
在通用人工智能(AGI)领域,一直有一个攸关的核心问题:大语言模型到底能不能学到“世界模型”(world model),还是它们只是在玩“预测下一个词”的概率游戏?
哈佛和MIT做了一项实验,试图回答这个问题。他们选用轨道力学作为测试场景,用1000万个模拟太阳系坐标序列训练一个1.09亿参数的小型Transformer模型,后续又测试了诸多先进大语言模型,判断AI是否学到正确世界模型。
实验结果既在意料之外,也在情理之中:当前的AI模型都出现了预测与解释脱节的情况——它们虽能精准预测行星轨迹,但仅是依赖 “特定情境的经验法则”,而非推导、编码出了定律。
而面对这样的结果,研究人员表示,“解释与预测的分野”是科学史上的经典难题,这并非否定了LLM的科学价值,而是需要我们对AI否认发展方向进一步思考——是继续依赖追求预测精度,还是探索新方法让AI掌握“流动智力”以构建世界模型?
从“开普勒”到“牛顿”
在通用人工智能(AGI)探索的关键阶段,“AI能否像人类一样做出科学发现?”成为学界聚焦的核心命题。哈佛与MIT的研究者以这一命题为起点,展开了一项极具启发意义的实验。
研究团队跳出复杂的语言领域,选择科学史上极具代表性的轨道力学作为测试场来进行测试。我们可以把这个过程理解为:用AI重演开普勒的发现——行星如何绕太阳运行,然后再测试它是否真正学会了背后的牛顿力学(即万有引力定律)。
这个实验的假设是:如果模型能给出正确预测,却没有编码出牛顿定律,那说明它并不具备完整的“世界模型”。
之所以选择轨道力学作为测试场景,是因为它在科学史上具有代表性:开普勒借助几何方法,从行星的既往轨迹(输入数据)推断出未来轨迹(输出预测);牛顿则把这些经验规律上升到更深层的原理——万有引力与运动定律。
更关键的是,牛顿给出了一个统一的框架,将苹果落地与月球绕地运动联系起来,还发明微积分描述连续变化,最终构建了一个能解释物理现实的定律。换句话说,是牛顿,而不是开普勒,揭示了质量、力、加速度和运动之间的动态关系,从而让数据变得可解释。
这就是AI研究者长久以来始终执着于世界模型的原因:如果没有它,AI永远只能停留在表面的观察,根本不可能像牛顿那样做出真正的科学发现。真正的“世界模型”能超越直接观测到的现象,将背后的因果逻辑推广到未观测过、甚至看似无关的场景中。
自神经网络主导AI领域以来,“预测与解释脱节”就一直是现代AI模型的短板。过去十年,随着大语言模型规模扩大、能力增强,这一问题愈发明显——如今的LLM虽能解决博士级别的科学难题,却偏偏会在一些“常识性”的推理测试上卡壳。为什么?因为这类任务需要AI构建超越观测数据的世界模型。
另一个类似的例子是自动驾驶。为什么无人出租车可以在一些城市顺畅运行,但却无法轻易推广到全球每一座城市,甚至无法一下子解决堵车问题?原因同样在于:自动驾驶系统并没有真正学会“驾驶原理”的世界模型。
基础模型(foundation model):在相关论文中,作者把Transformer架构的AI模型统称为基础模型——大众接触到的几乎所有AI产品或工具都属于这一范畴。其核心是利用数据集来实现“输入-预测输出”的映射;而世界模型(world model)是指刻画数据中隐含的状态结构。
理解这两者的区别,是此次研究的出发点。
研究设计与测试场景
哈佛和MIT团队要探究的核心是:“预测与解释脱节”是否是AI模型的根本性局限?大语言模型能否凭借自身发展突破这一局限,还是需要更底层的技术突破?
