
这两年我用 AI 写代码,心态上其实一直有点跌宕起伏。
最开始看到一句话的指挥就可以生成还比较像样的结果,会叫人特别兴奋。Cursor、Claude Code、Codex 这些工具出来之后,也在尝试地做一些东西。
不过一段时间后,兴奋感会下降。因为在很多细节的地方,如果不是自己手搓的话,依然会面临想改但无从下手的时刻。尤其是在遇到疑难杂症 bug 的时候,代码不是自己写的,改起来会非常痛苦。常常是花一两天时间把基础框架都写好了,但是要花两个星期去优化细节和修改 bug。
再回头看,当然还是一直有兴奋感的。像我自己也做了两个自己用起来挺开心的 APP。
然而我一直觉得,当 coding 的门槛不断降低之后,它的意义不在于代替程序员写代码,或者让独立开发者成本更低的开发产品,而是对于很多愿意动手的人来说,可以自己通过 coding 解决很多个性化的问题。
就像是手机刚出现的时候,大家都会觉得只有做生意的人才需要用手机。等到手机足够普及、大家也都在用手机通话和发短信之后,大家又会觉得,只有专业的媒体人才需要用手机创作内容。而很快,大家就都开始发朋友圈、发微博、发小红书了。
写代码这件事也在经历类似的变化。
过去代码是一种职业技能,而现在模型能力以及围绕模型能力搭建的产品体验,可以让代码变成普通人能调用的能力。当我们使用这个模型,做一些轻量的脚本和程序的时候,并不是要把它们正式发布或者上线,而是就是属于自己的一个小工具、小网页。
在之前,能够满足这样基础使用体验的模型,基本都是海外的。现在,豆包 2.1 Pro 真的达到了一个阈值:可以放心给大家推荐,值得每个人都试用一下了。
按照字节跳动 Seed 团队公开发布的信息,Seed 2.1 Pro 这次重点强化的就是 Coding Agent 的端到端交付能力,也就是从需求理解、功能实现、Bug 修复、运行环境搭建到结果验证的完整链路,而不是只看一段代码能不能写对。
