
2026 开年没多久,大模型圈就又要热到火起来了。
仅仅是 2 月前后这几天,Kimi 2.5、Qwen3-Max-Thinking、Step 3.5 Flash 就接连发布。Qwen3-Max-Thinking 直接对标 GPT-5.2-Thinking、Claude-Opus-4.5 和 Gemini 3 Pro 等旗舰推理模型,Kimi 2.5、Step 3.5 Flash 则瞄准了 Agent 时代的模型升级。
今天(2 月 6 日)凌晨,OpenAI、Anthropic 也几乎同时推出了小版本迭代的 GPT-5.3-Codex 和 Claude Opus 4.6。
但这一切还是刚开始,阿里 Qwen 研究员郑楚杰在 Qwen3-Max-Thinking 发布时强调这是 Qwen 迄今为止最好的模型,同时又透露「Qwen 3.5 的发布也指日可待」。

图片来源:X
指日可待的不只是 Qwen 3.5。
1 月初智谱上市,智谱首席科学家唐杰就在内部信中透露即将推出新一代模型 GLM-5,最近南华早报的披露把发布时间进一步缩小至「春节前」。而以「海螺 AI」出圈的 MiniMax,也会同期推出新一代大模型 MiniMax M2.2。
稍早前几天,The Information 不仅进一步佐证了 Qwen 3.5 的即将发布,还援引内部人士报道称,字节跳动将于 3 月推出下一代模型矩阵,包括大语言模型 Doubao 2.0、图像生成模型 Seedream 5.0,以及视频生成模型 SeedDance 2.0。
至于去年春节期间引爆全球 AI 圈的 DeepSeek,其下一代模型 DeepSeek V4 是否继续在春节期间发布发布还存疑,南华早报的消息是继续更新 DeepSeek V3 系列。

图片来源:DeepSeek
但无论 DeepSeek 下不下场,这场春节前后的大战都会是空前的。除了小版本迭代的 GPT-5.3-Codex 和 Claude Opus 4.6,内测代号「Snow Bunny」的 Gemini 3.5 以及代号「Fennec」的 Claude(Sonnet)5 也都流出了部分基准成绩和测试表现。
