
智驾行业最近又吵了起来。
这两天,在上汽大众的ID. ERA技术发布会上,Momenta CEO曹旭东正式宣布他们的Momenta R7强化学习世界模型即将推出,并会全球首发搭载于上汽大众全新旗舰SUV ID.ERA 9X。
继去年推出基于强化学习的一段式端到端大模型后,曹旭东在新一代模型的打造上选择了世界模型+强化学习的路线,就此世界模型路线除了华为乾崑为代表的玩家之外,又加一员。
与此同时,理想汽车在这两天的GTC大会上发布了他们的新一代自动驾驶基座模型MindVLA-o1。

按照理想基座模型负责人詹锟的介绍,该基座模型通过六大技术创新,构建了面向物理世界智能的自动驾驶基础模型,从而让自动驾驶看得更远、想得更深、行得更稳、进化更快、部署更高效。
这一两年,理想在智驾技术上的迭代一直保持着很快的速度。从2024年推出端到端+VLM双系统模型,再到去年将空间理解、语言理解与行动决策统一到同一模型框架——VLA司机大模型,再到今年的MindVLA-o1,可以说保持着一年一代模型的迭代效率。
同是VLA阵营的小鹏汽车,在前不久他们的第二代VLA正式发布并开启量产上车,距离他们推出第二代VLA仅过去了4个月,相比于传统VLA架构他们率先提出了去掉两次显性转译过程的新VLA架构。
随着这两年理想、小鹏和元戎等玩家把自身的算法架构从端到端逐渐演变为VLA模型架构;与此同时,也有华为乾崑等玩家选择了更注重对于现实世界理解的世界模型架构。
就此,整个智驾行业就开始争论VLA和世界模型的孰优孰劣,两个阵营的拥趸都认为自己坚持的路线会成为智驾行业的终局。毕竟在理论上,这两条路线都有各自的短板。
再加上Momenta押注世界模型,理想、小鹏和元戎启行加速优化VLA模型的当下,让这样的争论变得更加热闹。但在飞说智行看来VLA和世界模型这两条技术路线本身或许并不对立。
1、只有分工不同,没有绝对对立
传统VLA存在着明显的挑战。
首先是理解3D空间环境、语言思考和推理输出具体驾驶行为轨迹这三件事的对齐效率不高;再则是还存在长尾场景的问题;最后是VLA模型往往包含着LLM的能力,由此会带来较高的计算和内存成本。
为了解决这些问题,理想他们提出了MindVLA-o1。该模型是一个原生多模态的MoE Transformer。这就意味着,该模型具备了视觉、语言和行动等多模态统一训练和对齐,以及较强泛化的能力。
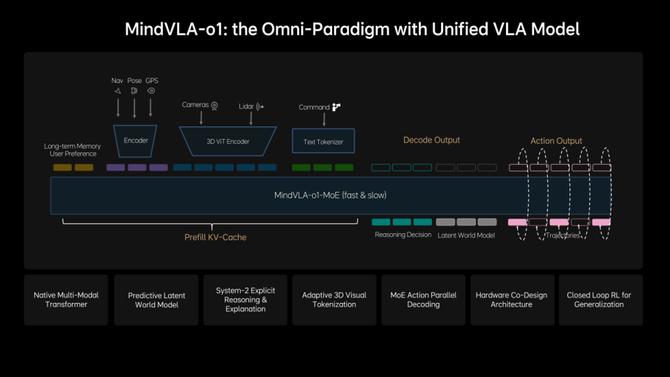
其中在感知上他们引入了3D ViT Encoder,就能更早地融合LiDAR数据和视觉数据,在编码阶段直接构建3D空间表示,使模型更自然理解现实世界的物理空间结构。