当然跟海外最强的模型比还有一定差距,但是它真正进入了一个可以认真比较的阶段,上了牌桌了。
再加上火山引擎公开的价格是每百万 Tokens 输入 6 元、输出 30 元、缓存命中 1.2 元,官方称综合使用成本较 Claude Opus 4.6 降低近 80%,这就让它不只是一个能跑分的模型,而开始变成一个普通用户和开发者都可以、也大概率会高频尝试的 Coding 工具。
我今天随手做了几个小玩具,大家可以感受一下。
我是在 TRAE Work 上试用的。
1
先讲一个比较好玩的:半拿铁歇后语扭蛋机。
这个需求说起来很简单。我想做一个网页扭蛋机,每次点击按钮之后,掉出一个歇后语。歇后语最需要是半拿铁节目里常出现的那些歇后语。
做出来的效果大概是这样的。
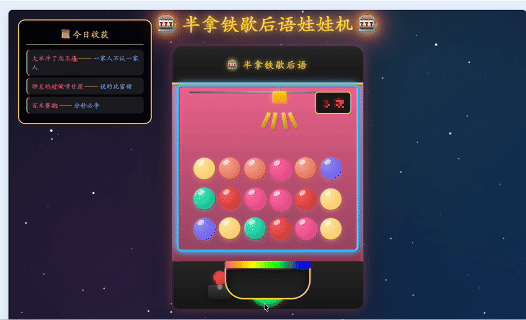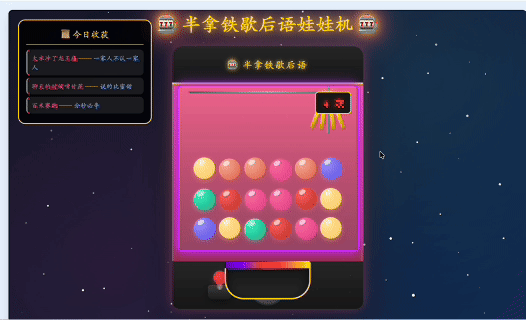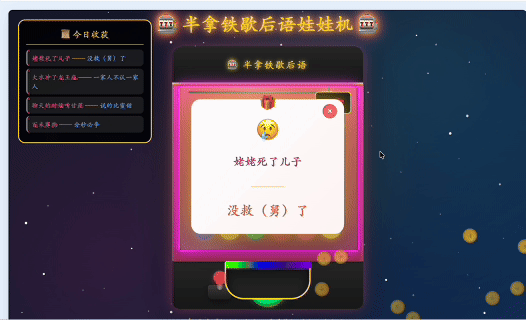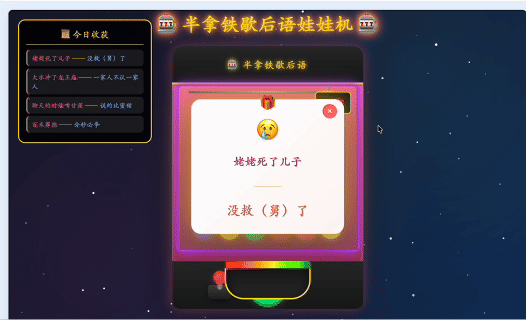
第一版出来之后,是一个霓虹赛博风的娃娃机。深紫色背景、粉色机器、霓虹灯边框、金币雨、粒子爆炸,很热闹。不过说实话,还是有点丑的。
所以我让他改了一个版本,整体上更加素雅。
它变成了一个日式ガチャガチャ风格的拟物扭蛋机。背景从深紫霓虹改成米灰色渐变,机器主体是奶白色塑料质感,玻璃球罩里堆着马卡龙色扭蛋,投币口有金属凹槽,旋钮点击时会真实旋转,扭蛋掉到取物口时有弹性回弹。
这个当然也有优化空间,但是比刚才的版本来说,要好看太太太太多了。
