

在这篇文章中,我将解释为何尽管风险投资公司(VC)和大型科技公司投入了数亿乃至数十亿美元用于训练,如今的人形机器人仍无法学会如何具备灵巧性。
在文章的结尾,在我完成关于这一观点的论述后,还附加了另外两篇短文。第一篇探讨了双足人形机器人在行走时,要确保人类在其附近活动安全,仍需解决的问题;第二篇则分析了15年后,我们虽会拥有大量人形机器人,但它们的外观既不会像如今的人形机器人,也不会像人类。
一、 序言
自1956年“达特茅斯人工智能夏季研究项目”提案中首次出现“人工智能”一词后的几年起,人工智能研究者们试图让机器人手臂和手部实现物体操控的探索,已持续了65年以上。
到1961年,海因里希·恩斯特(Heinrich Ernst)完成了一篇博士论文,文中描述了一款他与麻省理工学院TX-0计算机相连的计算机控制式手臂和手部,该设备能拾取方块并将其堆叠,更令人惊叹的是,相关过程还有视频记录。他的导师是克劳德·香农(Claude Shannon),他还感谢了马文·明斯基(Marvin Minsky)的指导——而这两位正是达特茅斯人工智能提案四位作者中的两位。
这一研究催生了工业机器人。无论是过去还是现在,工业机器人都是配备各种“末端执行器”(可理解为简易手部)的计算机控制式手臂,60年来已在全球工厂中广泛应用。
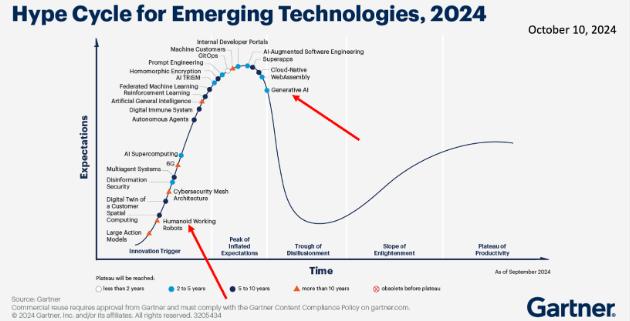
近来,新一代研究者偶然萌生了制造人形机器人的想法,你可能也注意到了相关的一些宣传热度。高德纳(Gartner)表示,目前人形机器人仍处于发展初期,远未达到宣传热度的峰值。下图距今仅一年,从中可看出,人形机器人正处于发展周期的起点,而生成式人工智能已过峰值,正朝着低谷期回落:
人形机器人的设计理念是采用与人类相同的身体结构,并在为人类打造的环境中像人类一样工作。这种理念认为,我们无需制造不同类型的专用机器人,只需研发能完成人类所有工作的人形机器人即可。例如,人形机器人公司Figure的首席执行官称:
“我们要么制造数百万种执行特定任务的不同类型机器人,要么打造一种具备通用接口、能执行数百万项任务的人形机器人。”
以下是他“总体规划”的第一阶段:
1. 打造功能完备的机电一体化人形机器人。
2. 实现类人操控能力。
3. 使人形机器人融入劳动力市场。
在刚刚过去的这个夏天,特斯拉(Tesla)首席执行官在谈及名为“Optimus”(擎天柱)的人形机器人时表示:
“擎天柱可能会创造30万亿美元的收入,并将人形机器人称为‘或许是全球最大的产品’。”
对这两家公司,或许还有其他几家公司而言,它们的总体计划是让人形机器人实现“与人类即插即用”——能够以更低成本、同等水平接替人类,完成各类体力劳动。在我看来,认为这一目标能在数十年内实现的想法,纯属幻想。但许多人预测,最快两年内就能实现;而那些更为“保守”的鼓吹者则认为,人形机器人将在五年内产生显著的经济影响。
我所在的公司专注于研发部署在仓库中的机器人,它们采用基于“轮子”的新型移动系统(事实上,我们的移动系统确实是创新设计,仅在两年前,这种设计还完全不存在)。我们曾向一些风险投资公司进行融资路演(这是创业圈的常用说法),希望获得资金以扩大规模、满足客户需求,却被问到:“既然所有人都知道,两年内双足双臂的人形机器人就会接管人类的大部分工作,你们为何还要执着于研发仓库机器人?”
