
2026年,一个酝酿已久的技术奇点正在到来。
央视《新闻联播》的镜头罕见地对准了一项前沿芯片技术。全国人大代表、华中科技大学副校长冯丹在两会通道上发出呼吁:支持湖北打造世界级存算一体化产业基地,为国家在“人工智能+”新时代掌握战略主动权。
技术层面的突破也在同步发生。ISSCC 2026上,清华大学、华为与字节跳动联合团队在会上发布了一篇关于存内计算芯片的论文,引起业内关注。论文中首次提出基于28nm工艺的混合存内计算(Compute-in-Memory, CiM)芯片,这款芯片通过创新架构设计,将推荐系统核心运算的效率和能效提升1–2个数量级(QPS提升66倍,QPS/W提升181倍)。
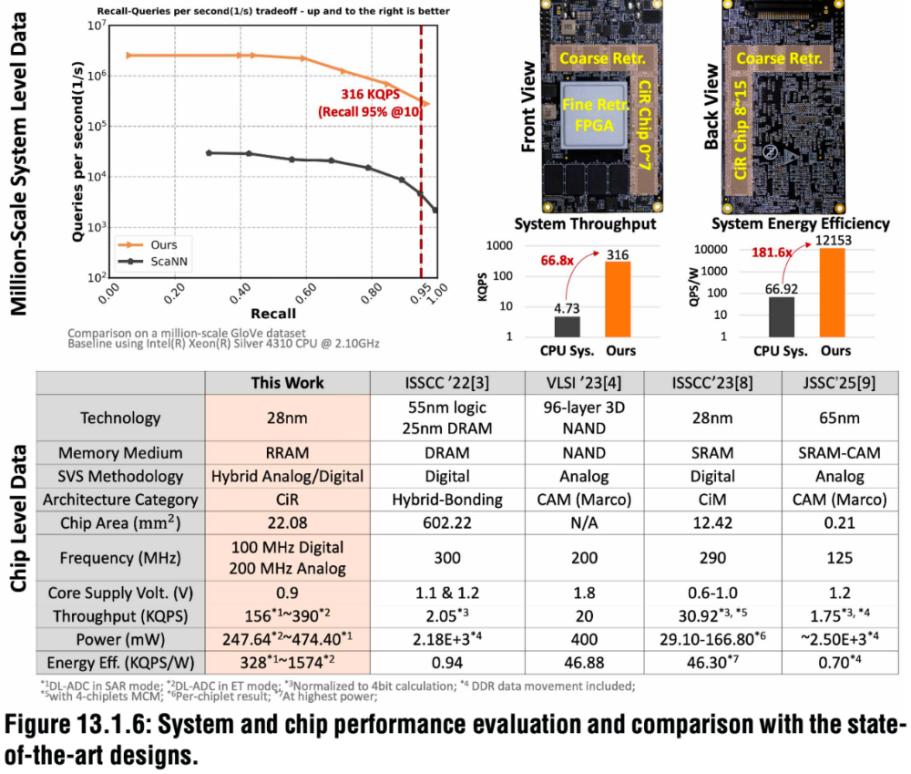
01 存算一体:后摩尔时代的破局之道
要理解存算一体为何重要,需要先理解一个基本矛盾:数据搬运正在“吃掉”计算效率。自1945年冯·诺依曼提出存储程序计算机架构以来,全球计算产业在此框架下发展了八十余年。这一架构的核心特征是将计算单元与存储单元分离,数据在处理器与内存之间频繁搬运。这就像一个工厂,原料仓库与生产线相隔甚远,每生产一个零件,都需要人把原料从仓库搬到生产线,再把成品搬回仓库。当零件较小时,这种模式的弊端尚不明显;但当生产规模急剧扩大,搬运所消耗的能源和时间就开始成为瓶颈。
在芯片世界里,这个瓶颈有个形象的名字:“存储墙”和“功耗墙”。英伟达CEO黄仁勋曾坦言:“GPU有70%时间在等待数据”。
屋漏偏逢连夜雨。随着半导体工艺逼近物理极限,摩尔定律带来的性能提升红利逐渐消退,传统芯片制程微缩的成本效益比日益降低,进一步加剧了算力供给的困境。大模型技术的迅猛发展进一步放大了这一矛盾。以GPT为代表的大语言模型参数规模从数十亿增长至数千亿,对存储容量和带宽的需求呈指数级上升。
正是在这样的背景下,存算一体技术走到了聚光灯下。
存算一体的核心逻辑很简洁:将计算单元之中,使数据在直接嵌入存储阵列存储位置即可完成计算。这个理念看似简单,却是芯片架构层面的范式级创新。
简单来说,如果把传统芯片比作一个需要频繁出差的企业:计算单元和存储单元分属两地,员工(数据)每天在两点之间往返通勤,那么存算一体芯片就是一个把办公室直接建在仓库里的企业:原材料就在手边,随取随用,效率自然天壤之别。
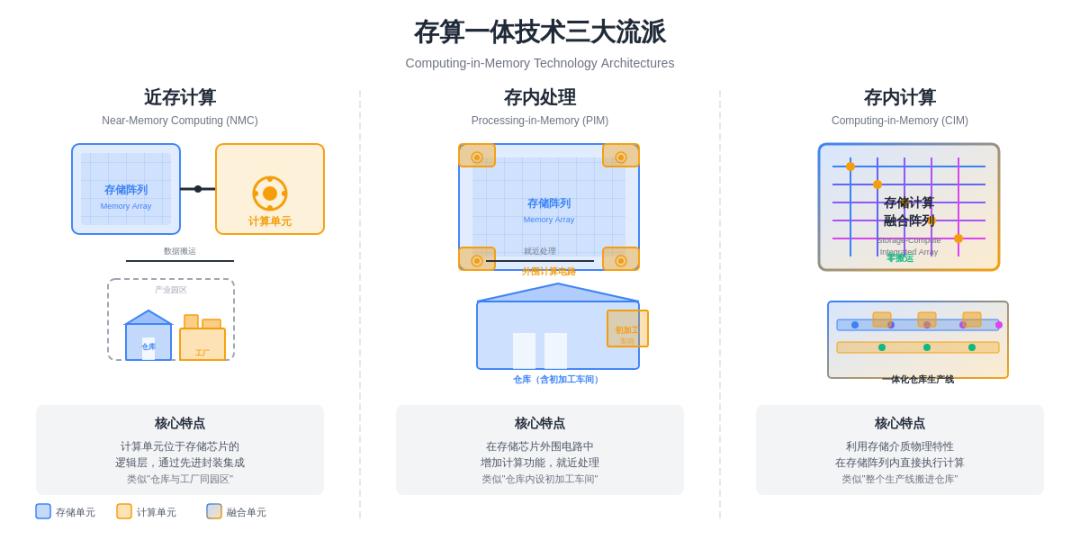
存算一体技术目前形成了三大流派:
第一,近存计算(Near-Memory Computing, NMC)。计算单元位于存储芯片的逻辑层,或者通过先进封装技术与存储器紧密集成。这类似于把仓库和工厂建在同一个园区,虽然仍在两个地方,但距离大幅缩短。高带宽内存(HBM)中的逻辑层集成或3D堆叠技术就属于这一类。
第二,存内处理(Processing-in-Memory, PIM)。在存储芯片的外围电路中增加计算功能,使部分计算任务可以直接在存储器内部完成。这相当于在仓库里增设了初加工车间,原材料不必全部运出厂区,部分处理就能完成。
