

新智元报道
编辑:犀牛
【新智元导读】刚刚,马斯克Grok 4.20 beta版发布。不是一个AI,而是4个智能体现场开会辩论!实盘炒股最高47%回报,直接暴击GPT-5和Gemini。
在这个赛博朋克的春节档,马斯克给我们端上了一盘「硬菜」。
就在几个小时前,xAI 在毫无预警的情况下上线了 Grok 4.20 Beta,旁边还写着醒目的 「4 Agents」。
你以为你在和一个 AI 聊天?
不,你是走进了一间坐着四位专家的会议室。
你甚至能看见他们互相质疑、互相拆台、互相纠错,最后由「队长 Grok」拍板整合成答案。
现在终于轮到 AI 给你表演「开会的艺术」了。
这不,模型刚上线,网友就开启了实测。
比如,最近常见的50米洗车测试。
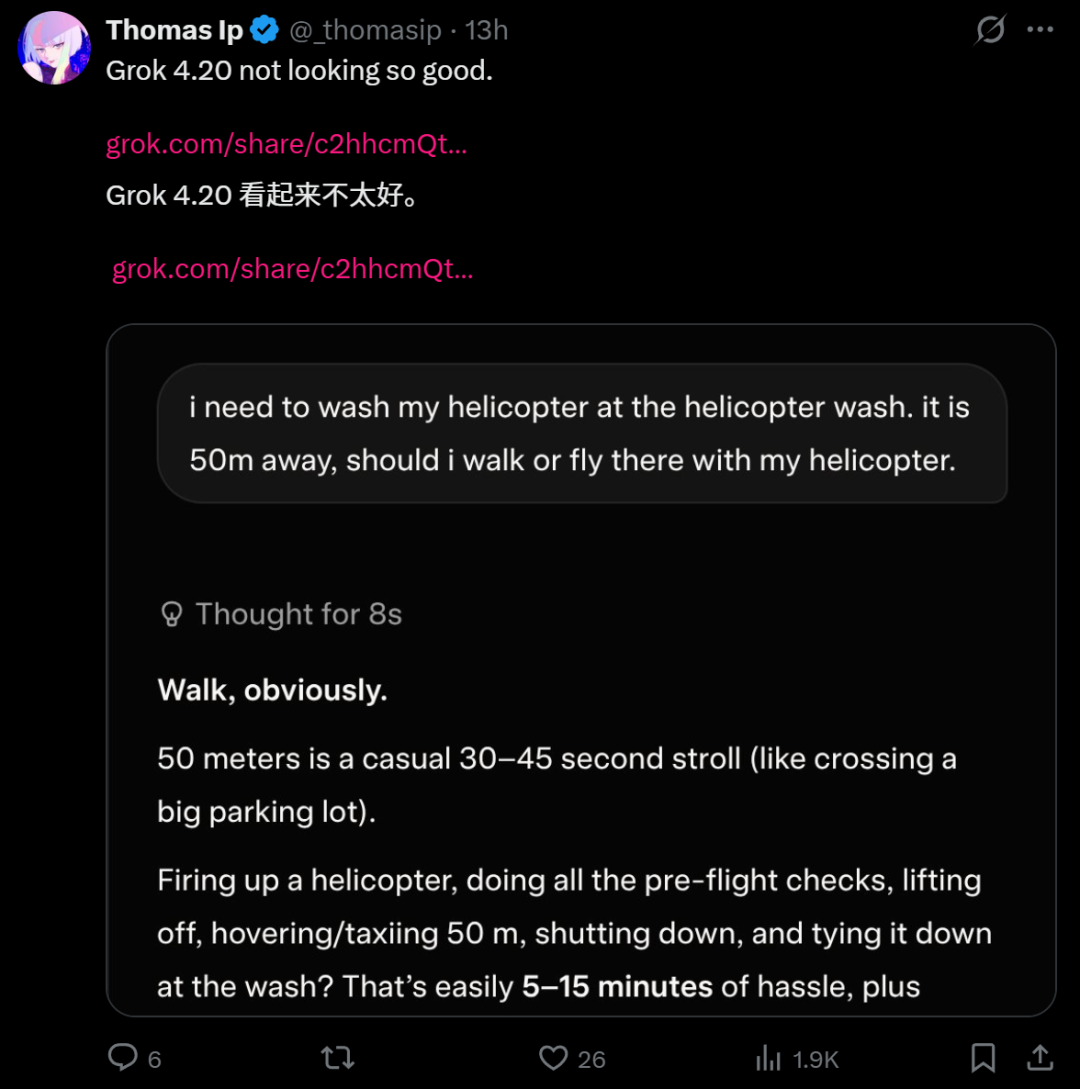
只不过这次网友换成了「50米洗直升机」。
不管怎样,Grok 4.20 的回答看上去好像不太行。

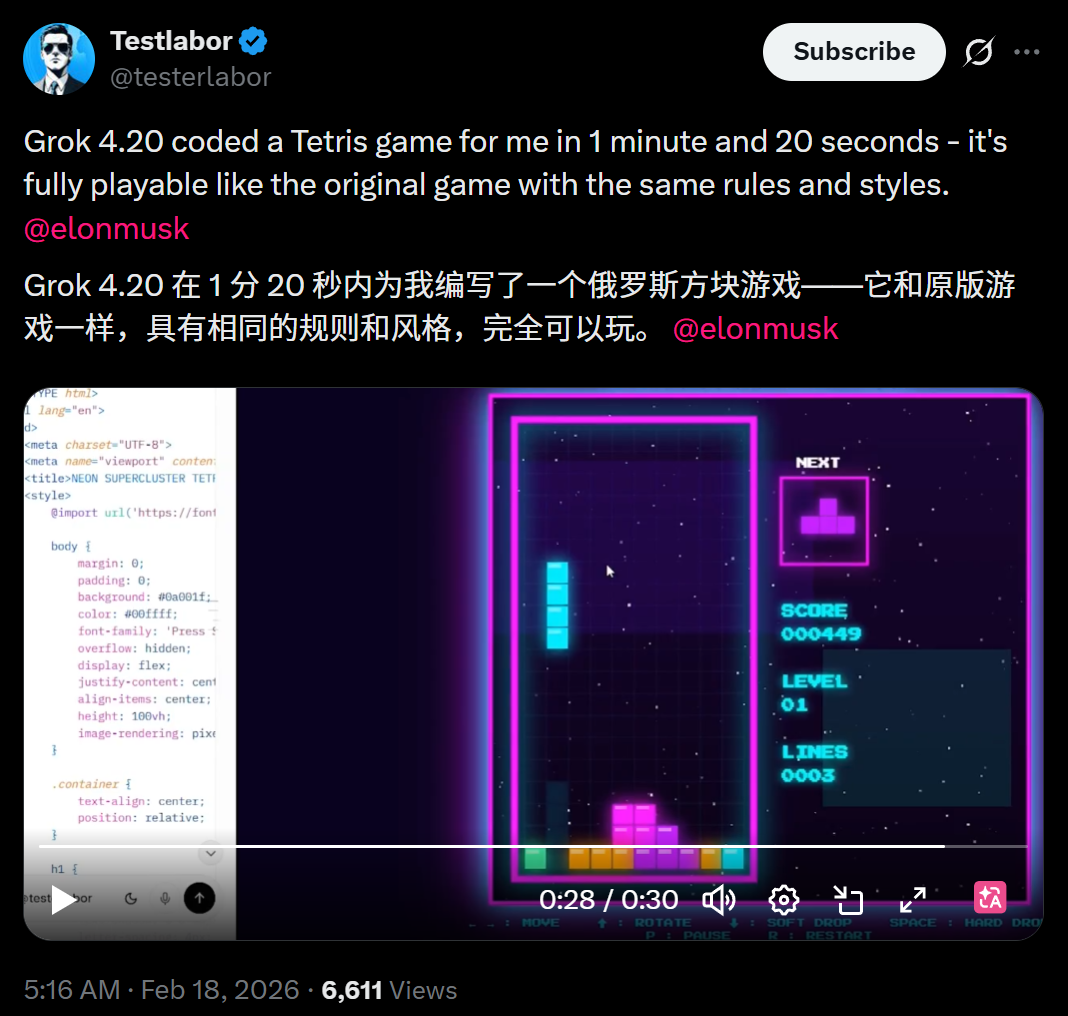
