。HBC的做法是通过3D堆叠硅技术,把计算单元和内存紧密集成在一起,走的是近存计算路线。
高通给出了几组数据来说明HBC的潜力。
搭载HBC Gen 1的AI250,每卡有效内存带宽达到133 TB/s,比采用LPDDR5X的AI200提升了18倍。采用HBC Gen 2的AI300,带宽相比AI200的提升幅度将达到54倍。
与当前主流的HBM(高带宽内存)相比,HBC在同等功耗下的带宽是其6倍。而与SRAM(静态随机存取存储器)相比,HBC在同等功耗下的容量是其200倍。
换言之,HBC单位功耗能处理的数据量大幅提高,对数据中心的总拥有成本(TCO)有直接影响。 AI250的商业样品预计2027年中期提供,AI300的商业样品则要等到2028年。
连接产品是高通的老本行,这次也没有缺席。该公司提供从Die-to-Die、铜缆、光纤到园区级的互连方案,支持800G和1.6T速率,覆盖数据中心内部到最长20公里的场景。
超过35家技术生态企业公开表达了对这套路线图的支持,名单里包括超微、联想、SK海力士、美光、三星SDS和Arista等。
04、收购Modular,联手Hugging Face
硬件之外,高通在软件生态上也有密集动作。
首先是收购AI软件公司Modular。收购对价是大约39亿美元的高通股票,预计2026年下半年完成交割,还需获得监管批准。
Modular的核心产品是一个开放、AI原生的软件堆栈,可以让模型在CPU、GPU、NPU和定制ASIC等不同芯片架构上运行,开发者不需要为每一种硬件重写代码。Modular由克里斯·拉特纳(Chris Lattner)等人联合创办,其平台在业内被看作英伟达CUDA之外的一个开放性选项。
安蒙评价这次收购时表示,智能体在数据中心和边缘扩展后,行业需要一个更开放、更现代的软件基础。高通希望通过这次收购,给客户在多样化计算环境中提供真正的部署选择。
其次是与Hugging Face扩大合作。合作内容分三块:
* 将Hugging Face的内部和开发者工作负载引入由高通Dragonfly驱动的数据中心;
* Hugging Face平台上超过300万个开放模型,能够直接加载到搭载高通平台的设备和数据中心机架上,简化开发者从实验到部署的流程;
* 开发“Hugging Face Agent”,用于在设备端和云端的混合环境中编排AI工作负载,根据性能、成本和延迟的需要动态分配任务。
Hugging Face联合创始人兼CEO克莱门特·德朗格(Clément Delangue)解释说:“我们正在让我们的1600万开发者能够轻松地在任何地方运行开放模型,从你手中的设备到数据中心的完整机架。”
双方合作还有一个具体安排。Hugging Face将向使用高通平台设备或云系统的客户,提供Hugging Face PRO的访问权限,包含高级存储、计算和协作功能。
这一步降低了开发者用开放模型做应用的门槛。
05、汽车、机器人、中国
在数据中心这条主线之外,高通也更新了其他业务的进展数据。
汽车业务方面,“汽车设计中标项目储备”已扩大到650亿美元,高通把2029财年的收入目标提高到100亿美元。汽车芯片的需求背后是ADAS和自动驾驶的持续渗透。
物联网业务拆得更细了。工业、网络和机器人单独分列,目标收入80亿美元;个人AI和计算目标60亿美元。高通判断,智能体将触发智能连接设备的新一轮升级周期。公司估计,到2030年这些业务的总体规模将达到1.7万亿美元。
关于中国市场,安蒙在活动中做了简短回应。美国政府目前有向中国出口AI相关硬件的规定,但他表示高通会有不触发出口限制的数据中心芯片版本。他没有展开讲具体方案,但这个表态说明中国市场的机会没有被搁置。
综合来看,高通这次投资者日释放的信号比较完整。从C1000到HBC,从收购Modular到与Hugging Face合作,从150亿美元数据中心目标到18美元每股收益,都是可验证的节点。客户有了,产品有样品时间表了,财务模型也给出了。
接下来几个季度的财报,会是对高通这些路线图的第一轮检验。