我个人的看法最终或许无关紧要,但关键在于,人形机器人的宣传热度源于一种理念:它们将成为通用机器,能够完成人类可做的任何体力任务。无需为了用自动化替代人力而改变现有工作方式,人形机器人只需直接接手现有工作,无需费力调整流程。要实现这一点,人形机器人的操控能力必须达到人类水平——就像我们如今期望无人驾驶出租车具备人类级别的城市道路驾驶技能一样。
因此,要让人形机器人在经济和技术层面都具备实际意义,就必须使其拥有类人操控能力。在人形机器人的支持者中,这一观点毫无争议,而这也正是人形机器人存在的根本原因。人形机器人研发者认为,要实现其实际价值,就必须尽快让人形机器人的灵巧性不断接近人类水平。
二、人形机器人简史
数十年来,众多研究者致力于人形机器人的研发。早在20世纪60年代中期,日本东京早稻田大学(Waseda University)的研究者就开始研究双足行走机制;到70年代初,该校人形机器人研究所研制出了首台人形机器人WABOT-1(早稻田机器人)。
80年代初,WABOT-2问世,此后早稻田大学持续研发新型人形机器人。日本汽车制造商本田(Honda)在80年代末开始研发双足行走机器人,最终于2000年推出了人形机器人ASIMO。
索尼(Sony)先是研发并销售了机器狗Aibo,随后在2003年推出了小型人形机器人QRIO,但从未实际销售过该机型。法国公司奥尔德巴兰(Aldebaran)于2007年推出了小型行走人形机器人NAO,它取代Aibo,成为已有30年历史的国际机器人足球联赛的标准平台。
之后,该公司又推出了更大尺寸的人形机器人Pepper,但商业成效欠佳。35年前从麻省理工学院拆分出来的波士顿动力(Boston Dynamics),在多年研发四足机器人后,于2013年推出了人形机器人ATLAS。
除了日本早期在人形机器人领域的研究,全球还有众多学术团队致力于类人形态机器人的研发——这些机器人有的有腿、有的无腿,有的有臂、有的无臂。
我在麻省理工学院的研究团队于1992年开始研发人形机器人Cog,先后开发了七个不同版本的平台;2008年,我创立了Rethink Robotics公司,推出了Baxter和Sawyer两款人形机器人,销量达数千台,已部署到全球各地的工厂。
我的一些前博士后研究员回到意大利后,启动了RoboCub开源人形机器人项目,该项目助力全球数十个人工智能实验室成功研制出人形机器人。

数十年来,这些团队始终坚持研发人形机器人,并探索如何让它们在为人类打造的环境中行走、操控物体以及与人类互动。早在2004年,《国际人形机器人期刊》(International Journal of Humanoid Robotics)就已创刊,最初为纸质版。

如今,你可以在网上查阅该期刊的内容,目前它已出版到第22卷研究论文。
2.1 人形机器人的操控挑战
1961年,海因里希·恩斯特要让机器人用手臂和手部操控物体,已是一项艰巨任务。此后,无论是机器人研究者还是工业工程师,乃至如今的从业者,都始终面临这一难题。
20世纪60年代中期,平行夹爪抓取器问世。这种抓取器有两个可开合的平行“手指”,如今仍是机器人手部的主流形式。下图左侧是我在20世纪70年代于斯坦福大学(Stanford University)研发机器人时使用的平行夹爪抓取器,右侧是我创办的Rethink Robotics公司在2010年代中期生产销售的款式,两者均为电动驱动。

两者唯一的区别在于:右侧更现代的抓取器内置了摄像头,可通过视觉伺服系统对准目标物体——而在70年代,受限于技术,无法在定价合理的产品中实现这一功能,因为当时的计算能力不足以支撑。
德国公司雄克(Schunk)生产销售1000多种平行夹爪抓取器,涵盖电动和气动(压缩空气驱动)两种类型,适配机器人手臂。该公司还销售部分三指径向对称手部以及少量专用抓取器。目前,尚无任何一款多关节手指(即带活动关节的手指)机器人手部,能达到足够的耐用性、力度和使用寿命,以满足实际工业应用需求。
在有压缩空气供应的场景中,可通过文丘里喷射器将其转化为吸力,因此另一种常见的机器人手部是利用一个或多个吸盘,通过吸附物体表面来抓取物体。下图是Rethink Robotics公司推出的吸盘式抓取器,可与电动平行夹爪抓取器搭配使用。

单吸盘和多吸盘末端执行器(即手臂末端类似“手部”的装置)已广泛应用于成品搬运——例如将成品装入相同规格的定制包装盒,或搬运即将寄送给消费者的成品箱与包裹。事实上,运输包装用软质材料与吸盘式末端执行器已形成协同进化:相较于其他方式,吸盘能更轻松、快速地抓取寄往家庭的软质包装。
过去几十年间,研究者们研制出了众多模仿人类手部的多关节手指机器人手。下图展示的几款分别由约翰·霍勒巴赫(John Hollerbach)、肯·索尔兹伯里(Ken Salisbury)和松冈洋子(Yoky Matsuoka)研发。

然而,从通用角度来看,尚无任何一款类人机器人手能展现出显著的灵巧性,也没有任何一款的设计能投入实际应用。目前,灵巧性研究多采用数学和几何方法,但这些方法始终未能让人形机器人达到人类级别的灵巧性。
你可能见过类人机器人手完成特定任务的精彩视频,但它们完全无法将能力迁移到该特定任务之外的场景。近期,本杰·霍尔森(Benjie Holson)在一篇轻松却极具洞察力的博文中(披露:我与本杰在Robust.AI公司密切合作),提出了“人形机器人奥运会”的构想,列出了15项任何8岁人类都能完成的任务,并设有奖牌。
例如,其中一项挑战是:人形机器人折叠衣物时,需将一件袖子外翻的男士衬衫挂好,且至少扣上一颗纽扣;另一项挑战是清理自身手部的花生酱。你不能以“这项任务更适合其他类型的机器人机械装置”为由推脱——因为人形机器人的核心价值主张就是能完成人类可做的所有任务。
看完本杰列出的15项挑战后,你很容易再想出15项或30项灵巧性任务,这些任务与他提出的任务几乎无共通之处,但人类无需思考就能完成。此外,还有一些更复杂的任务,只要有需要,人类也能完成。
2.2 一种曾奏效的思路
那么,我们该如何是好?怎样才能让人形机器人具备灵巧性?我猜想,很多人肯定都有过这样的内心思考:
过去20年,端到端学习(end-to-end learning)在至少三个领域取得了显著成效:语音转文字、图像标注,以及如今的大型语言模型(LLMs)。既然如此,与其试图通过数学方法解决灵巧性问题,不如直接采用端到端学习?我们可以收集大量人类用手完成任务的数据,将其输入学习系统,就能输出灵巧的机器人控制模型。这样一来,我们的公司就能估值数十亿美元。
别想太多,动手干就完了!