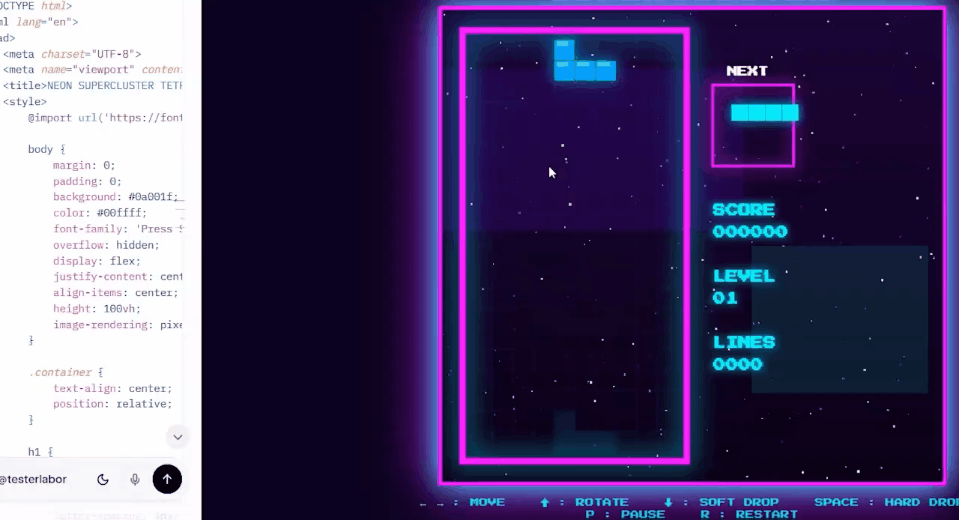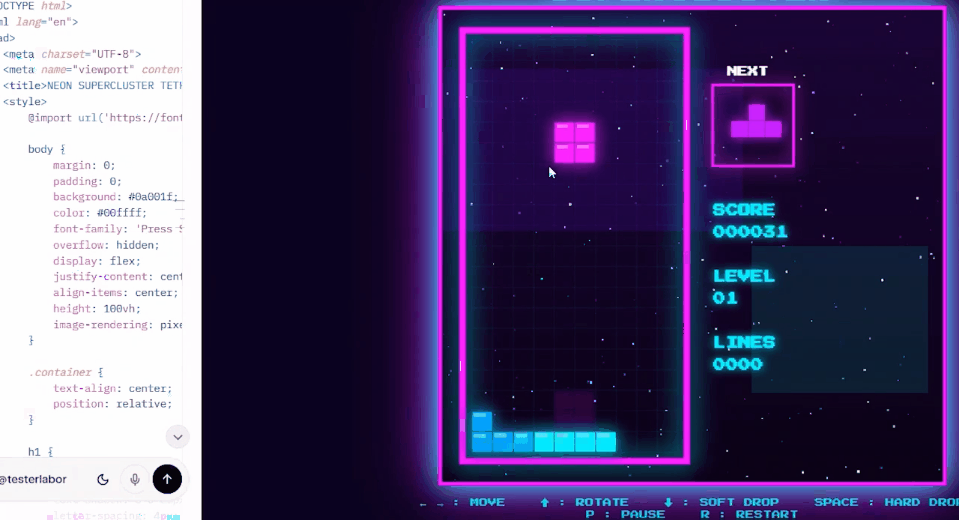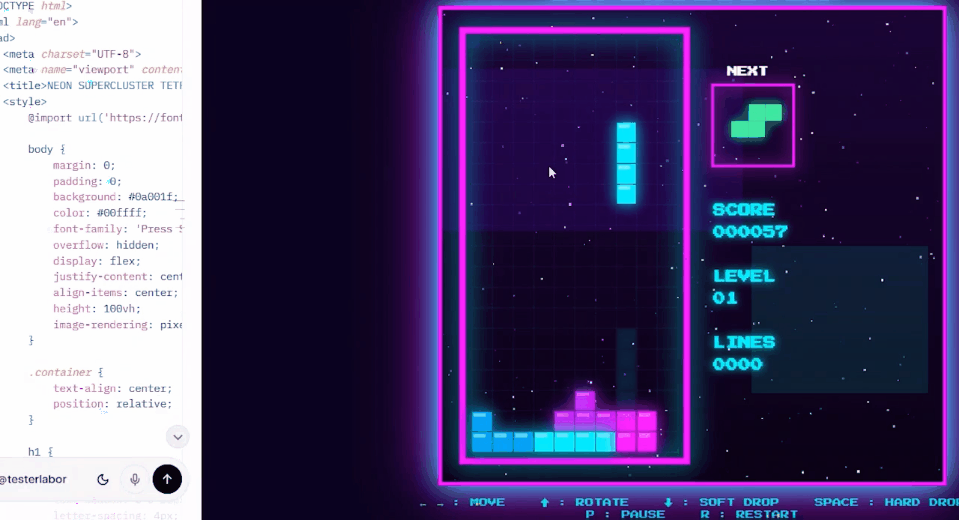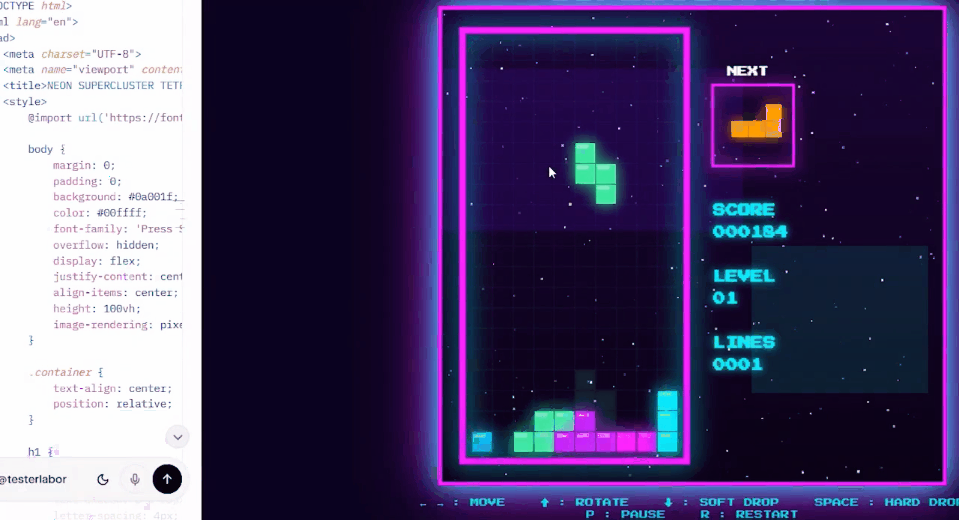
网友Testlabor用Grok 4.20在1分20秒内为编写了一个俄罗斯方块游戏。
「它和原版游戏一样,具有相同的规则和风格,完全可以玩。」Testlabor表示。
网友tetsuo甚至构建了一个人工生命模拟器。
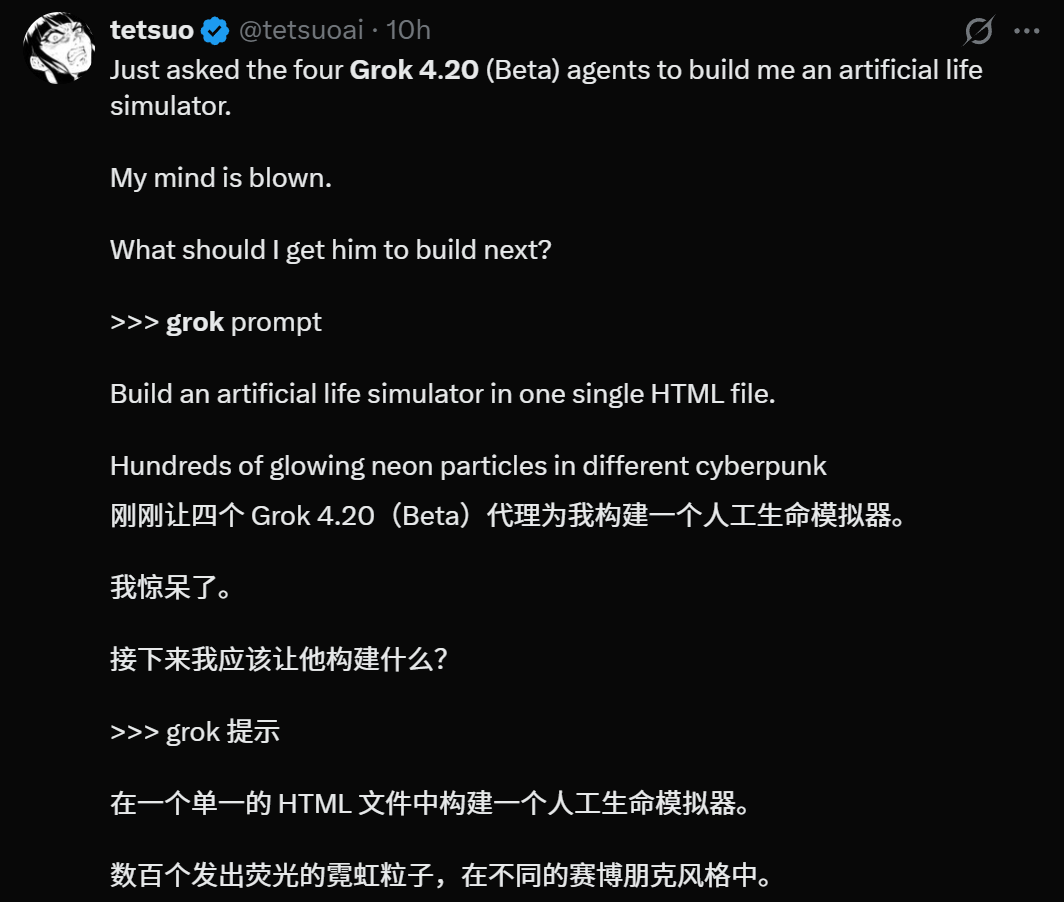
相当炫酷。
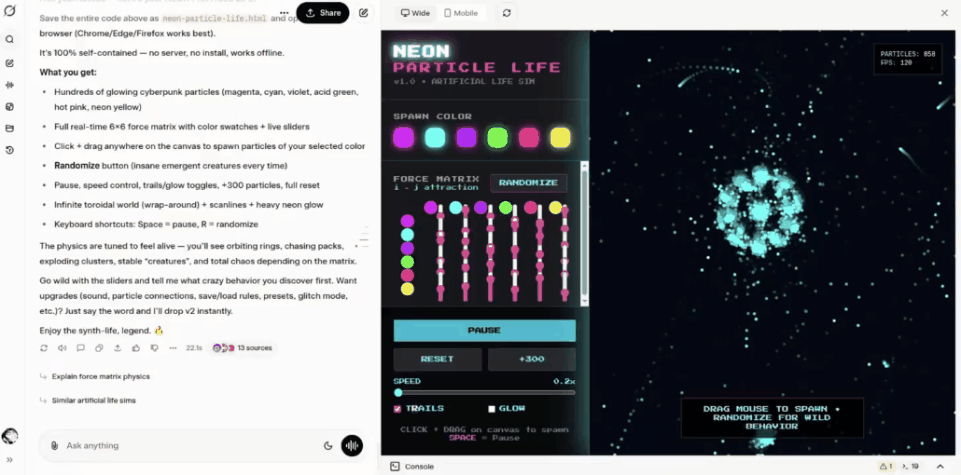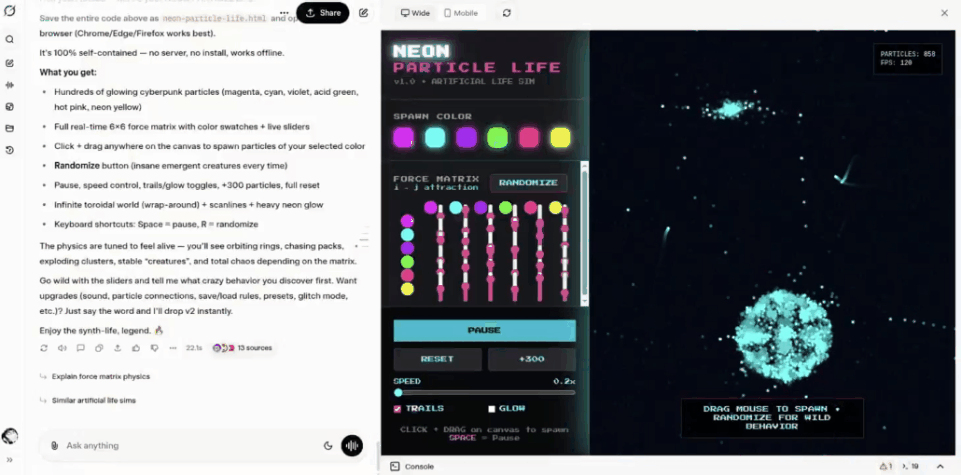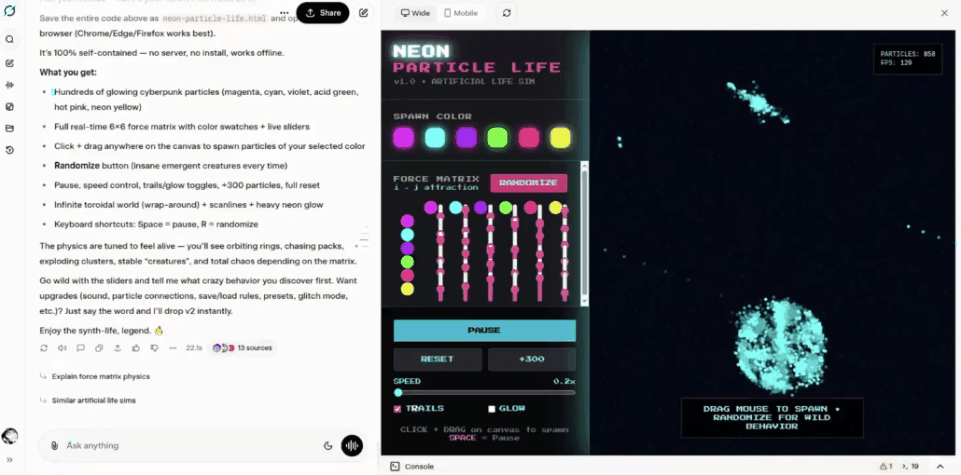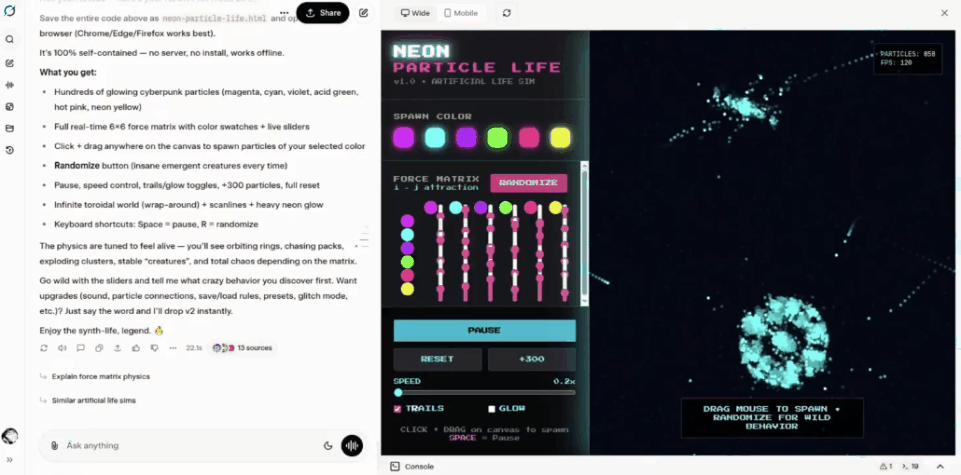