简言之,中美头部玩家几乎在同时推进一场大版本迭代。它们所竞争的,也不再只是参数规模或榜单排名,而是谁能定义 2026 年的 AI。
一切为了 Agent,新一代模型的三大升级
如果把过去两年的大模型竞争总结为「更大、更强、更全」,那么 2026 年这一轮更新,方向已经明显变了。
从目前披露的信息看,不论是国内的 Qwen、GLM、DeepSeek,还是海外的 Gemini、Claude,新一代模型的升级重点明显有所不同,一方面是 RL 强化学习的再引入,另一方面则是大家不再满足于「能力」,而是更多「实用」。
第一,推理不再是少数旗舰型号的专属卖点,而正在成为下一代基础模型的默认能力。
智谱在上市后释放的信号非常清晰:GLM-5 不再强调参数规模,而是强调复杂任务的一致性完成能力,包括长链路推理、跨文档理解以及工具调用的稳定性。这意味着推理不再是「多想一步」,而是模型默认的工作方式。
2 月刚发布的阶跃星辰开源模型 Step 3.5 Flash,更是明确了这一点,在 196B(激活 11B)的参数规模下不仅实现了更强的推理,还能做到秒回应。一个核心的技术关键是,Step 3.5 Flash 采用了 MTP-3(三路多 Token 预测) 技术,模型在生成当前内容时,就能同时预测后续多个 Token。
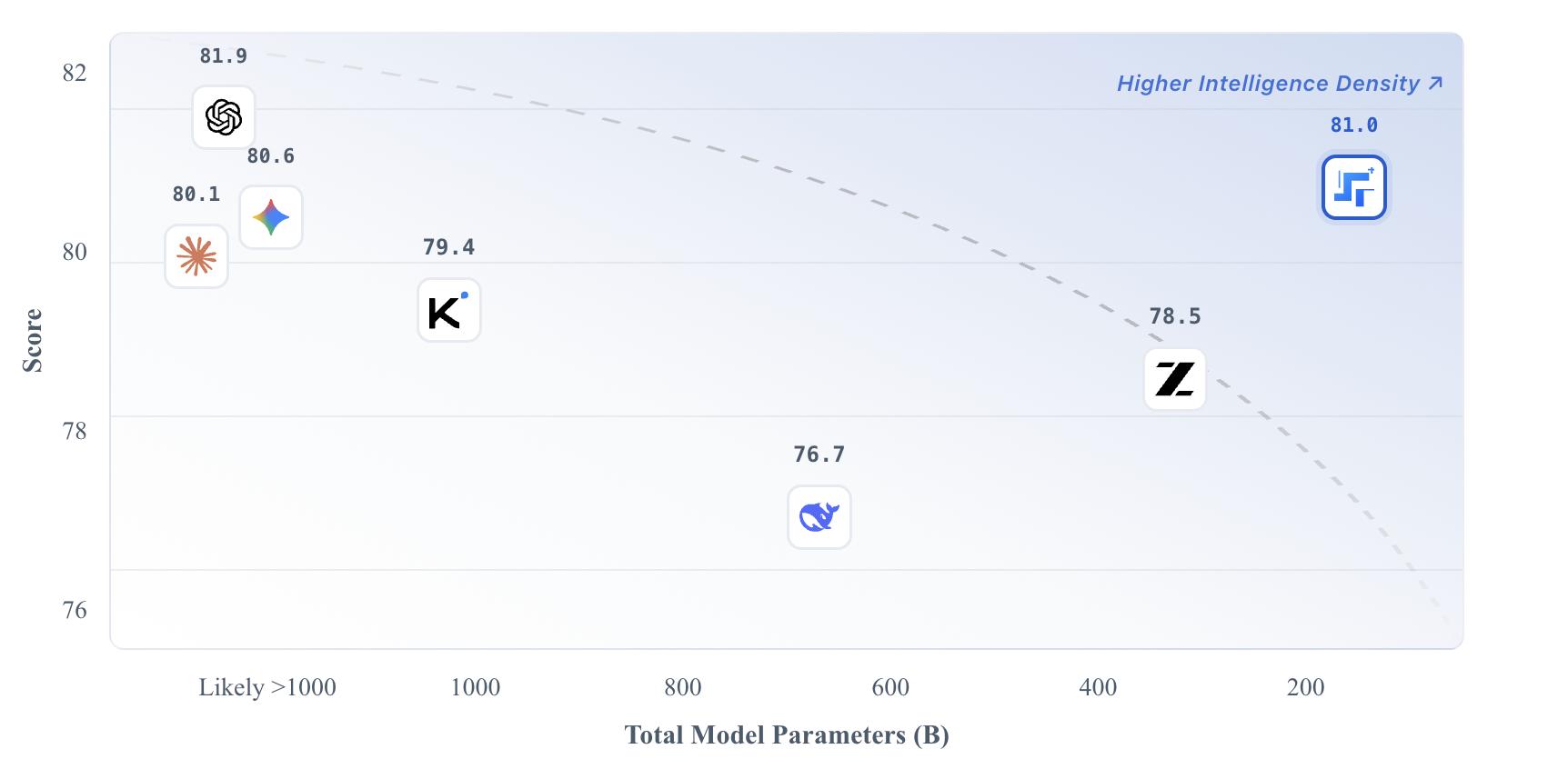
右上角为 Step 3.5 Flash,图片来源:阶跃星辰
在海外,内测代号为 Gemini 3.5 同样被曝出强化了深度推理模式,并允许在速度与深度之间动态切换。这类设计背后的共识是:推理能力如果不能按需调用,永远只是榜单能力。
第二,长上下文也仍然基础模型的升级重点。
2 月 3 日,腾讯混元后,腾讯混元团队发布了姚顺雨担任首席 AI 科学家后的首篇论文,推出了 CL-bench 基准测试,核心就是瞄准了大模型在「上下文学习」(现学现卖)上的痛点。
