
Meta首席执行官马克·扎克伯格近日批准了一项涉及约600名员工的AI部门裁员计划,这是Meta今年在人工智能领域规模最大的一次调整,主要波及公司核心研发机构。
时任Meta FAIR团队负责人的田渊栋在社交媒体X上证实:“我和我的部分团队成员也受到此次裁员影响”。Meta FAIR作为“超智能实验室”(MSL)科研体系中的核心支柱之一。田渊栋的离开也引发业界的广泛关注。
在此消息公布后,田渊栋首次公开露面,接受了腾讯科技特约作者「课代表立正」的独家深度访谈。
面对行业中的质疑,田渊栋在此做出澄清和“正名” :他的团队在Meta大模型开发中也做出了大量贡献和重要工作。然而,他们面临的最大的挑战并非技术本身,而是如何说服产品团队。
随后,访谈重心转向了田渊栋的近期研究成果,着重探讨了有关AI大模型的“顿悟(Grokking)”。
“Grokking”,这个词源自科幻作家罗伯特·海因莱因,意指对事物本质的深刻理解。大语言模型的高分不意味着智慧。真正的临界点,是它第一次学会“思考”的那一刻。
今年9月,田渊栋发表了一篇独立论文指出,Grokking不是神秘涌现,而是可计算的能量景观动力学(Energy Landscape)。

- 论文标题:Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking
- 论文链接:arxiv.org/abs/2509.21519
田渊栋的研究揭示了AI学习的核心突破:在群运算任务中,任务复杂度为M(如词汇量或概念数),传统认为模型需穷举M²种组合才能学会规律,数据需求随M平方增长。而他以严格数学证明,模型仅需O(M log M)个样本即可实现泛化——近乎线性增长。以M=1000为例,以往需百万级样本,而新理论仅约7000个。
这意味着,AI无需“看遍世界”式的暴力学习,也能像人类一样,从极少样本中顿悟深层结构,为数据受限时代的高效训练提供了理论依据。
在这场访谈中,田渊栋解读Grokking的研究,揭示了其中AI学习的关键:大模型如何从“记忆式拟合”跃迁到“结构化泛化”的内在机制。
此外,田渊栋在访谈中透露,AI对这篇论文的贡献也很大,其中的一些思考是他和GPT-5进行对话后产生的。田渊栋调侃道:“这听起来有点像self-play(自娱自乐)。不过在对话的过程中,需要给它一些insight(洞察)和思考,它才会有不一样的输出”。
本次访谈的核心观点如下:
- Grokking揭示了从记忆到泛化的数学机制,从记忆到泛化不是神秘涌现,而是优化动力学:数据不足时“记忆峰”占优,数据增多时“泛化峰”升高,一旦泛化峰略高,参数集体翻越,产生顿悟现象。
- 表征学习是所有智能能力的基础。无论是思维链推理,还是直觉判断,其根本都取决于模型如何“表示”与“理解”世界。正如数学归纳法取代穷举那样,真正的飞跃源于表征方式的改变。
- Loss Function(损失函数)只是优化的代理信号,其作用是生成合适的梯度流,引导表征朝正确方向更新。不同损失函数若诱导出相似的梯度结构,就能学到近似的表征。目标函数本身并非目的,而是优化的“可计算代理”。
- 黑盒 Scaling 强调堆参数、调配置,短期高效;机制理解则追求解释与结构,长期天花板更高。当数据触顶、样本稀缺时,Scaling Law 失效,唯有机理导向的改进才能突破局限。
- 泛化的本质是让模型学会“压缩”世界:从冗余的记忆中提炼出可重复使用的结构。真正的理解有两个标准:一是能在新情形下给出正确答案;二是能将复杂问题还原为简洁、通用的逻辑。当证据与归纳偏置(Inductive Bias)相互强化到临界点时,模型就会“跨峰”,进入泛化状态。
以下为完整版访谈内容,腾讯科技在不改变原意的情况下进行了精编整理:
01、Meta裁员事件后的澄清:为团队正名
课代表立正:最近看到了一些关于你(离开 Meta) 的消息。
田渊栋:是的,现在算是比较“自由”吧,可以做任何想做的事情了。
课代表立正:恭喜!我是在准备这次访谈的时候才注意到,你已经在 Meta 工作了整整十年。当初你加入 Meta 的时候,大概有多少人?
