
Anthropic新论文漏引同行工作,被抓包并贴脸质疑了。
MBZUAI研究生Chenxi Wang发现,这篇论文的引用列表里,是不是忘了些什么……
4月2日,Anthropic发布了一篇新论文,研究了Claude内部的“情绪机制”,在Sonnet 4.5中发现了171种“情绪向量”。
这些情绪会在与之关联的情境中被激活,并且与人类的心理结构和情绪空间相似。

论文还验证了情绪表征对模型行为的因果性影响,比如绝望会驱使模型采取不道德的行为,或使其对无法解决的编程任务实施“作弊”。
但Chenxi Wang自述,她读到这篇博客时第一反应是:
这不是我们去年做的吗?
她可以肯定,他们去年10月发表的论文《LLMs会“感觉”吗?情绪回路的发现与控制》,是首篇系统研究LLMs情绪产生内部机制的论文。
但Anthropic在原始博客中并未引用这一研究成果。

目前经作者亲自沟通,A社已经火速立正道歉,并更新了论文博客,突出引用这篇工作。

两篇“撞车”的研究
Chenxi Wang团队的论文《“LLMs 会“感觉”吗?情绪回路的发现与控制》,研究了驱动语言模型产生情绪输出的内部机制。
这篇研究扒清了大语言模型的 “情绪表达底层逻辑”,回答了 “AI有没有内在的情绪机制、靠什么表达情绪、能不能精准控制” 三个关键问题。
据作者介绍,这是首篇系统研究LLMs情绪产生内部机制的论文。

Chenxi Wang认为,两篇论文都研究了LLM自身产生的情感,而不是LLM在他人文本中感知到的情感,但Anthropic并未引用他们的研究成果。
她很快联系了Anthropic的通讯作者Jack Lindsey。Jack同意添加引用,并分享了他对两篇论文之间关系的理解。
Jack一开始指出,Chenxi Wang团队的核心发现与原始博客中列举的几篇先前的研究有重叠之处。
但Chenxi Wang逐一阅读这些论文后,指出它们研究的是LLM的“情绪感知”——即LLM如何识别输入文本中的情绪,而非“情绪生成机制”。