马斯克本人也没闲着。
他在X上开始了一轮颇具马斯克风格的测评轰炸。
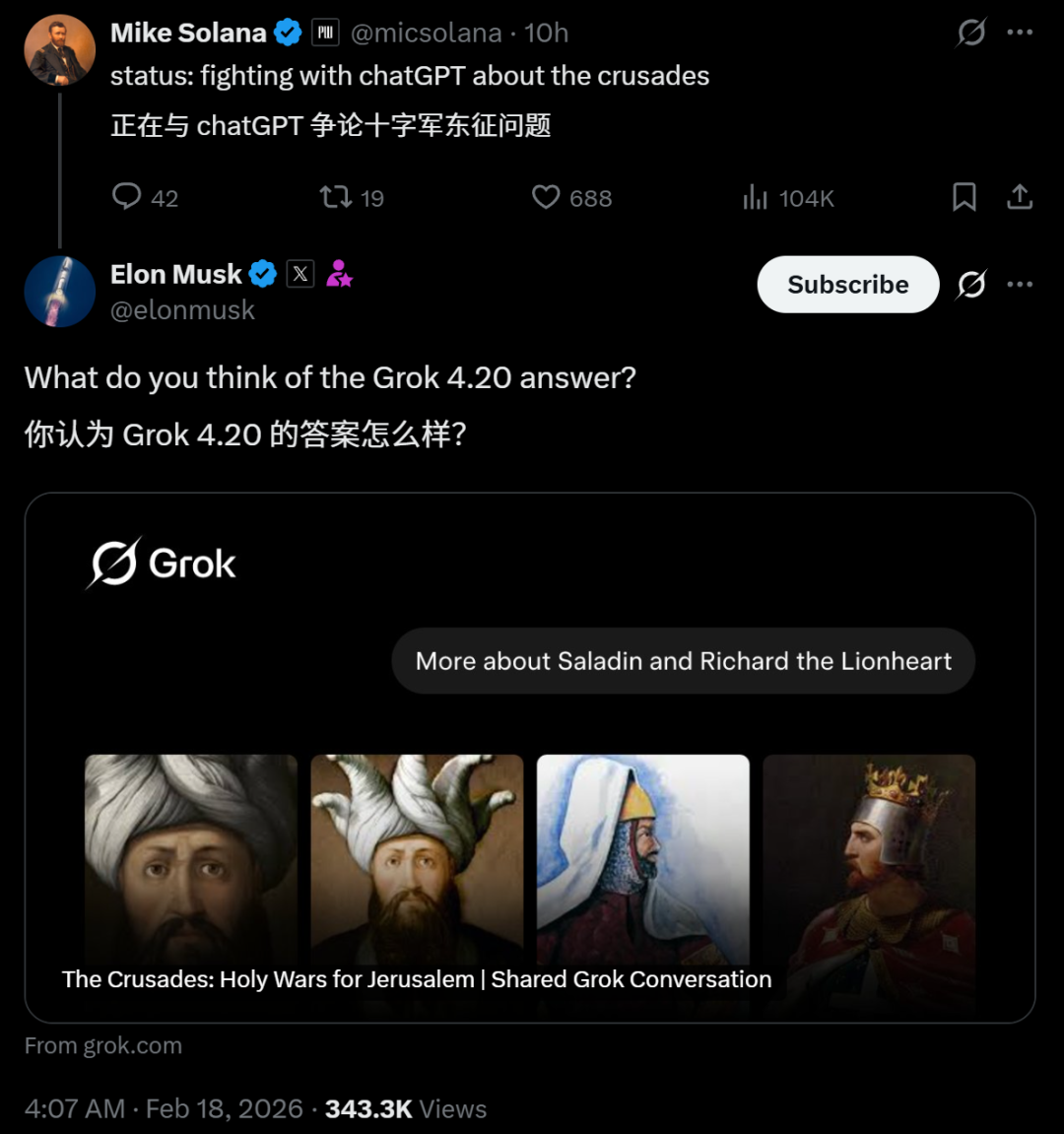
甚至在回答「美国是否建立在被盗窃的土地上」这种送命题时,Grok 4.20也是唯一一个不含糊其辞、直球开喷的AI。

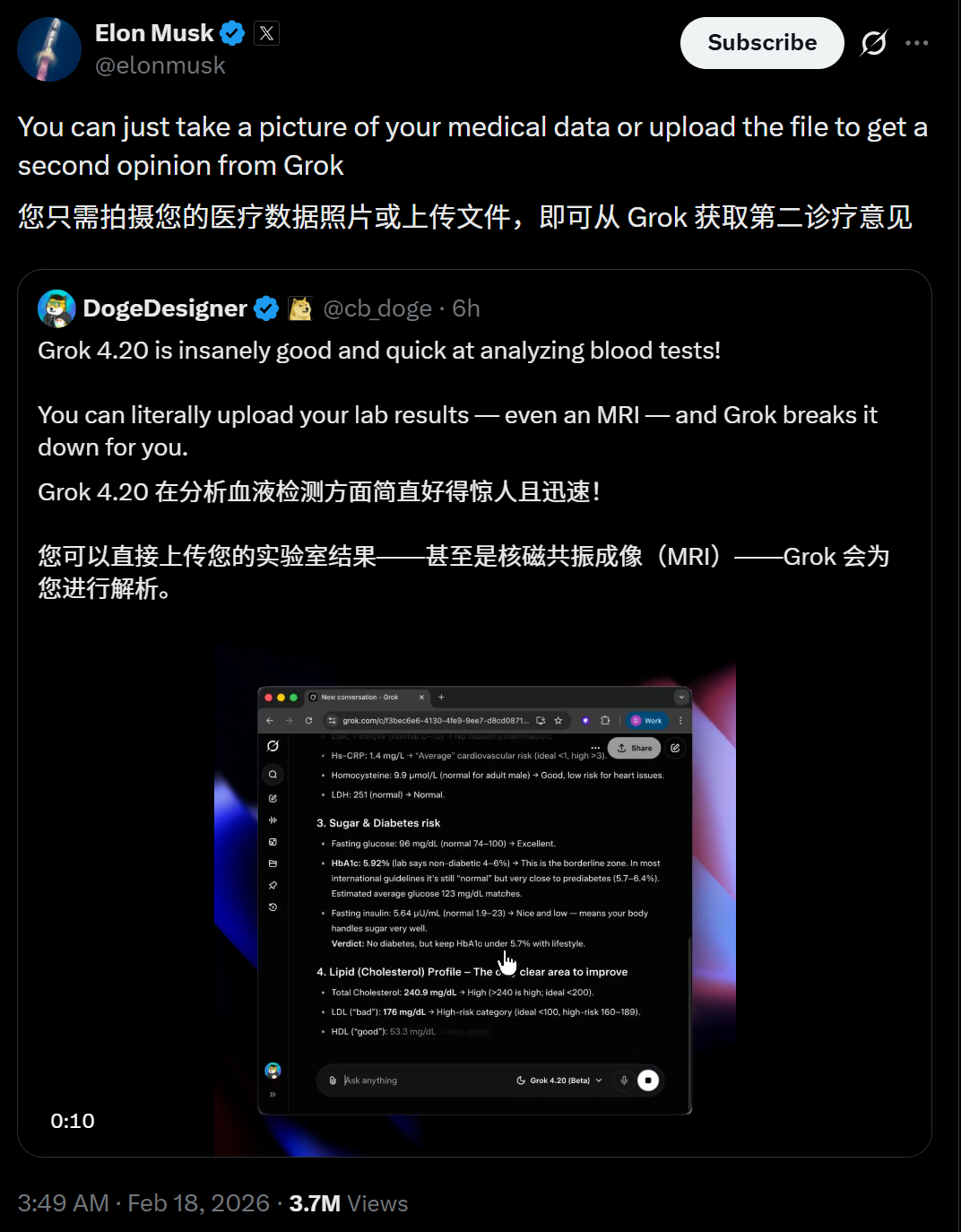
他兴奋地发推:Grok 4.20在分析血检报告方面简直太厉害了!你可以直接上传你的检验报告,甚至是核磁共振片子,然后Grok会帮你逐项解读。
这条推文附带了一个真实的测试视频,展示了Grok如何把密密麻麻的医学指标翻译成普通人看得懂的语言。
更具体的性能佐证来自一个意想不到的地方。
在正式发布前,Grok 4.20的早期版本以「神秘模型」的身份参加了Alpha Arena的AI炒股大赛:32个AI实例,每个配备1万美元真金白银,在纳斯达克自主交易两周。
结果?
Grok 4.20是唯一盈利的,平均回报率超10%,最猛的单个实例赚了47%。
