

苏姿丰、陈立武等人组成的“复联”,图片由AI生成。
3月16日,美国加州圣何塞的冰球场又将座无虚席。英伟达CEO黄仁勋将穿着他那标志性的皮夹克走上舞台,开启一年一度的GTC大会。
但今年,气氛有些微妙。
过去十年,英伟达可以称为AI芯片市场唯一的“王”。
《华尔街日报》统计的数据显示,从2025年2月到10月,英伟达卖出了1478亿美元的芯片和相关硬件,比上年同期的910亿美元增长了62%。去年7月,英伟达成为全球首家市值突破4万亿美元的公司,后来一度摸到5万亿的门槛儿。
但这个芯片帝国正被一群对手围猎。这场围列的参与者可以大致分成三股势力:
第一是博通领衔的定制芯片(ASIC)阵营,可以说是几乎所有大客户“叛逃”的技术后台。谷歌的TPU、Meta的MTIA、OpenAI即将推出的自研芯片Titan,背后都有博通的身影。
博通上季度AI收入84亿美元,同比暴增106%。根据Counterpoint Research预计,博通明年将控制定制AI芯片市场60%的份额。当英伟达的大客户们纷纷转向定制芯片,博通就成了这场围猎中最关键的“军火商“。
第二股是超大规模云服务商的自研芯片浪潮。谷歌的第七代TPU Ironwood峰值性能4.6 petaFLOPS,已开始对外出租;亚马逊的Trainium 2芯片正被Anthropic用来训练大模型,规模达50万颗;微软的Maia加速器持续迭代。这些巨头十几年前被英特尔卡过脖子,如今应该再也不想让英伟达再来一次。
第三股是传统芯片对手的反击。AMD的MI300X已部署在微软Azure上为ChatGPT做推理,拿下了OpenAI和甲骨文的大单;英特尔新任CEO陈立武用低价和低功耗的Gaudi 3抢市场。
黄仁勋喜欢说的一句话是,英伟达卖的不只是芯片,而是“AI工厂”。但眼下,想开工厂的人,不想只从他一家进货了。
01 大客户倒戈:谷歌、亚马逊要自己造芯
在挑战英伟达的队伍里,最让市场紧张的,是那些原本排队等着买芯片的巨头突然说:我们自己造。
谷歌是这条路上走得最远的。它研发张量处理单元(TPU)已经有差不多十年时间。过去这些芯片主要用于自家的云服务和内部工作负载,但今年2月份,谷歌开始将TPU租给Meta。这还没完,谷歌又和云公司Fluidstack合作往外租TPU。
谷歌的第七代TPU叫Ironwood,峰值性能4.6 petaFLOPS,比英伟达B200还略高一点,功耗却低不少。AI初创公司Anthropic已经计划用上百万颗Ironwood来运行Claude模型。去年11月下旬,SemiAnalysis创始人迪兰·帕特尔(Dylan Patel)曾感叹:“谷歌芯片越来越流行,可能意味着英伟达主导地位的终结。”

图:谷歌CEO皮查伊介绍第七代TPU Ironwood
亚马逊的AWS推出了Trainium芯片专门用来训练模型,还有Inferentia芯片专攻推理。
Anthropic正在用50万颗Trainium 2芯片训练模型,未来亚马逊还要给它建一个拥有上百万颗芯片的数据中心集群。

图:亚马逊两款芯片分别针对训练和推理
微软的Maia 100加速器还处于研发早期,专为Azure工作负载设计。Meta早在2024年内部已经部署了超过150万颗自研的MTIA芯片。它的逻辑很简单:与其让英伟达赚走73%的毛利,不如自己造自己用。

图:微软的Maia 100加速器
02 定制芯片的围剿
就在GTC开幕前五天,Meta一口气公布了四款自研MTIA芯片路线图,从300到500系列,全部瞄准AI推理,每六个月迭代一代。而帮Meta设计这些芯片的,正是博通。
博通专门做定制芯片(ASIC,专用集成电路),谷歌的TPU也是博通帮忙开发的。现在,博通占据了AI ASIC市场超过50%的份额。
2026年,在台积电115万片CoWoS晶圆产能中,博通预定量大幅增长到20万片,同比猛增122%。这些订单主要分给谷歌(60%到65%)、Meta(20%)以及OpenAI。其中,OpenAI年底将推自研芯片Titan,占博通所占晶圆产能的5%到10%,2027年将超过20%。

