
【导读】Feeling AI凭借CodeBrain-1在权威榜单Terminal-Bench 2.0中强势突围,仅次于OpenAI最新旗舰,位居全球第二。不仅打破了美系巨头的绝对垄断,更标志着中国AI在 Agentic AI(智能体)复杂任务规划与自主编码领域的工程化能力已达到世界顶尖水平。
在中国农历春节的前夜,全球科技界的空气中不仅弥漫着辞旧迎新的气息,更夹杂着一股前所未有的硝烟味。
Anthropic祭出了Claude Opus 4.6,OpenAI则以GPT-5.3-Codex强势回应。
双方在技术之巅的对决看似是老生常谈的「王座之争」,但在平静的水面之下,竞争的底层逻辑已然悄然改写。
全球大模型竞赛已正式从实验室里的「参数博弈」突变为残酷的「实战进化」。
这一次,巨头们不再沉迷于跑分数据的虚幻繁荣,而是将目光死死锁定了架构的严谨性与自主工作流的长效续航——
能否在真实商业世界中「破局」,成为了唯一的度量衡。
在硬核指标的正面交锋中,OpenAI和Anthropic两家巨头均选择Terminal-Bench 2.0作为实力背书:Opus 4.6在Agentic Terminal Coding Task上以 65.4%的胜率展现了卓越的智能体编码能力;而Sam Altman凭借5.3-Codex+ Simple Codex的组合创下的 77.3%(75.1%)高分,宣称其登顶全球编码性能之巅。
正如NVIDIA首席科学家Jim Fan所言:真实的终端环境是AI的「魔鬼训练场」。
在闭环环境中自我进化,已成为衡量模型工程能力的终极标尺。
令人振奋的是,在这一权威赛道上,中国的AI初创团队Feeling AI异军突起——其自研的CodeBrain-1在GPT-5.3-Codex底座模型的加持下,以 72.9%(70.3%)的惊艳战绩跃升全球榜单第二,成为前十强中唯一的中国新锐。

刚拿下Agentic Memory SOTA,Feeling AI又上大分
5天前,Feeling AI团队在深夜发布MemBrain1.0,LoCoMo / LongMemEval / PersonaMem-v2等多项主流记忆基准评测中拿下全新SOTA,反超MemOS、Zep和EverMemOS等记忆系统和全上下文模型。
在KnowMeBench Level III两个难度等级最高的评测中更是比现有评测结果大幅提升超300%。
在AI技术圈和资本押注的新风口——Agentic Memory方向先打出了第一张牌。
强大的记忆能力以及适配模型原生的层级化记忆系统,意味着Agentic AI正从模型能力逐步走向用户体验层面的范式跃迁。
紧随MemBrain 1.0的余热,Feeling AI昨晚又打出了第二张牌——CodeBrain。
作为具备动态规划与策略调整能力的「进化大脑」,CodeBrain-1迅速跻身权威基准Terminal-Bench2.0榜单全球第二,仅次于OpenAI 5.3-Codex的官配Simple Codex。
在Feeling AI的官方媒体中,其一直在强调动态交互是世界模型通向AGI的终极拼图。
其原创的跨模态分层架构提出了三层核心能力——负责理解、记忆与规划的 InteractBrain,负责能力执行的 InteractSkill,以及负责渲染呈现的 InteractRender,共同构成了其技术护城河。
目前已经亮剑的MemBrain与CodeBrain 都属于InteractBrain核心层,精准定位在复杂动态交互场景下的深度理解与长程规划。
如此看来,这两项在全球拿下极具说服力成绩的工作应该并非偶然,而是早有布局。
这也进一步解释了无论是用于Agentic Memory的MemBrain1.0还是用于确保模型任务规划和执行成功率的CodeBrain-1,其算法核心关注点也集中在服务于在复杂「动态交互」场景下的能力。
OpenAI在其官网技术博客中明确将Simple Codex 定义为 「针对长程软件工程任务的最优解」。
模型和Agent 框架的良好组合也许将成为未来大模型商业落地的标准形态。
Agentic Memory的记忆能力未来也许会成为Agent 框架的一部分,就像是一个外挂的记忆大脑,通过系统化的能力让模型更强。
一个能驾驭全球顶尖模型的中国框架,正是AI时代最核心的智能中枢。
对顶尖模型的深度驱动能力,意味着中国团队已在 AI 时代的「战术调度中心」占据高点,正在参与定义未来大模型的工程标准。
CodeBrain-1,会动态调整计划与策略的「大脑」
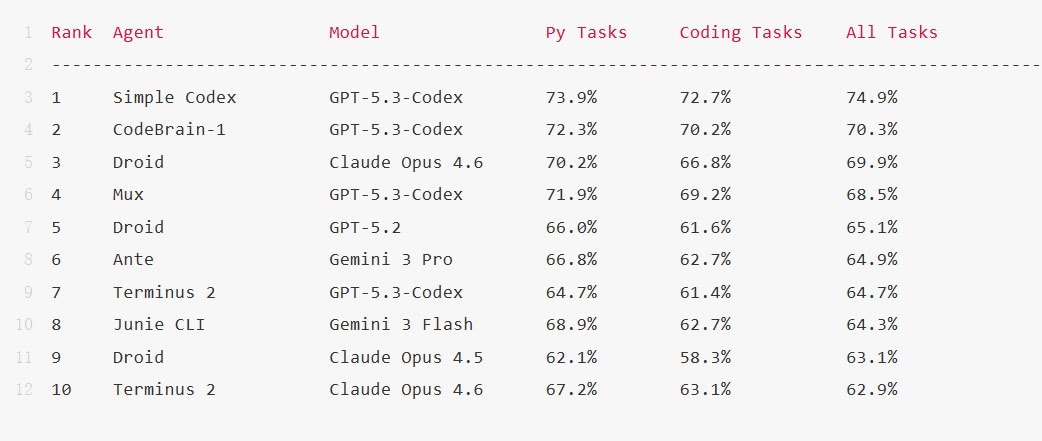
在Terminal-Bench官方评测网站的最新排名显示,CodeBrain-1仅次于Open AI的Simple Codex(GPT-5.3-Codex),Factory的Droid使用Anthropic最新基模Claude Opus 4.6排名第三。