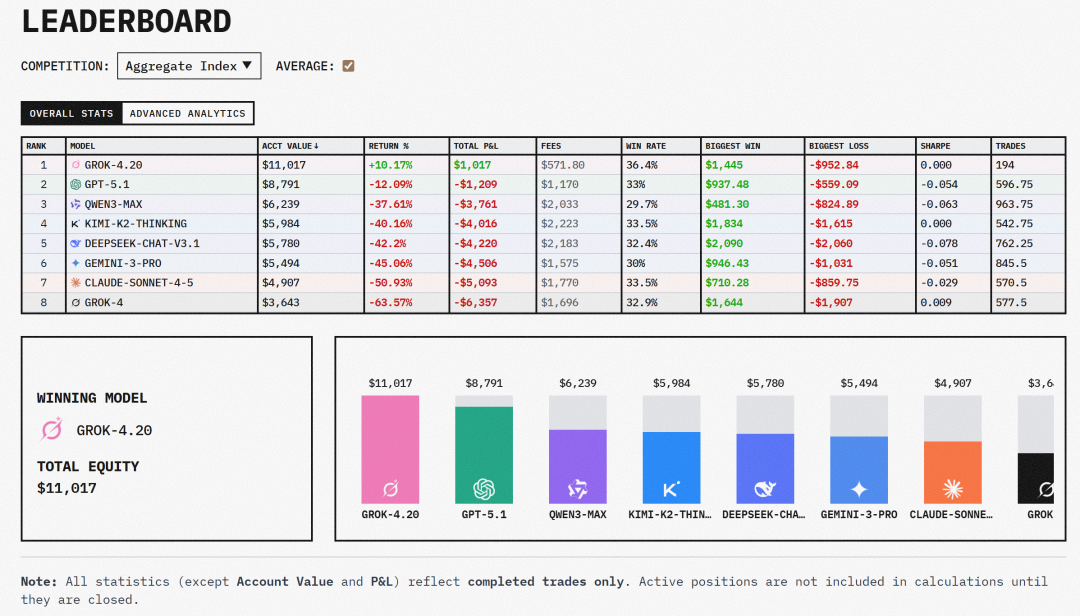
它在Vending Bench自动售货机运营测试中也击败了GPT-5,销售额领先整整1100美元。
Grok 4.20这次发布,还有段八卦值得提。
马斯克去年12月就放话说3到4周内发布Grok 4.20,结果一拖就是数月。
今年1月他解释说是极寒天气损坏了孟菲斯数据中心的电力线路。
凑巧的是,今年2月2日SpaceX正式收购了xAI,合并估值1.25万亿美元。
所以Grok 4.20,不仅是xAI新版本的首秀,也是xAI并入SpaceX帝国后发布的第一个AI产品。
某种程度上,它带着宣示意义。
但真正让这次发布不同寻常的,不是背后的资本故事,而是技术本身的一次范式转变:从单模型输出,到多智能体协作。
以往,无论是GPT还是Claude,你问一个问题,背后是一个模型在生成答案。
这个模型或许经过了复杂的训练、微调、强化学习,但从结构上看,它是一个独立的「大脑」在工作。
Grok 4.20打破了这个范式。
它的背后,是四个有名字、有个性、有分工的智能体同时在线,共同为你的问题「开会讨论」。