并且,他们还引入了前馈式的3DGS表示(Feedforward 3D Representation),来提升模型对环境的理解。
对于高阶智能驾驶乃至自动驾驶,仅能理解当前环境是不够的,还需要做到对世界的预测。行业基本会想到用几十B参数量的世界模型来做,但这样规模量的模型又很难在车端运行,随之无法让车端得到“预测”的能力。
对此,理想他们在引入"下一帧预测(Next-state prediction)"作为训练过程中的自监督信号和为多模态推理保留语言能力的同时,还采用了预测式隐世界模型(Predictive Latent World Model)。
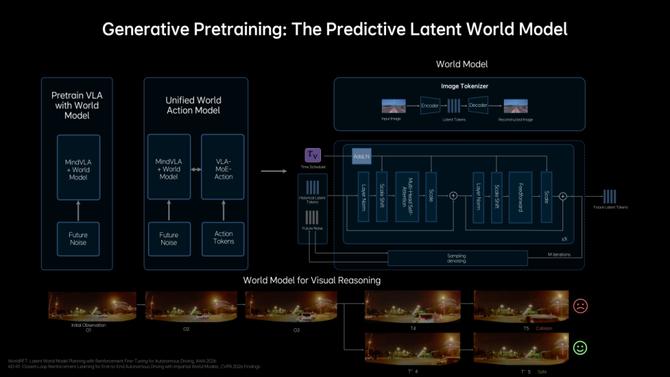
所谓预测式隐世界模型,简言之就是被极度压缩的世界模型,其内不是真实世界的图像或点云,而是经过编码之后的抽象向量。
训练时,应该是先把多模态感知数据进行压缩表示,然后在隐空间里理解当下并对未来环境变化的进行推演,最后再把结果用于模型内算法预测和驾驶决策的联合训练。相比于用真实数据层面的预测要快得多,算力消耗上也会更少。
结果是算法模型拥有了“想象”的能力,也就是詹锟口中的“多模态思考(Generative Multimodal Thinking)”能力,同时计算成本也被压缩到了车端算力能支撑实时调用的级别。
为了把车端思考和想象的信息生成最后的驾驶轨迹,理想他们设计了 Unified Action Generation(统一动作生成)模块,该模块主要由三大能力组成:
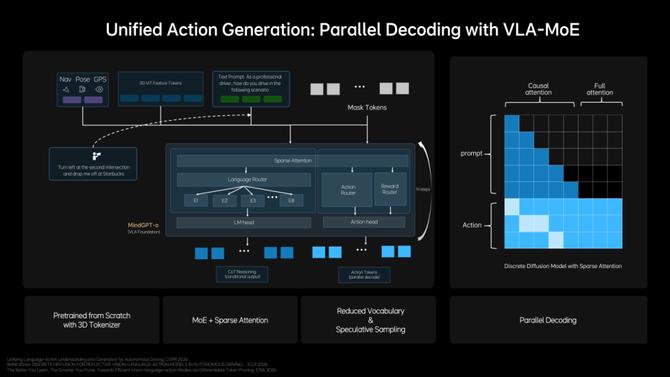
首先采用了混合专家模型(VLA-MoE),其中专门引入了Action Expert(动作专家),专注于生成高精度的驾驶轨迹;其次,采用了Parallel Decoding(并行解码),可以让所有的轨迹点并行生成,这对于长时间序列轨迹预测十分重要。
为了保证并行生成轨迹的质量,他们还引入了Discrete Diffusion的扩散优化方式,让模型通过多轮迭代不断对轨迹进行优化,最终得到空间上连续、在时间上稳定,同时满足车辆动力学约束的轨迹。
面对复杂交通环境,轨迹生成既要快、又要稳定、还得覆盖不同的决策路径,在此之前要满足以上三大要求比较困难,但现在理想给出了一套组合的解法。
模型搭建好了,接下来是数据去哪里找的问题。
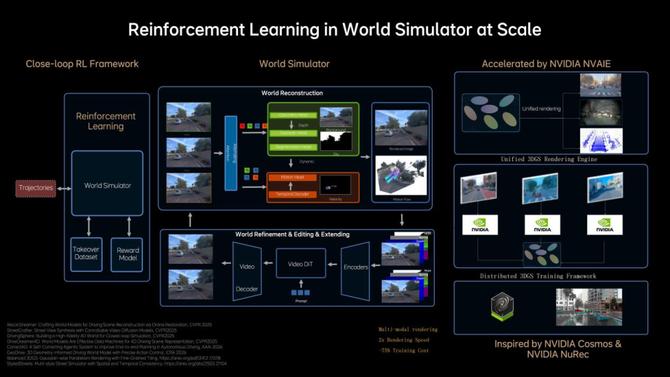
前些年智驾算法的训练大多依靠于人类驾驶真实数据,但这些数据无法覆盖所有的长尾场景(Corner cases)。
