

部署超大规模 MoE 这件事,国产芯片的推理性能,已经再创新高了 —— 不仅是“英伟达含量为 0”这么简单,更是性能全面超越英伟达 Hopper 架构!

而做到这一点的,正是华为昇腾;具体而言,共包含两个产品:
CloudMatrix 384 超节点
:部署 DeepSeek V3 / R1,在 50ms 时延约束下单卡 Decode 吞吐突破 1920 Tokens/s
Atlas 800I A2 推理服务器
:部署 DeepSeek V3 / R1,在 100ms 时延约束下单卡吞吐达到 808 Tokens/s,可支持灵活的分布式部署
之所以能够这般,是因为华为昇腾所采取的“以数学补物理”—— 这种通过数学理论、工具、算法和建模等方式,来弥补硬件和工艺的局限性,实现最大化发挥芯片和系统能力效果。
华为昇腾还不只是“官宣”一下而已,后面更会是全面开源。
不仅已经将昇腾在超大规模 MoE 模型推理部署的技术报告分享了出来,在一个月时间内,还会把实现这些核心技术的相关代码也都会陆续开源出来。
那么接下来,我们就来深入了解一下华为昇腾背后的技术实力。
在华为昇腾上推理 DeepSeek
在深挖华为昇腾背后技术创新之前,我们且需了解一下为什么要这么做。
从 2017 年 Google 提出的 Transformer 架构,到 2025 年 DeepSeek V3 / R1 的爆红,大语言模型的重心正在从训练开发转向推理应用落地。
推理能力不仅是大模型能力的“试金石”,各大企业已从“拼模型参数”转向“拼推理效率”:
谁能让大模型在实际应用中跑得更快、更稳、更省资源,谁就能在商业化浪潮中抢占先机。
然而,以 6710 亿参数的 DeepSeek V3 为例,这类超大规模 MoE 模型虽然强大,却给硬件带来三大“成长烦恼”:
内存压力山大:一个模型包含 257 个专家,每个专家“体重” 2.5G,普通 64GB 内存的 AI 硬件根本“扛不动”,必须依赖集群协作。
