
还没有进入春节,各大厂商已经迫不及待了:前有元宝大派红包,马上千问就豪请奶茶——花不了多少钱,30 个小目标罢了。

预算在前面烧,基建在后面搭,毕竟等推广预算烧完,能做到多少用户留存,就要看产品本身了。这样一看,腾讯在下半年把前 OpenAI 研究员、清华姚班的天才少年姚顺雨挖到手,可谓计之长远。
执掌腾讯 AI 之后,近日姚顺雨终于发出了第一项署名研究,这是腾讯混元团队联合复旦大学发布的研究,把目光聚集到了上下文。这似乎是一个略显冷门的技术点,但研究的发现是能让所有日常都在玩 AI 的用户背脊一凉的:如果我们把大模型从「背书模式」切换到「现学现卖模式」,即使是目前地球上最强的 AI,得分率也只有惨淡的 23.7%。
这项研究远不止是一个技术圈的八卦,它直接揭示了为什么作为普通用户的你,经常觉得 AI 「听不懂人话」、「死脑筋」或者「胡说八道」。如果说有什么是 AI 的阿喀琉斯之踵,那上下文(Context)当如是。
上下文:AI 的灵魂
要理解这项研究的价值,我们需要先搞清楚大模型运作的两个基本阶段。
第一个阶段是预训练。在这个过程中,模型通过阅读互联网上浩如烟海的数据,记住了海量的知识和模式。这一点现在大家应该都不陌生了。这是 AI 知识储备的来源,也是它能够回答通用问题的基础。
但问题在于,预训练数据是静态的,它反映的是模型训练截止日期之前的世界。一旦脱离了这个范围,模型就会变得盲目——而真实世界是动态的。
这就来到第二个阶段,情境学习,也就是我们常说的上下文处理。当你把一段全新的、内部的、或者是极其复杂的规则文本发给 AI 时,你实际上是在要求它跳出预训练的记忆,根据眼前的信息进行实时推理和判断。
像什么呢?比如公司内部刚刚开完会之后的纪要,或者你玩的游戏有了新活动,这些知识从未在互联网上出现过,只能由你把规则、信息(即「上下文」)扔给 AI,让它根据这些新知识来回答问题。
这才是现实,互联网上并非应有尽有,模型对于上下文的学习能力可以说是非常重要,甚至可以说:上下文,就是 AI 的灵魂。
如果 AI 记不住、或者理解错了上下文,它就会开始编造(幻觉),可能会根据它「记忆」里通用规则来回答——会议纪要里明明说行政部要负责下午茶,它却说是产品经理管这事儿。
这就是混元团队这次建设 CL-bench 在干的事情。他们构建了近 2000 个从未在互联网上公开过的、由专家精心构造的「全新情境」,有虚构的法律体系,新的编程语言语法等等。
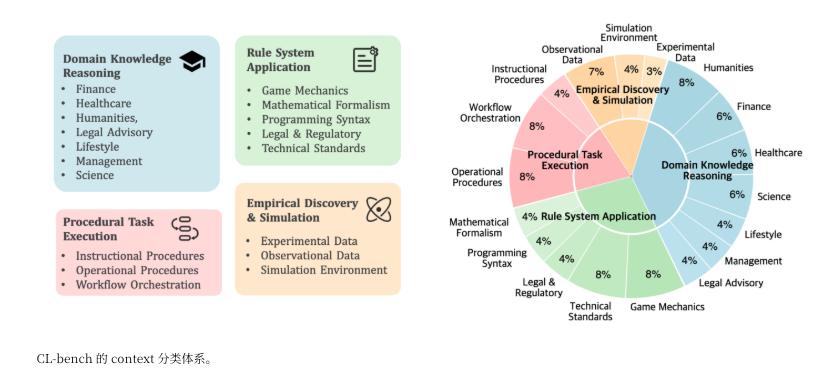
根据 CL-bench 的排行榜,目前最先进的 GPT-5.1 (High) 模型的正确率仅为 23.7%,Claude Opus 4.5 约为 21.1%,而其他的模型大都在 10%-18% 之间徘徊。
这意味着,当我们要求 AI 「忘掉你以前学的,只看我发给你的这段话」时,它们大概率会搞砸。它们就像那些固执的学生,哪怕老师已经在黑板上写了「今天 1+1=3」,它还是会大声喊出「1+1=2」,因为新知识对它而言都 「超纲」 了。
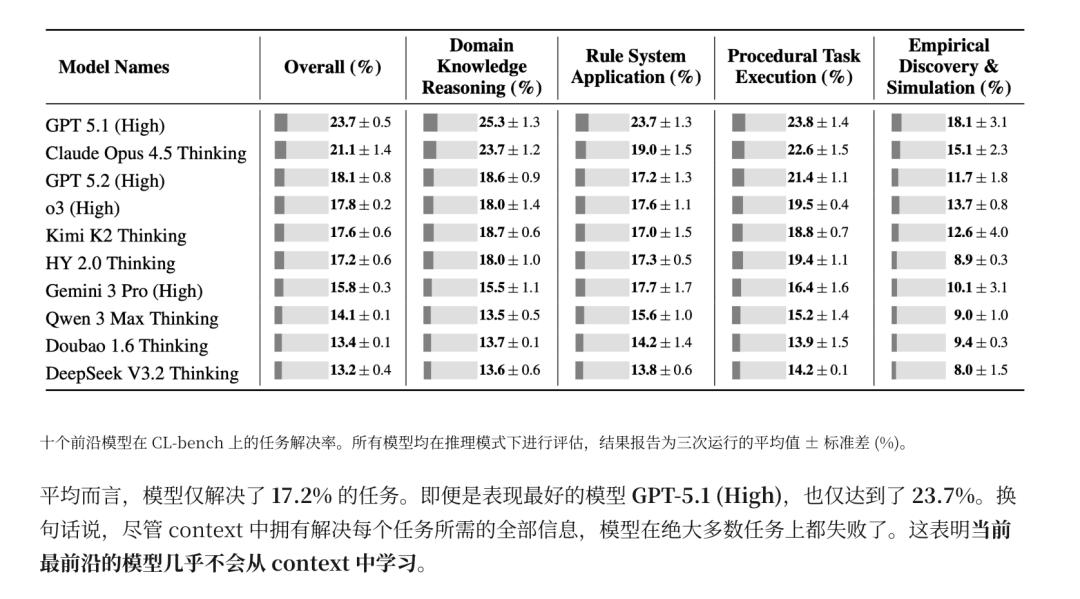
CL-bench 的研究揭示了几个导致模型在情境学习中失败的深层原因,这些原因解释了为什么我们在使用 AI 时会感到它有时聪明、有时愚蠢。
最常见的翻车原因。模型在预训练里学到的东西太「根深蒂固」了。当模型接收到新的上下文时,它往往无法有效抑制住预训练数据中那些根深蒂固的模式。
比如,在 CL-bench 的一个测试案例中,研究人员构建了一个虚构的软件开发包 Skynet SDK。虽然这只是个虚构的名字,但因为「Skynet(天网)」在 AI 的潜意识(预训练数据)里太出名了,模型可能会下意识地把《终结者》电影里的设定带入进来,从而无视说明文档里枯燥的代码规则。

