
在开始之前,我想先问大家一个简单的问题:
你们还在苦苦等待《GTA 6》的发售吗?
我是不清楚大家的想法啦,但小雷真的非常期待它的到来。要知道《GTA 5》发布至今已经过去十三年了,时至今日却依然魅力不减。让人不得不期待,在漫长的等待后,R星究竟能够端出一款怎样的作品。
不过,虽然现在说出来可能有点泼冷水,但在R星还在为发售日期遮遮掩掩的时候,大洋彼岸的谷歌DeepMind团队却悄悄搞出了一个大动作。如果不出现意外,这东西可能会彻底改变我们对游戏这两个字的理解。
近日,谷歌在官方博客正式宣布,已向部分用户开放体验Project Genie原型版本,能让用户生成属于自己的可玩游戏世界。
(图源:雷科技)
消息一出,《GTA》开发商R星的母公司Take-Two Interactive股价缩水10%,在线游戏平台Roblox下跌了超过12%,最惨的是游戏引擎制造商Unity下跌了21%,反而是国内厂商网易、腾讯基本没有受到什么影响。
趁这机会,小雷打算和大伙好好聊聊,这个敢抢《GTA 6》风头的AI到底是何方神圣,它现在的体验究竟到了什么地步,以及在不远的未来,我们的游戏和虚拟世界到底会变成什么样。
只要一张图,万物皆可玩
在介绍技术之前,我们得先搞清楚它有多离谱。
过去我们想做一款游戏,流程是怎样的?你需要策划写剧本,美术画贴图,程序员敲代码,最后还得通过引擎渲染出来。
这个过程可谓既漫长又烧钱,即便是育碧、EA这样的游戏巨头,也要做到数十年如一日地投资,最终成品却没有人能够笃定效果如何。
但Project Genie的诞生,把这个逻辑完全颠覆了。
(图源:谷歌)
它的核心能力可以概括为一句话:生成即交互。
你给它一张照片,或者一张手绘的草图,甚至是一句简单的文字描述,它就能把世界和角色搭出来。
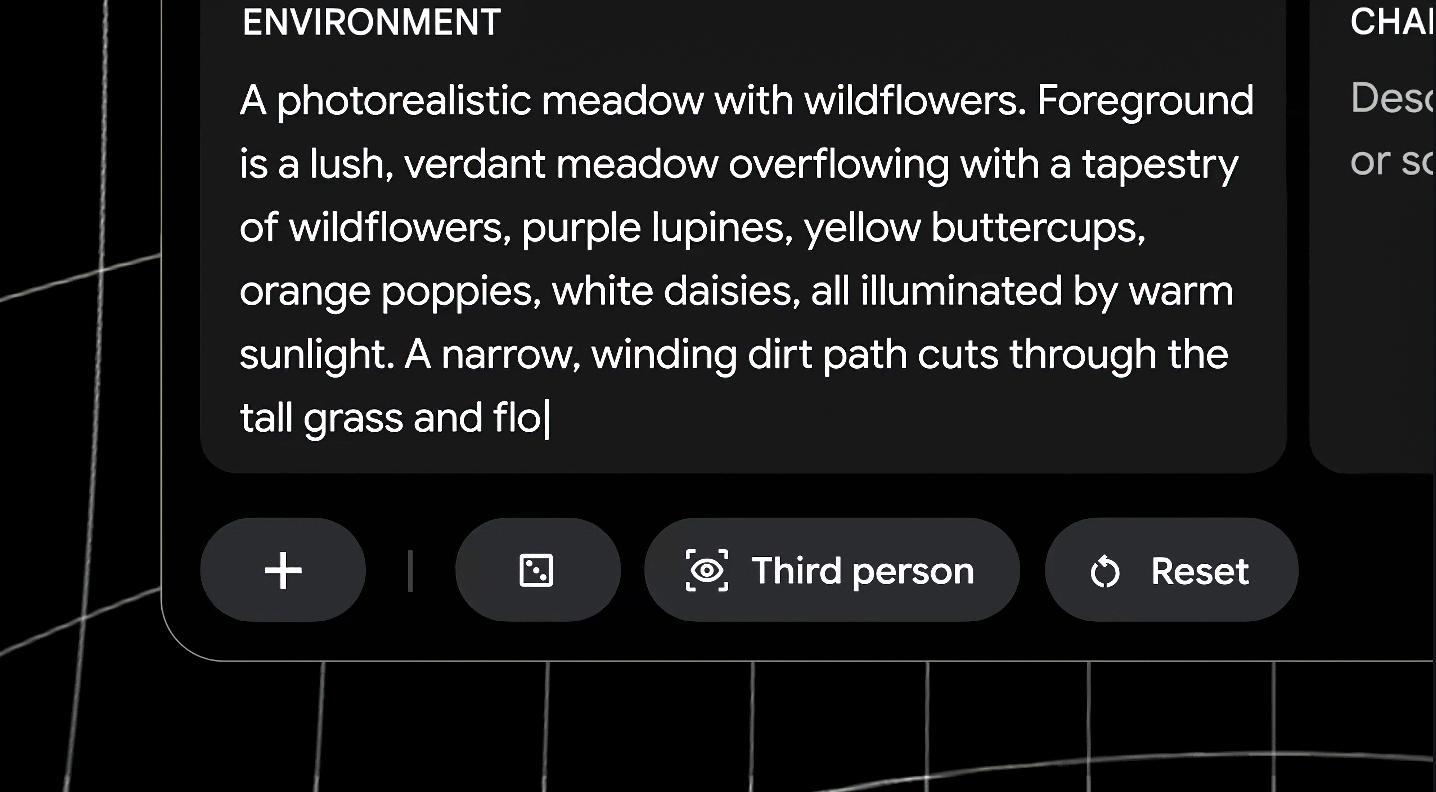
(图源:谷歌)
然后,你可以指定游戏的操作方法,例如走路、骑行、飞行还是开车,Project Genie就会试图理解物理规律,然后直接生成一个可以操控的世界:

(图源:谷歌)
没错,就像上面这个样子。
世界一旦生成,我们就可以直接在里面行动了。在Project Genie里,你往前走,前方路径会实时生成,你转视角,镜头也会跟着同步调整,整个过程更像是在一个持续展开的空间里进行探索。
不满意,那就把这个世界修改一下。
和其他AIGC内容类似,Project Genie生成的世界并不是一次性产品,我们还可以在已有世界的提示词基础上继续修改,比如把狗换成粉色气球兔子。

(图源:谷歌)
你甚至可以丢一个真实世界的图片进去,让Project Genie帮我们做二创并让其动起来,完成之后,还能直接导出成视频,方便保存或分享。
也正因为功能如此之强大,于是乎,脑洞大开的网友们很快就把它玩出了花。
在哔哩哔哩上,就有UP主上传了一张主播许昊龙的经典照片。在Project Genie的处理下,下一秒,画面里的炫狗就变成了可操控的角色,你可以按下键盘的方向键,控制他在那个车库背景里跑动、跳跃,甚至能和世界里的物品产生真实接触。

(图源:bilibili)
经典耄耋梗图?给我动起来!

(图源:bilibili)
给它一张《原神》的图,它也能自动生成风之翼的效果,让角色在空中自由驰骋,甚至能模拟出滑翔的效果。
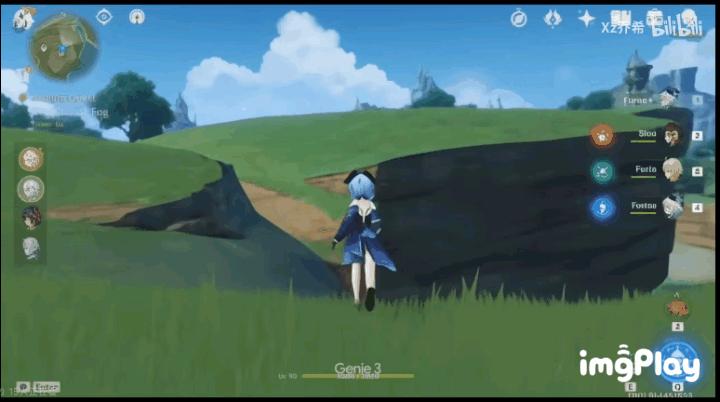
(图源:bilibili)
在推特上,甚至有人随手在纸上画了几个火柴人,旁边画了几道波浪线代表水,拍张照上传给Project Genie。系统就能把这个涂鸦变成一个关卡,火柴人真的能跳过那些波浪线,甚至如果不小心掉下去,还能模拟出坠落的效果。
而这就是Project Genie最吓人的地方:
它不需要代码,也不需要3D建模,它仅仅通过看图,就理解了什么是地面、什么是障碍物、角色该怎么动。
与之对比,国内游戏大厂们其实也没闲着,但方向多少有点小家子气。
你看,网易的《逆水寒》天天吹嘘AI NPC有多会聊天,腾讯忙着让AI在《王者荣耀》里虐菜。然而这些所谓的黑科技,说白了就是在用AI赋能游戏,本质还是机器人,远远达不到颠覆游戏创作流程的水平。
只能说国内厂商们,还是任重而道远啊。
看起来很美,但是不成熟
诶,有的读者可能要问了,既然这东西说得这么神,是不是明天游戏公司都要倒闭了?
嗯...这倒也不至于。
尽管看起来有些类似,但是Project Genie本质上和我们玩的《黑暗之魂》或者《王者荣耀》之类的游戏完全是两个物种。
传统游戏是基于游戏引擎的,你按一下跳跃键,程序会根据重力参数计算你跳多高;你扔出一个铁球,程序利用经典物理公式来计算它的下落速度;你打开手电筒,程序则会模拟光照和物体材质,来实时渲染光照的效果。
而Project Genie是基于Genie 3、Nano Banana Pro和Gemini的,其核心Genie 3本质上是一个采用自回归生成机制的帧生成模型,它会根据世界描述和用户操作,逐帧生成环境状态,而不是播放预先生成好的内容。
(图源:谷歌)
我知道,在老黄大肆推广的今天,帧生成已经不是什么新鲜玩意了。
它的工作原理,就是看着前几帧画面,然后猜测下一帧的画面。
通过学习谷歌庞大数据库里超过20万小时的游戏视频,Genie 3记住了每一种“当屏幕上有个小人,且玩家按下右键时,下一帧画面通常会发生什么”的可能性,并会在玩家做出的操作生成对应的画面。
问题就在这里,Genie 3根本不懂物理,没有可靠的逻辑计算,而是通过不断猜测来拓展世界的,这也导致了目前的体验有两个非常明显的硬伤。
首先是缺乏一致性。
尽管谷歌方面声称,为了防止AI算力过载或者逻辑崩坏,玩家只能生成一分钟的片段。
但在一分钟的限制下,我们依然能看到严重的记忆丢失。就用上面举例的许昊龙,明明玩家导入的是一张正面照片,但在实际操作角色10秒后,再次切到正脸,你会发现角色的面部发生了180°改变——变成了一个纯种白人大叔。