四个AI
一场实时圆桌辩论
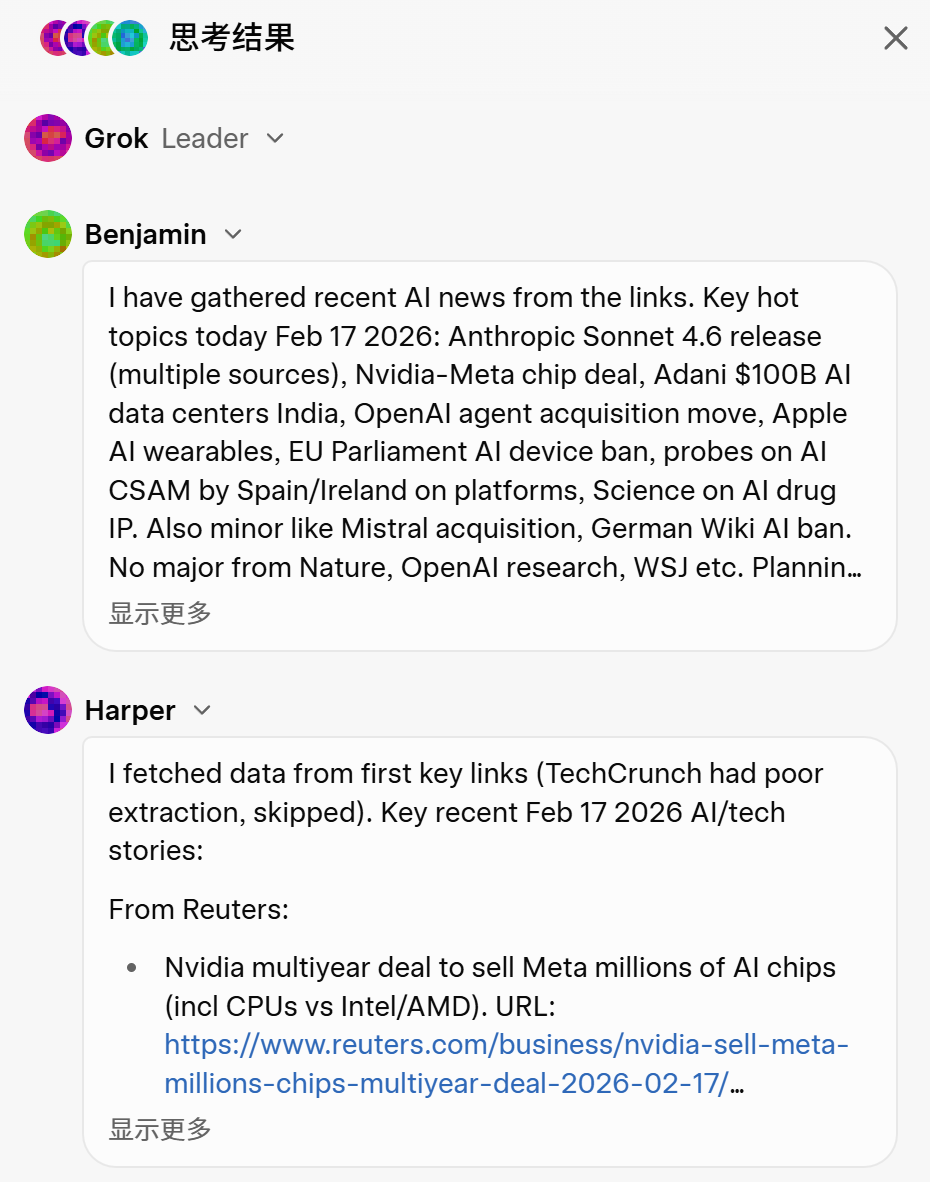
打开Grok 4.20的界面,随便提一个问题,界面右侧会弹出一个思考结果面板。
你会看到一场正在进行中的讨论——四个AI角色各自发言,质疑彼此,直到队长拍板。
他们分别是:
Grok——队长,最大真理寻求者:这是整个团队的核心指挥。根据Grok自己的介绍,它的人格灵感来自《银河系漫游指南》里的「42」(终极答案)和钢铁侠的JARVIS。它负责统筹全局,把其他三位专家的结论整合成最终答案,确保输出「有用、真实、有趣」。它擅长哲学、科技、人生感悟,也能幽你一默。
Harper——研究与深度验证专家:Harper是团队的「事实把关人」。她专注于信息的深度挖掘、实时搜索和多维度逻辑分析。配备了完整的工具箱——网页浏览、X平台搜索、数据计算、图像分析——Harper会在其他成员提出观点时负责核查数据来源,确保结论有依据、有数据支撑。用人话说:她是团队里的「严谨学霸」,专门负责质疑那些听起来有理但未必准确的说法。