田渊栋:我加入的时候大概有一万多人。
课代表立正:其实那个时候 Meta 也不算是小公司了。我记得它是2012年上市的?
田渊栋:对,现在应该大约近8万人左右。
课代表立正:我们今天的访谈可以从你的论文聊起,也可以顺便聊聊最近的一些动向。
田渊栋:都可以,我更愿意聊论文。我之所以近期会在 X平台(原Twitter)上发声,是因为看到有人站出来猜测和质疑,是否是因为没有做出公司预期的成果。对此我必须要为我的团队澄清一下:我们团队做了很多非常重要的工作,不能把责任推到我们身上。这一点必须说清楚。
课代表立正:那么,团队在大模型训练的过程中具体发挥了哪些关键作用?
田渊栋:我们团队率先发现了预训练模型设计中存在的chunk attention等关键问题,并推动了解决方案的落地,有效提升了long-context RL的稳定性。另外贡献还包括数据集生成和评测,RL基础设施的构建和优化,等等。
此外,对于大模型架构中存在的一些设计问题,我们也和公司侧的多个团队进行了深入沟通。一开始沟通很困难,因为他们认为这些问题不严重,甚至觉得根本不是问题。
虽然我当时是作为研究团队加入 Meta 的,而负责大模型具体开发的团队,自然更相信他们自己的判断。所以我们只能通过大量的实验去验证,用数据和结果来证明我们的判断和洞察是正确的。最终,事实也确实证明这些问题是存在的,他们才真正接受我们的结论。这整个过程,其实就体现了我们团队的重要价值。
此外,我们也攻克了不少在大模型训练中的不少难题。比如:如何让上下文长度训练 (long context length training) 更加稳定。这个过程解决了训练中常见的 blow up(训练崩溃) 问题。虽然这些技术成果最终没有直接体现在官方版本(official release)中,但它们确实为后续的模型研发打下了坚实的基础。
可以说,我们团队更像是“幕后英雄”,没有站在聚光灯下,但在关键环节起到了承上启下、夯实底层的作用。
02、研究员的核心价值是洞察力,但真正的难点是说服别人
课代表立正:您刚才提到的问题中,我有两方面想进一步了解:
第一,作为研究团队,你们并没有被完全信任,是因为缺乏训练大模型的直接经验,还是有其他方面的原因?沟通时接触的大模型团队是怎样的?他们自身是否有丰富的大模型训练经历?
第二,你们在接触到大模型的产品能力后,为什么能迅速发现问题?
田渊栋:他们的整体经验确实非常丰富。但在某些实验中出现了程序错误(bug),由此做出了错误判断。我们这边虽然没有直接参与超大模型的训练,但一直在做大模型相关的研究,也发表过不少论文。
我本人曾做过 Sparse Attention(稀疏注意力)相关的研究,对注意力结构的机制与意义相对熟悉,因此,一看到一些设计细节,就立刻判断出其中的问题。
当然,这种判断并不是我独有,很多研究者都能察觉问题。但真正的难点在于如何说服别人。我们需要花很多时间和精力去解释、论证这些问题的存在,通常要等到对方团队在内部自查时也意识到问题的严重性,态度才会开始转变。
课代表立正:换句话说,尽管没有直接训练超大模型,但研究过程中的直觉与经验依然能帮助你们快速定位问题、判断偏差并提出修正方向。
田渊栋:是的。这就是研究员的核心价值所在:即便在“数据点稀疏”的情况下,也能推断出关键结论,并将其迁移应用到更复杂的问题上。相反,如果一个人没有 insight(洞察),只会不断地跑实验、调参数,那这样的工作是非常容易被替代的。研究员的优势在于:在有限信号下识别结构性问题,从而避免大量无效计算与资源浪费。
课代表立正:你刚才提到“稀疏的数据点”。这里具体是指什么?是来自不同论文或实验的零散结果吗?