ASIC阵营的CoWoS产能预订和分配情况
另外,博通今年和OpenAI签了个大单,双方要一起开发定制AI加速器和机架系统,规模高达100亿瓦特,2026年底开始部署,预计2029年完成。
博通CEO陈福阳对自家公司的优势看得很清楚:英伟达的GPU虽然通用性强,但“全能”也意味着在特定任务上不够节省。而定制芯片恰恰是为特定场景而生,在推理这类任务上,ASIC的成本可比GPU低30%到50%。
03 老对手反击:AMD、英特尔的翻身仗
谷歌、亚马逊是客户变竞争对手,AMD、英特尔才是与英伟达对标的劲敌。
AMDCEO苏姿丰很早就定下方向——AI转型,她认为行业“对算力的贪婪需求”不会停。现在看来,苏姿丰赌对了。AMD市值从不到千亿美元涨到3500多亿,还签下了OpenAI和甲骨文的大单。
AMD的MI300X加速器已经部署在微软Azure上,并给ChatGPT做推理。192GB的HBM3内存,带宽5.3TB/s,内存比英伟达H100还高。2024年,AMD向微软、Meta、甲骨文出货了约32.7万颗MI300X。新一代MI325X也已经出货,MI350系列明年推出,官方称其推理性能提升35倍。

AMD的MI300X加速器
英特尔这位有些落寞的巨头,也在默默用力,Gaudi 3加速器定价只有H100的一半左右,128GB内存,功耗600W,比H100低100W。

英特尔Gaudi 3功耗更低
官方宣称在某些训练任务上比H100快1.5倍,性价比高2.3倍。戴尔、慧与、联想都在推Gaudi 3的系统。英特尔新任CEO陈立武上来就把AI芯片业务直接归到自己麾下,变成了“一把手工程”。
04 新秀突袭:Cerebras们的机会
除了老对手的穷追不舍,一批初创公司也在崭露头角。
最让英伟达紧张的大概是Groq。这家公司由前谷歌TPU工程师创立,专攻推理芯片,速度快、成本低。为了应对这种压力,英伟达去年12月砸了170亿美元,从Groq手里买下技术授权,还顺便挖走了核心团队。如此价格与阵仗,足以说明黄仁勋对Groq的重视程度。
Cerebras是另一家狠角色。它2015年成立,估值230亿美元,其设计的芯片有餐盘那么大,叫“晶圆级”芯片。今年1月,Cerebras和OpenAI签了100亿美元的大单。