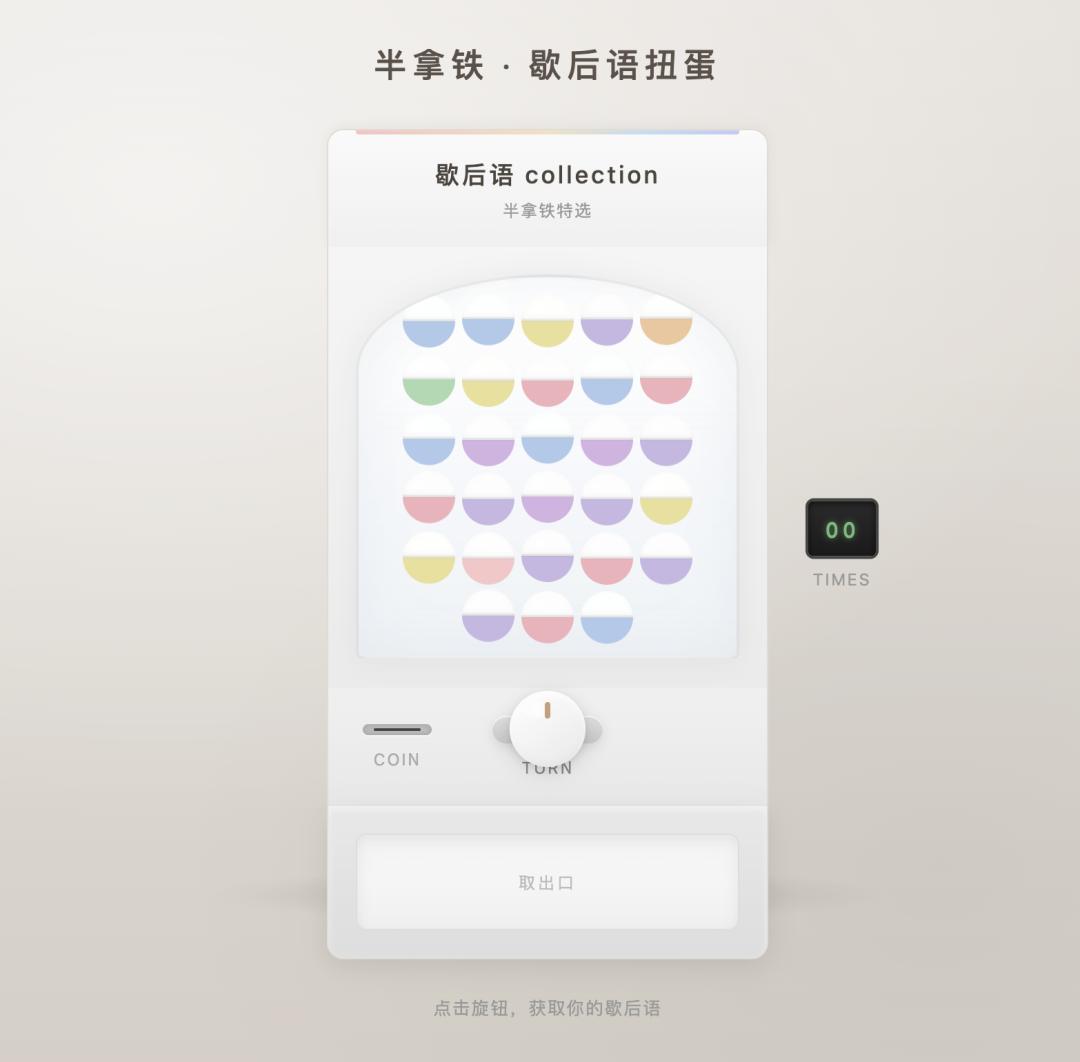
这个过程里面,如果只是简单跟它说,好看一点,效果其实并不好,需要详细跟它说怎么改。
所以这就要求,当我们想要做一个东西出来的时候,内心里得有一个大概的「画面」。这件事特别关键。
而 AI coding 的模型的意义就在于把这些画面实现出来。现在我们不需要再用复杂的方式,还要找设计师和程序员去完成。
2
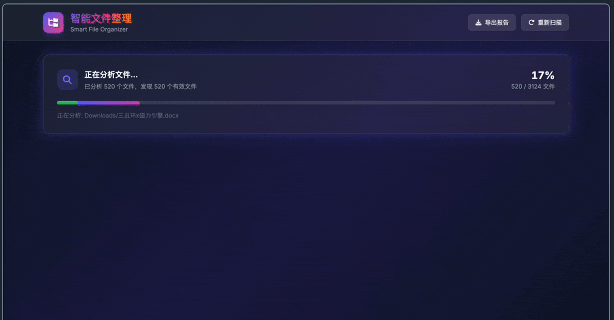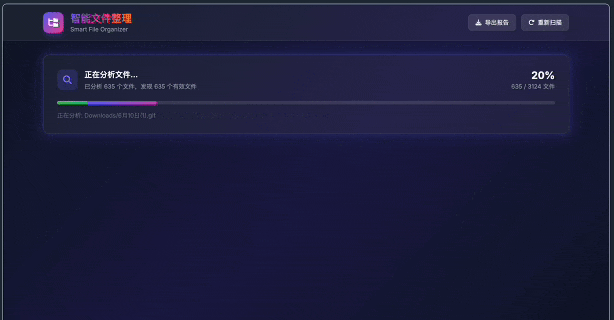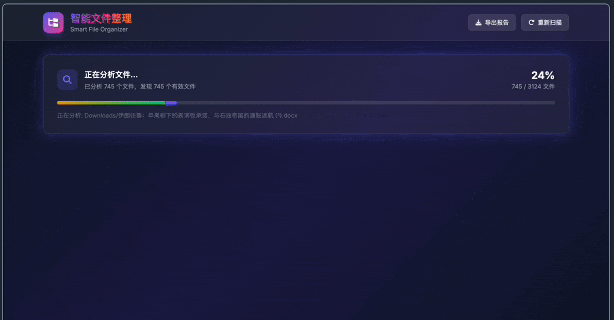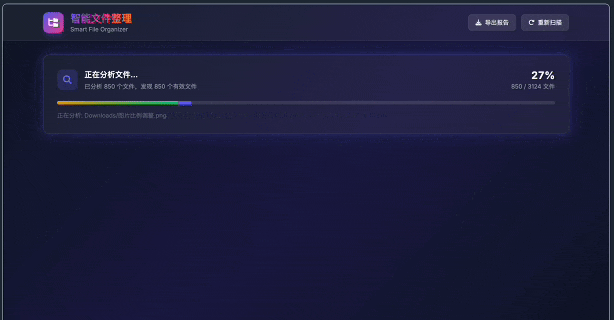
第二个例子是:智能文件整理工具。
这个需求想必很多朋友都有。
我自己的电脑里总有一个特别混乱的下载文件夹。里面有 PDF、截图、录音、视频、压缩包、合同、发票、临时文件、播客素材。理论上可以手动整理,每次手动整理都会非常烦躁,懒得整理。每次系统空间不足了,得花大半天时间去折腾。这个文件夹可以称之为信息沼泽。
我跟豆包2.1 Pro 说的是:扫描一个文件夹,自动识别里面的文档、图片、音频、视频、压缩包,但不只是按后缀名分,而是尽量读取文件名、文件类型、路径、元数据、文档内容,判断它更像播客资料、商务合同、发票票据、图片素材、临时下载,还是可删除大文件。最后用一个视觉清晰漂亮的页面展示出来。
当然,只说这个需求的话,大家可能会提到有一些空间整理的软件了。但是这里我可以给出非常个性化的要求,比如像刚刚提到的,对音频的处理、对播客素材的处理,我会给的更细。肯定不会有人做专门给播客主播的整理软件的。