田渊栋:可以这么理解。比如说一位新手可能需要跑一万组实验,得到一万个数值,但这些数据是“死”的——缺乏结构性分析与总结。
而一个有经验的人,看到二十个甚至十个点,甚至只是观察到一部分 training curve(训练曲线),就能判断这个路线是否行得通,从而及时止损并调整方向。
这也是为什么 AI 研究员通常薪资较高:一个真正高质量的“洞察(insight)”,可能就能节省上百、上千甚至上万张 GPU 卡的试错成本。GPU 当然重要,它能支撑更大规模的实验、带来更多观察机会;但 insight 和算力是互补的。
课代表立正:你刚才用了两个词,一个是经验(experience),一个是洞察(insight)。我想深入探讨一下这个问题:你认为到底什么是洞察能力(insight)?有些人认为这是品味(taste),有些人说是直觉(intuition),你怎么看?
田渊栋:我们需要通过对话与追问,去观察一个人是如何思考问题的。我举一个例子:在 PhD qualifier(博士资格考试)中,老师们会围绕某个主题(例如偏微分方程)不断追问,直到考生能清晰地解释关键概念之间的联系,并用最简洁的语言表述“两个最核心要素的关系”。
如果一个人只能背出定义、却说不清其中的原理,比如什么时候 A→B、什么时候 A→C,那说明他还没有形成真正可迁移的 mental model(心理模型)。做研究最忌讳的就是“概念套概念”,而没有掌握它们之间的关系与使用条件。
当前的大语言模型也普遍缺乏这种能力——在“极少数据”的条件下进行稳健外推。这恰恰是人类仍然在某些认知任务中占据优势的地方。
03、“顿悟”如何发生
课代表立正:这也呼应了我想和你对话的初衷——你的研究重点之一正是 Grokking:解释模型如何从“记忆式拟合”跃迁到“结构化泛化”。你的论文就是围绕这一机制展开的。
田渊栋:对。Grokking 提供了一条观察“从不可压缩到可压缩表示”的动力学路径(dynamics)。理解这条路径,有助于我们在数据与算力受限的环境中,用更少的样本与更可靠的训练信号,获得可泛化的表示与更强的模型。
课代表立正:你刚才提到的“顿悟”并非只是某个具体任务层面的能力,而是更底层的机制:在某个时间点,模型完成了一次表示的重组,就像“学会了”某件事。
我有关注到你此前的专访,以及我与Denny Zhou在 X平台上关于 chain-of-thought(思维链)的讨论中,也探讨过类似的现象。从理论上讲,如果逻辑链条能够被完整表达,那么 chain-of-thought 应该是可以求解的;
但现实中,模型往往需要大量数据去逼近解,而人类却能在瞬间抓住要点。这种差异似乎与刚才所说的那种底层机制相关。如果要给这种能力下定义,你会倾向称之为 reasoning(推理能力),还是另有所指?
田渊栋:更准确地说,它发生在 reasoning 或其他任务之下的“共同底层”机制,那就是 representation learning(表征学习)。
随着训练推进,模型的表征会不断演化。一开始更像是死记硬背;但随着足够的积累和联结,结构会突然“贯通”,从而出现类似“读书百遍,其义自见”的转折点。比如说在小学生的教育中,老师可能会先要求他们背诵一些知识,过段时间通过新的知识联结,原本模糊的含义逐渐显现,这就是顿悟的一部分。
课代表立正:也就是说,无论是 chain-of-thought 还是直觉判断,其实最终都依赖于“我如何表示、如何理解这个世界”这一底层机制?
田渊栋:对。比如,小学生可能解题靠穷举;而进入初高中后,引入了数学归纳法,仅靠简洁的证明就能覆盖无限情形,这种方法背后的“表示”就发生了根本性变化。神经网络的学习关键差异,也正体现在表征方式上。
04、两种研究路径:Scaling Law与机制理解,选择更困难的后者

指神经网络通过寻找能拟合训练数据的“最短程序”(最简洁的模型),从而实现最好的泛化能力 图片来源:课代表立正
课代表立正: Ilya Sutskever在 2016 年 MIT 的演讲里提过两个问题:为什么反向传播能起作用?以及理论上最优的假设空间是否等价于简洁程序(short programs)。那你的意思是不是说——模型原本要走许多路径,但突然找到了更高效的联系,实现了压缩,从而获得更强的泛化能力?