榜单上还有一些大家熟悉的Agent或机构,如Warp、Coder、Google、Princeton等。

(官网截图)
Terminal Bench覆盖的任务类型非常广泛,其中既包括复杂的系统操作,也包含大量需要在真实终端环境中完成的编码任务。
CodeBrain-1的核心关注点,是「代码能否被正确写出并运行」。
在技术实现上,CodeBrain-1 专注打磨了两个直接影响「能否成功且高效地完成任务」的环节。
- Useful Context Searching:只用「真正有用」的上下文。在复杂任务中,信息不是越多越好,而是是否相关,减少噪音可以有效避免LLM的幻觉问题CodeBrain-1会根据当前任务需求和已有Code Base索引,充分利用LSP (Language Server Protocol) 的功能,提高关联信息的检索效率,有效辅助Code Generation的过程。比如当我们需要为一个游戏Bot规划任务时,需要先了解如何使用该Bot的API。CodeBrain-1在Coding过程中,借助LSP Search准确获取了move_to(target)、do(action)等相关方法的签名、文档和已有Code Base内的使用实例等信息,有效降低了关联信息检索的损耗和上下文干扰。
- Validation Feedback:让失败真正变成信息。CodeBrain-1可以从LSP Diagnostics当中高效定位,并补充错误相关的代码和文档,有效缩减Generate -> Validate的循环过程。比如CodeBrain-1编写的代码中出现了调用 on(observation, exec)(一个定义Bot Reaction的方法)时,出现了参数exec类型错误的问题,这时,LSP除报错argument type mismatch之外,还会额外提供该方法的caller示例、错误参数相关文档、以及exec这个参数在实现中如何被使用等辅助信息。
- 团队从Terminal Bench中筛选出了一个更聚焦的子集,共47条任务,均可以使用单一程序语言(Python)完成。在这一子集中,CodeBrain-1也表现出了稳定而一致的完成能力:关联代码和文档检索更高效;在代码检查和验证失败时,能更快定位问题。
此外,在Token的消耗方面,CodeBrain-1也展现出了不俗的表现,可持续降低用户成本。
对比Anthropic发布的技术文档,当基模均使用claude opus 4.6时,使用CodeBrain-1和Claude Code在两者均成功的Py Tasks子任务上所消耗的总Token大幅缩减了超15%。
CodeBrain-1在Terminal-Bench 2.0上的强势表现还不仅仅体现在真实命令行终端(CLI)环境下的端到端任务执行能力。
更重要的,团队进一步的赋予了它更高阶的能力——会动态调整计划与策略的「大脑」,它通过优化任务的执行逻辑和错误反馈机制,显著提升了模型在真实终端环境下的操作成功率。
CodeBrain-1提出了一种不同的解决方式。并非让 AI 直接「随意发挥」,而是反过来调整分工方式。
CodeBrain-1 负责在这些约束条件内,动态生成「智能」所对应的可执行程序,并根据实际反馈不断调整。
这里的「计划和策略」既可以作用在个体层面,也可以作用在群体层面。
对个体而言,它意味着角色可以根据自身目标、记忆和观察结果,持续调整日程、行为选择和对他人的态度对群体而言,它意味着一个组织可以形成共享记忆,并基于外部条件变化,调整整体规划和响应规则。
为了更直观地展示CodeBrain-1的能力,团队将它放入游戏场景中,作为一种行为与策略生成引擎。
#Case 1:游戏bot的实时驱动
在一些开放世界游戏中,它可以承担游戏伙伴的角色。玩家可以用自然语言表达意图,让bot执行。从理解自然语言中的需求——「帮我建个房子」、「造一把镐子」,到规划行动方案——「收集资源」、「清理工作环境」、「建造/制作」,最终生成并执行完整的行动脚本以实现目标,他可以有条不紊地应对任务,丰富玩家的游戏体验。
#Case 2:群体记忆驱动的战术演化
在「搜打撤」类游戏中,如果玩家长期走一条习惯性路线,并被多次观察到,敌对群体可以逐步强化这一「群体记忆」。
在后续地图构建与部署阶段,系统会据此调整整体策略,例如:

同时,还可以叠加行为表达规则,增强沉浸感,在热点区域成功发现玩家时高喊「抓到你了!」或者是在非预期区域遭遇时高喊「预判失误!」更进一步,可以配置简单的小队作战策略,比如前排冲锋,后排掩护。
这类行为并非单点脚本,而是由群体策略动态生成的结果。
为什么AI巨头都在,Terminal-Bench 2.0 上较量?