通信开销爆炸:专家分布在不同芯片上,数据传输耗时甚至超过计算时间,就像团队成员频繁开会沟通,效率大打折扣。
架构创新的“甜蜜负担”:例如“多头隐式注意力机制(MLA)”虽然压缩了数据空间,却导致中间变量激增,对芯片的计算能力提出更高要求。
流程重构
:将投机模型后置於主体模型,直接复用主体模型的输出结果与控制参数,大幅减少框架耗时,完美适配参数-数据分离(PD 分离)的分布式部署架构;
轻量步间优化
:对投机推理场景中的框架和算子优化实现了轻量步间准备,适配多核并行的全异步框架。
计算通信并发
:通过 Gate 函数计算与 AllGather 通信的解耦,结合共享专家的数据并行(DP)策略,利用昇腾多流机制实现计算与通信的并发执行,最大化硬件利用率;
通信通信并发
:针对 DeepSeek 模型的量化场景,将激活值与 scale 的传输任务并行处理,在不增加带宽压力的前提下掩盖小数据量通信的启动开销;
通信和权重预并发
:利用通信阶段 HBM 带宽低占用特性,提前将后续算子权重预取至缓存,降低计算阶段的数据搬运开销,实测 MLA 层计算性能提升 10%。
算法重构:提出 AMLA 算法,通过二进制编码与存内计算,将乘性计算转换为加性等价形式,直接在全局内存完成输出更新,减少数据搬运耗时;
缓存策略:通过 L1 / L2 缓存精细化管理与 K-buffer 流水排布,提升缓存命中率与计算效率,实现张量计算与向量计算的相互掩盖;
前序算子融合:在 Prefill 与 Decode 阶段分别采用双流并发与算子融合技术,结合权重预取、分块策略及定制指令集优化,构建端到端高效计算链路。
通算融合算子:针对 EP 部署模式下 MoE 专家的跨卡调度难题,设计 MoeDistributeDispatch / Combine 算子,通过 Token 粒度的流水排布与内存语义通信技术,将通信与计算并行化,减少卡间同步开销;