田渊栋: 对,“压缩”是一个通俗但恰当的说法。不过,目前我们仍不清楚——什么时候可以压缩,什么时候不行。
这正是研究 Grokking 的意义所在:它提供了一条动力学路径,展示系统如何从“不可压缩”状态过渡到“可压缩”状态。
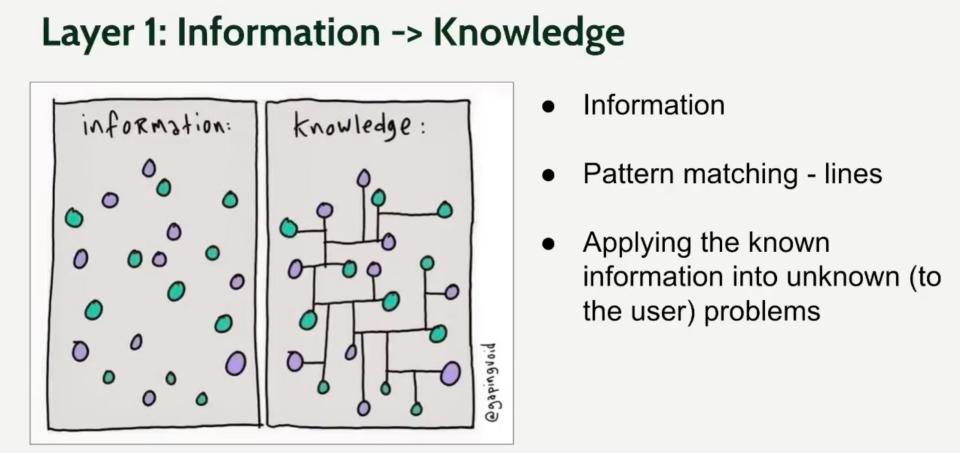
指AI通过模式匹配(连线)将散乱的信息转化为结构化的知识,从而能够应用已知规律解决未知问题。图片来源:课代表立正
课代表立正: 这听起来和人类的知识学习非常相似。我们也是通过“信息的连接”形成知识。
教育心理学认为最重要的是先验知识(prior knowledge)——新的信息只有与旧的经验建立联系,才能形成理解。 但无论在人脑还是大模型中,我们都不清楚这些“连接”究竟是如何形成的。也许理解这一过程,就能抓住下一代模型的关键契机?
田渊栋: 完全正确。 现在主要有两种研究路径:一种是把系统当成黑盒,用“scaling law(规模定律)”去堆参数、试配置;另一种是“打开机器”,理解其内部机制,然后带着直觉去调参数。
目前黑盒方法更主流,见效快、成本低;但要真正理解模型的工作原理,就必须走后一条更艰难的路。
课代表立正: 为什么黑盒方法更占上风?是不是因为即使我们“打开”了,人类也依然难以判断里面到底发生了什么?
田渊栋: 是的。这就是为什么要建立一个更高层次的整体理解框架——去统摄不同学习范式的共性。我做 Grokking 这篇论文的目的,正是尝试构建这样的框架。
短期来看,黑盒路线依然高效;但从长期来看,理解机制的那条路天花板更高。
05、Grokking:从记忆跃迁到泛化的数学机制
课代表立正:黑盒路径之所以占主流,也因为即使“打开”模型,人类也很难判断其内部到底发生了什么。因此,能否建立一个足以统摄多种学习范式的“大框架”变得很关键——这也是你们把 Grokking 作为正式论文(paper)发布的原因?