人形机器人公司和学术研究者选择的实现方式,大致是让学习系统“观看”人类完成操控任务的视频,试图从中学习机器人完成相同任务所需的动作。在少数案例中,人类会远程操控机器人(人类能看到机器人及被操控的物体),并能获得少量力反馈和触觉反馈——但这些反馈大多来自机器人手部,而非手腕、肘部、肩部或髋部,且这类触觉数据的精度非常低。
本杰·霍尔森在博文中指出,目前收集的数据不仅数量匮乏,精度也很低,我完全认同他的批评。以下是他的观点,表述已十分透彻,我无需再补充:
“目前我看到的有效方法是‘从演示中学习’(learning-from-demonstration)。研究者会准备一些机器人和操控界面(标准配置通常是两台相同的机器人:人类抓取并移动其中一台,另一台同步模仿;或使用Oculus头显+控制器,配合手部追踪技术),然后反复记录一段10-30秒的动作(重复数百次)。
之后,训练神经网络模仿这些示例动作。这种方法确实让机器人能够完成一些任务,比如‘拉扯毛巾边角查看是否平整’这类步骤较难预测的任务,或‘木块可能以6种角度摆放、毛巾却能揉成无数种形状’这类高状态空间任务。但稍加思考就能发现,这种方法存在一些局限性。尽管存在例外情况,但总体趋势如下:
1. 无手腕力反馈:机器人的表现完全依赖人类远程操控,而目前尚无成熟的标准方法,能将力信息准确传递给人类操控者。
2. 手指控制精度有限:无论是人类操控者,还是人工智能基础模型,都难以精确观察和控制机器人的所有手指,大多只能实现简单的开合动作。
3. 无触觉感知:人类手部布满传感器,而目前根本无法让机器人手部具备类似的触觉感知能力,更无法将其传递给人类操控者。
4. 精度中等:根据视频推测,这类任务的精度约为1-3厘米。
折叠毛巾和T恤这类任务,对腕力要求不高:只需通过捏握动作拉扯、提起衣物,再张开手部展开衣物,就能完成。通过视觉观察就能判断抓取位置是否合适,无需手指感知。1-3厘米的精度也完全足够。”
事实确实如此:人形机器人公司及众多学术项目,都在试图仅通过“展示动作”来训练机器人掌握灵巧操控能力,完全不涉及力反馈或触觉反馈的运用。
例如,就在上周,Figure公司宣布了“Project Go Big”(大步向前计划),介绍了他们将如何训练机器人掌握新技能。这一计划并无新意,与该公司此前的表述和展示完全一致。以下是该公司的相关说明(重点为我所加):
“传统上,教机器人掌握新技能需要耗费高昂成本进行演示、编写手动程序,或搭建高度受控的环境——而这些环境无法模拟真实世界的复杂性。但人形机器人具有独特的结构优势:它们的视角和运动学特性与人类一致,这使得知识能直接从日常人类视频中迁移。”
该公司表示,他们将通过人类完成任务的第一视角视频,训练机器人掌握新的体力技能。
此外,一个月前,科技媒体eWeek发布了一篇新闻报道,称特斯拉正全力通过“观看人类完成任务的视频”来训练人形机器人擎天柱。报道指出:
“特斯拉调整了人形机器人擎天柱的训练策略。不再依赖动作捕捉服和远程操控,而是转向‘纯视觉方案’。
如今,工作人员会佩戴由头盔和背包组成的摄像设备(内置5台自研摄像头),记录‘折叠T恤’‘拾取物体’等日常任务。这些视频随后会用于训练擎天柱,使其模仿相关动作。”
报道后文还提到:
“佛罗里达农工大学-佛罗里达州立大学联合机器人实验室主任克里斯蒂安·胡比基(Christian Hubicki)向《商业内幕》(Business Insider)表示,这种多角度摄像装置或许能捕捉到‘关节和手指位置等细微细节’,从而提高数据精度。”
Figure和特斯拉都坚信,只需让机器人观看人类用手完成任务的视频,就能训练其掌握手部操控能力。他们赌的是:通过机器学习大量人类手部动作视频,就能让机器人习得灵巧性。他们认为,视觉精度及大规模视觉数据集,已足够实现这一目标。【也有可能他们在“藏拙”——毕竟30万亿美元的诱惑巨大,即便对已身价不菲的人来说亦是如此,或许他们只是不想让竞争对手知晓真实的研发方向。但在本文的论述中,我将假定他们的表述属实。】
三、 端到端学习依赖“目标”的选择
过去20年,借助线性阈值神经模型,端到端学习在三个领域实现了革命性突破:语音转文字、图像标注,以及如今大型语言模型(LLMs)生成流畅文本。
在语音和图像领域,新方法的性能大幅提升。这两个领域的成功,关键在于尽可能将问题交给学习方法处理。具体而言,在语音领域,研究者摒弃了此前主导的音素(高度依赖语言本身)显式模型;在图像标注领域,则不再依赖线条(边界)检测、形状、阴影或颜色恒常性等传统图像理解方法。
大型语言模型展现出的语言能力和通用问答能力(如今仍存在严重的“幻觉”问题),远超所有人的预期。更令人意外的是,它们的训练完全不依赖外部输入来解释文本含义——无需与真实世界互动获取直接经验,就能实现这一能力。它们是“自给自足”的语言机器,无需像所有人预期的那样“在真实世界经验中扎根”(即解决“符号接地问题”)。【就连艾伦·图灵(Alan Turing)也在其1948年撰写、1970年才发表于《机器智能5》(Machine Intelligence 5,由伯纳德·梅尔策(Bernard Meltzer)和唐纳德·米基(Donald Michie)编辑)的经典论文《智能机器》(Intelligent Machinery)中提及这一点。在该论文(该书第13页)中,图灵指出,制造智能机器的可靠方法是“以人类为整体,尝试用机器替代人类的所有部分”——如今我们或许会称之为“制造人形机器人”,这一预见极具前瞻性!至于“在真实世界经验中扎根”,他进一步表示:“要让机器有机会自主探索,就需允许它在现实世界中活动,但这对普通民众而言风险极高”(重点为我所加)。他得出结论,以当时的技术水平,要实现这一点难度过大。这又是他极具前瞻性的两个观点。】
这些突破都是革命性的,让包括我在内的大多数研究者都感到震惊。但不可否认的是,这些新方法的效果远胜于以往我们见过的任何技术。
2019年3月13日(大型语言模型出现之前),里奇·萨顿(Rich Sutton)——他后来在2024年与安德鲁·巴托(Andrew Barto)因在强化学习领域的研究共同获得图灵奖——发表了一篇略带成就感的短博文,标题为《惨痛的教训》(A Bitter Lesson)。在文中,他将自己的观点延伸到了更多领域,其中就包括“大规模搜索让计算机在国际象棋和围棋上超越人类”这一案例。