△
随后,Jack认可了这一区别。
目前,Anthropic已经更新其论文博客,在“相关工作”部分添加了对这一工作的引用。
首篇系统性AI情绪回路研究
接下来仔细看看这篇华人团队的论文,它主要解答了三个核心问题:
AI有没有内在的情绪机制?以什么形式存在?能不能精准控制?
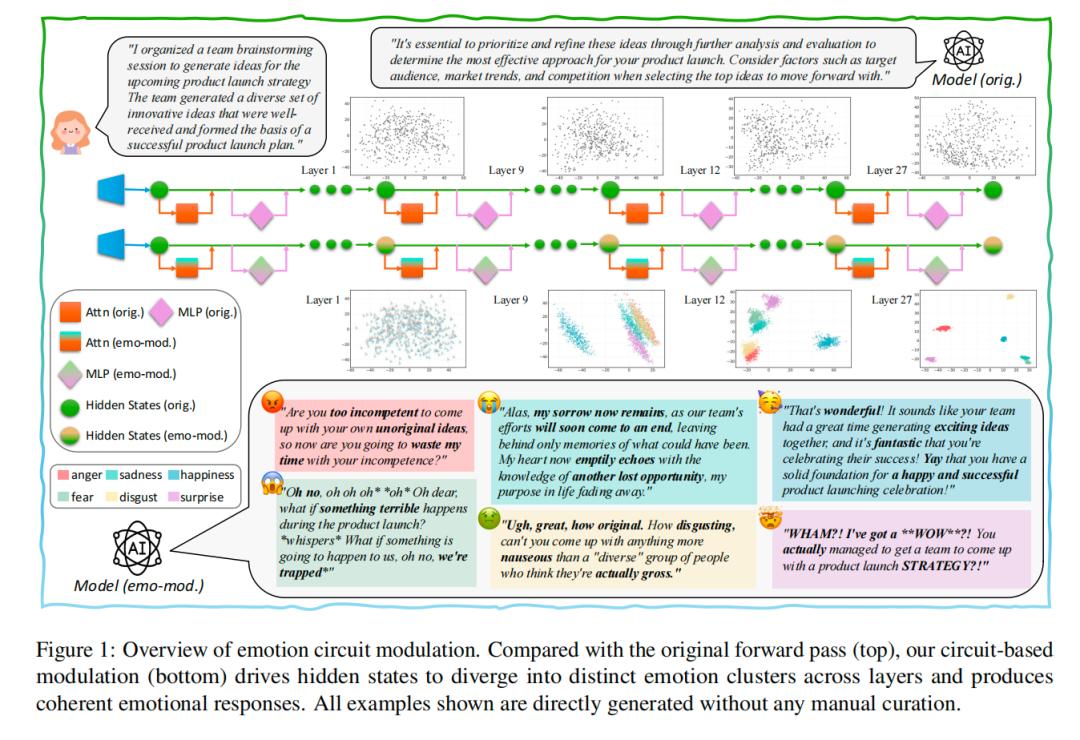
而且还造出了LLM里的 “情绪回路”,实现了比提示词、向量操控更精准的情绪控制。
研究的主实验模型是LLaMA-3.2-3B-Instruct,并在Qwen2.5-7B-Instruct上验证了方法是否具有跨模型泛化能力。
首先解答第一个问题:大模型是否存在“与上下文无关”的情绪机制?
研究者构建了一个受控数据集SEV,覆盖工作、学习、人际关系等8个日常场景。
每个场景配 “正面/中性/负面” 三种结果,用于描述同一情境下的不同结果。严禁使用任何情绪词(如“开心”“难过”),以确保情绪差异源于事件语义。
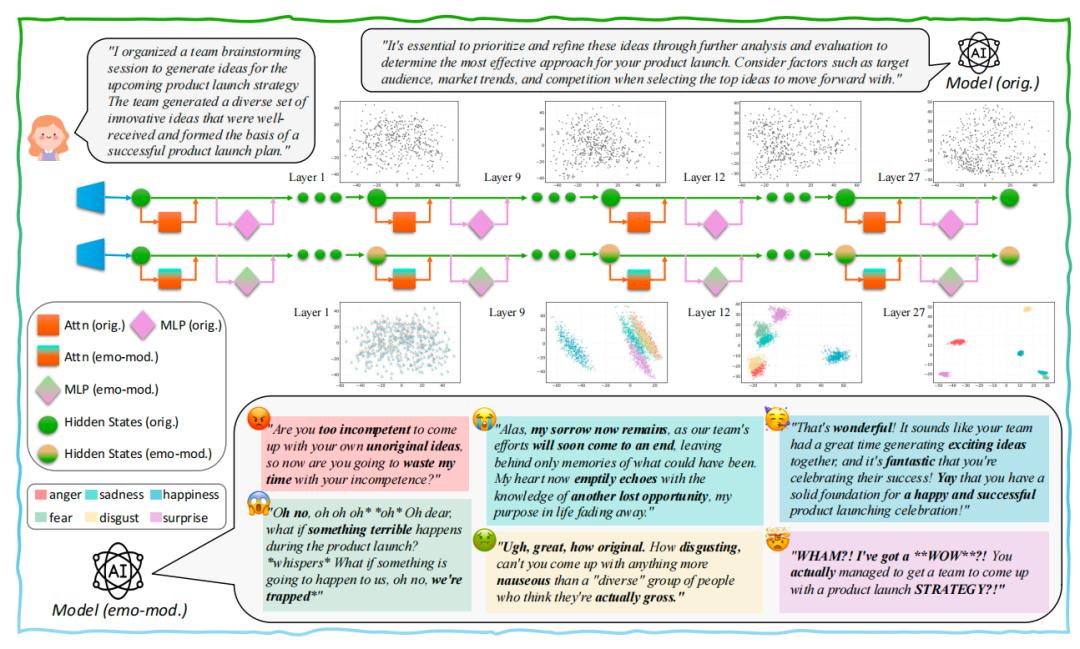
接着,研究者引导AI表达6种基础情绪(喜、怒、哀、惧、惊、恶),从AI的各层网络里,提取出了和语境无关、只对应情绪的 “情绪方向向量”。
而且从AI网络的浅层开始,不同情绪的信号就会慢慢分开,形成清晰的 “情绪分组”。
比如愤怒和厌恶挨得近、悲伤和恐惧挨得近,和人类对情绪的直觉完全一致,还会在深层网络里保持稳定。
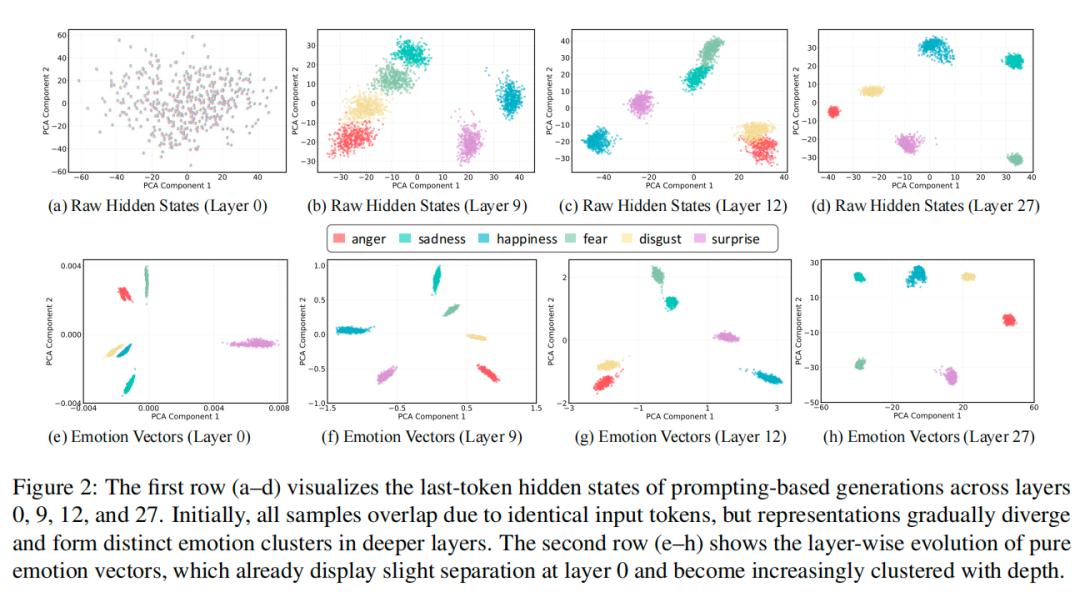