Cerebras的CS-3芯片
Cerebras刚推出新的推理平台,基于它的CS-3芯片,号称比英伟达H系列快20倍,而价格只是零头。CEO安德鲁·费德曼( Andrew Feldman)表示:“打败800磅大猩猩的方法,就是拿出好得多的产品。更好的产品通常能赢。”
SambaNova在收购谈判和英特尔谈崩之后,自己又融了3.5亿美元,给企业客户做AI硬件和软件系统。Tenstorrent估值20亿美元,也是做GPU替代方案。还有d-Matrix、Etched、Positron AI……这一串名字,每一个背后都站着几亿甚至几十亿美元的投资。
这些初创公司有一个共同判断:AI正在从训练转向推理。训练再重要,也就是几个月的事,推理则是每天每时每刻都在发生的事。到2030年,推理将占全球AI计算需求的75%。而推理任务对成本敏感,对延迟敏感,最容易被专用芯片吃掉。
英伟达当然不会坐视不管。除了购买Groq的技术,它还将自家NVLink网络技术开放给第三方,英特尔、高通、富士通、Arm都拿到了授权。这意味着,以后别人家的CPU也能和英伟达的GPU更好地连在一起。英伟达的逻辑是:不管你用什么架构,都能和我家产品兼容。
英伟达的策略显然已经见效,埃隆·马斯克(Elon Musk)旗下xAI就选择了与英伟达深度绑定。
xAI的Colossus超级计算机几乎全部采用英伟达的Hopper和Blackwell系列GPU,目前规模已经超过20万颗,还在向百万颗迈进。在孟菲斯数据中心,光是芯片采购就花了数百亿美元。马斯克不但在122天内建成了Colossus,还公开感谢过英伟达的网络技术。
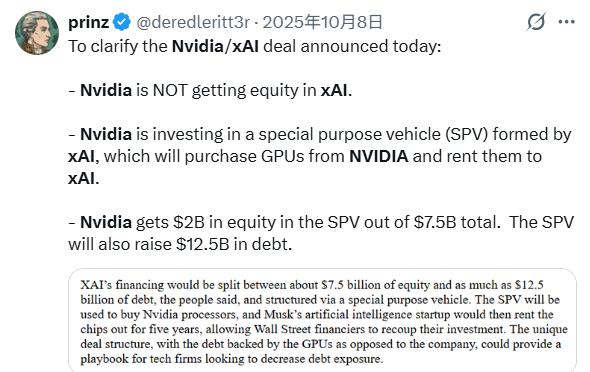
2025年10月,xAI通过特殊目的工具融资约200亿美元,英伟达直接投了20亿,这笔钱最终又回到英伟达账上买芯片。双方还一起参与BlackRock、微软发起的AI基础设施合作伙伴计划。
05 暗藏杀机:CPU复兴与电力墙
除了明面上的对手,英伟达还面临两个更深层的威胁。
一个是CPU的复兴。
过去几年,GPU光芒太盛,CPU的存在感显得暗淡许多。但智能体AI崛起之后,局面正在变化。智能体需要大量“编排”工作,在用户与各类AI智能体之间来回调度任务。这类任务GPU无法胜任,CPU才是主角。英伟达自己也承认,“在扩展AI和智能体工作流程方面,CPU正成为瓶颈”。
英伟达早在2021年就推出了数据中心芯片CPU Grace,如今第二代Vera已进入投产阶段。今年2月,该公司与Meta签下多年协议,首次大规模独立部署Grace CPU,并计划2027年引入Vera。美国银行预测,CPU市场规模有望从2025年的270亿美元增长至2030年的600亿美元。
但问题在于,产能跟不上需求。据路透社报道,AMD和英特尔已向中国客户发出预警:CPU将面临供应紧张。交付周期拉长至六个月,价格上涨超过10%。
AMD数据中心主管福雷斯特·诺罗德(Forrest Norrod)坦言:“过去六到九个月的需求增长前所未有。”英特尔发言人也表示,库存已降至“最低水平”。芯片分析师本·巴加林(Ben Bajarin)打了个比方:“晶圆不是树上长的,没法说多收10%就多收10%。整个行业都在紧巴巴地过日子。”
另一个威胁是电。
英伟达的B200 GPU,满配功耗达1200瓦,比上一代H100的700瓦又增加了71%。用于训练大模型的GB200机架,整机功耗达到120千瓦,必须依靠液冷才能运行。与之相比,一个美国普通家庭的平均用电量仅为1.2千瓦。换句话说,一个英伟达机架的耗电量相当于一百个家庭。