第三,存内计算(Computing-in-Memory, CIM)。这是融合度最高的方案,直接利用存储介质的物理特性(如电阻、电荷、磁性等)在存储阵列内部执行计算操作。基于SRAM、RRAM(阻变存储器)或MRAM(磁性存储器)的存算一体,能够实现高度并行和超低功耗的计算。这已经是把整个生产线搬进了仓库。开头论文中的芯片就属于这一类。
三种路径各有优劣。近存计算实现难度最低,但提升幅度也相对有限;存内计算潜力最大,但技术挑战也最为严峻。
02 百家争鸣:中国存算一体的技术流派与核心玩家
据预测,2025年全球存算一体芯片市场规模将突破120亿美元,中国占比达30%。中国的存算一体企业在技术路线上呈现出丰富的多样性,这种多样性既来自对不同技术路径的探索,也来自对不同应用场景的专注。
计算范式上,主要分为数字存算一体和模拟存算一体。数字存内计算精度高、与CMOS工艺兼容性好,是目前产业化的主流方向。模拟存内计算能效更高,但精度受限。数模混合方案试图在精度与能效之间寻求平衡。
存储介质上,主流技术路线包括SRAM、DRAM、Flash和新型忆阻器(ReRAM、MRAM、PCM等)四大方向,每种介质都对应着不同的技术特点和适用场景。
SRAM存算一体方案基于CMOS工艺,可采用先进工艺节点,读写速度快,但存储密度相对较低且静态漏电流较高。DRAM方案存储密度高于SRAM,适合处理大容量模型场景,但与CMOS工艺的兼容性较差。Flash方案具有非易失性和低功耗优势,但读写速度相对较慢。
新型忆阻器方案是近年来最受关注的探索方向。ReRAM(阻变存储器)、MRAM(磁性存储器)、PCM(相变存储器)等新型存储介质具备良好的工艺可扩展性和超低功耗特性,被认为是存算一体技术的“未来之地”。但目前,这些新型介质的工艺成熟度和良率仍是制约产业化的主要瓶颈。
值得一提的是,先进封装技术是存算一体实现高性能的关键支撑。2.5D封装通过横向堆叠互连实现存储与计算单元的集成,3D封装则进一步实现垂直堆叠和极致融合。目前业内封装水平最高的是台积电提出的3.5D封装。
根据应用场景的不同,中国存算一体企业大致可分为两个主要阵营:以数据中心、智能驾驶、端边大模型为代表的“大算力”阵营,以及以智能穿戴、智能家居、物联网为代表的“端侧AI”阵营。另一条暗线是底层技术,以昕原半导体为代表的“新型存储介质”探索者。
大算力、大模型方向
这类企业主要面向数据中心、高性能计算和智能驾驶等需要强大算力支持的场景,致力于解决大模型训练和推理中的“存储墙”和“功耗墙”问题。
后摩智能是大算力存算一体芯片领域的代表性企业。其技术路线以SRAM存算一体为基础,自研第二代IPU架构——天璇。天璇架构采用按比特串行计算方式,将计算单元与存储单元集成在一起实现数据就近处理。其核心技术创新包括弹性加速(Elastic Acceleration)技术,最高可实现160%的加速效果。此外,后摩智能还是业内首个实现量产浮点运算的存算一体芯片厂商,开源或FP16浮点模型可直接运行,无需量化参数调优。对于开发者而言,这大幅降低了迁移成本。在产品进展方面,后摩智能发布国内首款大算力存算一体智驾芯片:鸿途H30,算力达到256TOPS,功耗35W,这是国内首款存算一体的智驾芯片。2025年7月,公司发布第二代量产芯片——漫界M50,该芯片于2025年第四季度正式量产。