DeepSeek V4 虽然还没发布,但在 1 月刚刚发布了一篇关键论文,提出了全新的「Engram 条件记忆」机制,能在计算量较 MoE 减少 18% 的情况下,在 32768 个 token 的长上下文任务中,反超同参数量的 MoE 模型。
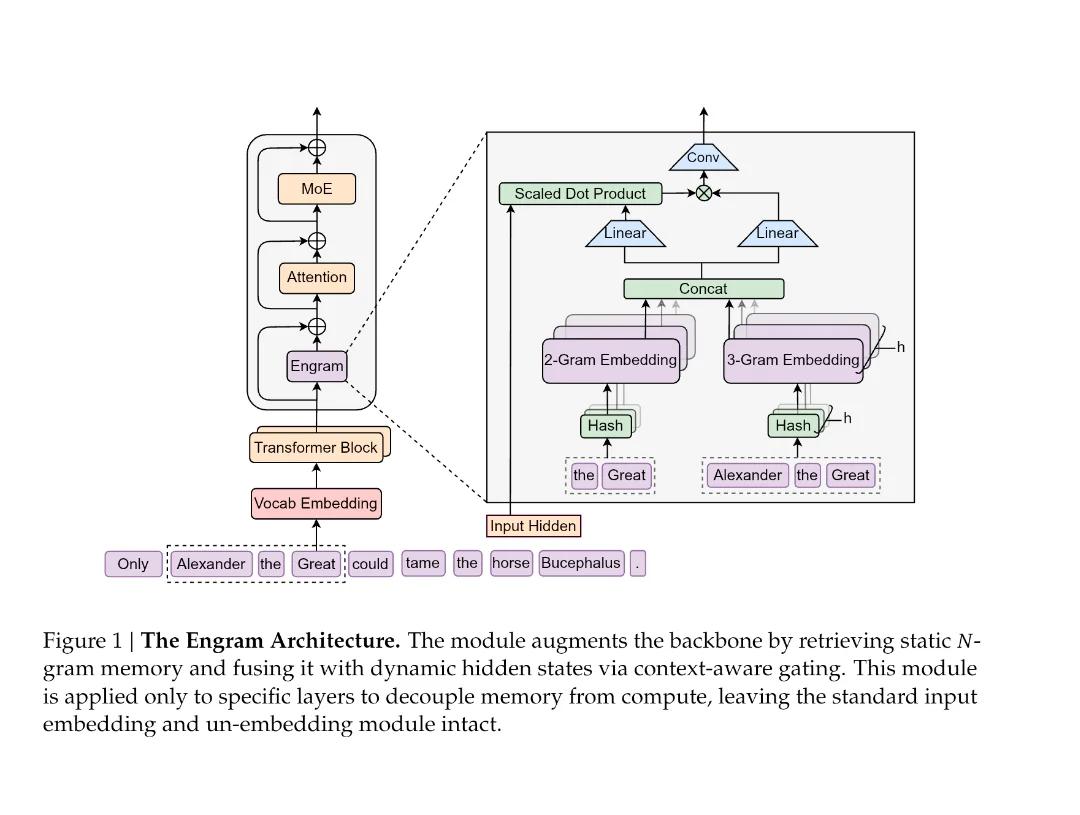
图片来源:DeepSeek
同样的逻辑也体现在 GLM-5 与 Gemini 3.5 的设计传闻中:长上下文被更多用于真实工作场景,比如跨文件代码分析、多文档合并推理、长时间 Agent 任务,而不是一次性塞满文本。
这意味着,长上下文正在从「指标」变成「系统能力」。
第三,Agent 不再是 Demo,而是 AI 系统的核心。
尽管我们已经看到了豆包手机助手引发的热议,以及 AutoGLM 的开源热潮,但 2025 年的 Agent 更多还会停留在展示阶段。不过 2026 年,Agent 正在重新定义基础模型,并进一步改变 AI 体验。
Qwen、智源以及 DeepSeek 之前的论文都反复提及工具调用能力和多步骤任务。这背后指向的是同一个问题:模型是否能在较少人工干预的情况下,完成一个完整任务,而不是中途崩溃。
阶跃星辰的 Step 3.5 Flash 更是「为 Agent 而生」,打造了新的基础模型结构,大量升级也是围绕「从推理到执行」的闭环进行优化,强调模型的规划、调用工具、执行长流程任务的能力,还有很快的是输出表现。
包括代号 Fennec 的 Claude 5 也被曝出一种「蜂群模式」,强化了多 Agent 协作与长任务保持能力。相比单次回答是否聪明,Claude 5 更关注在复杂工作流中,模型是否能保持角色、目标和上下文的一致。

图片来源:APIYI
这类能力一旦成熟,模型的形态就不再只是「对话框里的助手」,而更多会成为嵌入各种系统的「发动机」。
春节将至,这场模型大战在看什么?