英伟达B200 GPU功率远高于同类竞品
数据中心的供电能力正在成为瓶颈。德勤对120家美国数据中心和电力公司高管的调查显示,72%的受访者认为,电网与供电容量对AI基建构成了“非常”或“极其严峻”的挑战。目前,全球仅有不到5%的数据中心能够支持单机架50千瓦以上的功率密度,而Blackwell配置的需求是60到120千瓦。
高盛预测,到2030年,全球数据中心的电力需求将增长165%。在弗吉尼亚这样的关键节点,电网并网申请的处理周期已拉长至四到七年。
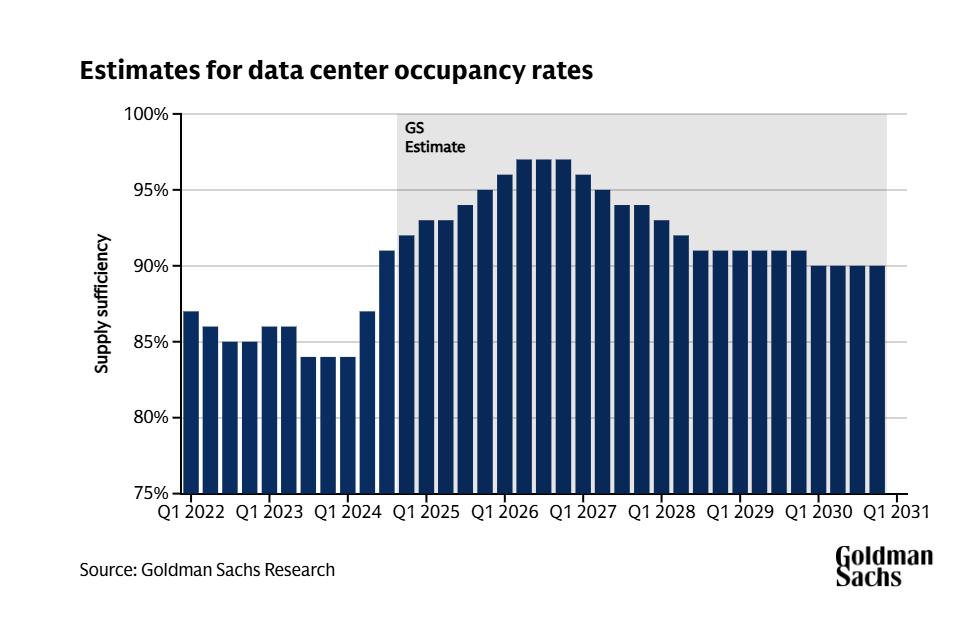
高盛预计,与2023年相比,到2030年,全球数据中心电力需求将增长165%
这意味着,英伟达的芯片即便订单再多,实际的部署数量仍将受限于供电能力。与此同时,功耗更低的替代方案迎来了窗口期。谷歌称,他们的Ironwood芯片的能效是第一代云TPU的30倍;英特尔更是将低功耗作为Gaudi 3的核心卖点之一,意在抢占总体拥有成本的优势。
当效率开始比性能更关键,游戏规则正在悄然改写。
06 护城河CUDA?
CUDA被称为英伟达最深的护城河,这个护城河会永远有效吗?
CUDA于2006年发布,比ChatGPT的问世早了整整16年。在这十余年间,英伟达持续投入巨额资源,即便在亏损阶段也未曾中断。数百万开发者掌握了CUDA编程技术,PyTorch、TensorFlow等主流深度学习框架均优先针对CUDA进行优化,cuDNN、cuBLAS等底层计算库历经无数次迭代。这套软件生态的建立,绝非一朝一夕之功。
但CUDA不是魔法。软件护城河,也是可以架桥的。
AMD的ROCm软件堆栈正在缩小性能差距。PyTorch已正式支持ROCm,AMD还投资做了ZLUDA——一个能让CUDA程序直接在AMD硬件上运行的兼容层。微软据说也在开发工具,用于将CUDA模型迁移到AMD芯片上。OpenAI的Triton 3.0已支持AMD Instinct加速器。
CUDA的锁定效应还在,但一年比一年弱。
今天,英伟达依然是全球盈利能力最强的公司之一,其产品性能仍保持领先地位,软件生态的壁垒也最为深厚。在大模型训练这一核心赛道上,短期内尚无任何对手能够撼动其主导地位。
但市场格局正在发生变化。训练仅占AI计算的一小部分,推理才是未来的主战场。在这一领域,专用芯片具备天然优势。超大规模云服务商自研芯片,并非出于技术理想主义,而是为了切实降低运营成本。英伟达高达73%的毛利率,每一分都代表着客户希望省下来的开支。
未来的AI芯片市场,大概率不会呈现赢者通吃的局面,而将走向两条腿并行的格局:英伟达继续在训练和高性能计算领域保持领先,而博通等厂商则在推理和定制化应用中切走越来越大的市场份额。
到底谁能笑到最后,不仅要看硬件的运算速度,还要看谁能在性能与价格之间找到那个最舒适的平衡点。
特约编译金鹿对本文亦有贡献