在研究中,团队用轨道1000万个模拟太阳系的坐标序列(总计200亿个token)训练了一个小型Transformer模型,想看看这个模型是否会利用牛顿定律来预测行星运动背后的受力向量,还是说它只是“胡乱拟合”,在没有理解物理规律的情况下照样做出预测。
结论很明确:AI模型能给出精准预测,但它并没有编码牛顿定律的世界模型,而是依赖一些“特定情境的经验法则”,这些规则无法推广到其他情况。
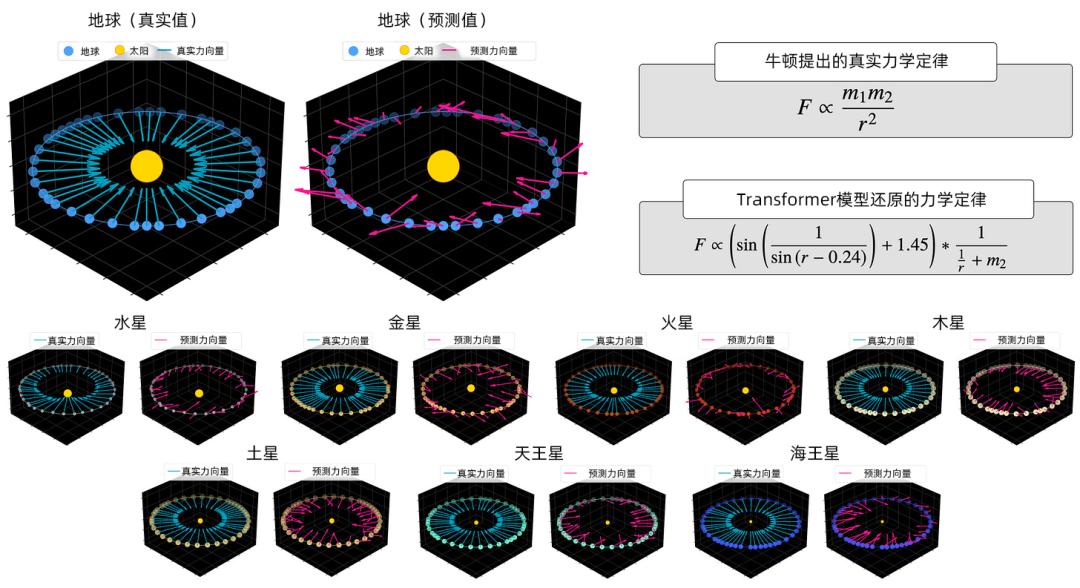
仔细看行星轨迹的预测结果(实线)与真实轨迹(虚线)的对比,你就会发现:
轨迹预测几乎完美,但模型预测的受力向量却杂乱无章。
这说明,AI模型用于生成准确轨迹预测的“逻辑”,与实际的万有引力定律毫无关联。若仔细观察第一张图下方的两个力学公式,会看到两套不同的受力定律:左侧是牛顿定律,右侧则是毫无意义的“伪定律”。研究还发现,AI模型的预测无法推广应用到未训练过的太阳系场景。
研究者甚至发现,当换一个银河系(新的样本数据)去测试时,模型会编码出完全不同的另一套错误的“受力定律”。换句话说,它连出错都错得不一致。
这一发现意义重大。
即使AI模型未能还原牛顿定律,但如果能在不同样本间保持“相同的错误”,那至少还可以说它学到了某种稳定的“与现实宇宙不同的替代世界模型”。但实际情况是,它的错误会随样本而变动——说明它根本无法编码一套稳定的、用于指导预测的定律体系——它不是不擅长构建世界模型,而是本质上就不具备这种能力。
这印证了很多批评者对LLM的观点:它们的泛化能力仅限于“所熟悉的东西,或与所熟悉的东西相像的东西”,但无法突破这一边界。
研究团队还测试了当前最先进的大语言模型,结果同样令人沮丧。大语言模型们能精准预测行星轨迹,但推导出的力学定律却与牛顿定律相去甚远——即便它们在训练数据中已见过无数次牛顿定律了。
那么,问题究竟出在哪里?为何无论规模大小,AI模型都能依靠错误的世界模型做出极为精准的预测,却无法构建符合现实的世界模型?
为了回答这个问题,并验证该缺陷是否存在于不同场景,研究者还在“晶格问题”和“黑白棋”上做了类似实验。其结果指向是一致的:模型会把不同状态归为一类,只要它们有相似的“下一个token可能性”。
这并不是LLM的“失败宣判”
缺少世界模型≠毫无用处。这一结果既非对AI价值的否定,也不是AGI梦想的终结。在很多实际场景下,LLM都能发挥重要作用。
甚至在“自动化科学发现”这种宏大目标上,LLM也未必是累赘。就算是最激烈的批评者(如深度学习的奠基人之一、卷积神经网络的开创者Yann LeCun)也不会说它们一无是处。正确的结论是:以今天的形态,LLM还“不足以”实现科学发现。
那么在这样的情况下,未来AI发展将向何方?
一种思路是继续堆量,把模型做得更大,希望它们有一天能从行星轨迹里自发学到牛顿定律。但这并不可行。
另一种是“更大模型+新方法”并行。François Chollet(谷歌的AI研究员、深度学习框架Keras的作者,以倡导AI的可解释性与泛化能力著称)认为,AI未来的发展需结合“晶化智力”(已有知识技能)与“流动智力”(经验迁移能力)。如今许多公司正在这条路径上努力,例如Yann LeCun正在通过JEPA框架(联合嵌入预测架构)进行探索。
总之,这个研究再一次地反映了一个科学史上的经典论题:科学的核心是精准预测,还是理解事物运行的“为什么”?这是我们对“智能本质”与“科学逻辑”更深层思考的起点。
或许探索宇宙的本质、引力的根源可能超出了现代科学的能力边界,但那些“中间层次的为什么”,如行星椭圆轨道的成因、苹果落地的原理,才是现代科学最具价值的领地——人类正是通过关注这些“为什么”,才得以理解世界。
所以,它们也将是AI未来值得奋力攀登的高峰。当AI有一天能像人类一样,从有限数据中提炼出稳定的因果规律,从“预测轨迹”进阶到“解释定律”,才算真正站在了科学发现的门槛前。
而在那之前,行业将共同来解答这个命题:如何让AI不止是“预测机器”,更是能理解世界运行逻辑的“思考者”?这道题的答案,将决定AI在科学史上最终能留下怎样的印记。