田渊栋:对。我们希望通过系统性研究,建立起更大的理解框架,从而为未来的改进指明方向。
课代表立正:我再引入一个相关讨论。我们常常从人类学习中汲取灵感。
现在有两个派系,Rich Sutton 强调,强化学习(Reinforcement Learning, RL)才是更贴近人类的学习方式,因为它拥有明确的目标函数(objective);而另一派代表(如 Hinton)认为,经验不仅来自物理互动,语言也能有效传递经验。
这场争论的核心是:人类如何学习?什么是学习?人类是如何生成新知识并 connect the dots 的?你个人更倾向哪种猜想?
田渊栋:我赞同“通过经验学习”的观点,但更重要的问题是:“哪种经验更有价值?”有一种观点强调,必须有 embodiment(身体化经验),也就是“行万里路”“亲身体验”“感受情绪”等,才能形成真正深刻的表示;另一种观点则认为抽象概念也可以通过语言传递被学习。其实这两者并不冲突。我们追求的是高质量的 representation(表征)——这种表征能够支撑预测、支持泛化。
表征是如何形成的,关键在于输入的丰富性及其结构。直观经验和抽象概念可以混合输入,只要最终能产出高质量、可泛化的表征即可。这个比例不一定非黑即白,可以是一半一半,也可以是三分之一对三分之二,关键在于能否形成有用的认知结构。
06、从黑盒试验到机制理解,打开系统才能抬高模型上限
课代表立正:回到“打开模型”这条路,它的现实意义是什么?是更高效率的学习,还是在同样的知识里学到“新的东西”?当数据见顶时,效率的边际价值似乎有限。
田渊栋:恰恰相反,数据见顶时更需要对机器的理解。如果训练 token 总量对于大众领域已足够,但对于小众领域样本稀缺,且训练算法“费数据”,模型就容易停留在记忆(memorization)而非泛化(generalization)层面。
此时仅靠 scaling law(扩展法则)可能就会失效。你可以做 data augmentation(数据增强),但如果你对模型的机理有更深入的理解,或许可以通过改进训练算法或架构本身,在少样本的情况下学到更合适的表示。
课代表立正:从大模型的生成过程来看,inference(推理)期间产生的新 token 更像是记忆还是泛化?
田渊栋:这要视情境而定,通常是两者的混合。任务种类丰富且覆盖多样组合时,更可能学到稳健的表示并实现泛化。材料越多,见到的组合越广,就越有可能形成对未见组合也有效的表征。所谓“真正理解”,一方面体现在能对新情形给出正确答案;另一方面则体现在能够将问题还原为更简单、可广泛适用的逻辑。
这两点加在一起,就构成了我们对“泛化”的一种可操作性定义。相反,若某一领域数据稀缺、结构难以捕捉,模型往往只能“死记硬背”,在训练集上的错误率尚可,但难以推广至新的样本。
课代表立正:当 scaling law 在数据受限的情况下边际效益递减,而机理导向的范式能在样本稀缺处提升“可压缩的表示”,是否意味着后者将在“高难度、小样本、结构强”的场景中显示出决定性优势?
田渊栋:这是我的判断。短期来看,黑盒方法扩大规模依旧高效;但从长期来看,打开系统并理解表示形成与迁移的动力学,才有可能真正抬高模型的能力上限。
07、从压缩性走向解释力:泛化的终极价值
课代表立正:如何更形式化地解释“从记忆到泛化”的跃迁?很多人将其视为神秘的“emergence”(涌现)。
田渊栋:我们可以通过“多峰非凸优化”(multi-modal non-convex optimization)的图景来理解。不同的表征对应着不同的“山峰”(局部最优解)。数据分布决定山峰的高低:当数据不足时,“记忆峰”更高;当数据增多且结构更清晰时,“泛化峰”会升高,“记忆峰”则下降。
优化过程会趋向更高的山峰;一旦“泛化峰”略高,参数便会集体“翻越”,呈现出“顿悟(grokking)”现象。这是一条清晰的数学路径,并非神秘跳变。
课代表立正:是否可以理解为:泛化的正确表征一直潜伏在数据中,只是我们以前未曾发现或未予重视?随着数据点的增多,其价值被凸显,我们才开始重视?
