
算力,就像运力一样,也要学会调度。
假如你在深夜点了一份外卖。几分钟后,系统迅速给你派来最近的骑手,他不需要全城出动的大军,只要顺路接单,就能把一碗热汤准时送到你手里。
美团正在把这种“派单逻辑”搬到 AI 世界。
在最新发布的 LongCat-Flash 模型里,算力不再是一股脑砸上去,而是像运力一样被精准调度:复杂问题派更多“高手”,简单问题就近解决,最大限度减少浪费。
美团最近的财报,和所处的竞争环境,让它需要新的故事。而 LongCat-Flash,就是美团递出的第一张筹码:在大模型赛道开打另一场战斗,把百万 tokens 的推理成本压到 0.7 美元。
以下为LongCat-Flash技术文档解读:像管理运力一样管理算力
1
技术创新:算力活在算法中
首先,LongCat-Flash 的特别之处,不在于它“更大”,而在于它会“精打细算”。
它的总参数规模有 5600 亿,但在实际推理时,每个 token 只需要调用一小部分,大约 18.6B–31.3B。可以把它想象成一个庞大的骑手团队,不是每一单都要全员出动,而是根据订单的难度,派出最合适的几位骑手去送。这样一来,既能保证覆盖面,又避免了算力浪费。
而所谓“零计算专家”,其实就是处理简单任务的捷径。
比如,一单只是送楼下便利店的一瓶水,就不需要总部复杂调度,附近的小哥顺路就能完成。同样,LongCat-Flash 遇到简单的 token,就直接放行,不浪费多余算力,把资源留给真正复杂的任务。这种“按需分配”的逻辑,让模型像调度运力一样,把活派得更合理。
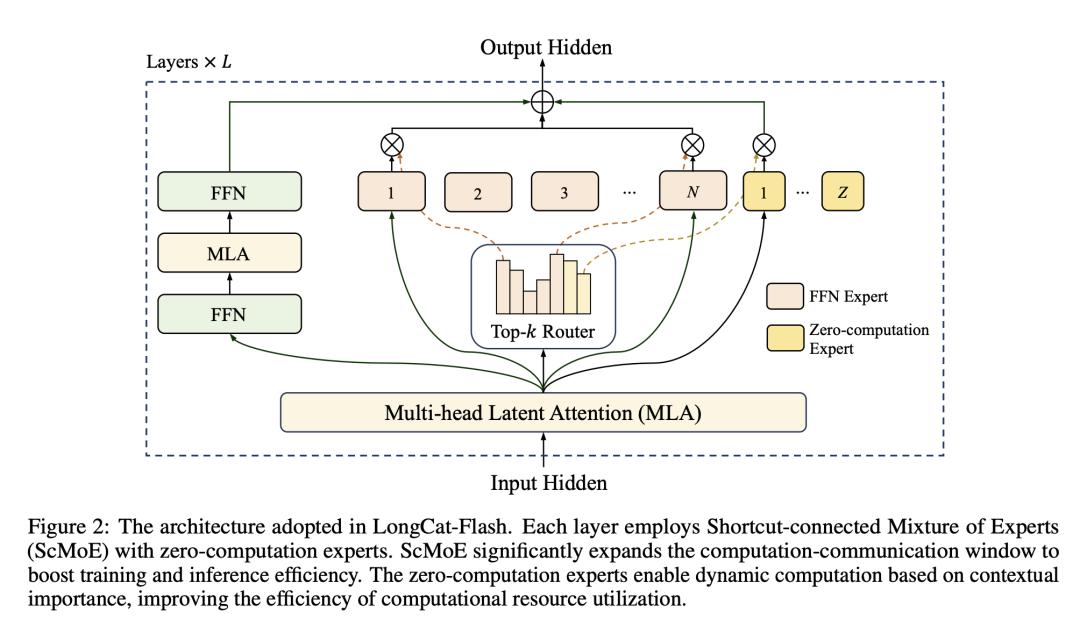
