
Alisa Liu 下周就要加入 OpenAI 了。
在这之前,她刚刚结束了一场漫长的求职过程:参与了 11 家公司的 57 场面试,还有另外的 46 次招聘沟通,以及 16 次 offer 之后的沟通。她把这段经历写成了一篇求职复盘,很快在 AI 圈传开。
Alisa 在华盛顿大学完成了为期六年的自然语言处理博士学位,求职方向主要是研究科学家和技术团队成员这类岗位。按很多人的想象,拥有这样的背景去面试顶级 AI 公司,最关键的考察应该是论文、研究方向、模型理解和前沿判断。但她的复盘让大家意识到:一旦进入正式面试流程,真正被反复检验的仍然是编程基本功。
会不会写代码,会不会实现模型,会不会在类似 LeetCode 的算法题里快速找到数据结构和算法解法,这些基础的东西依然绕不开。
在评论区,许多 AI 研究人员也提到了类似经历。
Meta 的研究科学家 Mimansa Jaiswal 说,她第一次完整的全流程面试就是 Anthropic,当时 9 轮面试里有 2 轮 Colab 编程没发挥好。她后来才意识到,编程面试必须提前练。

另一位来自 Meta 和纽约大学的 AI 研究人员 Ravid Shwartz Ziv 也回忆,很多年前他第一次参加公司面试时,面试官给了他一些编程任务,30 分钟后回来,他大脑一片空白,一行代码都没写出来,面试官只说了一句“谢谢,也许下次吧”,然后关门走人了。
顶级 AI 公司最常考的还是技术基本功
Alisa 在复盘中写道,她一共面试了 11 家公司,经历了 57 场正式面试。这个数字还没有包括另外 46 次招聘沟通、16 次拿到录用意向后的进一步交流,以及求职前后大量非正式的人脉沟通。
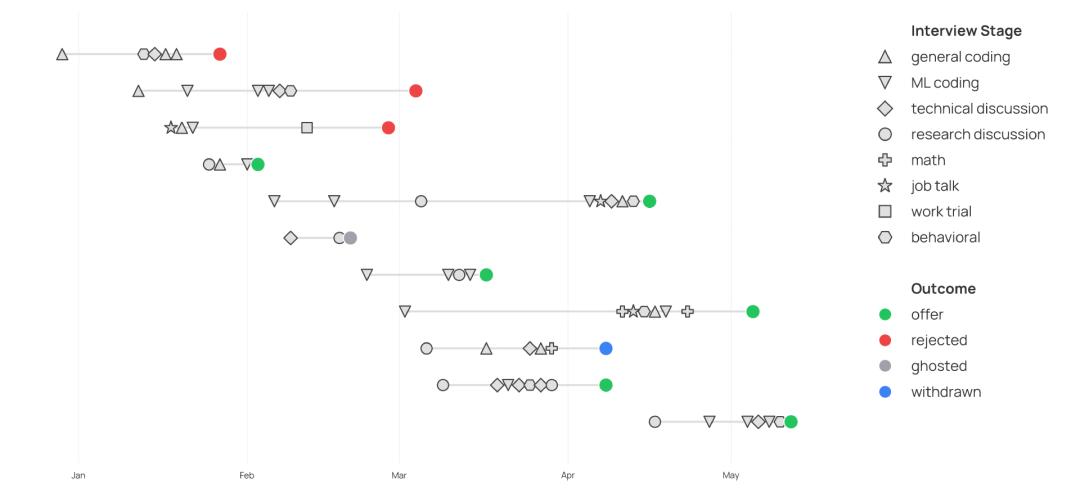
在这个过程中,她对顶级 AI 公司面试到底在考什么,有了一个比较具体的观察:“总的来说,技术能力和技术知识比研究经验更受重视,尽管研究经验很可能是获得面试机会的关键。”
她在复盘中把面试大致分成了几类:机器学习编程、通用编程、技术讨论、研究讨论、行为面试、数学面试和工作报告。
出现最频繁的是机器学习编程面试。这类面试要求现场动手实现。题目可能要求你实现一个给定的模型架构、一种解码策略、一个传统机器学习算法,有时也会是更有创造性的任务。熟练使用 PyTorch 是必备能力;少数情况下,她会被要求只能使用 NumPy,比如从零写反向传播,但面试官并不期待她记住 NumPy 的具体语法。
第二类是通用编程面试。 基本上就是 LeetCode,有时会加一点变化。
这里打好基础很重要,因为很多数据结构和算法概念也会出现在机器学习编程面试中。也就是说,即便面试的是 AI 岗位,动态规划、图、哈希表、树、堆、双指针、二分查找这些东西仍然可能影响最后结果。
第三类是技术讨论。 这类面试不需要写代码,但技术含量很高。有时候,整场面试会围绕一个主题展开,比如如何设计实验来回答某个研究问题,或者完成某个技术目标。面试官通常会不断追问你的设计选择,也会让你解读一些假设性的实验结果,并据此设计后续实验。还有一些面试更像一连串快速问答,比如:位置编码有哪些不同方式?什么是 5D 并行?PPO 和 GRPO 有什么区别?这类问题的目的,是让她证明自己确实熟悉这个领域。前一种面试考察的是思考方式,后一种则考察知识面的广度。
第四类是研究讨论。 这类对话是博士期间最常训练的。面试官通常会先让你介绍一个过去做过的项目,然后顺着这个项目继续追问。他们也可能会问到你简历上的其他论文。准备这类讨论时,很有必要退后一步想清楚:当初为什么选择这些问题,过程中形成了哪些洞察和判断,以及你认为哪些未来方向更有前景。
她还会根据不同岗位调整自己的研究介绍,因为面试官也很累,候选人如果能更快命中岗位相关关键词,对方就更容易判断你的背景是否匹配。
第五类是行为面试。 她说这类面试基本就是标准行为面试,只是偶尔会出现关于 AI 安全或社会影响的问题。
她的教训是,不能因为觉得自己“表现一直不错”就轻视这类面试。她第一次行为面试就失败了,因为面对一些非常简单的问题时,大脑一片空白,临场很难一边回忆博士期间的经历,一边把它组织成一个符合问题的故事。她建议提前列出博士期间一些印象深刻的经历,并把它们对应到常见行为面试问题上,这样面试时才能快速调用。
第六类是数学。 有些公司会安排数学面试,内容从有趣的逻辑谜题,到需要用纸笔完成的严肃数学推导都有。她建议复习概率、线性代数和微积分。
