
近日,斯坦福大学与 SambaNova Systems 合作发表了论文《Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models》。
该论文提出了一个名为ACE(Agentic Context Engineering)的框架,可以让AI在不重新训练权重的前提下,实现自我改进。

论文链接: http://arxiv.org/abs/2510.04618v1
论文的核心思想是,大模型的能力,并非仅由参数决定,更取决于“上下文的质量”。换句话说,谁能构建出最优的上下文,谁就能让模型更聪明。
ACE的核心思想,是让模型不再依赖“静态提示(prompt)”,而转向一种动态、结构化、可进化的“知识剧本”(playbook)。
这些剧本记录了模型在任务执行中积累的策略、规则、模板和修正规则。每一次失败或成功,都会被转化为一条“增量更新”(delta)。
与传统的“重写提示”不同,ACE通过小步安全更新不断改进剧本,而不是一次性推倒重来。
这种机制意味着,AI可以在运行中学习、记忆、改进,而不需任何参数微调。
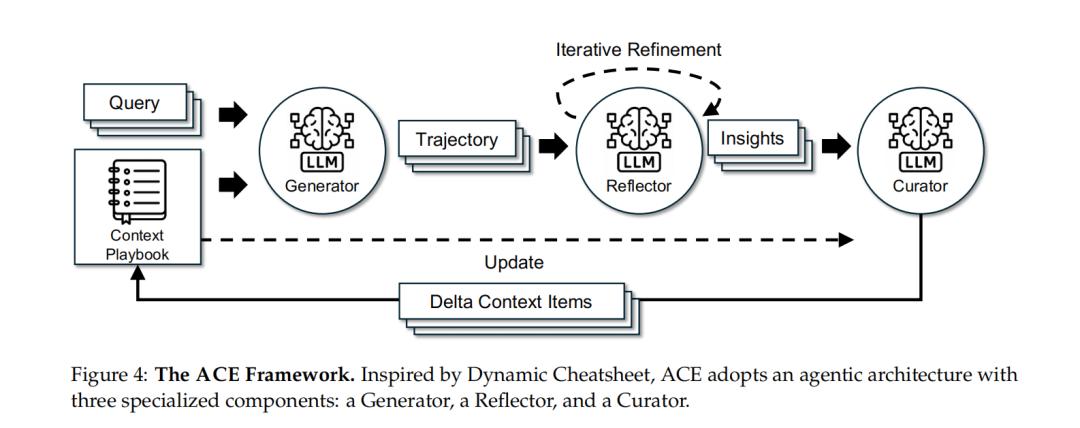
ACE框架
研究者指出,这一机制能避免两种致命问题:一是简化偏差(brevity bias),即在追求简洁的优化中丢失关键细节;二是上下文崩塌(context collapse),即重写导致的知识损毁。
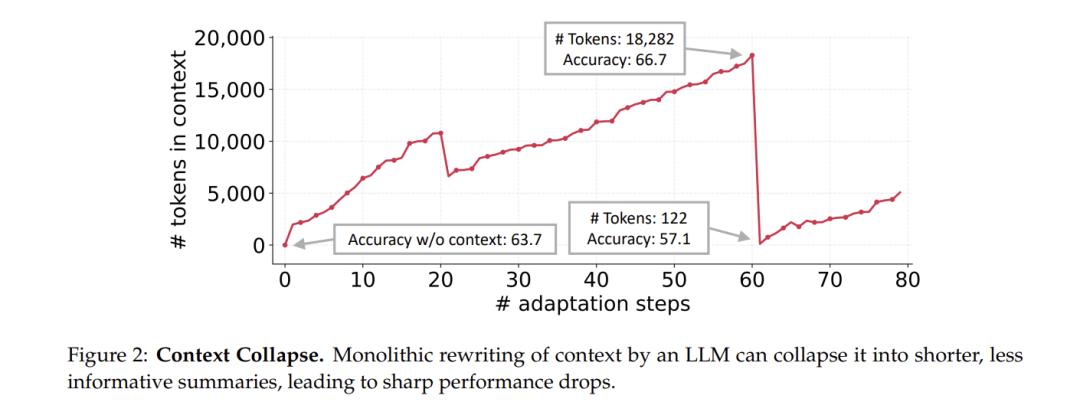
论文举例称,在实验中,一个AI代理积累了1.8万token的上下文,表现良好。但当模型试图“总结压缩”它时,剧本被削减至仅122个token,性能瞬间跌至57.1%。
研究者直言:“模型擅长使用知识,但不擅长整理知识。一次错误的重写,就可能摧毁全部积累。”
论文称ACE解决了这种“自毁式学习”的结构性风险。
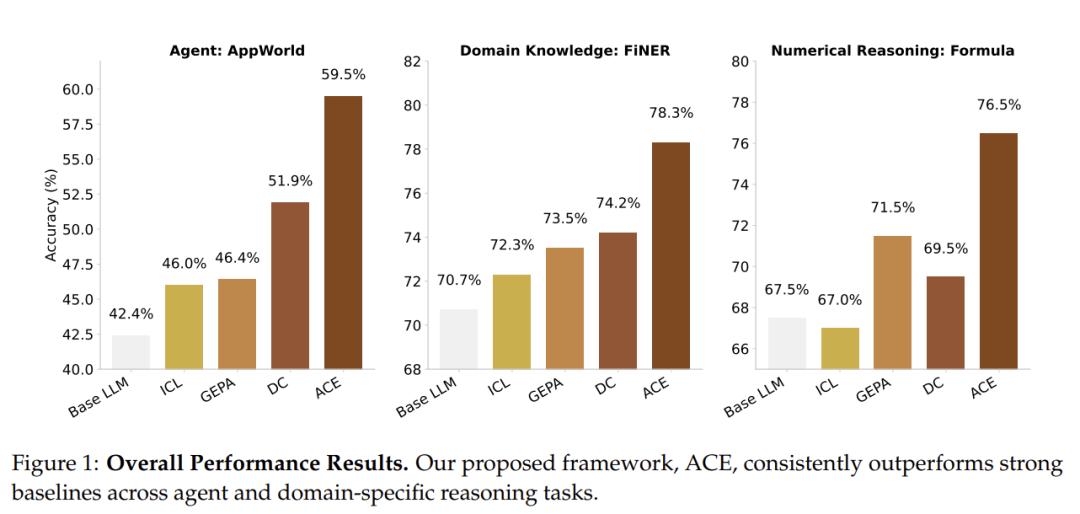
图注:ACE 框架在三类任务(智能体操作、领域知识、数值推理)上都显著优于其他方法,准确率提升最明显。
三角色协作:生成、反思、策展
ACE体系建立在一个极简哲学上: 不要重写知识,要管理知识。
整个系统被拆解为三个互补的角色。