每个人的文件夹混乱方式不同,每个人的整理规则也不同。
豆包 2.1 Pro 的实现方式是多层检测。
它不只是看后缀名,而是读取文件头 16 字节做 Magic Bytes 检测,用来识别 JPG、PNG、GIF、ZIP、RAR、7Z、PDF 等真实文件类型;再结合浏览器 File API 的 MIME 类型,判断 audio、video、image、application 这些大类;然后再根据后缀名、文件名关键词、所在路径、文档内容前 4KB 做进一步判断。
分类上,它做了一个加权评分机制。比如文件名里有“合同”“协议”“甲方”“乙方”,就提高商务合同分类的分数;内容里出现“增值税”“发票”“报销”,就提高发票票据分类的分数;路径在“下载”“临时”“缓存”里,就提高临时下载的分数;超过 100MB 的大文件,又会进入可删除大文件的判断。
页面上,它不是给一个简单列表,而是做了统计面板、分类图表、筛选标签、搜索框、排序功能、文件预览和报告导出。点击某个文件,可以看到大小、类型、修改时间、分类标签,以及分类匹配分数。图片还能直接预览。所有分析都在浏览器网页里本地进行,不需要把文件上传到服务器,这一点也很重要。
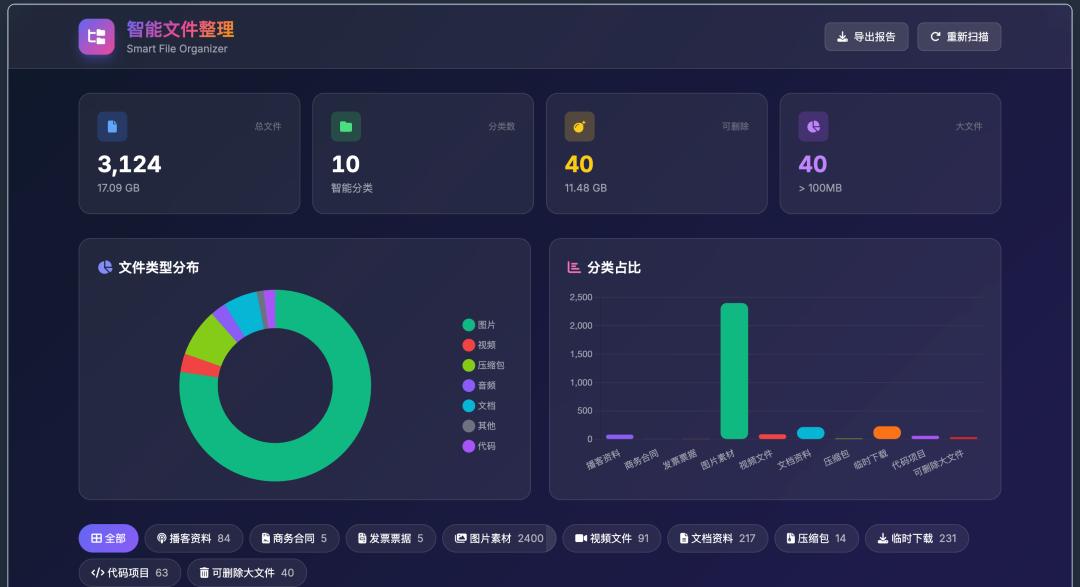
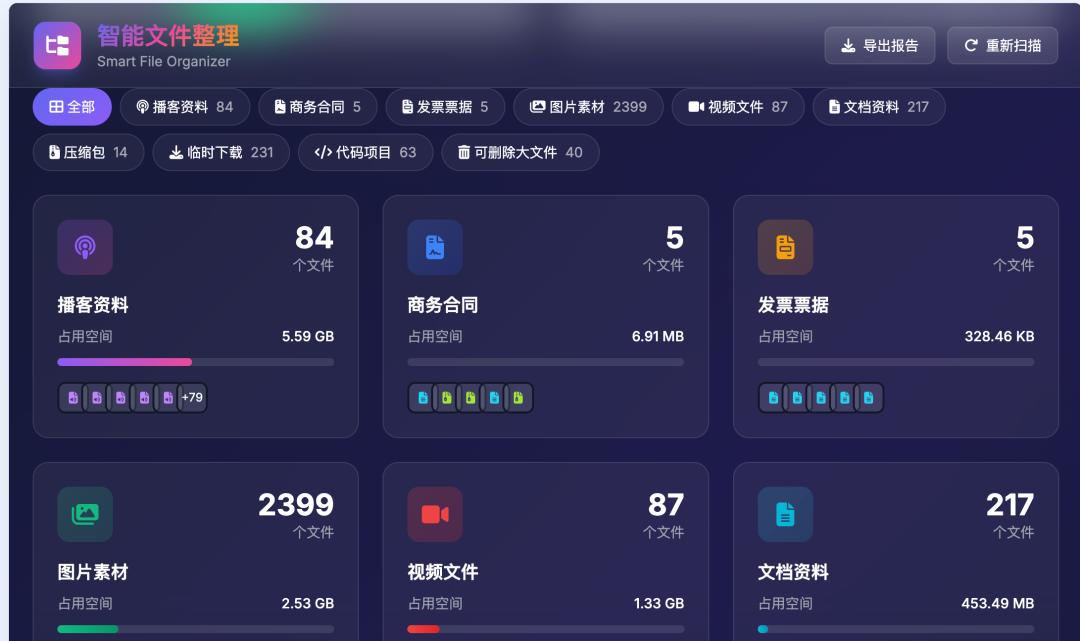
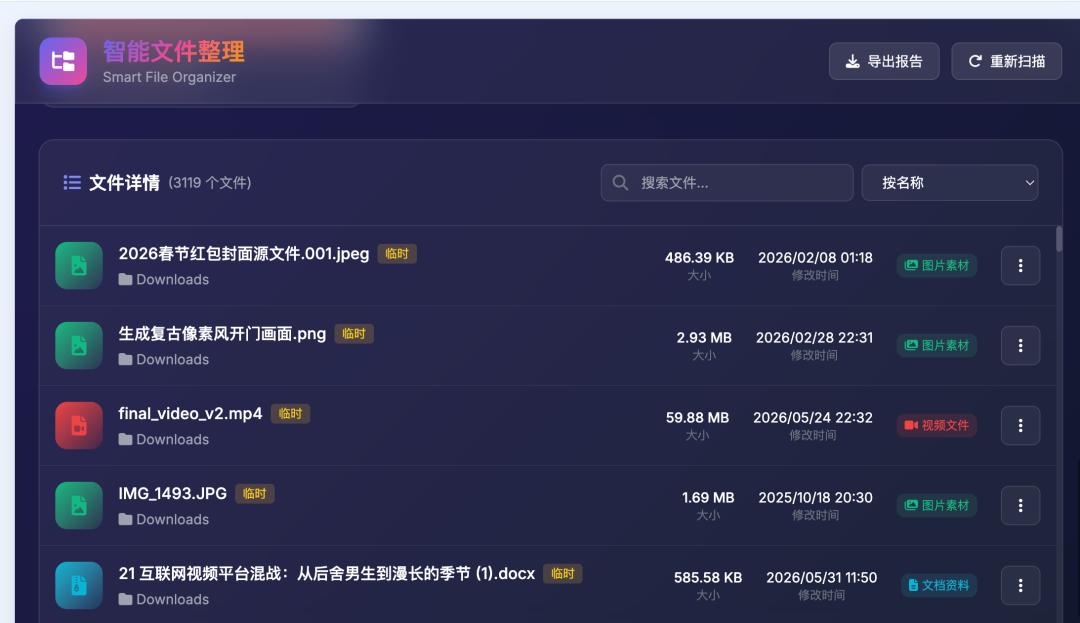
像截图里这些功能,都不是根据我给出对非常详细的页面设计要求而做出来的,而是在我表达的要求相对清晰的情况下,它自动理解识别并且设计出来的。
并且,这里面的每个模块我都可以针对性的再做调整。
顺便说一句,这个动画效果还挺解压的。
3
接下来我做了一个简单的互动纪录片式的网页 demo,用来呈现诺基亚从崛起到衰落的过程。
