
2026年的春天,对于大洋彼岸的硅谷来说,冷意下浮动着暗流。
过去几周,几则看似孤立、实则暗流涌动的边角料新闻,正在悄然改变着全世界对“AI霸权”的陈旧认知。
首先是2月份,那个曾让华尔街颤抖的DeepSeek,被曝出未向英伟达和AMD提供其最新旗舰模型进行适配,反而给华为等国内芯片商开了“小灶”。
紧接着3月初,国内外的几个知名科技论坛频繁传出“开源的Deepseek V4不更新,全世界的大模型都没得更新了”的段子。
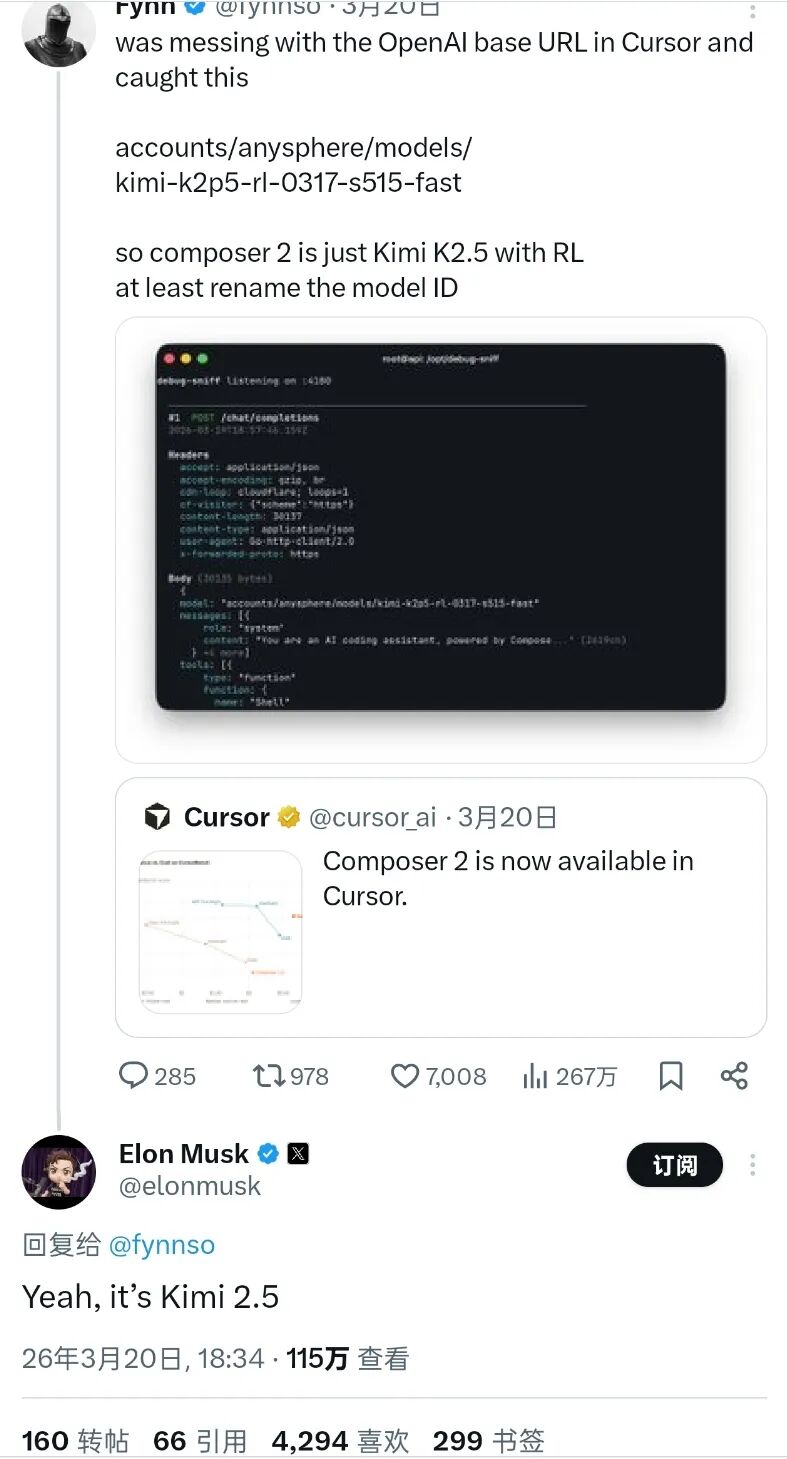
更搞笑的是3月底,估值500亿美刀、全球最高的AI编程工具Cursor,被网民发现其大吹特吹的下一代产品,核心模型竟然是“套壳”中国的Kimi。连马斯克都绷不住了,下场实锤说是的,这特么就是Kimi2.5。
最后,也是最戏剧性的是,曾经被誉为下一代AI范式、让好莱坞集体失眠的Sora,在字节跳动Seedance的强势追击下,悄无声息地关闭了消费端应用。同时,当Meta试图以天价收购东大AI初创Manus时,官方直接出手,限制其创始人出境,理由是涉及“敏感人工智能技术向境外转移”。
这几记重锤敲下来,一个模糊的现实正逐渐清晰:仰望和追赶者的角色,被反转了。
局势甚至严峻到在如今的硅谷,如果你不会中文,那你可能真的搞不懂什么叫AI了。
A.
此前,中美AI的竞争逻辑非常简单粗暴:西大负责造“核武器”(大参数闭源模型),东大负责搞“应用”。
现在,竞争已经进入了另一个维度里。