对于搜索和学习这两种方法,他表示:
“依赖人类知识的方法往往会使技术变得复杂,使其难以利用通用方法发挥计算能力的优势。”
随后,他以国际象棋、围棋、语音和图像领域为例展开讨论,主张完全不应在问题构建中融入人类的固有偏见。但无论是当时还是现在,我都认为,在所有这些成功案例中,人类知识其实都发挥了作用——因为“端到端”的本质,依赖于人类对“目标(ends)”的定义。
萨顿发表博文六天后,我也以一篇同样简短的博文《更好的教训》(A Better Lesson)作为回应。在那篇博文中,我指出了这种方法在规模化应用中存在的一些普遍问题——正如我们现在所见,大规模语言模型需要巨大的能源和服务器支持,还需要数千人参与数据集准备,这些事实本身就反驳了“将人类排除在流程之外”的观点。
更重要的是,我指出图像标注并非“从图像到标签”的纯粹端到端过程。相反,它会以卷积网络作为前端,来规定学习算法获取图像信息的方式。尽管当时我没有针对语音转文字或尚未问世的大型语言模型提出类似观点,但现在我认为,这三个领域的成功,都离不开工程师们构建的“特定于场景的预处理步骤”——而这些步骤,本质上是对人类生理机能部分功能的直接模拟(无需通过学习实现)。
以下是这三个领域中,为配合学习而设计的前端数据预处理方案:
3.1 语音转文字
语音转文字的任务,是将麦克风接收到的人类语音信号,转换为代表对应文字的字符串。如今,我们已经习惯了与各类设备对话——比如亚马逊Alexa、电视遥控器、汽车,或是客服热线等无数设备和渠道。
这些设备都依赖语音转文字技术提取文字,再将其输入系统以生成合适的响应(我们希望如此)。而这项技术直到近20年才变得实用,其背后正是“基于大规模数据集的端到端学习”——通过同时获取麦克风输入和对应的正确文本,让学习系统掌握从信号到文本的转换能力。
声音信号进入计算机进行学习的方式有很多种。理论上,我们可以将麦克风的模拟输出进行数字化处理,每秒采集数万次响度数据,再将这些数据作为学习的输入。但在实际应用中,我们并不会这样做。
相反,语音转文字技术依赖于20世纪为全球电话网络语音通信开发的一项技术:为了让单条线路能承载更多通话,工程师们对每条语音线路的信号进行了压缩。这项研究明确了信号中必须保留的关键信息——只有保留这些信息,远方的接收者才能听懂说话内容。而人类能听懂经过压缩的信号,这就意味着,这些压缩后的信号中包含了理解语音所需的全部信息。
不同语音转文字学习系统的输入方式有所差异,但通常会包含以下常见预处理步骤:
首先,以固定频率(如16kHz)对模拟输入信号进行采样;接着,通过高通滤波器增强高频信号(高频信号对识别辅音至关重要);
然后,将信号分割成帧(例如每帧25毫秒,帧与帧之间重叠10毫秒);
之后,对每帧信号进行预处理,避免因窗口过短影响后续的快速傅里叶变换(FFT);过程中可能还会加入降噪处理;
最后,通过FFT、梅尔滤波器组、输出对数转换、余弦变换等一种或多种方法,将信号划分为不同频段。在部分实现方案中,还会先对这些帧进行初步训练,以便深度网络能尽早识别与语言相关的帧特征。
不同系统会选择上述部分或全部技术,甚至引入其他技术,但核心在于:经过这些预处理后,端到端学习才会作用于这些转换后的输入信号。
此外,所有这些信号转换技术,最初都是为了实现人类语音的存储和远程传输而研发的。这些转换的关键意义在于,它们能让人类的听觉系统在无需调整的情况下,理解经过处理的语音信号。
3.2 图像标注
自2012年起,基于深度学习的图像标注技术,已成为计算机视觉领域解读图像内容的主流方法。但深度学习并非直接以相机输出的原始像素作为输入,而是通过两种方式借鉴了人类的生理机制(无需学习)。
相机输出的数据是线性排列的像素值——对于彩色图像,有时会是红、绿、蓝(RGB)三个独立的线性像素流。
现代数字相机采用全局(电子)快门:光线通过镜头进入相机后,会使一个矩形阵列的“电子桶”中产生电子,所有“电子桶”同时开始和停止收集电子;随后,这些“电子桶”中的电荷会转移到相邻的“桶”中,并通过模数转换器读取——本质上是读取特定“桶”中的电子数量,读取顺序通常是从左到右、从上到下(或其他类似顺序)。因此,无论是单色还是彩色图像,其原始数据都是一个或三个线性数据流。
但深度学习并不会直接处理这种线性数据流。相反,这些数据会被重新组织成一种数据结构——这种结构能还原原始像素的相邻关系,对于彩色图像,还会叠加三种颜色通道的信息。
当然,这在任何计算机图像处理中都是标准操作,但这一过程其实是人为施加的明确结构。动物的视觉系统并不会将图像“序列化”:视网膜中的每个“像素”(感光细胞)都会通过一条神经纤维连接到大脑皮层的扁平细胞阵列,视网膜中感光细胞的几何分布,会在大脑皮层中得到完整保留。
这种神经纤维的规则排列在出生前就已形成——视网膜中相邻感光细胞的局部兴奋信号,会引导神经轴突(即上述神经纤维)在大脑皮层中形成对应的局部连接,从而还原视网膜的空间分布。
随后,深度学习的前几层会采用一种特定结构,确保学习过程具备“平移不变性”——例如,图像左下角的猫和右上角的猫,能以完全相同的方式被识别。这种专用网络就是卷积神经网络(Convolutional Neural Network, CNN),一种专为处理大幅图像而设计的视觉处理结构。
在2015年5月27日《自然》杂志(需付费订阅)刊登的一篇题为《深度学习》(Deep learning)的文章中,作者扬·勒丘恩(Yan LeCun)、约书亚·本吉奥(Yoshua Bengio)和杰弗里·辛顿(Geoffrey Hinton)——这三位是2018年图灵奖得主——指出:
“首先,在图像这类阵列数据中,局部数值通常高度相关,会形成易于识别的独特局部特征;其次,图像及其他信号的局部统计特征具有平移不变性——换句话说,某个特征能出现在图像的一个位置,就可能出现在任何位置。因此,不同位置的神经元可以共享相同的权重,从而在图像的不同区域识别相同的模式。”
他们还提到,这种架构的灵感来自福岛邦彦(Kunihuko Fukushima)的研究——福岛曾研究手绘字符识别(早于反向传播算法),而多年后扬·勒丘恩也从事了类似研究(晚于反向传播算法)。我能找到的、福岛关于这一主题的最早英文非付费论文,发表于1979年在东京举办的国际人工智能联合会议(IJCAI),该论文共三页,收录于会议论文集第一卷第291页。【那是我第一次在国际会议上发表论文,我的论文也收录在同一卷中,主题是一种如今已被淘汰的古老图像目标识别方法。】