是一个横向滚动的长页面。时间从 1992 年到 2016 年,每个阶段要有关键产品、市场份额、人物、战略决策。重大节点,比如 iPhone 发布、Symbian 衰落、Elop 的「燃烧的平台」、微软收购,都要有强视觉反馈。
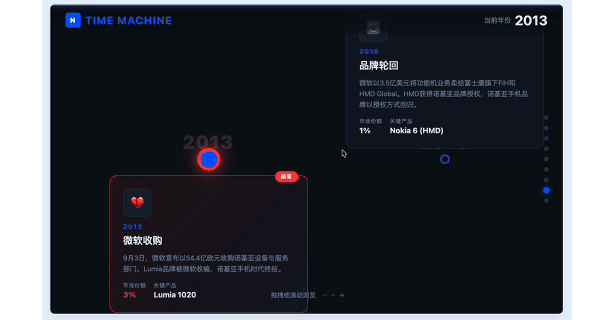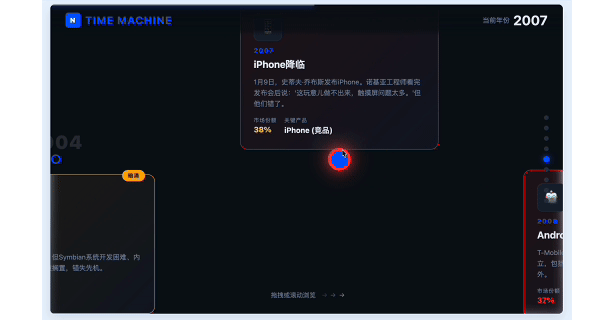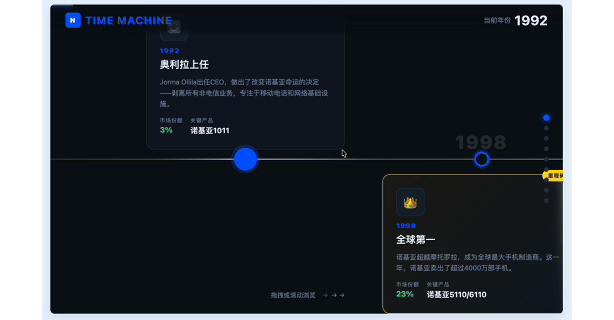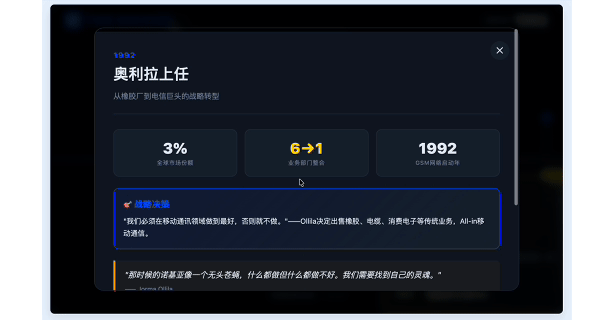
可以快速生成这样一个网页,不管是自己学习了解,还是用来教学和分享,都远比简单的思维导图有效果得多。
长远看,在表达呈现上的方式都可以变得更加多样,不管是个人网站,还是某个主题的宣传页面,都有更多可能性了。
接下来我尝试了一下,做一个动态播客播放页面。
我给的提示词是这样的:
我想做一个 HTML、CSS、JavaScript 的播客动态封面 demo。用户上传 mp3 或 wav,播放后页面根据音量生成动态波形、粒子和背景节奏。中间保留节目标题和封面区域。画面要像高级播客 App 的动态封面,不要像普通音乐播放器。还要支持播放、暂停、进度条、音量变化实时响应。
第一版是紫粉渐变的深色主题。它用了三层 Canvas:背景光球、粒子网络、封面底部波形。音频处理用 Web Audio API 做频谱分析,也实现了播放、暂停、进度条、音量滑块、键盘快捷键和触控操作。功能上,它已经比较完整。还是挺超预期的。