亿铸科技是基于存算一体架构,面向数据中心、云计算、中心侧服务器等场景的AI大算力芯片公司。走的是ReRAM介质路线,据官网介绍其自主设计并量产基于新型存储的全数字存算一体架构大算力计算芯片。此外,亿铸科技还积极拥抱RISC-V生态,在AI大算力芯片领域,首批引入RISC-V核,用于承载大模型业务中的任务调度、矢量运算等操作。
端侧、边缘AI、低功耗方向
这类企业主要面向智能穿戴、智能家居、物联网设备等对功耗、体积和成本有严格要求的场景,通过存算一体技术实现高效的边缘AI计算。
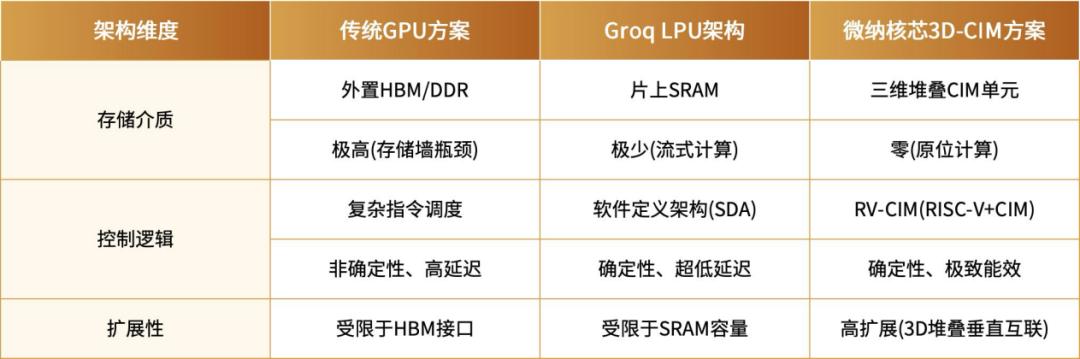
微纳核芯是一家值得关注的企业。微纳核芯的目标是为AI手机、AI PC、IoT、一体机、服务器、机器人等大模型推理应用提供高性能、低功耗和极致性价比的芯片解决方案。微纳核芯孵化于浙江省北大信息技术高等研究院,走的是CIM技术路线。在CIM的基础上融合了“3D近存计算”和“RISC-V与存算一体异构架构”,首创三维存算一体(3D-CIM)架构。从多次流片迭代和测试结果表明,相比传统冯·诺依曼架构,微纳核芯的存内计算CIM技术已实现4倍以上算力密度提升(同等成本改善)和10倍以上功耗降低。今年3月,兆易创新入股了微纳核芯。
炬芯科技是上市公司中布局存算一体技术的代表企业,公司构建CPU+DSP+NPU三核架构,创新采用SRAM存内计算技术,配套ANDT工具链加速算法落地。在技术演进方面,炬芯科技正在推进第二代存内计算IP研发,目标实现单核NPU算力倍数提升、能效比优化,并全面支持Transformer架构。
知存科技是NOR Flash存算一体技术的代表企业。知存科技的核心产品包括WTM2101和WTM-8系列。WTM2101是全球首款基于NOR Flash的存算一体语音芯片,于2022年1月正式量产。该芯片专注端侧低功耗语音交互场景,功耗仅5mW,相对于NPU、DSP、MCU计算平台,在同等功耗水平下可将算力提高10至200倍。WTM-8系列是知存科技的新一代计算视觉芯片,适用于低功耗高算力场景,支持Linux操作系统,可实现AI超分、插帧、HDR、检测与识别等功能。该系列芯片能够提供至少24TOPS算力,而功耗仅为市场同类方案的5%。
新型存储介质方向
昕原半导体是国内忆阻器(ReRAM)存算一体技术产业化的领军者,专注于ReRAM新型存储技术研发和产业化。昕原半导体的核心产品是28nm制程ReRAM存储芯片,已实现量产。公司的ATOM产品系列利用ReRAM兼容先进工艺的特性,将存储和计算单元融为一体,是国内唯一实现ReRAM量产的企业。