于是,理想构建了一个可扩展的世界模拟器,把传统的逐步优化式重建升级为前馈生成(Feed-forward)的场景重建方式,能使模型瞬时生成大规模、高保真的驾驶场景,从而支持大规模并行训练。
同时,他们还将这种前馈式场景生成与生成式模型结合,使模拟环境不仅可以重建真实场景,还可以进行扩展、编辑和生成新的场景。
这个可扩展的世界模拟器是处于一个闭环强化学习(Closed-loop RL)框架中。这意味着,模型不仅可以基于真实数据训练,还能在世界模拟器中遇到现实中很难遇见的场景,然后在其中探索、优化和迭代,从而让解决长尾问题接近穷尽。
为了如何让模型上车,理想他们采用了一套叫做Roofline的分析框架,在模型精度与推理延迟之间建立精确的映射关系,通过测试了大约2000种不同的模型配置,并在NVIDIA Drive Orin与Thor平台上进行了验证,最终找到了在精度和延迟之间的最优平衡点。
按照詹锟介绍,基于这一套软硬件协同设计方法,他们将模型架构探索的时间从数月缩短到了几天,这大大提升了端侧VLA模型的设计效率与部署速度。
通过上述分析,能看到理想MindVLA-o1模型架构,基本解决了传统VLA模型存在的挑战。而MindVLA-o1再加上VLA数据引擎MindData、多模态世界模型MindSim和强化学习模块RL Infra,则构成了理想面向物理世界智能的基座模型全景图。
值得注意的是,在理想基座模型架构中,同时囊括了世界模型和VLA架构,这两个模型在整个框架中各有分工和协作融合。而像这样的案例,还有很多。
在去年11月的ICCV大会上,特斯拉自动驾驶副总裁阿肖克·埃鲁斯瓦米(Ashok Elluswamy)分享了特斯拉算法架构的最新进展,不仅采用了3D高斯特征和思维链COT等技术来提升数据质量和模型可解释性,同时还建立了名为“神经世界模拟器”的闭环仿真系统。
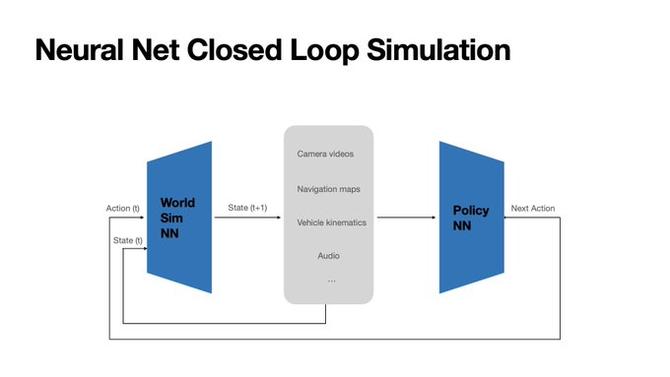
特斯拉闭环模拟神经网络模型,图源Tesla AI
能看到在特斯拉目前的算法研发体系中,也把VLA模型和世界模型同时纳入其中。飞说智行曾在《深度 | 特斯拉已不是智驾行业“标准答案”》一文中对此进行过阐述,不再赘述。
另外,无论是小鹏已经开始量产上车的第二代VLA模型,还是元戎在这两天GTC上透露的VLA基座模型,都需要世界模型提供的大规模仿真训练、场景数据生成、以及驾驶行为预测推演等数据闭环能力作为支撑。
而以上这些玩家会这样融合VLA和世界模型两大技术路线,来打造自身的算法基座模型,也是为了更大的目标做准备。
2、物理AI,自动驾驶只是起点
研发智能驾驶或者自动驾驶,行业的目标是一致的——如何为机器构建一个可以在真实世界中运行的“数字大脑”?