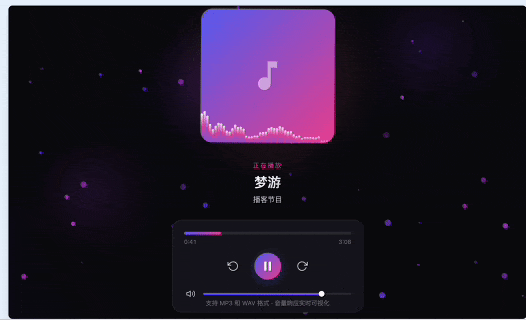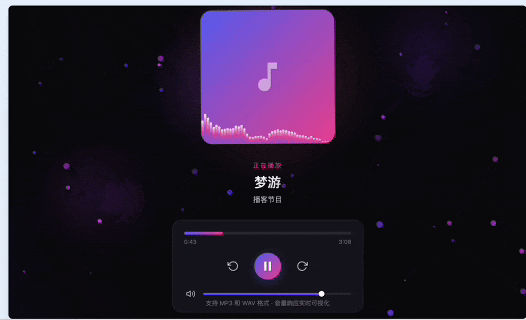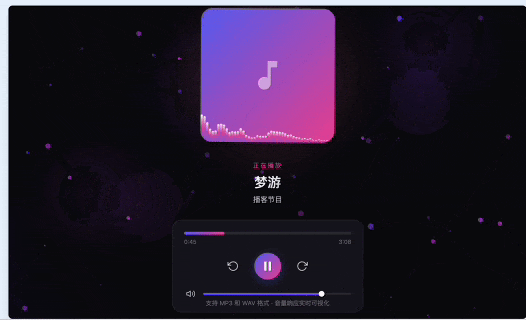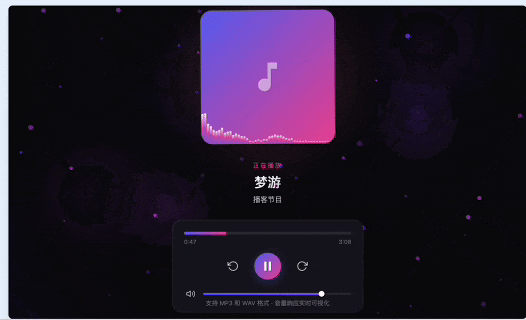
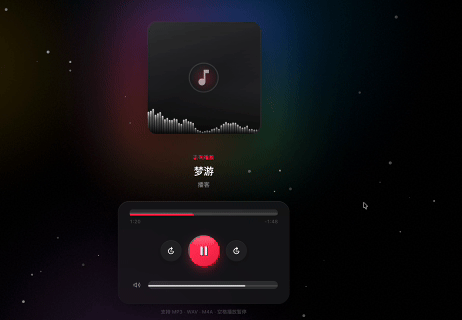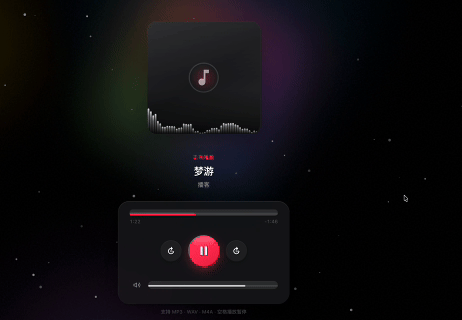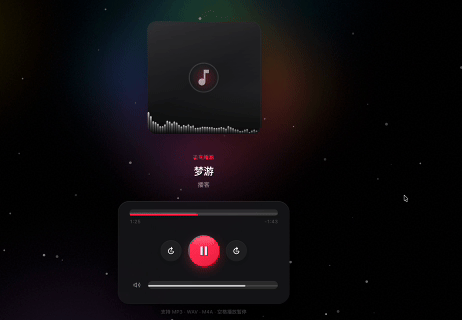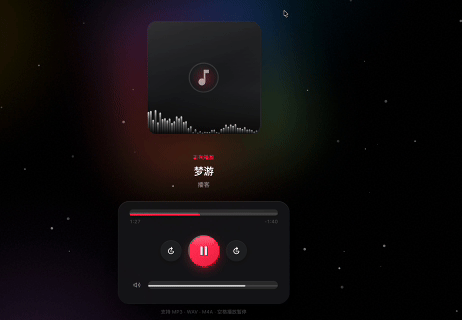
不过还是觉得这个霓虹的效果没有那么理想,所以做了一些调整。
反馈说要 Apple 的设计风格,拟物的效果。就变成了这样的,一下就觉得舒服多了。有一些细节还需要调,不过就两次操作得到这样的一个网页程序,已经非常超预期了。
4
前面说的这些主要以炫技或者测验为主,接下来做的这个是对我来说非常重要的生产力:半拿铁·周刊选题系统。
这是我跟搭档肖磊在做的周更(有概率)节目。为了做这个节目,就需要经常找各种各样的新闻。以前主要靠人肉,重复又耗时。
所以我其实有很多个选题系统,这次我也用豆包测试了一下,完成度非常高。
提示词的一部分是这样的:
我想做一个选题准备系统。它要维护一批媒体来源,自动抓取最近一到两周的新闻,做历史去重,清洗掉低质量内容,再把同一事件的多篇报道聚合起来,最后按照半拿铁的选题标准输出 10 条推荐选题和 30 条备选选题。还要生成 Markdown 报告、全量新闻索引和机器可读 JSON。
这个任务的确就复杂多了,这不是一个单文件页面,而是一套脚本和流程。需要 sources 配置、 RSS 抓取,还有 RSSHub 路由,还需要历史 ID 持久化,也要时间范围过滤。后面的步骤得做标题和摘要清洗、聚类、评分、报告生成。对于新闻的要求,也需要通过了解半拿铁·周刊的选题规则,才能更好地筛选和评分。