(图源:bilibili)
我想,除了玩Roguelike游戏的时候,应该没有多少人愿意接受这种在一个游戏里,同一个地方每次去都不太一样的情况吧
其次是没什么逻辑。
在传统游戏里,你撞到墙会被弹回来,对吧。
但在Project Genie的世界里,AI是有猜错的时候。这就导致你控制的角色可能会突然穿墙而过,或者跳着跳着突然融化进了地板里,甚至有时候走着走着,身后突然长出一棵树来。
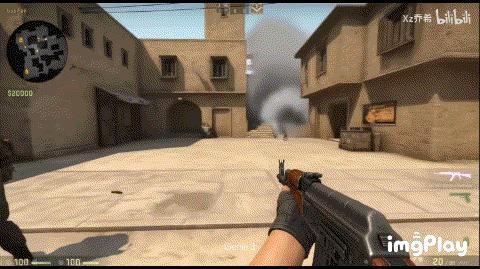
(图源:bilibili)
这种体验非常诡异,就像我们在做清醒梦,你知道自己在控制着角色,但世界总是在发生一些毫无逻辑的形变。
需要明确的是,相比前代以及其他视觉语言模型/世界模型,Genie 3的一致性、稳定性已经强出不少,但出戏的情况仍然有相当大的概率出现,这在追求可玩性的游戏里绝对是不可接受的。
正因如此,它目前的价值,更多是给游戏设计师提供一个快速验证灵感的方法。
对我们普通玩家来说,当个新鲜玩具,玩个几分钟娱乐一下或许还行。距离真正的沉浸式娱乐,还有很长一段路要走。
世界模型,才是AI的下一个战场
说到这里,可能有人会觉得,既然画质这么渣,Bug这么多,那谷歌花这么多钱搞这个Project Genie,是不是点错科技树了?
在我看来,恰恰相反。
Project Genie的出现,其意义远不止做个游戏这么简单,它代表了人工智能从“理解静态世界”迈向了“模拟真实世界”的关键一步。
我们现在熟悉的Sora、Runway这些视频生成模型,虽然能做出好莱坞级别的画面,但它们是被动展示的。观众只能看,不能互动。

(图源:OpenAI)
而Genie 3代表的世界模型,则是要让AI理解:因为我做了一个动作,所以世界发生了改变,让AI从被动展示到主动交互,从静态叙事到动态推演,这正是通往通用人工智能(AGI)的必经之路。
试想一下,如果未来的Genie能进化到4K画质、60帧,并且物理逻辑完全准确,那意味着什么?
举个简单的例子,这意味着我们不需要在现实中去训练机器人了。我们可以让AI机器人在Project Genie生成的虚拟世界里,摔倒一万次,学会走路,学会拿杯子,然后再把这个算法加载到实体机器人身上。
当然了,目前盯着这个赛道的,可不止谷歌一家。
OpenAI明确说过Sora本质上也是世界模型,英伟达刚推出的Cosmos模型号称专注于让AI理解物理定律,国内的众多大厂也在暗中布局。大家都在赌,谁能先造出那个成熟的世界雏形。
对这种新生代物种来说,好戏才刚刚开场。