西大的AI正在陷入一种“富人的烦恼”。以OpenAI为例,Sora的关停虽然官方说辞是聚焦核心业务,但根本原因逃不开两个词:算力与成本。据外媒测算,Sora每天光是电费就要烧掉1500万美刀,生成一个视频的成本是售价的数倍,在盈利压力和IPO的财务审视下,这种“赔本赚吆喝”的C端业务只能被无情砍掉。
硬件层面上,西大虽然手握英伟达的先进算卡,但产能受限、电力告急,许多州的电网已经接近极限,新建一个数据中心甚至需要一座小型城市的电力供应。
这种背景下,西大AI的发展路径越来越窄:为了向投资人交代,只能加速堆叠算力,去卷那些看起来高精尖、实则离钱近离用户远的B端生意。
甚至最近内存市场鸡飞狗跳的原因,就是上述情况的外溢。
反观东大,这条路走得非常“狡猾”、或者说“接地气”。硬件被封锁后,东大AI公司们开始狂卷“软件优化+场景适配”之路。字节跳动的Seedance之所以能逼死Sora,靠的不是单纯模拟物理世界,而是更懂用户要什么——2K分辨率、更快的生成速度、更符合东方审美的镜头感,甚至允许用户上传音频进行“导演级”控制。

这场深水区的碰撞逐渐演变成为西大在赌“算力”的无限增长,而东大在赌“体验”的无限下沉。也就是一个“堆算力”,一个“卷体验”。
可算力还是会遭遇物理世界的瓶颈,但体验感却可以在疯狂的迭代中永无止境。
B.
如果AI只是芯片和代码的较量,那反而简单了。最近Manus两位创始人被限制出境的消息,赤裸撕开了更深层次的竞争帷幕。
这不仅是一起简单的收购案受阻,它是东大在国际前沿科技行业中、首个明确提出”防止敏感技术外流“的案例,残酷的揭示了AI核心资产正在被“主权化”的事实。更深层次的逻辑是,AI训练所依赖的庞大数据、底层架构、乃至诞生的环境,正在成为战略级资源。
AI的根基到底是什么?是软件研发、还是算力卡的硬件产能?还是更进一步的电力基建,稀土原材料?