SMTurbo-CPP 技术:针对小数据量通信效率问题,通过读写混合、聚合流水等硬件并发技术,提升 AllToAll (v) 算子的吞吐能力,降低 Dispatch / Combine 场景时延;
细粒度分级流水算法:基于 Atlas 800I A2 组网特性,实现节点内 / 节点间的集合通信并发执行,大幅提升集群环境下的带宽利用率。
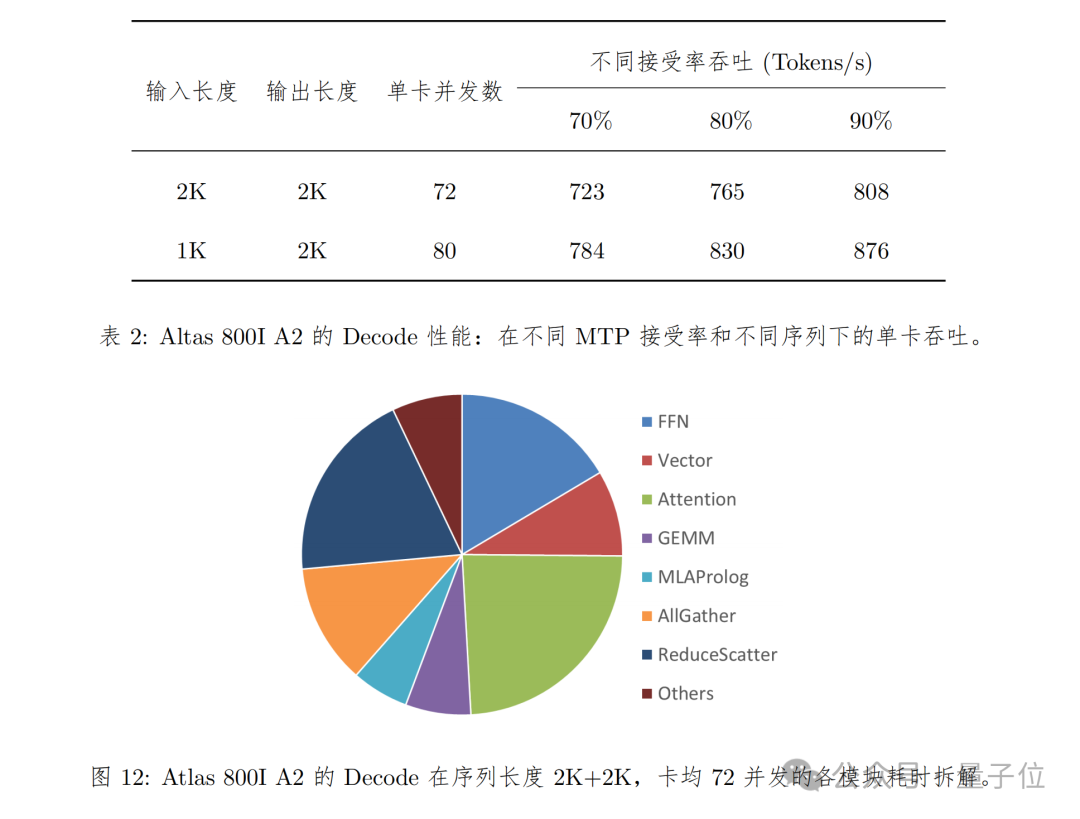
序列长度为 2K 输入 + 2K 输出和 1K 输入 + 2K 输出两种情况
在使能 MTP 进行推理加速的情况下,由于不同测试数据集和业务场景的 MTP 接受率不同,性能测试结果会有比较大的偏差。因此在计算时延和吞吐的时候默认按照 70% 接受率来折算。
TPOT(Decode 平均每 Token 时延)不超过 100ms。
面对这些挑战,华为团队从算子、模型和框架三方面入手,基于昇腾硬件特性,开发了一整套面向集群的大规模专家并行解决方案。
在硬件部署上,华为团队根据不同硬件配置 ——CloudMatrix 384 超节点和 Atlas 800I A2 推理服务器,针对性地采取了不同的部署优化策略。为解耦 Prefill 和 Decode 阶段的时延约束,昇腾采用 PD 分离部署方式。
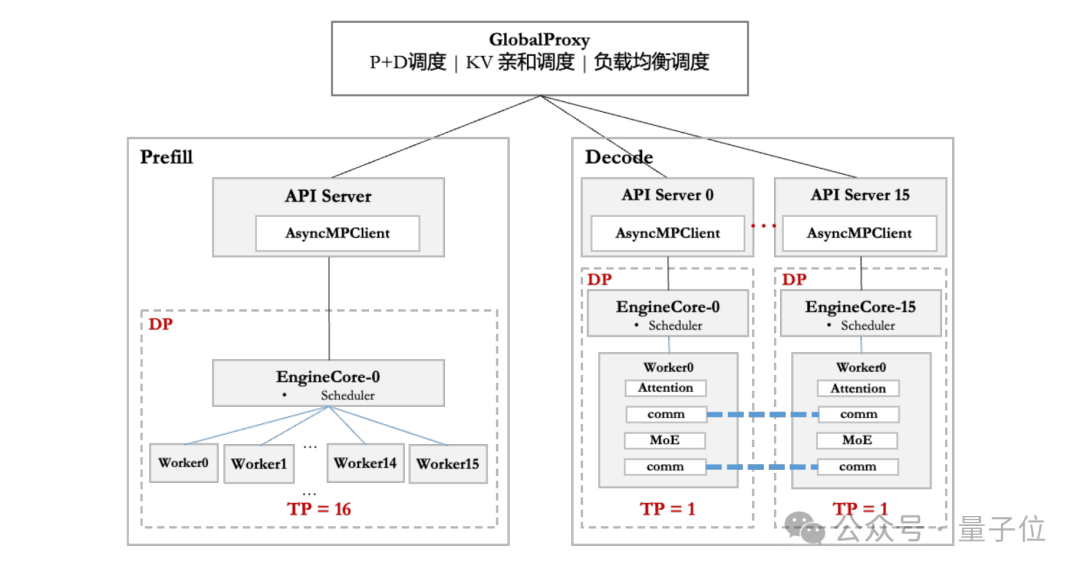
在框架侧,昇腾基于 vLLM 框架,适配 DP 和 EP 等多种并行策略,通过 Prefill 调度分桶、灵衢互联与分层传输等技术来降低调度开销,优化请求下发、调度策略等环节,提升系统性能。
在模型方面,昇腾采用 A8W8C16 量化策略,其中 A8W8 使用 INT8,C16 使用 BF16,并针对不同机型进行差异化部署。