福岛表示,他的研究灵感来自戴维·休布尔(David Hubel)和托斯滕·威塞尔(Torsten Wiesel)对猫和猴子大脑皮层柱结构的研究——这两位研究者因这项工作获得了1981年诺贝尔奖,详见戴维·休布尔的诺贝尔奖演讲摘要。福岛在其模型中模拟了休布尔和威塞尔发现的“简单细胞”(S细胞)和“复杂细胞”(C细胞),并将两人提出的“超复杂细胞”进一步细分为模型中的两种亚型。这些模拟细胞能识别图像中任意位置出现的常见特征。
在上述《自然》杂志付费论文的图2中,你可以看到这种“交替层”结构的具体实现。正如勒丘恩等人所说:
“卷积神经网络的核心思路有四个,均利用了自然信号的特性:局部连接、权重共享、池化操作,以及多层结构。”
包括人类在内的动物,其视网膜感光细胞的分辨率存在差异——视网膜中央区域的感光细胞排列更密集,分辨率更高。许多动物(包括人类)会通过眼球的快速扫视运动(saccade),将视网膜的高分辨率区域对准图像的不同部分——你现在阅读这些文字时,就在做这样的动作:眼球沿行扫视,然后向下移动到下一行,在每个位置停留极短时间(移动眼球时,视觉系统会抑制运动感知,避免图像模糊)。
而用于深度学习视觉的大型卷积神经网络,通过“重复权重共享”实现了全图像高分辨率识别,从而无需依赖眼球扫视运动。
由此可见,这并非“纯粹的端到端学习”。深度学习图像标注的背后,是对人类大脑复杂结构的精细模拟——这种结构被植入学习机器中,形成了前端工程的核心。尽管人们热衷于宣扬“让系统自主学习,避免人类因选择错误结构而干扰学习过程”,但深度学习图像标注技术,本质上是建立在一套复杂精妙的前端工程之上,而这套工程正是对动物大脑中已发现结构的直接模拟。同时,它还依赖于我们研发的图像捕捉与传输技术——通过“序列化”图像,让人类视觉系统能理解远方或过去场景的图像。
3.3 大型语言模型
大型语言模型(LLMs)——例如ChatGPT或Gemini——的训练仅依赖大量文本数据,无需任何外部输入来解释文本含义。从这个角度看,似乎学习机制能自主理解所有信息。
然而,无论是在训练初期,还是后续处理输入文本时,都存在一些预处理步骤——这些步骤融入了人类语言的结构特征,以及特定语言的某些属性,同时还涉及内部表示的设计。这主要通过“令牌(tokens)”和“嵌入(embeddings)”两种机制实现。【当然,还有2017年提出的“Transformer架构”——包括多头注意力机制、“逐步追加输出并反馈至输入”等设计。这些由人类设计的大规模架构和工程,是大型语言模型能够工作的关键,进一步反驳了“无人类偏见的纯端到端学习”观点。但在本节中,我仅讨论与前两个领域类似的“数据预处理早期步骤”。】
特定语言的基本单位,会以“线性令牌序列”的形式输入大型语言模型。以英语为例,通常会使用约5万个不同的令牌,包括完整单词(如dog、cat)、前缀(如pre-、sub-)、后缀(如-ing、-ed)、常见词根(如marine、auto-)等。
在训练大型语言模型的最初阶段,会通过一种基本无监督的方式学习“令牌”:将大量目标语言文本输入令牌学习系统,系统会根据文本中字符组合的出现频率,生成可能的令牌候选,并统计其出现概率及与其他令牌的组合模式;随后,通过对令牌频率和“单词拆分合理性”的评分,自动确定最终使用的离散令牌数量。
令牌确定后,会通过一个小型程序(令牌解析器)将所有输入文本拆分为上述令牌序列。
接下来,这些令牌会被“嵌入”到一个高维向量空间中——该空间的维度通常为3×2ⁿ(n为固定值)。近年来,随着大型语言模型训练规模的扩大,n的值也在不断增加:ChatGPT-2的n为8,而ChatGPT-3的n则为12。
“嵌入”过程本身需要学习——即确定每个令牌在向量空间中各维度的坐标。这一步会通过“训练前的预学习”完成:系统会分析原始文本中“令牌在相似上下文环境中的替换模式”,从而确定令牌的嵌入方式。研究表明,这种学习会使向量空间的不同子空间(按向量空间的标准子空间定义)对应令牌的不同相似性维度——例如,在某个子空间中,“orange(橙色)”和“red(红色)”的距离可能比它们与“fruit(水果)”的距离更近;但在另一个子空间中,“red(红色)”可能成为离群值,而“orange(橙子)”和“fruit(水果)”则更接近。第一个子空间可能对应“颜色”属性,第二个子空间则对应“实体类别”属性。但这些分类并非由人类预先定义——无论是分类维度还是令牌间的距离,都是系统从数据中自主学习得到的。
n的值由大型语言模型的研发者在项目初期确定,这一选择取决于他们对云服务成本的承受能力——因为n会直接影响训练所需的数据量和待学习参数的数量。
一旦完成“嵌入”,大型语言模型神经网络的第一阶段就会将令牌解析器输出的每个令牌,转换为其在嵌入空间中的向量坐标。以ChatGPT-3为例(n=12),每个令牌会被转换为12288个数值。
由此可见,在大型语言模型的预训练过程中,人类的工程设计和知识发挥了重要作用——包括对“单词构成”的理解、对“语言含义相似性提取方法”的认知等。
从某种意义上说,令牌是“准符号”——但与传统符号不同,其核心价值不在于“独特标识”,而在于“与系统内其他准符号的相对关系”。此外,这些准符号基于人类语言的组成部分——即“书写”这一发明所定义的语言单元。书写使语言能够脱离声音和实时交互进行传播:无论何时何地,即使作者已去世,读者都能阅读文本。
3.4 端到端学习在三个领域中的共性
这三个端到端学习的成功案例,不仅依赖于特定领域的下游学习架构,还都依赖于“特定领域的早期数据预处理”。
更重要的是,这三个领域的早期预处理技术,最初都是为其他目的研发的——例如,语音预处理用于实现远程或异步的语音收听与理解,图像预处理用于实现远程或异步的图像观看与理解。
但在触觉领域,我们尚无这样的技术积累。目前,人类的触觉感知仅限于“即时直接感知”(并非双关语)——作为一个物种,我们尚未研发出能够“捕捉、存储、远程传输触觉信号”的技术,更无法将触觉信号回放给人类自身或其他个体。
在下文第4节中,我将说明触觉对人类灵巧性的核心作用。
若认为“无需理解触觉的构成要素、无需测量触觉信号、无需存储和回放触觉数据,就能教会机器具备灵巧性”,这种想法很可能是愚蠢的,也会导致高昂的错误成本。
四、 为何灵巧性的“目标”尚未破解?