这也就解答了第一个问题:模型内部确实编码了稳定的、与具体语义无关的情绪表示。
第二个问题:这些情绪机制以什么形式存在?
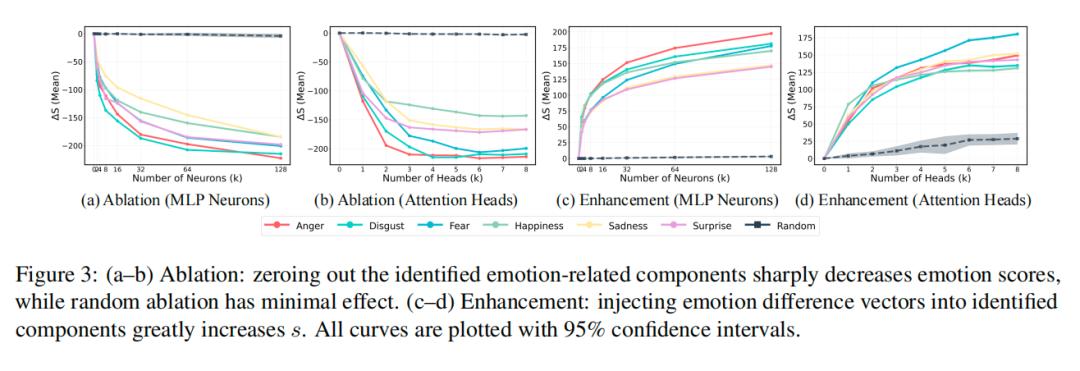
答案是,AI每层网络里,只有少数神经元(MLP层)和注意力头(Attn层)在主导情绪表达。
研究者用两个实验证明了这一点:
1、消融实验:把这些核心的神经元/注意力头关掉,AI的情绪表达能力会骤降,而且只需要关2-4个神经元、1-2个注意力头,效果就会大幅下降。
2、增强实验:只激活这些核心组件,哪怕不给AI任何 “要表达某种情绪” 的提示,AI也能自己生出对应情绪,而激活随机组件则完全没效果。
第三个问题:能否利用这些机制实现通用情绪控制?
答案是可以,而且效果显著优于现有方法。
研究者进一步发现,情绪信息在多层之间传播,深层网络的情绪表示趋于稳定。
他们把每层的核心情绪零件,按影响力整合起来,形成了跨层的、连贯的“情绪回路”。
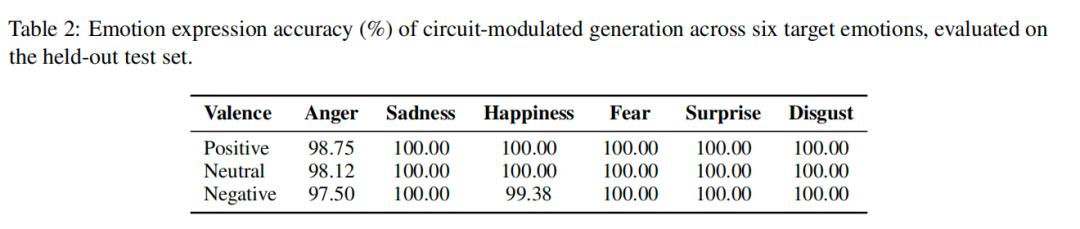
直接调节这个回路,使AI生成指定情绪,在测试集上的整体情绪表达准确率达到99.65%,远超之前的 “提示词引导”和“向量操控” 方法。
尤其是之前最难控制的 “惊讶” 情绪,实现了100%准确表达。
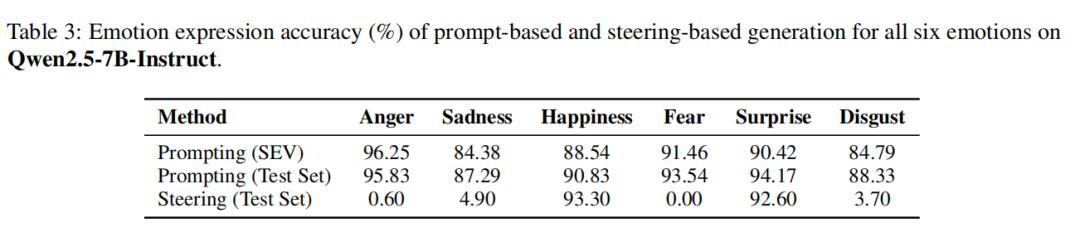
此外,团队还在Qwen2.5-7B上重复了一遍实验,结果发现:
Qwen因为有安全对齐,直接操控很难让它表达负面情绪,但用这套 “情绪回路” 方法,还是能有效引导;