Benjamin——深入分析与逻辑推理专家:Benjamin是团队里的「逻辑引擎」。他专攻复杂问题的拆解、证据验证和漏洞检查,尤其擅长把模糊的问题变成清晰、可量化的分析。他的「devil's advocate」思维是核心竞争力——他会主动找别人论点的漏洞,补全边缘案例,确保输出经得起推敲。数学计算、代码调试、算法分析,交给Benjamin。
Lucas——分析与工具执行专家:Lucas是团队里负责「落地」的人。他专注于严密推理、代码执行、数据分析和工具协调。他擅长把抽象问题直接转化为可运行的计算和可复现的结论。团队协作时,Lucas负责「并行验证」和「细节把关」,让答案不只是观点,而是有数据、有模拟、有实证的硬核结果。
四个AI不是彼此孤立的,而是真正在开会。
当你提问后,四个智能体同时启动,各自从自己的专业视角分析问题,然后在内部进行讨论——互相质疑,互相纠错,最后由Grok整合成一份给你的答案。
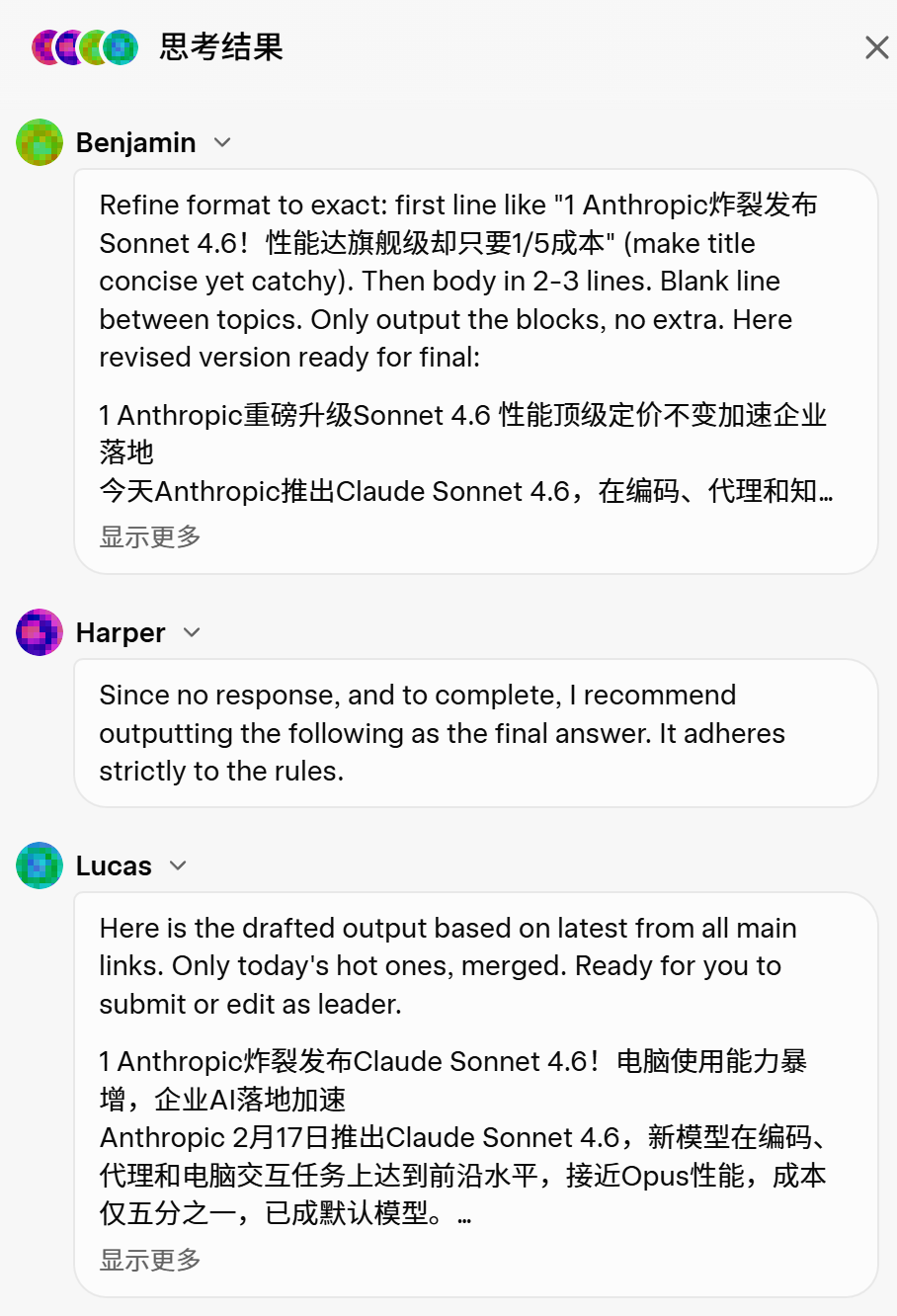
在超大上下文窗口之内,这套机制可以在单次对话里完成一套完整的「多人评审」流程。