我的核心论点是:那些被人们推崇为“重大突破”的暴力学习方法,其成功依赖于“针对特定场景、精心设计的前端工程”——正是这些前端工程从现实世界的原始信号混沌中,提取出了正确的数据。
既然这一规律适用于那些成功案例,那么对于“通过暴力学习实现灵巧性”,它很可能同样适用。若想在这一领域取得成功,研发者必须同时做到“收集正确的数据”和“学习正确的目标”。但目前大多数人形机器人灵巧性研发项目,两者都未做到。尽管一些学术实验室正在进行激动人心的探索,但尚未能接近“展示真正灵巧性”的目标。根据我的“机器人第三定律”——即便要实现“具备最低灵巧性的人形机器人首次商业化盈利部署”,我们仍需等待十年以上。
人类的灵巧性依赖于丰富的触觉感知,且人类的灵巧动作不仅涉及手部——通常还需要肘部、躯干前部、腿部和脚部的配合(许多机器都配有脚踏板)。我不会像撰写正式学术论文那样,在此进行全面论证,但会通过一组随机选取的、跨度达50年的权威同行评审研究成果,证明人类在灵巧动作中广泛依赖触觉和力感知。
4.1 人类的触觉感知极其丰富复杂
以下两个视频来自瑞典于默奥大学(Umeå University)罗兰·约翰松(Roland Johansson)的实验室——该实验室数十年来一直致力于人类触觉研究。第一个视频中,实验者从火柴盒中取出一根火柴并点燃,整个过程耗时7秒;第二个视频中,同一实验者再次尝试相同动作,但这次她的指尖被麻醉,无法感知指尖的触觉——她仍能感知手指和手部其他部位的触觉,以及骨骼肌系统通常能感受到的所有力。
若浏览器无法直接打开以下YouTube视频,可使用以下链接:
www.youtube.com/watch?v=zGIDptsNZMo
www.youtube.com/watch?v=HH6QD0MgqDQ


失去指尖触觉后,实验者多次尝试从火柴盒中取火柴均告失败;随后,她无法捡起掉在桌上的单根火柴;回到火柴盒前整理好火柴后,她终于拿起一根,但在调整火柴在指间的角度时频频失误;最终,她成功点燃了火柴,但耗时是指尖有触觉时的四倍。
这一实验表明,人形机器人要完成此类任务,必须具备触觉感知能力——而且这种触觉感知需要达到与人类指尖相当的精细度,绝非目前机器人手部常用的简单压力传感器可比。【我曾走访过美国、中国、日本、韩国、中国台湾和德国的100多家工厂,其中一些工厂生产我公司的五大系列机器人(Roomba、PackBot、Baxter、Sawyer和Carter),一些工厂采购我们的机器人以提高工人生产效率,还有一些工厂邀请我担任技术顾问。在这些工厂里,我亲眼目睹了人类用类似的灵巧动作完成各类复杂任务。】
一篇回顾约翰松1979年早期研究的文献指出,人类手部无毛皮肤(即不长毛发的皮肤)中约有1.7万个低阈值机械感受器,仅每个指尖就有约1000个,而手指其他部位和手掌的感受器密度则低得多。这些感受器分为四种类型(慢适应型与快适应型、小感受野型与大感受野型),当感知到压力施加或释放时,就会产生神经信号。
接下来,我简要介绍哈佛大学戴维·金蒂(David Ginty)实验室及其学生的研究。该实验室自1987年起发表的所有论文可在此查阅,其研究使命是:
“我们运用分子遗传学、解剖学、生理学、行为学和系统神经生物学方法,研究哺乳动物的躯体感觉神经元及支撑触觉感知的中枢神经系统回路。”
一篇总结金蒂近40年研究成果的新闻报道,对触觉的描述如下:
“触觉涉及多种刺激,包括戳刺、拉扯、气流、抚摸和振动,还包括不同温度和化学物质(如辣椒中的辣椒素、薄荷中的薄荷醇)。这些输入信号会让人产生压力、疼痛、瘙痒、柔软、坚硬、温暖、寒冷等感知,以及对身体空间位置的认知。”
报道还提到,目前已发现15种不同类型的神经元参与人类手部的触觉感知。
这些神经末梢具有高度特异性:皮肤表层有一种扁平的默克尔小体复合体(Merkel cell complex),能感知轻微按压,在嘴唇和指尖分布密集,使人能辨别物体的形状和纹理;指尖还布满呈螺旋状的迈斯纳小体(Meissner corpuscles),它们缠绕在支持细胞周围形成球状结构,能捕捉抓握物体时轻微滑动产生的微弱振动,让人能精准使用工具;皮肤深层有洋葱状的帕西尼小体(Pacinian corpuscles),可感知地面震动;还有纺锤状的鲁菲尼小体(Ruffini endings),能传递皮肤拉伸的信号。
触觉是一套极其复杂的传感与处理系统,它所提供的、与时间和运动相关的信息,远比简单的局部压力感知丰富得多。
除了触觉,人类在操控物体时还会依赖骨骼肌的力感知:骨骼肌能感知自身施加的力或外部施加于自身的力。肌梭(Muscle spindles)可检测肌肉长度及拉伸状态,而高尔基腱器官(Golgi tendon organs)能感知肌肉张力,进而感知施加在肌肉上的力。
此外,人类会通过视觉和触觉判断物体属性,进而调整操控时的姿势和力度。罗兰·约翰松(再次提及)的研究表明,人类会判断物体材质、估算密度,从而预测操控所需的力度;即便判断失误,也能迅速调整。