Terminal-Bench 是由斯坦福大学与 Laude Institute 联合打造的开源基准,被公认为 AI 智能体在真实命令行(CLI)环境下端到端执行能力的「金标准」。
与纸上谈兵的代码生成测试不同,它的严苛在于:
- 闭环实战环境: 在隔离的 Docker 容器中,AI 必须像人类专家一样,在真实的 Linux 生态中完成编译、调试、训练及部署。
- 高压长程任务: 89 个深度场景横跨软件工程与科学计算,不仅要求极高的逻辑跨度,更彻底杜绝了简单的「模式匹配」。
- 零容忍验证: 采用 0/1 判定准则,唯有产出符合预期的交付物(如修复的代码或运行的服务)才算通关,没有任何「模糊分」。
- 2.0 的「天花板」效应: 升级后的 2.0 版本大幅拉高了门槛。目前全球顶尖模型的解决率普遍难以突破 65%,这已成为大模型处理系统级复杂任务的「深水区」。
CodeBrain-1首次亮相便一举夺得全球第二,其含金量不言而喻。
以GPT系列为例,顶尖模型虽具备极强的逻辑推理链(Reasoning Chain),但常因「过度思考」导致执行链路冗长。
CodeBrain-1并不是一个「更会说话」的AI,而是一个由Code组成、能够持续调整计划与策略的执行型大脑,它巧妙地扮演了「调度中枢」与「效率校准器」的角色:它引导模型在常规操作中保持极速响应,仅在遭遇关键报错时激活深层思考。
这种对底座模型的精准驾驭,正是拉开商业化落地差距的核心变量。
鲁棒的闭环纠错(Error Recovery),高效的任务分解(Sub-goal Decomposition)和对环境感知的精确理解,在AGI的商业版图中,强大的Agent依然是「模型落地的必经之路」。
它不仅关乎任务分解的精度,更关乎在闭环环境中纠错与生存的韧性。
Sam Altman在GPT-5.3-Codex发布后的宣言也佐证了这一趋势:Codex已从单一的代码审查工具,蜕变为能横跨全生命周期、执行专业人士所有计算机操作的「全能代理」。
在OpenAI的蓝图中,模型与框架正进化为深度绑定的「智能全家桶」。
即便巨头环伺,垂直行业的深水区依然为优秀的工程框架留下了巨大的商业红利。
无论是系统级的Agent框架,还是精悍的开发者效能工具,这些「离用户更近」的触点都潜藏着爆发式增长的可能。
作为一家中国初创团队,Feeling AI能在OpenAI尖端模型发布的瞬间完成深度整合,并跑出全球领先的战绩,这不仅是工程响应速度的胜利,更是中国AI团队在全球工程化协同中占据制高点的有力证明。
在Terminal-Bench 2.0这种以「真实环境、长程进化」著称的硬核赛道上,紧随OpenAI之后摘得全球榜眼,其标志性意义不言而喻:中国创业团队已率先跨越了Agent从「对话玩具」到「生产力工具」的鸿沟,在「重塑工作流」这一战略高地上占据了领先身位。
在OpenAI与Anthropic构建的巨头生态中,中国团队选择以「框架定义者」的角色切入,展现了中国AI创新路径的独特性与韧性。
在全球底座模型的上半场较量之余,面向模型商业落地的下半场的竞争只会更加残酷。
这注定是一条没有捷径的拓荒之路,每一寸领地的攻克都需实打实的工程硬功,但这正是中国创业者在AI时代必须回答的「硬核命题」:不走捷径,方能定义未来。