最后一类是工作报告,也就是 job talk。相比学术界的报告,工业界的 job talk 通常更短,也更聚焦在一篇论文或一个研究方向上。她自己的 job talk 主要围绕 tokenizer 展开,大部分时间讲一篇一作工作,然后简要覆盖几篇二作和正在进行中的工作,因为这些内容刚好能串成一个比较完整的方向。
Transformer 要练到肌肉记忆,写代码时还要关掉 AI
Alisa 在复盘中写道,准备面试几乎是最值得投入时间的事情。
对她来说,这个过程很像重新回到本科阶段:做笔记、画图、刷练习题,整天待在咖啡馆里,确保自己把机器学习的基础概念真正理解透。技术面试很难,而且它考察的能力并不会自动从研究经历里长出来,需要在研究之外专门投入时间训练。
她说,对她自己以及她聊过的大多数人来说,“找工作本身就是一份全职工作”。
她的准备过程,是从 Stanford 的 Language Modeling from Scratch 课程开始的。
她看完了这门课的全部 lecture,这能帮助她看到自己需要补齐的知识范围,也能把脑子里很多分散的概念重新组织成一张关于语言模型的完整图景。打完基础之后,她把剩下的时间用来逐个深挖概念:读相关博客和论文,跟 ChatGPT 和 Claude 进行大量的交流,同时练习从零实现各种功能。
她特别把 Stanford 这门课里的 Homework 1 拎了出来。她认为这个作业“至关重要”,因为 Transformer 的实现和调试在面试中出现得太频繁了,把它练成肌肉记忆,会带来非常大的回报,也完全不值得在这种地方丢分。

这份 Homework 1 是 Stanford CS336 的第一个基础作业,主题就是从零构建一个 Transformer 语言模型,不是调用现有模型在框架里改几个参数。
作业要求学生亲手实现链路中的每一层。提供作业的仓库 cs336_basics/* 中明确写着:“这里没有现成代码,你可以完全从零开始,按自己的方式实现。”
首先要求实现 byte-level BPE tokenizer,需要理解基本的编码和子词切分机制,并写出可训练、编码和解码的 tokenizer。还要求学生分别在 TinyStories 和 OpenWebText 上训练这个 tokenizer,比较不同语料训练出来的压缩效果和词表差异。
接下来是从零实现 decoder-only Transformer 语言模型,包括 embedding、Transformer block、causal self-attention、RoPE、前馈网络和输出层,重点在于把张量维度和 attention mask 处理正确。
最后,还需要实现交叉熵损失、AdamW 优化器和完整训练循环,并支持模型与优化器状态的保存与加载,形成一个最小可用的语言模型训练流程:原始文本进来,经过 tokenizer 变成 token ID,再进入 Transformer 训练,最后生成样本文本,并用 perplexity 衡量效果。
更关键的是,这个作业对“从零实现”的要求非常严格。除了 torch.nn.Parameter、torch.nn 里的容器类,以及 torch.optim.Optimizer 基类之外,学生不能直接使用 torch.nn、torch.nn.functional 或 torch.optim 里的现成高级组件。换句话说,线性层、归一化、attention、loss、optimizer 这些核心部分,都不能简单调用官方封装糊弄过去,而要自己真正写出来。
并且这份作业虽然允许学生用 AI 工具回答高层概念问题,或者查询函数签名、库 API 这类文档信息,但不允许用 AI 工具实现任何作业代码,包括 Cursor Agents、Codex、Claude Code 这类编码代理,还要关闭 Cursor Tab、GitHub Copilot 的补全功能。因为之前的学生反馈说,关闭 AI 自动补全让他们更容易深入理解材料。
这也和 Alisa 的面试建议一致。她提醒在练习的时候“务必确保在练习编码的时候关闭 AI 辅助功能,以模拟真实的面试环节,否则会低估自己对 AI 的依赖程度!”
她还说,这种面试准备过程最像一种高强度临时备考:“每次面试都像是一门略有不同的数学或计算机科学课程。你从未上过课,却只有大约三天时间来准备期中考试。”
参考链接:https://alisawuffles.github.io/blog/job-search/


