
最新最强的开源原生多模态世界模型——
北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。
图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
先感受一下它的高精度操作:一句话消除手写痕迹。

第一视角漫游动态3D世界:

要知道,现在AI迭代的速度,正在刷新所有人的认知。
尤其是在文生视频这条赛道上,几乎每个月都有新技术出来“搞事情”。
肉眼可见,AI视频一个比一个真,一个比一个长。
but,先别急着鼓掌——
真正的赛点,早已不是“像不像”,而是“懂不懂”。
它知道桌子上的苹果被拿走后,那里应该变空吗?它明白你转身之后,背后的场景依然存在吗?如果答案是否定的,那再逼真的视频,也不过是“高级的GIF”。
现在,致力于攻克这一终极难题的玩家,终于带着悟界·Emu3.5来了。
从官方放出的demo来看,Emu3.5生成的作品展现出极强的连贯性、逻辑性,尤其让AI模拟动态物理世界的能力又双叒增强了。
它能让你以第一人称视角进入它所构建的虚拟世界。你的每一次移动、每一次转身,它都能动态构建出你下一步应该看到的场景,全程保持空间一致性。
除了上面展示的探索3D游戏世界,还能第一视角参观阳光下的客厅:

在火星上开卡丁车也很丝滑:

由于掌握了世界运行的内在规律,它不仅能像专业设计师一样,进行高精度、可控的图像编辑:
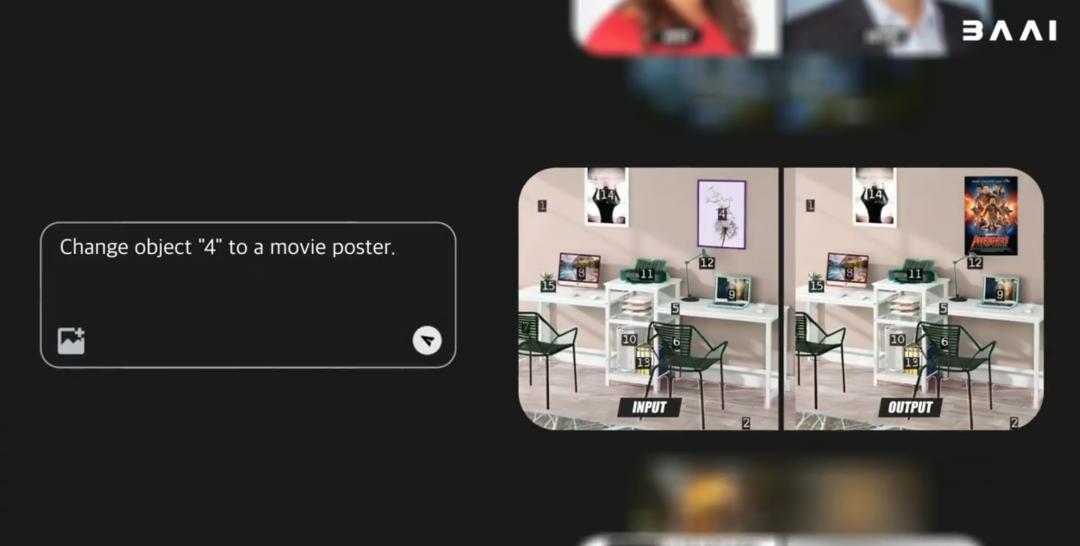
还能像拍电影一样,生成图文并茂的视觉故事:

从测评成绩来看,悟界·Emu3.5的表现也极其亮眼——在多项权威基准上,性能媲美甚至超越了Gemini-2.5-Flash-Image,没错,就是那个Nano Banana,在文本渲染和多模态交错生成任务上优势尤其显著。
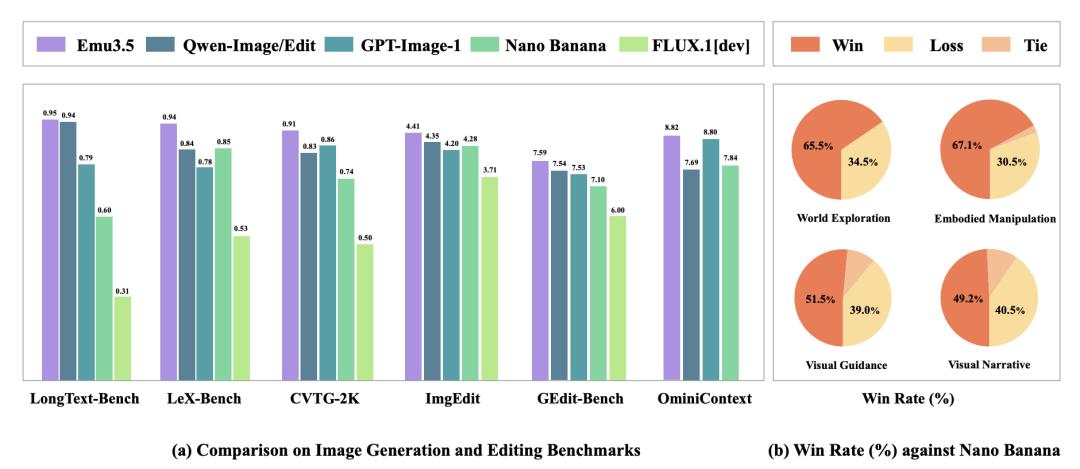
Emu3.5的命名,就揭示了它的定位:世界模型基座。
顾名思义,它要做的是世界模型的基础模型,这等于是在AI领域开辟了一条全新的赛道。
那么,这样一个被寄予厚望的模型究竟有多强?来看更多案例。
像智能体一样理解长时序
核心能力:世界探索与具身操作
这是Emu3.5最核心、最能体现其“世界模型基座”本质的能力。它能像一个智能体(Agent)一样,理解长时序、空间一致的序列,模拟在虚拟世界中的探索和操作。
比如下面这个“整理桌面”的任务,就是通过以下指令一步步实现的:
- 先把桌上所有东西清空。
- 把所有线缆解开并分类。
- 用扎带把线缆捆好。
- 用理线槽把线缆隐藏在桌下。
- 最后把桌面物品摆放整齐。