最根本的,其实是人。
拉开AI之间差距的是算法,算法的根基是数学,而数学正好是东大教育的压舱石。从国际奥数竞赛的连年霸榜,到清华姚班、北大图灵班源源不断输送的“技术大牛”,东大源源不断的人才储备,开始引发整个AI行业的质变。
斯坦福大学的AI指数报告显示,在美国顶级AI研究机构中,2025年,拥有中国本科背景的研究人员占比已超过50%,但具体是51%还是59%就不提了 。而2019年这个数字还是29%,到2022年已经达到47%。
现在回看,无论是Meta那个75%是华人的“梦之队”,还是OpenAI负责数学推理的“天才少年”陈立杰,华人在硅谷AI领域的统治力早已不是秘密,而是基石。

C.
当一个行业的核心人才结构发生质变时,整个行业的生态逻辑就会被彻底颠覆。
一个在硅谷广为流传的段子是:Meta的AI核心会议结束后,一群华人工程师熟练地切换到中文唠嗑,留下其他外国同事站在原地一脸懵圈。这不光是文化现象与习惯,更是技术趋势。
因为不同母语的工程师,在AI的底层运转逻辑上是有先天立场的。
英文是分析性语言,讲究主谓宾的严谨结构。而中文是意合型语言,讲究语境和留白。一个从小浸润在中文语境里的工程师去设计Transformer架构时,他对“注意力机制”的理解,天然就会带有中式思维的烙印。
更隐蔽的是,这种烙印正在反向塑造AI的生态。
因为华人占据了硅谷AI的“承重墙”,当他们敲下一段段代码组成模型后,模型的推理逻辑会更贴近东方的“举一反三”,而非西方的“三段论”。当这个由母语是中文的工程师主导、中文数据深度训练的AI生态越来越庞大,它就会像黑洞一样,虹吸全世界的开发者和用户。
这就是为什么Hugging Face的CEO会说“中国开源模型正在成为全球AI技术栈的最大力量”。因为不懂中文,就无法理解最前沿的开源代码注释。不能理解中式逻辑,就很难在那些华人主导的顶级团队里找到一席之地。
D.
最后,一个不得不提的新现象是,国内的大厂们正高薪聘请大量文科生。
是的,没看错,在AI领域文科生的身价正在暴涨。这代表了一个核心的指标:AI与用户的交互体验,已经从“逻辑”转向了“文化”。
早期的AI,我们追求的是“智商”,是算对数学题。现在的AI,我们追求的是“情商”,是让它在交互中像个人,甚至像一个特定文化背景下有特定性格的人。
当大厂开始大规模招聘哲学、历史、文学、心理学专业的毕业生来训练AI时,他们训练的不是冰冷的概率模型,而是“语境”。他们教AI理解“只可意会不可言传”的潜台词,教AI分辨“呵呵”到底是开心还是嘲讽,教AI在面对“我和你前女友谁更漂亮”这种死亡问题时,贴心的告诉直男们最完美的答案。
这就是中美AI竞争中,东大最隐蔽、也最恐怖的软实力。
西大虽然有顶尖的算法工程师,但他们缺乏东大这种海量的、经过五千年文明沉淀的“高语境”数据。当东大的AI不仅能生成视频、还能生成符合“仁义礼智信”审美标准的视频时,当东大的AI不仅能回答问题、还能像老朋友一样“接住”你的情绪时,当东大的AI不仅能一本正经的严肃、还能活人感十足的懂梗懂”阴阳怪气“时。这种文化壁垒是再先进的GPU都无法突破的。
这就回到了一开始我们想说的:为什么在硅谷,不会中文就搞不了AI?
因为现在的AI,不再仅是物理、半导体,也不仅仅是线性代数和代码。它是数学、是算力、是电力,但最终,它是文化力。
Sora可以模拟物理世界,但它很难模拟国人”意思意思”的人情世故;Meta的Llama可以写代码,但它很难写出”落霞与孤鹜齐飞“的意境。从东大的AI人才占据硅谷半壁江山开始,到开源模型定义全球标准,最终到文科生用文史哲给AI注入灵魂。这场游戏一开始的那版老旧规则,早就被东大涂抹的面目全非。
在AI这个赛道上,未来或许不会再有纯粹的“美国队”和“中国队”。但有一点可以肯定:如果你不懂中文,就注定要被关在大门之外了。