为什么偏偏集中在 2026 年春节前后?原因其实不复杂。
一方面,去年春节 DeepSeek 的意外爆发,已经证明这个时间窗口可以承载巨大的技术关注度;另一方面,新一轮强化学习与推理训练周期在 2025 年底基本成熟,多家厂商的下一代模型自然在年初进入集中释放阶段。再叠加上市、融资与全球竞争节奏,春节反而成了一个罕见的「同步窗口」。
但时间点只是背景。真正让人在意的,这场春节模型大战会发生什么?
从从目前各方释放的节奏看,这不会是一两款模型的发布,而更像一轮连续出牌。这意味着,从春节前一两周到 3 月初,行业很可能进入一个罕见的「连续发布」:每隔数天,就会有一家头部厂商放出新模型或关键能力更新。
但这种节奏也意味着,单一模型很难长时间吸引广泛的注意力,仍然只会有少数模型可能成为绝对的讨论热点,这对模型本身以及各家的营销都是一个很大的考验。
图片来源:DeepSeek
而与过去不同,这一轮模型发布后,很可能不会经历漫长的评测周期。原因很简单,大多数新模型都会在发布同时开放 API 或产品入口,开发者与普通用户几乎可以即时上手。再加上推理、Agent、长上下文等能力本身就容易被直接体验,模型之间的差距会迅速在真实使用中被放大。
换言之,春节期间很可能会出现不同模型在相同任务下被大规模横向对比。不是基准测试,而是写代码、写方案、做多步骤任务、调用工具等真实场景的对比。一旦这种对比在社区和社交媒体扩散,模型的优劣排序会在极短时间内形成共识。
换句话说,这一轮大战的第一阶段,很可能不是发布本身,而是发布后的实际使用反馈。
当然,并不是每一轮模型更新都会带来代际变化。过去两年,很多版本升级更像是性能线性提升:更快、更准、更长。但从目前各方释放的信号看,2026 年这一轮更新,可能第一次同时涉及训练方式、推理模式与模型定位的变化。
如果多个厂商的新模型都在强化学习、推理架构、工具调用与系统整合上完成切换,那么这一轮更新带来的,将不只是能力提升,而是模型工作方式的变化。
对于开发者来说,这意味着调用方式与应用结构可能需要重写;对于厂商来说,这意味着模型可以从「功能组件」变成「系统底座」;对于行业来说,这才是真正意义上的代际跃迁。
春节前后是否会出现这种跃迁,是这场大战最值得观察的长期变量。
写在最后
模型发布本身的热度只能持续数天,但入口的占据却会持续数月甚至更久。过去一年里,无论是 ChatGPT、Gemini 还是豆包,真正拉开差距的并不是模型本身,而是它们进入用户与开发者日常使用的速度。
因此,这场春节大战的真正胜负,很可能不取决于谁先发布,而取决于谁能在发布后被更多用起来,进入办公软件、进入开发工具,甚至进入操作系统。
模型能力的差距,可能只会存在几周,但入口与调用习惯一旦形成,差距就会被放大。
从这个角度看,今年这场春节前后的更新大战,可能影响未来一年的全球大模型格局。谁能在能力之外率先完成落地,谁才更有机会在这一轮大升级中占据主动。