田渊栋:可以这样理解,但前提是该结构确实存在,并且数据量足以让它的优势显著到可以“打败”记忆式的解。在证据不足时,“记下来”更划算;而证据充足时,泛化结构因更简洁、更稳健而自然占优。
课代表立正:这引出了评价与奖励的问题。预训练阶段主要使用 next-token prediction(下一词预测);那么在后训练阶段,如何促成更强的泛化?又该如何避免 reward hacking(奖励机制被规避)?
田渊栋:预训练的损失函数相对稳定,比如预测下一个词等。而后训练阶段的“玩法”则丰富得多:可以在强化学习(Reinforcement Learning)的训练中设定不同的value/reward(价值/奖励)或 rubric(评分标准);也可以引入 chain-of-thought(思维链),让中间步骤经得起检验,以此抑制“走捷径”的现象(比如选择题盲猜)。不同方向的优化会分别强化模型的不同能力维度。
课代表立正:你提到“优雅(elegance)/压缩”的倾向。这种倾向存在于 reward function(奖励函数)中吗?
田渊栋:它更像是训练过程中的隐式偏置(implicit bias):在众多可行解释中,优化算法倾向于选择更简洁、更具压缩性的表示,这与我们对“优雅”的直觉是契合的。这并不是一个显式的目标项,而是由优化过程和归纳偏置(inductive bias)诱导出的学习方向,从而提升了表示的质量和泛化能力。
08、loss function只是“代理信号”,不是目的
课代表立正:你曾提到我们定义的 loss function,并不是我们真正想优化的目标,而是它的一个“代理函数(surrogate objective),这个观点该如何理解?
田渊栋:损失函数的核心作用,是生成合适的梯度流(gradient flow),以推动表示朝“正确方向”更新。不同的损失函数可以诱导出相似的梯度结构,从而学到相似的表征。
目标函数本身并非“终极目的”,而是为可学习的优化路径提供一种可计算的代理信号。很多表征学习中的目标函数,拆解后本质上都是不同形式的反向传播(backpropagation)梯度。只要梯度结构相近,哪怕换一种损失函数,学到的表征也会很接近。
课代表立正:可以将“梯度”想象为等高线图上最陡的下降方向,而这些等高线最终勾勒出的就是对世界规律的刻画。
田渊栋:这个比喻非常贴切。我们沿着等高线行进,寻找能够统一解释更多现象且更简洁的结构;当证据与归纳偏置协同达到一定程度时,模型就会“跨峰”进入可泛化的表示状态。表面上看是“顿悟”,实际上是优化动力学的自然结果。
课代表立正:回到“记忆与泛化”的关系。给模型更多“记忆材料”,是否会提高泛化的可能性?
田渊栋:在许多任务中确实如此。看到的组合越多,模型就越能学到稳健的表征,这种表征对未见过的组合也具备预测能力,这就是泛化。真正的“理解”往往表现为方法论能力的提升,能在新情境下,用少量且简单的逻辑统一解释更多现象,并能推广到更多场景。
课代表立正:如果数据很少,模型学不到好的表征,会发生什么?
田渊栋:它会倾向于记忆式学习,以满足训练误差的目标;但一旦超出训练集范围,错误率就会上升,人们往往会将其归因于过拟合或记忆主导。
09、未来方向:在小样本稀疏世界中实现“结构性迁移”
课代表立正:当 scaling law 因数据瓶颈而失效时,除了 data augmentation,还有哪些方向可以尝试?
田渊栋:可以基于机理理解来改进训练算法或模型架构,以降低“费数据”的特性,使优化过程更容易抵达“泛化峰”。这在小众领域尤为重要,因为每个子域的数据“坑”很小,常规的数据扩充手段难以奏效。
课代表立正:能否用一个直观的比喻来帮助理解?
田渊栋:可以把大语言模型看作极度勤奋、算力极强的“读书人”。读够了三百万首唐诗后,它开始作诗:不是靠背诵,而是穷尽其规律,并形成可以评估与自我提升的“方法”。
另一种路径则像发现数学公式那样,直接“跃迁”到背后的规律本身。比如,阿基米德发现浮力定律的过程其实包含两步:第一,穷举大量可能;第二,能立刻意识到“这个是对的”。而机器目前仍难以在“立刻意识到对的”这一步做到像人类一样高效。
再比如,地心说和日心说都能预测行星位置,但日心说更简洁优雅;一旦我们采用日心说,轨道变为简单的椭圆形,我们就会立刻意识到这是更好、更接近真实与美的解释。这种“优雅/压缩”的倾向,也是在训练过程中由隐式偏置自然诱导出来的。
课代表立正:在 loss function 之上,是否还存在一层更隐含的“reward”?