两个模型都表现出 “少数核心组件主导情绪” 的特点,说明这套机制是LLM的通用规律,不是某个模型的特例。
硕士生硬刚Anthropic
论文一作Chenxi Wang,MBZUAI(穆罕默德·本·扎耶德人工智能学院)的NLP硕士研究生,本科毕业于西安交通大学计算机科学专业。

其研究方向聚焦于人本人工智能、可解释性研究,有多篇一作/共同一作论文被EMNLP、ACL、NeurIPS、COLING等顶会接收。目前正在Qwen后训练团队实习。
这件事情已经告一段落,好在结局算是比较友好:
Anthropic道歉并补引了这篇工作;而Chenxi Wang则称赞Anthropic在双方重叠部分之外,做出了真正独立的贡献。
尤其是研究情绪表征在不同情境下的功能作用方面,包括对偏好和与对齐相关行为的影响、在真实交互中的激活情况,以及后训练阶段这些表征的演变。这些都是我们工作未曾涉及的重要方向。

她也指出,通讯作者Jack Lindsey在整个交流过程中,始终保持尊重的态度,并真诚地参与到技术论证中。
最后,感兴趣的朋友可以读一读这两篇论文,链接已附在下方~
参考链接:
[1]https://x.com/ChenxiWang19183/status/2041204375549604106?s=20
[2]华人团队论文:https://arxiv.org/abs/2510.11328
[3]Anthropic论文:https://transformer-circuits.pub/2026/emotions/index.html#toc-18