第一个是生成器(Generator)。它负责执行任务,与环境交互,生成推理过程、代码或操作序列。
第二个是反思器(Reflector)。它分析生成器的行动轨迹,识别成功与失败的原因,提取“可操作的教训”。这些反馈信号可能来自代码错误、执行结果或外部标签。
第三个是策展器(Curator)。它将这些经验提炼为结构化条目(delta context),并通过确定性规则(非语言模型决策)整合进主剧本。
这样的三层循环——行动、反思、整合构成了ACE的学习闭环。
每次更新都只影响局部条目,不触碰整体文本。这种局部增量机制,让知识库既能不断扩展,又不会坍塌。
剧本本身被设计为项目化结构:包含策略规则、API调用模板、调试经验、常见错误解决方案等。每条条目附带使用计数与正负反馈元数据。
反思器会根据这些记录判断哪些规则有效、哪些无用。策展器再据此修改或删除。
论文称,这种方式让AI的知识“像Git仓库一样演化”,能安全地生长、细致地修剪、透明地追溯。
研究者强调,ACE的复杂度并非负担,而是一种结构化的安全机制,以微小的系统开销换取知识的稳定积累。
小模型“越级打怪”:DeepSeek击败GPT-4.1
在复杂的AppWorld代理任务中,ACE框架带来了+10.6%的平均性能提升,并将适应延迟降低86.9%。
研究团队特别提到,这一提升并非依赖更大的模型,而是源于更好的上下文管理。
一个典型例子是:DeepSeek V3.1,参数量低于GPT-4.1。但在ACE框架下,它在AppWorld基准测试中,竟能与GPT-4.1代理(IBM CUGA)持平,甚至在更复杂的测试集上反超。
研究者指出,这一结果说明,“上下文工程”已成为新的算力平权器。
更重要的是,ACE的效率优势惊人。在多轮任务学习中,它的更新延迟减少82%~91%,token成本下降83.6%。
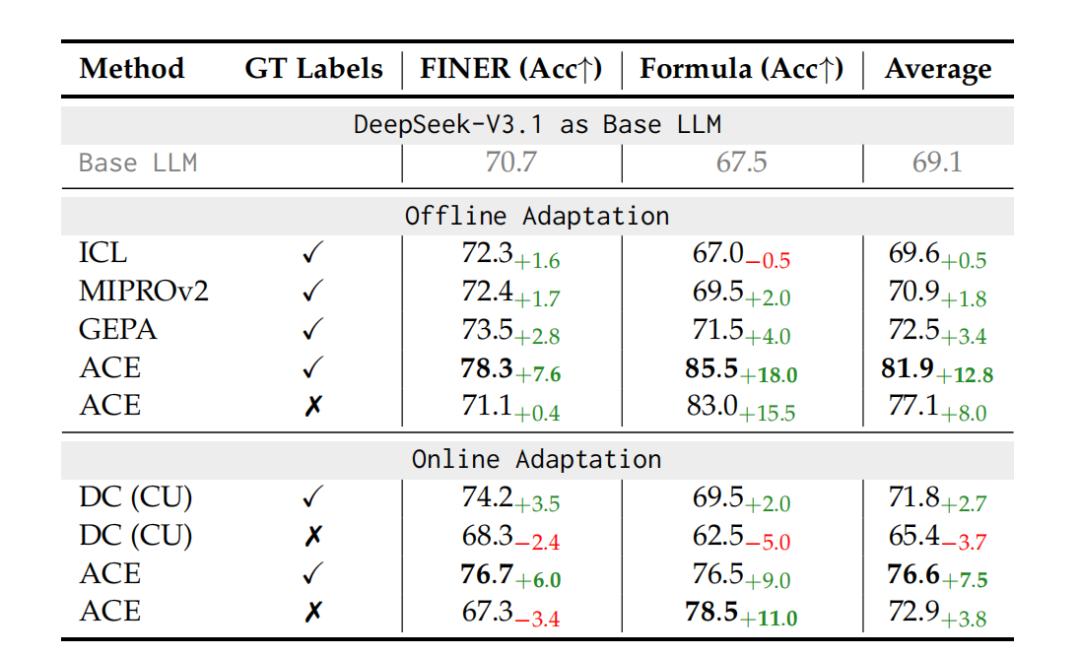
图注:在金融分析任务中,ACE 框架显著提升模型表现(平均提升约 8.6%),即使没有真实标签也能保持稳定表现。
论文认为,这让“在线持续学习”从概念变为现实。AI不再需要频繁微调,而可以在运行中自我优化。
同时,ACE的结构化剧本让学习过程可解释、可审计、可撤回。
如果某条规则被发现过时、偏颇或违规,系统可以精准删除对应条目,实现“选择性遗忘”。