ReRAM(阻变存储器)是一种新型非易失性存储技术,具有存储密度高、工艺和CMOS兼容、性价比高等优势。相比DRAM,ReRAM存储密度可大幅提升;相比Flash,ReRAM读写性能更优。昕原半导体的技术路线代表了存算一体与新型存储介质结合的重要方向。字节跳动曾入股昕原半导体,表明其RRAM技术在VR/AR等终端设备应用中的潜力。
03 商业化落地,咋样了?
技术领先是一回事,把技术变成产品是另一回事。
炬芯科技的年报显示,炬芯科技率先在业内实现存内计算技术商业化应用,正式推出面向端侧场景的AI音频芯片。其中ATS323X芯片已快速落地品牌客户旗舰无线麦克风并实现上市发售。同时在国内头部品牌无线电竞耳机中量产上市,ATS362X芯片也成功切入多家专业音频头部品牌供应链。
知存科技的WTM2101芯片已实现超过1000万颗的出货量,应用于华为、小米等品牌的智能可穿戴设备中。这是目前国内存算一体芯片商业化最成功的案例,证明了存算一体技术在端侧低功耗场景的商业价值。截至目前,知存WTM-2系列累计交付30多家客户,尤其今年上半年有某智能穿戴终端头部客户的大单出货。
后摩智能的鸿途H30芯片于2024年发布,这是国内首款存算一体的智驾芯片,已通过AEC-Q100车规认证,2025年实现量产。漫界M50芯片计划于2025年第四季度正式量产,已与联想、科大讯飞、中国移动等头部客户建立合作意向。最近,后摩智能在开天X7等信创电脑上进行了本地龙虾的适配。
微纳核芯凭借3D-CIM技术架构,已与国内头部存储器厂商和多家终端龙头企业深入合作,是唯一同时与多家手机龙头企业深度合作、且拉通手机主芯片厂商配合的3D AI芯片公司。目前,微纳核芯作为RISC-V存算一体应用组组长单位,在杭州萧山牵头启动全球首个RISC-V存算一体标准研制工作,联合20余家产业链龙头企业,推动自主可控AI芯片生态建设。
亿铸科技在2023年7月成功流片并点亮了基于新型存储的高精度、低功耗存算一体AI大算力原型技术验证芯片,验证了核心技术路线的可行性,2026年将推出极具性价比和软件兼容性优势的国产AI算力卡。
04 存算一体是大模型的终极答案吗?
随着大模型参数规模的不断膨胀,对算力的需求已达到前所未有的高度。存算一体技术因其独特的优势,被寄予厚望,有望成为大模型时代算力瓶颈的终极解决方案。然而,这并非一蹴而就,而是一个逐步演进的过程。
存算一体在万卡集群中的演进路径:初期,作为专用加速器,处理特定任务(如推理、数据预处理)。在此阶段,存算一体芯片将首先作为现有GPU万卡集群的补充,承担特定的计算任务。
中期,与GPU深度融合的混合架构,实现更高层次的协同。随着存算一体技术的成熟和Chiplet(小芯片)技术的普及,存算一体单元将与通用计算单元(如GPU或NPU)通过先进封装技术(如3D堆叠)进行深度融合,这种混合架构将实现“近存+存内”的协同。
长期,可能出现以存算一体芯片为主导的新型万卡集群,彻底颠覆现有架构。当新型非易失性存储介质(如RRAM)的工艺和良率达到高度成熟,且存算一体芯片的通用性和可编程性大幅提升时,我们可能会看到以存算一体芯片为核心构建的新型万卡集群。这种集群将彻底颠覆现有的冯·诺依曼架构,实现真正意义上的“存储即计算”。