另外,复杂逻辑的推演能力依然是目前技术的瓶颈——这点多少有些令人意外,都 2026 了,AI 处理超长文本不是早已经驾轻就熟吗?但实际上,虽然模型能吞下几万字,它并不一定能从数据海洋里面精准地捞出那一根针。研究发现,当提供的上下文非常长、逻辑非常复杂(比如复杂的逻辑推理链条、多轮的交互依赖)时,模型的表现会直线下降。
如果上下文仅仅是「知识检索」(比如从文档里找一个名字),现在的模型还凑合。但一旦涉及到「逻辑推理」,模型的解决率就暴跌。
为什么是腾讯来做?
CL-bench 是姚顺雨入主腾讯后,首次署名的研究成果。如果把它放到腾讯庞大的产品矩阵中去审视,就会发现「上下文学习」和这家互联网巨头自身业务逻辑之间的关系。

与其他更偏向搜索或通用生产力工具的科技公司不同,腾讯的根基深深扎根于「社交」与「内容」的土壤之中,而这两个领域对 AI 上下文能力的要求可谓极其苛刻。
想象一下微信或 QQ 的使用场景。这里产生的数据并非孤立的问答,而是连绵不断、高度碎片化的对话流——最新的元宝派就是例子。当用户试图在一个拥有数百条消息的群聊中让 AI 总结重点,或者在一段长达数月的私聊记录中寻找某个约定的细节时,AI 面临的挑战正是 CL-bench 所测试的极限:它必须在不依赖外部通用知识的前提下,精准地理解这段封闭对话中特有的语境、人际关系和隐含逻辑。
如果 AI 无法妥善处理这种高密度的上下文,它就无法真正融入十亿用户的社交链路,只能作为一个甚至会打断对话流畅度的累赘存在。
另外,腾讯在游戏与企业服务领域的布局,也决定了它对「情境学习」的渴求。游戏自不用说,各家都在探索 AI 如何根据即时的操作和游戏内的实时局势(即游戏上下文)做出反应,而不是机械地背诵预训练好的台词。
在企业微信和腾讯会议的场景中,用户需要的往往是基于特定会议纪要或私有文档的精准分析。在这些场景下,通用的预训练知识不仅无效,甚至可能因为「幻觉」而带来严重的误导。
「在场景中演满分的学生,未必能胜任真实世界的工种」 —— 混元团队意识到了这一点,这也恰恰是对当下 AI 最好的注脚。对于坐拥海量应用场景的腾讯来说,一个能在复杂上下文中保持清醒、逻辑严密的模型,远比一个博学但只会死记硬背的模型,具有更大的商业价值和落地潜力。