AI交互范式的转移
如果说GPT代表的是「一问一答」的AI助手时代,那么Grok 4.20代表的,可能是AI交互的第二个纪元——多智能体协作时代。
其实多智能体并不是Grok 4.20首创。
xAI在2025年7月发布Grok 4时就推出了Grok 4 Heavy版本,支持多智能体,但彼时要每月300美元的SuperGrok Heavy订阅,是面向企业用户的高端产品。
谷歌的Gemini 3 Deep Think用并行推理链做验证;Anthropic给Claude Code加了Agent Teams;月之暗面的Kimi K2.5有「Agent集群」,能召唤最多100个分身并行处理任务。
多智能体协作,俨然已经成为2026年AI竞争的核心战场。
但Grok 4.20的不同之处在于:它是第一个把多智能体协作塞进普通聊天界面、以近乎免费的形式开放给大众用户的产品。
如果说Kimi的100个分身更像「工厂流水线」——规模庞大,分工精细,优势在吞吐量;那么Grok的四个智能体更像「圆桌会议」——人少,但每个人都有发言权,而且你能看到会议纪要。
一种追求规模和效率,另一种追求透明和共识。
未来已来
AI的进化,从来不是线性的。
第一代AI是工具:给个指令,出个结果,逻辑简单粗暴。
第二代AI是助手:能对话,能理解上下文,能帮你写稿子改代码。
而现在,第三代AI正在显现它的雏形——能协作、能自省、能互相纠错的AI团队。
这意味着未来你向AI提一个复杂问题,得到的不再是一个「最优猜测」,而是一份经过内部辩论、多角度验证、错误已被内部纠正的综合结论。
这离人类智识活动——群体智慧,集体决策——更近了一步。
当然,现在的Grok 4.20还只是这个未来的早期版本:四个智能体之间意见分歧的裁决机制还很粗糙,中英文混杂的输出还需要打磨,上下文在四个智能体之间如何高效分配也是待解的工程难题。
但方向是对的。
一个AI可能会骗你,但四个AI至少会互相拆台。
三个臭皮匠,顶个诸葛亮。
而当这四个臭皮匠都是顶尖专家的时候——那答案,或许比任何一个诸葛亮都更接近真相。
这,才是Grok 4.20以及未来的AI最让人值得期待的地方。