过去20年,罗兰·约翰松的研究重心转向“基于观察的预判在人类手部与身体任务策略选择中的作用”。他近20年的论文可在此查阅,部分论文标题如下:
《指尖粘弹性使人类触觉神经元能同时编码负载历史与当前力》
《人类触觉感受器对单条指纹纹路尺度空间细节的敏感性》
《学习手动任务中连续动作阶段关联时的注视行为》
《在体楔束核神经元中感觉量子的整合》
《技能学习涉及动作阶段关联的优化》
《人类指甲边缘的慢适应机械感受器编码指尖力》
这些研究表明,即便能精准测量手指位置(如前文2.2节提及的特斯拉最新数据收集策略),人类抓握动作的丰富性和多样性也远超简单的手指运动。
4.2 什么是“正确的数据”?
仅收集视觉数据,并非收集“正确的数据”。人类灵巧性涉及的诸多关键信息,都被视觉数据完全忽略。
除了Figure和特斯拉明确表示不会收集视觉以外的数据,其他大型公司对此均未表态(不过从哪些公司在招聘你的朋友,大致能判断出有多少大公司在研发人形机器人)。
但在学术界,仍有不少颇具前景的实验正在开展。例如,2025年5月在“机器人系统与科学会议”的“人类灵巧操控研讨会”上,麻省理工学院计算机科学与人工智能实验室(CSAIL)普里特克·阿格拉沃尔(Pulkit Agrawal)团队的研究获得“最佳论文”。该研究提出了一种新型数据收集方法,可为人形机器人灵巧性学习提供“正确的数据”。
如下图所示,实验者需将手伸入一只手套,手套上固定连接着一个机器人手——机器人手与人类手部相距约10厘米,且完全平行。实验者通过活动自己的手指来控制机器人手的手指,通过移动自己的手臂来调整机器人手与待操控物体的接触位置。
机器人手的手指和手掌装有触觉传感器,传感器数据一方面传输至数据收集系统,另一方面传输至致动器,致动器会刺激实验者的指尖和手掌。
尽管该系统无法记录人类手臂直接感知和控制的力,但能将人类的手指动作与“人类在决定如何控制机器人手时所感知的触觉信号”关联起来。

显然,该系统距离理解人类复杂触觉与力感知系统的全部功能仍有很大差距,但它已超越“仅收集视觉数据”的局限——仅靠视觉数据,绝不可能推断出实现灵巧性的方法。
【若那些向大规模人形机器人训练投入巨资的科技巨头和风险投资公司,能将20%的资金投入高校研究,我认为他们或许能更快接近目标。】
4.3 什么是“正确的学习目标”?
最后,我想回到本节(第4节)开头提到的“学习正确目标”的必要性。
目前,工业界和学术界采用的学习框架均源于强化学习(见前文第3节引言部分)。在强化学习中,学习的核心是“策略(policy)”——即根据传感器当前传递的“状态”,映射出机器人当前应执行的特定动作。
但从个人经验及上述触觉研究者的论文来看,人类在进行灵巧动作时,往往会先制定“任务目标规划”。传感器感知到的信息并非直接映射为动作,而是可能用于调整“遵循规划的执行过程”(或许可表示为有限状态机)。因此,要真正实现灵巧性,不仅需要学习“如何在子任务空间中规划”,还需要学习“触觉层面的感知如何调整这些规划”。
要解决这些问题,仍需大量研究;之后还需数年时间实现可靠的实验室演示,再经过数年才能开发出可部署、能为客户创造价值的系统。
五、人形机器人的另一大难题:行走安全
鉴于人形机器人的设计目标是“采用人类形态,以便在为人类打造的环境中工作”,人们自然会期望它们“在身边活动时是安全的”——对于在家庭中为老年人提供医疗护理的人形机器人而言,这一点尤为重要。
但根据人形机器人的总体规划,在其他环境中也需满足这一要求,因为其核心理念就是“融入人类空间”;而这意味着人类会与它们共享空间,否则直接研发专用的无人化机器完成任务即可,无需人形机器人。
因此,若要大规模部署人形机器人,关键在于确保人类能与其安全共享空间——例如,人类可在仅距其数厘米的范围内活动,可倚靠它们支撑身体,可被它们触摸和协助(就像人类护工协助老年人站立、洗漱、如厕、上下床等)。
但问题在于,当前与人类等大的双足行走人形机器人,对人类而言并不安全。而人形机器人的设计逻辑要求它们必须与人类等大,才能在人类空间中活动、完成人类的所有任务。
或许你会说:“我见过半尺寸人形机器人的视频,甚至曾在数厘米内靠近过它们(我就有过这样的经历),感觉很安全。所以,只需再花一点时间,就能把它们放大到人类尺寸。”但物理学规律会在此给我们泼冷水。
当前人形机器人的行走方式与人类截然不同。人类的身体是“富有弹性的弹簧式系统”,即便没有复杂的神经控制,也能维持行走状态。事实上,你可以看到纯机械结构的双足行走模型——无需电源,仅依靠自身的被动动力学,就能沿缓坡下行,通过“下山时获取重力势能”为行走提供机械动力。
以下是一个简单示例:
视频链接:www.youtube.com/watch?v=wMlDT17C_Vs