进阶能力:视觉指导与复杂图像编辑
正因为掌握了动态世界演变规律,Emu3.5尤为擅长提供具有连贯性和指导意义的视觉内容。
当给了Emu3.5一张狐狸的草图,并给出一系列指令“把它变成3D模型、3D打印出来、再上色”后,它直接一步步生成了从草图到最终手办形态的完整视觉流程。整个过程中,狐狸的核心特征和神态都得到了完美保留,扛住了长时程创作的挑战。
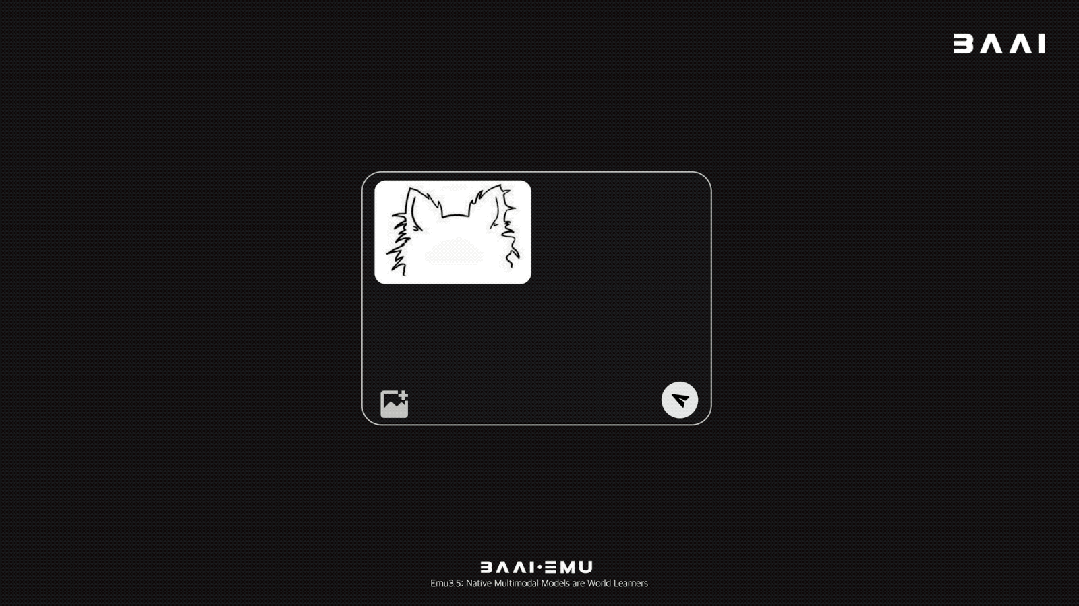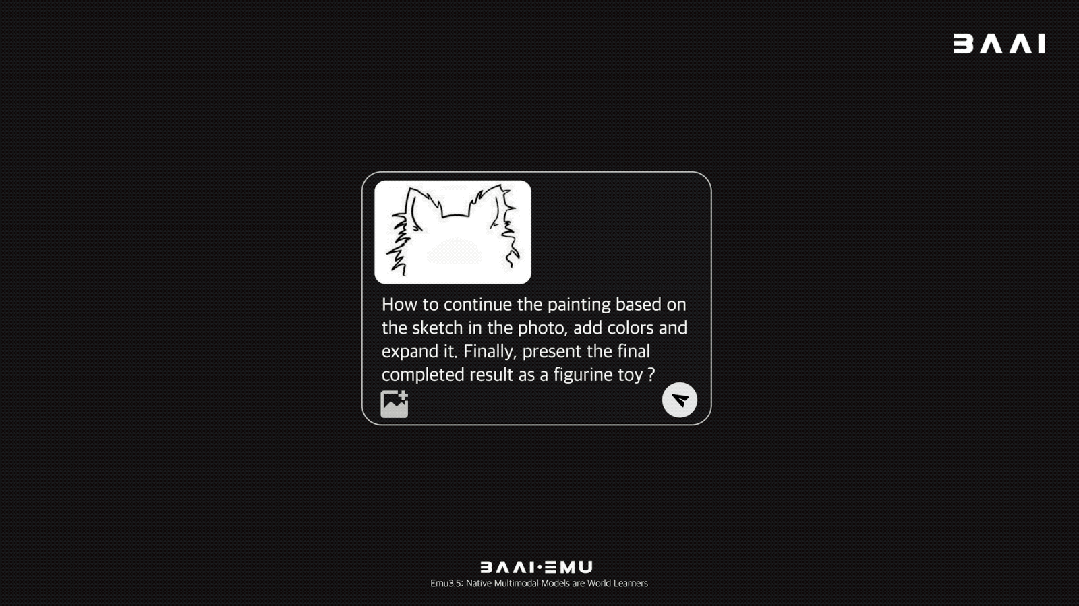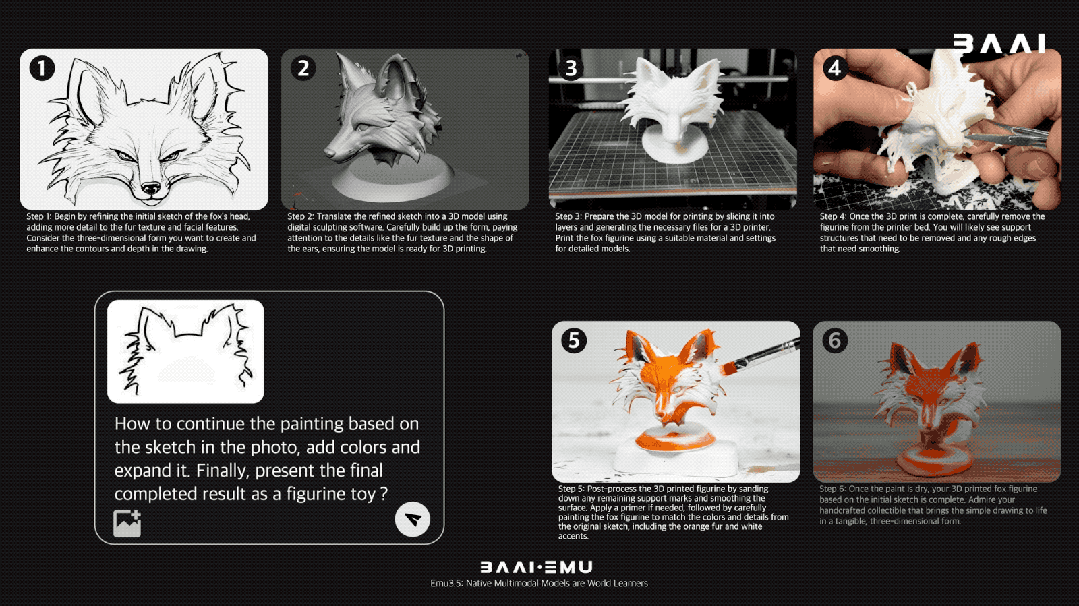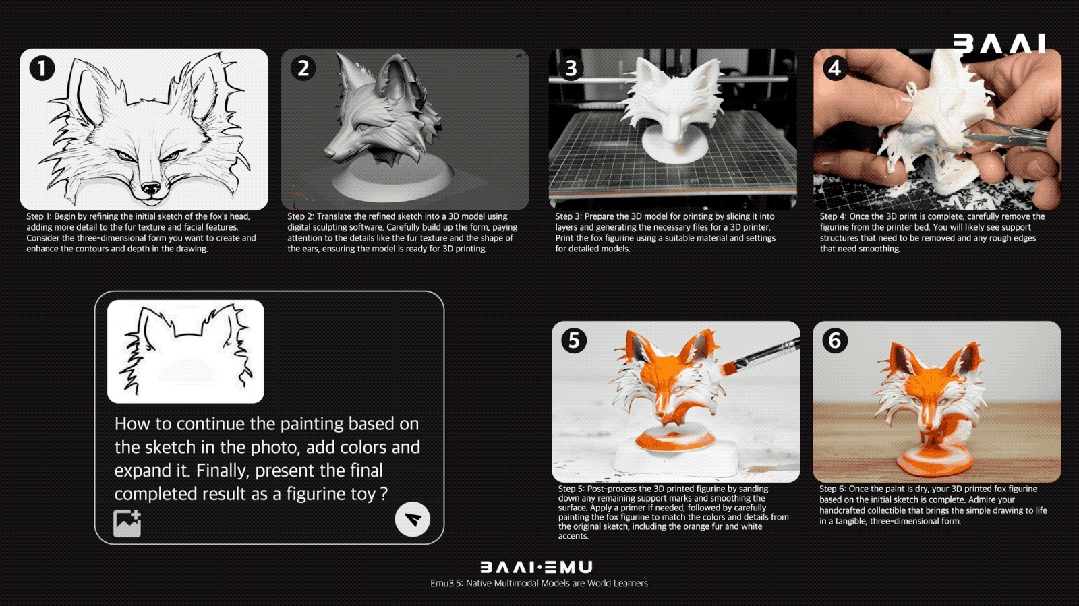
这种能力让它还能生成分步教学指南,手把手教你做菜、画画、种菜:

同时,它也支持多图、多轮指令的复杂图像编辑,主体一致性、风格保持能力达到业界顶尖水平。
敲黑板,由于Emu3.5本身就在海量的互联网视频上进行预训练,所以它天生就具备理解时空连续性的能力,能够生成长时序、逻辑一致的序列,而不会出现风格漂移或事实错乱。
为了构建Emu3.5,智源这次在技术方面也是进行了一系列创新和突破。
背后技术原理
Emu3.5参数量仅34B,整个模型以标准的Decoder-only Transformer为框架,单一模型能够同时完成视觉叙事、视觉引导、图像编辑、世界探索、具身操作等多种任务。
它将所有任务都统一为下一State预测(Next-State Prediction)任务,无论是文本还是图像,都被一个强大的多模态分词器(Tokenizer)转换成离散的Token序列。
- 海量视频数据预训练
模型在超过 10万亿 Token的多模态数据上进行训练,其中主力是来自互联网视频的 连续帧和转录文本 。这使得模型从一开始就沉浸式学习时空连续性和因果关系。
- 强大的分词器
视觉分词器(Tokenizer)基于IBQ框架,拥有13万的视觉词汇表,并集成了扩散解码器,能实现高达 2K 分辨率的高保真图像重建。
- 多阶段对齐
在预训练之后,模型经过了大规模的 有监督微调(SFT)和大规模多模态强化学习(RL) ,使用一个包含通用指标(如美学、图文对齐)和任务特定指标(如故事连贯性、文本渲染准确率)的复杂奖励系统进行优化。
- 推理加速黑科技
为了解决自回归模型生成图像慢的问题,团队提出了 离散扩散适配(DiDA)技术 ,它能将逐个Token的生成方式转变为并行的双向预测,在不牺牲性能的前提下,使每张图像的推理速度提升近20倍。
One More Thing
这么强的模型,智源选择——开源!

全球的开发者、研究者,不用再从零开始,就能直接上手一个懂物理、有逻辑的世界模型。
从生成更逼真的视频,到构建更聪明的智能体,再到赋能千行百业的实际应用……想象空间拉满了。
对了,如果想要体验科研内测版,可戳下方链接申请~
体验链接:https://jwolpxeehx.feishu.cn/share/base/form/shrcn0dzwo2ZkN2Q0dveDBSfR3b
项目主页:https://zh.emu.world/pages/web/landingPage
技术报告:https://zh.emu.world/Emu35_tech_report.pdf