就拿我们开车来说,经过驾校的系统性学习以及长时间的驾驶实践后,就能在几百毫秒内对于眼前看到的交通场景做出判断并且驾驶车辆做出安全的避险动作,对于“老司机”来说,这样的能力更是已形成肌肉记忆。
相较之下,随着智能辅助驾驶的逐渐普及,目前已从“能用”阶段无限接近“好用”的阶段,但相较于真正的“爱用”、以及达到人类老司机的水平还有很多路要走。
而就在最近的GTC上,理想他们在打造“数字大脑”的征程中有了一些进展。
借用上述提到的理想面向物理世界智能的基座模型,从视觉感知到世界理解和推理,到行动决策,再到强化学习持续优化,以及最终的系统效率和硬件协同。在詹锟看来,很像动物的大脑。
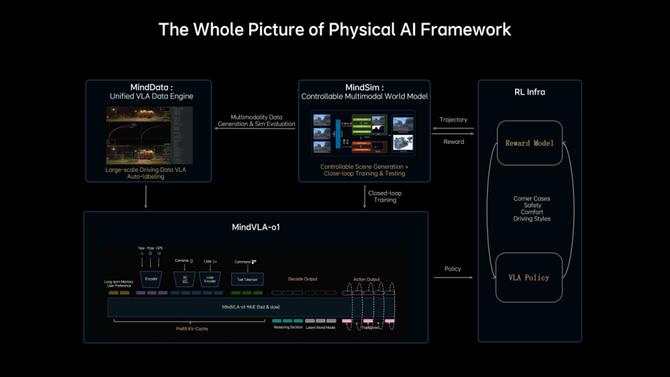
理想汽车物理AI框架全景图
视觉信息首先进入视觉皮层,然后在前额叶进行推理和规划,再由运动皮层生成具体动作,通过多巴胺系统进行强化学习,最终通过高效的神经系统指导肌肉完成动作,同样是一个闭环。
这套“数字大脑”的能力应该已经被应用到理想的智能辅助驾驶中。就像给理想的车一个指令“帮我把车停到前面那辆橘色车旁边。”就能看到车上的系统可以很快理解环境语义,并生成对应的驾驶轨迹去完成这个任务。
通过詹锟的演示,基于同样的基座模型,他们也让机器人完成了拿起瓶子,往桌面上杯子中倒养乐多的任务。换句话说,同一套基座模型,不仅可以控制车辆,也可以控制机器人。
有这样相同策略的,还有小鹏和特斯拉。
按照小鹏汽车CEO何小鹏的计划,要用第二代VLA不仅打通L2智能辅助驾驶到L4自动驾驶的路径,还要将其应用到机器人和飞行汽车的研发中。
因为在他看来,除了自动驾驶,机器人和飞行汽车同样属于物理AI,要从算法层面打通这些物理AI,则需要基座模型以及一整套AI基础设施支撑。

由此,在今年初小鹏将自动驾驶中心、智能座舱中心合并为通用智能中心,这个新中心由原自动驾驶负责人刘先明主导。该中心被何小鹏视为一个面向汽车+机器人的全新AI组织。
而对于特斯拉来说,传出他们的人形机器人和FSD在算法层面已经打通的消息,早在2023年就已经开始。
而在最近,硅谷人工智能专家Phil Beisel在《The AI Merge That Changes Everything for Tesla 》一个访谈中,介绍了特斯拉在自动驾驶和具身智能技术相通性的底层逻辑。
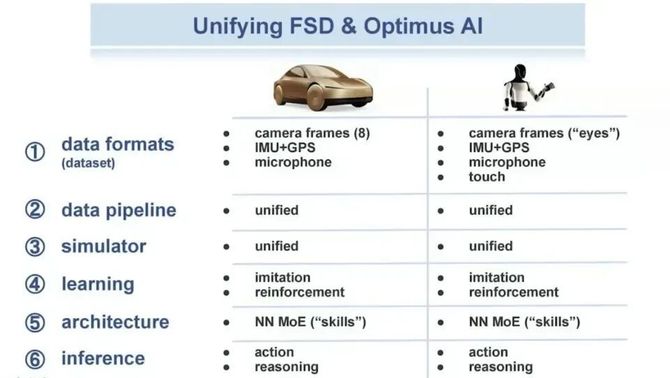
图源Phil Beisel X平台
特斯拉在一开始就考虑到了FSD和Optimus采用相同的相机视觉信息,然后两者都会走数据采集到处理,再到训练的一整套流程。为此,特斯拉为FSD和机器人搭建了同一套神经网络架构,采用了当前主流的MoE架构。
无论机器人还是自动驾驶,都会涉及到数据的传输,因此对于硬件数据管线上,特斯拉通过FSD探索出了一套最高效的数据传输系统,并且给机器人复用,从而让两者的传输效率达到一致。
无论从特斯拉、还是小鹏和理想等玩家的实践布局来看,VLA和世界模型并不是简单的非此即彼竞争关系,而是以端到端为基础、VLA和世界模型是升级的动态融合演进关系,从而能用更低成本和更高效率推进自动驾驶、乃至机器人或者飞行汽车等更多物理AI落地。
不过,VLA和世界模型的动态融合演进关系有可能也不是智驾行业的最终答案,毕竟该行业的算法迭代还在快速进行着,正如詹锟在GTC演讲最后说的:“自动驾驶只是物理AI的一个起点”。
(头图来源于豆瓣)