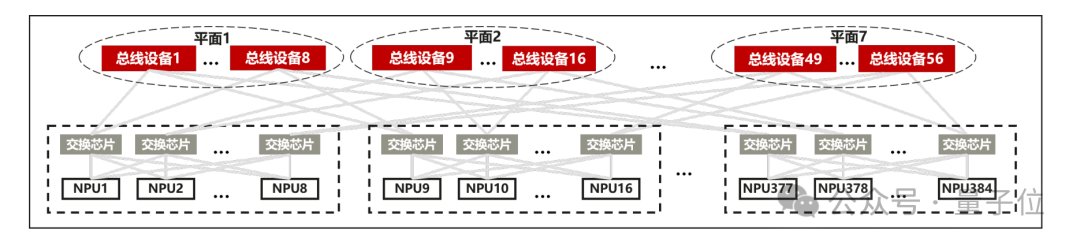
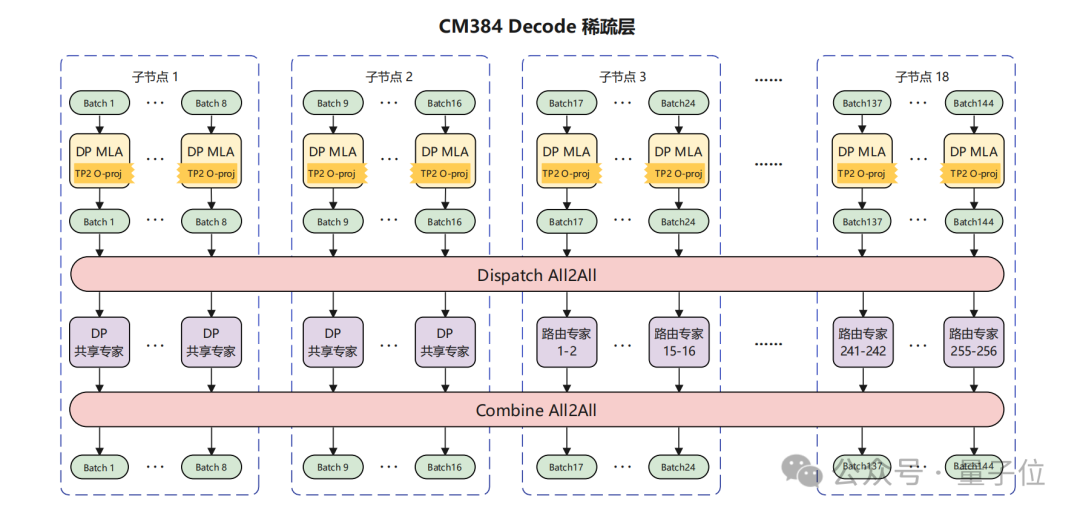
针对 CloudMatrix 384 超节点,其强大的组网能力大幅降低了通信耗时,释放了昇腾芯片的算力。
团队采用大规模 EP 并行部署,Prefill 使用 16 卡,Decode 使用 144 卡,其中 128 卡部署路由专家,16 卡部署共享专家,MLA 部分采用 DP 部署。
尽管存在时延约束、带宽抢占、调度开销、负载不均等因素影响,最终在 50ms 时延下,单卡 decode 吞吐达到 1920 Token / s。
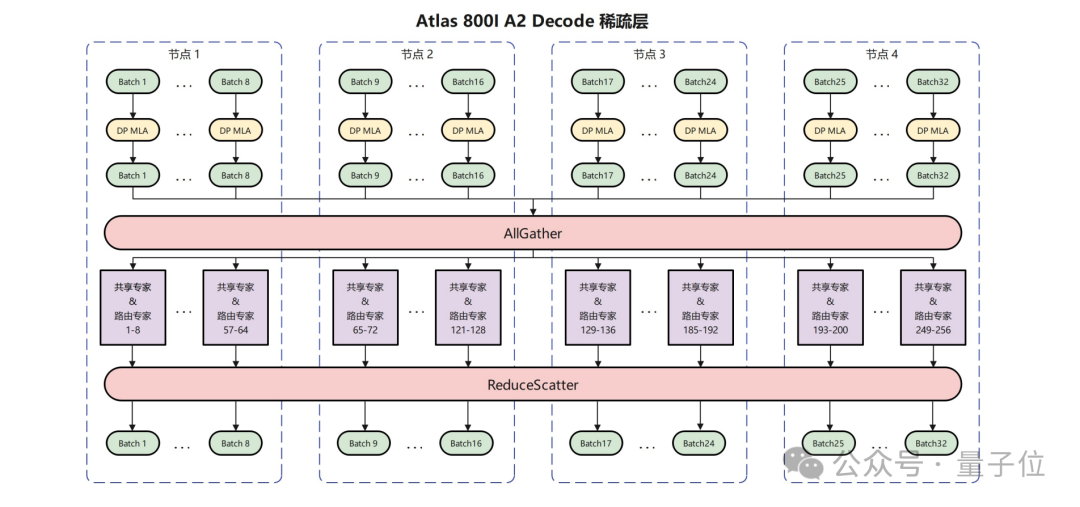
针对机群规模较小但部署更加灵活的 Atlas 800I A2 服务器,华为团队采用多节点互联的方式进行部署。
作为示例,华为团队使用 2 机 16 卡进行 Prefill,4 机 32 卡进行 Decode,每卡部署 8 个路由专家和 1 个共享专家,MLA 部分采用 DP 并行,并针对性地使用在真实负载下性能更优的 AllGather / ReduceScatter 的通信方案。
通过各种策略优化,在 100ms 时延下,单卡吞吐达到 808 Tokens / s。
还有更多优化技术
在推理框架优化方面,针对高并发场景下单点 API Server 这一性能瓶颈,华为团队设计了 API Server 横向扩展方案,采用水平扩展技术提升框架的请求响应能力,显著降低用户请求延迟并提高整体服务吞吐量(QPS)。
针对 MoE 模型中的负载不均问题,基于动态调整专家部署与缩小通信域、热专家冗余部署、实时调度与动态监控机制等核心技术,降低显存占用的同时实现动态负载均衡。
在投机推理技术的工程化应用中,如何将其从小批量低时延场景扩展至高吞吐量场景,是行业面临的共性难题。