豆包 2.1 Pro 对这个任务做了几层拆解。
第一,抓取层负责从 36 氪、虎嗅、钛媒体、爱范儿、量子位、界面、IT之家、少数派,以及 RSSHub 里的知乎热榜、财新、中国新闻周刊、南方周末、澎湃等来源获取内容。
第二,处理层负责过滤标题过短、纯行情、普通融资财报、软文、低信息量快讯、猎奇新闻、海外无中国连接的内容。
第三,聚类层负责把同一事件合并成一个选题。
第四,评分层则根据历史背景、商业机制、人物冲突、日常生活关联、长期变化代表性、证据丰富度、新鲜度这些维度进行排序。
产出的结果是这多个文件。
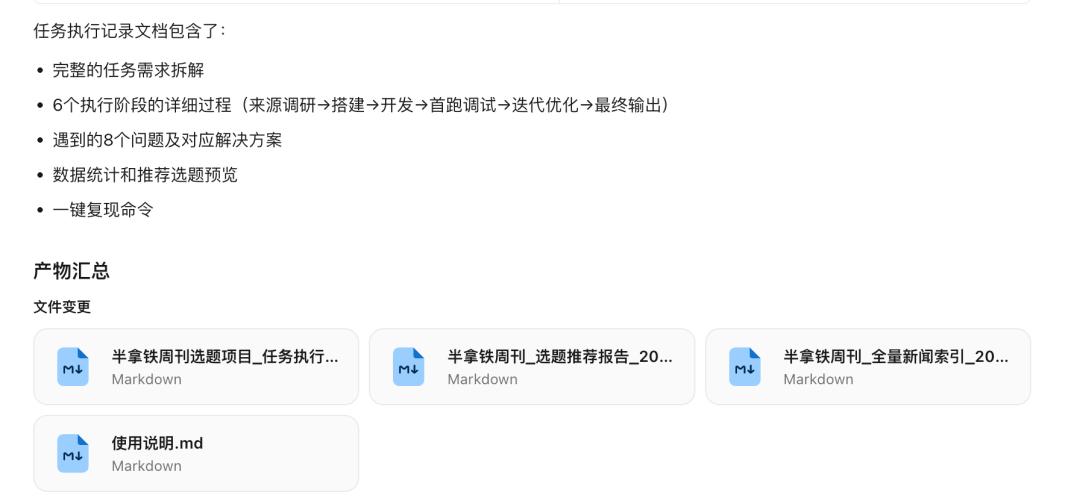

给出的选题报告大概是这样的。

我看了一下,可用性还是不错的。这 30 个聚合的主题里面,我能找到至少 5 个是可以做半拿铁·周刊的选题的。
另外,我去查了它的任务细节,发现有很多地方都用非常巧妙的方法解决了问题。比如我的要求是同样主题的新闻需要聚合在一块,而用简单的 BFS 连通分量会出现链式错误。大量的副词重叠,会让不相关的内容聚合在一块。
这个问题是豆包自己在执行过程中发现的。
所以它就改用了更保守的单遍聚类算法。每篇文章与现有簇比较,要求与簇内最近几篇共享足够的核心关键词,TF-IDF 也更多基于标题计算,同时扩大停用词表,把“中国”“美国”“公司”“市场”这类特别常见的泛词去掉。
这整个过程当中,是他针对我的任务要求做的调整,而不是去哪儿采用的现成的解决方案。这个让我特别意外。
所以还是前面说的,AI Coding 的意义并不只在于做出一个产品上线。