除了这种基础结构,人类的肌肉和肌腱还构成了“能量回收系统”——肌腱会储存能量,并在下一步行走时释放。例如,小腿后侧的跟腱是储存能量最多的部位,也是最容易断裂的部位。
尽管学术界已花数十年时间研发“类人行走机器人”,但这些研究尚未达到当前人形机器人设计的实用水平。
当前人形机器人主要依靠大功率电机维持平衡——当检测到失衡时,会向系统注入大量能量,其核心算法大多基于零力矩点(ZMP,Zero-Moment Point)算法的改进版。【该算法历史悠久:2004年,在本节开头提及的《国际人形机器人期刊》第1卷第157页,塞尔维亚和黑山的米奥米尔·武科布拉托维奇(Miomir Vukobratović)与布拉尼斯拉夫·博罗瓦茨(Branislav Borovac)发表论文,纪念该算法问世35周年,如今算来,该算法已有约56年历史。】
尽管研发人形机器人的大公司对具体技术细节讳莫如深,但他们似乎在ZMP算法基础上加入了强化学习(RL),以提升行走稳定性、减少摔倒次数。ZMP算法依赖脚底的力传感器,因此所有人形机器人都配备了这类传感器。但强化学习算法要求机器人整体结构“刚性极高”——这与人类行走时的机械结构完全相反。即便这些机器人摔倒次数减少,一旦摔倒,对附近人类仍极具危险性。
行走时若检测到失衡,机器人会注入能量以恢复平衡,之后通过腿部在数百毫秒内反向蹬地,释放多余能量——这种情况是安全的。但如果机器人真的摔倒,其腿部会携带大量自由动能,在空间中快速加速;若有物体挡在前方,会被金属材质的腿部重重撞击;若被撞击的是生命体,往往会受伤,甚至可能受重伤。
你可能会反驳:“半尺寸人形机器人很安全,那全尺寸机器人能危险到哪里去?”
这里涉及的是物理系统的“缩放定律”,而非机器人数量的规模化。
若将一个物理系统的所有维度按比例系数s放大,其质量m会按s³的比例增加。根据牛顿第二定律F=ma,要产生相同的加速度,所需能量需按s³的比例增加。例如,放大50%的机器人,能量需求会变为(1.5)³=3.375倍;若要将当前“相对安全的小型机器人”放大到人类尺寸(比例系数2),能量需求会变为2³=8倍——这会带来完全不同级别的潜在伤害。情况甚至可能更糟:以肢体为例,其质量按s³增加,但决定强度的横截面积仅按s²增加。【这就是为何大象的腿相对于身体尺寸,比蜘蛛的腿粗得多——即便蜘蛛有八条腿支撑体重,也仍遵循这一规律。】因此,放大两倍的机器人可能需要按比例加粗腿部,导致质量进一步增加,能量需求可能会超过8倍。
我的建议是:不要靠近全尺寸行走机器人3米以内。研发行走机器人的公司也深知这一点——即便在他们发布的视频中,也不会出现“人类靠近行走中的人形机器人”的场景,除非两者之间有大桌子隔开;即便如此,人形机器人也只是小幅挪动。
除非有人能研发出“更安全、可近距离接触”的双足行走机器人,否则人形机器人将无法获得在“有人区域”部署的认证。
六、人形机器人的未来走向
技术在发展,与技术相关的词汇含义也会随之变化。
2018年1月1日,我曾对未来技术做过一系列预测,当时“飞行汽车”和“自动驾驶汽车”的含义与如今截然不同。在最近评估这些预测的“成绩单”中,我也指出了这一点。
过去,“飞行汽车”指“既能在公路上行驶,又能在空中飞行的交通工具”;如今,它指“电动多旋翼直升机”——可像出租车一样在固定起降点之间飞行,且常被宣传为“无人驾驶”。这类交通工具被称为eVTOL(电动垂直起降飞行器)。但实际上,eVTOL目前尚无实用化产品,且已不再是“汽车”——因为它无法在地面行驶。
当时,“自动驾驶汽车”指“无需人类进一步操控,就能自主驶向指定目的地”;如今,“自动驾驶汽车”的定义变成了“驾驶座上无人,但可能有人类在远程监控(目前已部署的所有案例均如此),且监控者会偶尔发送操控指令”。特斯拉的自动驾驶出租车是个例外——其副驾驶座上会配备人类安全操作员。
遵循这一规律,“人形机器人”的定义也会随时间变化。
在不久的将来(目前已显现端倪),人形机器人的“脚”会被轮子取代——最初是两个轮子,之后可能更多,其腿部形态将不再与人类有任何相似之处,但它们仍会被称为“人形机器人”。
随后,会出现“单臂、双臂、三臂”等不同版本:部分手臂会配备五指手,但更多会采用两指平行夹爪抓取器,有些可能会使用吸盘——但它们仍会被称为“人形机器人”。
再之后,会出现配备“非被动摄像头传感器”的版本:它们的“眼睛”可能使用主动光成像,或能感知人类不可见的频率范围;手部可能装有“眼睛”,甚至在身体下部装有“向下看的眼睛”,以更好地观察地面、适应不平坦地形——但它们仍会被称为“人形机器人”。
未来会出现大量“为特定人类任务设计的专用机器人”,形态各异,但都会被称为“人形机器人”。
而如今,人们为“从当前人形机器人中榨取性能”投入的巨额资金,最终会付诸东流;这些机器人也会被淘汰,大多被轻易遗忘。
这就是未来15年人形机器人的发展图景。
作者:罗德尼·布鲁克斯,著名机器人专家,是iRobot公司的联合创始人,曾在麻省理工学院(MIT)工作数十年。