华为团队基于昇腾芯片高计算带宽比的硬件特性,提出 FusionSpec 投机推理引擎,针对性优化多 Token 预测(MTP)场景下的推理性能:
在通信优化方面,华为昇腾也有三大妙招。
首先,针对主流张量并行(TP)方案中 AllReduce 通信的固有缺陷(通信次数多、数据量大、冗余计算显著),华为团队推出 FlashComm 通信方案,通过集合通信逻辑重构与算子位置编排,实现低比特、低维度数据通信,在降低通信时延的同时消除冗余计算,最终实现 25% 通信量的降低和 10% 推理性能的提升。
其次,在 FlashComm 基础上,团队进一步提出层内并行转换方案,针对 Prefill 阶段的 MLA 层,通过张量并行(TP)与数据并行(DP)的灵活转换,消除节点内卡间求和操作,并利用网络低维特性与量化技术压缩通信数据量,显著降低跨卡通信时延,为大模型分布式推理提供更高效的通信支撑。
第三,通信方面的优化还有一个并发机制的深度挖掘,包括:
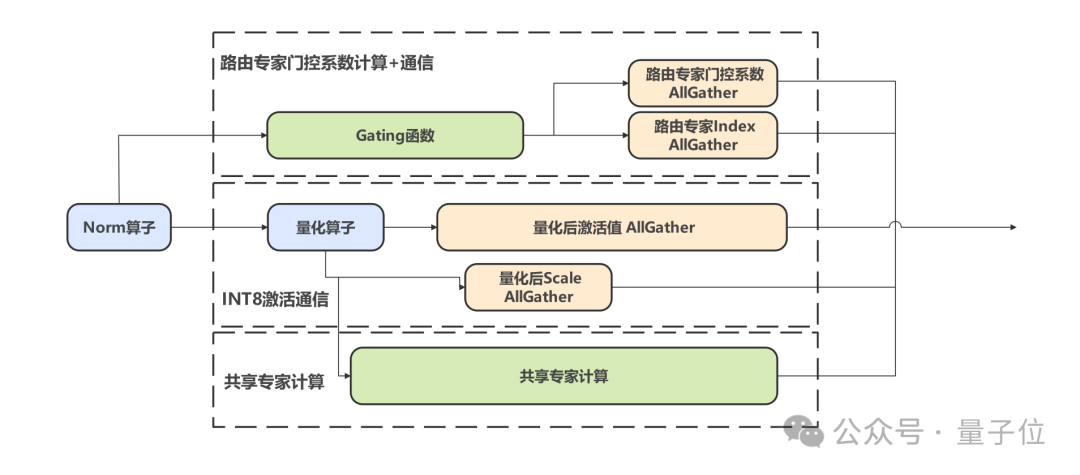
最后,就是在算子方面的优化了。华为团队通过以数学补物理,发展了一系列的优化技术。
针对 MLA 算子中间变量膨胀与计算量激增的挑战,团队开展硬件亲和性优化:
MoE 算子方面的优化则包括:
性能创新高
在 Decode 性能测试方面,Atlas 800I A2 所采用的方式是:
具体表现如下所示:
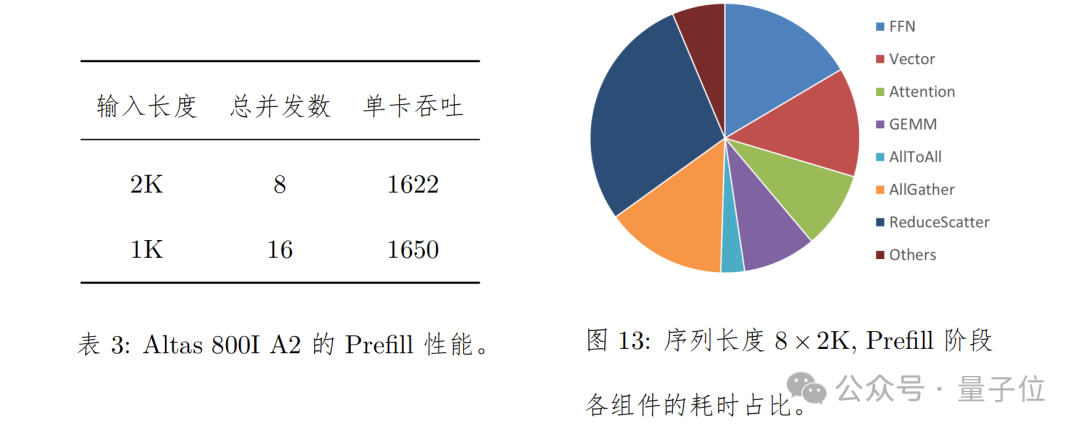
在 Prefill 上的测试方法是,单 batch 输入序列长度为 2K / 1K,通过拼 batch 的方式拼成一共 16K 序列。对于序列长度是 2K,共 8 batch 拼成一共 16K 序列的场景,端到端耗时为 631ms,卡均吞吐为 1622 Tokens / s。
具体表现如下图所示:
在 2025 年 4 月,硅基流动联合华为云基于 CloudMatrix 384 超节点昇腾云服务和高性能推理框架 SiliconLLM,用大规模专家并行最佳实践正式上线 DeepSeek-R1。
该服务在保证单用户 20 TPS (等效 50ms 时延约束) 水平前提下,单卡 Decode 吞吐突破 1920 Tokens / s,可比肩 H100 部署性能。

而也正如我们刚才提到的,昇腾在超大规模 MoE 模型推理部署的技术报告分享了出来了,想要更深入了解的小伙伴,可以在文末链接中自取哦。
One More Thing
就在本周,华为昇腾还将举办一个技术披露周!
大家可以关注 https://gitcode.com/ascend-tribe/ascend-inference-cluster/ 中每天的上新。
具体详情放下面喽,小伙伴们可以蹲一波了~

完整技术报告:
https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/Overview/%E5%8D%8E%E4%B8%BA%E6%98%87%E8%85%BE%E6%9C%8D%E5%8A%A1%E5%99%A8_DeepSeek_V3_R1_%E6%8E%A8%E7%90%86%E9%83%A8%E7%BD%B2%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.pdf
技术博客:
https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/Overview/ascend-inference-cluster-overview.md
本文来自微信公众号:量子位(ID:QbitAI),作者:金磊,原标题《华为 + DeepSeek,推理性能创新高!技术报告也公布出来了》