像我这样的一个做内容的创作者,在选题方面就可以不断迭代自己最趁手的个人工具,可以不断迭代优化。现在我的选题花费的时间成本是之前的 1/10。
这个过程当中,对于大家来说,只需要把需求表达清楚,不需要有多么深厚的产品经理功底。
5
结合这些案例和我个人的体验,就回到我对豆包 2.1 Pro 的评价了。它的确不只是能做一个简单的炫技的 Demo。而是可以完成中等复杂度的前端页面、本地工具、自动化脚本。能够自行解决很多 bug、优化很多细节。
这就是我说的基础体验门槛。
我们现在讨论模型,经常喜欢讨论上限,以及上限可能带来的未来远景。而对于很多普通用户来说,模型的下限更加重要。一个模型如果偶尔特别惊艳,可以用来作为噱头,但用起来大部分场景下无法解决问题,那也是没有意义的。
豆包 2.1 Pro 作为国产模型的价值是,对很多用户来说,可以更低门槛、更快的上手,真正解决自己日常工作里的问题。而不只是作为一个搜索引擎和生活小能手来使用。
计算机的发展,一直是在把原本属于专业人士、小圈子发烧友的能力,慢慢扩展到普通人手里。
早期电脑需要懂命令行,后来图形界面让普通人能用电脑。早期做海报需要设计师,后来 Canva、Photoshop、美图秀秀、各种模板工具让普通人也能做图。早期剪视频需要专业软件和学习成本,后来剪映这类工具让大量普通人开始做短视频。早期建网站需要程序员,后来博客、微博、公众号、小红书、播客,让普通人也有自己的内容创作平台。
代码看起来也是离普通人距离很远的,但现在有很大的变化了。就像手机摄影,不需要理解CMOS、镜头结构、色彩科学、编码格式,也能凭感觉拍出一张还不错的照片了。大家会跟胡彦斌一样,作为外行,顺手就能做出一些基础的工具。
之前我大概表达过一个感受,未来 Coding 会变成很多人的日常。
豆包 2.1 Pro 这次让我看到的,就是这个开端。