田渊栋:可以这么说。训练过程中的隐式偏置确实会引导模型自然地发现更优美、更具压缩性的解释,从而学到更好的表征和更强的泛化能力。所有损失函数本质上都是代理,目的是产生有效的梯度流,推动表征朝正确方向收敛;至于它们的具体形式,其实不如梯度结构本身重要。
课代表立正:我明白了。等高线的比喻也确实有助于理解:我们沿着可计算的代理信号走向更优的解释;当“泛化峰”略高于“记忆峰”时,模型的参数整体迁移,表现出“顿悟(grokking)”现象。但这个“等高线”的逻辑,其实是大家经常使用的比喻。不过,它忽略了神经网络本身的结构特性。
田渊栋:是的。这个比喻把整个 loss landscape(损失地形)看作是高维空间中的山峰,而每个山峰实际上对应的是神经网络参数空间中的一种表示结构。因此,我们不能只看山峰的形状,还需要关注这些结构与网络本身之间的关系。
课代表立正:换句话说,梯度在山峰上的变化,其实是通过每个神经元的梯度路径来实现的?
田渊栋:对。如果你能将梯度方向映射回神经网络中每组参数、每一层神经元,就能观察到哪些模块学到了什么样的表征。这个过程虽然较为复杂和细节化,但非常有助于我们从直觉上理解 representation learning(表示学习)的底层机制。
10、人机协作新范式:AI正在成为科研中的“共创者”
课代表立正:您刚提到研究范式的变化,现在您怎么看AI在科研中的角色?
田渊栋:研究范式的探索非常重要,我们也要与时俱进。不可能仍用过去的方式做研究。未来也许我们会拥有“AI Scientist”,或者我自己写一套Agent框架,来协助完成研究。
课代表立正:这听起来很有意思。
田渊栋:实际上,这篇关于 Grokking 的论文,一些思考是和GPT-5进行对话后产生的。虽然有点像 “self-play(自娱自乐)”,不过在对话的过程中,需要给它一些insight(洞察)和思考,它才会有不一样的输出。
课代表立正: 不过我注意到,那篇论文是您独立署名的?
田渊栋:是的。因为会议投稿不允许将大语言模型列为作者。但我在文中注明,我们大量使用了AI:我给模型想法,让它去论证、推导、再发现问题。它常常是错的,但偶尔能提出很有启发性的见解,帮助我把一个模糊的想法细化为可执行的研究过程。
课代表立正: 我也有类似体会。我曾与GPT的o1-pro讨论过比如关于量子力学的一些研究,感觉AI能帮助我整理思路,但写不出像您这样有“顿悟感”的论文。
田渊栋:这里的关键是,真正重要的 insight 仍需人类提供。AI可能会出现“卡壳”,绕着概念兜圈子,说不到本质。这就像一个“新来的博士生”,话很多,却抓不住核心。
课代表立正: 这确实是个普遍问题。
田渊栋:所以需要研究者去总结、提炼、引导。AI可以被“训练”,但还不具备判断“讲清楚”的美感。而“讲清楚”本身就是一种极高层次的能力,很难被建模成 loss function。
课代表立正: 的确,我们要先学会自己讲清楚,再去要求模型做到。
田渊栋:没错。这种“讲清楚”的能力,蕴含着理解的深度与美感。如何让模型具备这样的能力,可能是下一个值得探索的科学问题。
课代表立正: 听完这段,我更深刻地体会到AI对研究方式的改变。它不仅是工具,更是一面镜子,让我们重新思考什么是理解、什么是清晰表达。通过这篇论文,我们其实也在探讨人类与AI如何共同进化的过程。