上图中展示了 LongCat-Flash 的整体架构:每层由多头潜在注意力(MLA)+ MoE 专家组成,其中一部分是零计算专家,保证遇到简单 token 时可以“零开销”直接通过。
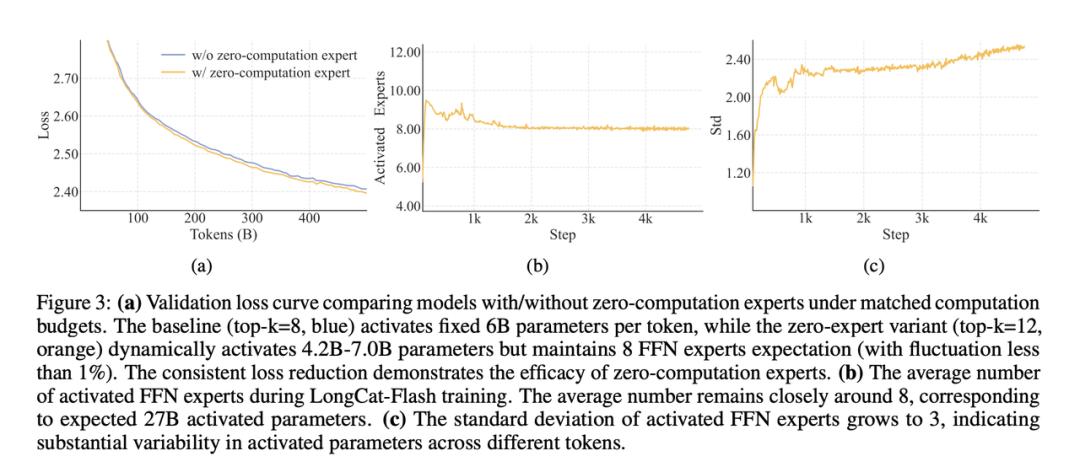
下图中 (a) 曲线显示:在相同算力预算下,加入零计算专家的模型 loss 更低,收敛更快;(b) 激活专家数稳定在 8 个左右,平均约 27B 参数;(c) 不同 token 之间算力分配差异明显,说明模型确实在“挑单子”。
另一个创新点叫 ScMoE(Shortcut-connected MoE)。传统模型要等一批任务全部处理完,再进入下一批,就像骑手要等所有订单派完才能出门。
ScMoE 的思路是“边派边送”:骑手在送餐的同时,系统已经开始为他规划下一单。这样,算力的使用和通信可以同时进行,整体效率自然提升。
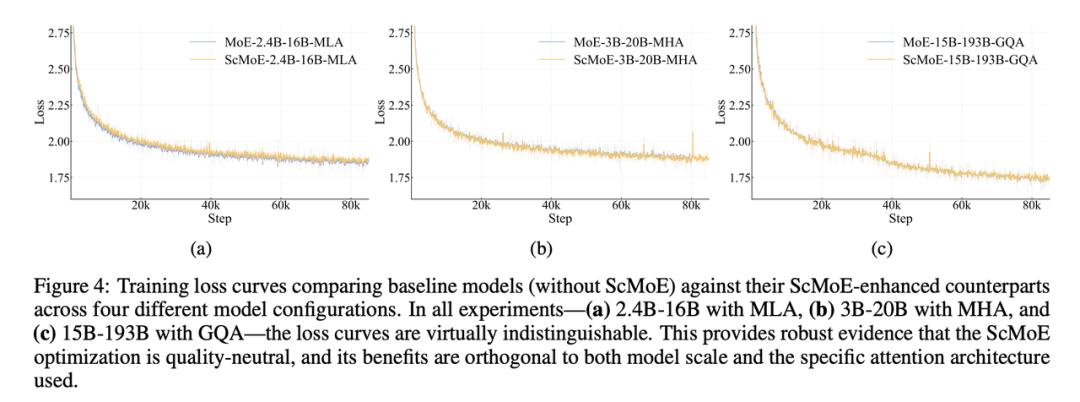
图中三组曲线(不同模型规模)显示:有无 ScMoE 的 loss 几乎重合,质量完全一致,但由于通信和计算可以重叠,ScMoE 在吞吐率和推理速度上显著提升。
2
工程能力:给算力买个“社保”
规模大,速度快只是第一步,关键是能不能稳定运行。LongCat-Flash 的训练方式更像是在逐步扩张一个运力网络:先在小范围试运行,把调度规则、路线规划都调好,再推广到更大的范围,避免一上来就乱成一团。
为了防止系统崩溃,它设置了“三重保障”。Router 稳定,相当于避免所有订单都集中在一条线路;激活稳定,让算力使用更合理;优化器稳定,则保证整体调度有节奏,长期能跑下去。正是靠这一套机制,它在 30 天里完成了 20 万亿 tokens 的训练任务。
3
性能比较:表现稳健
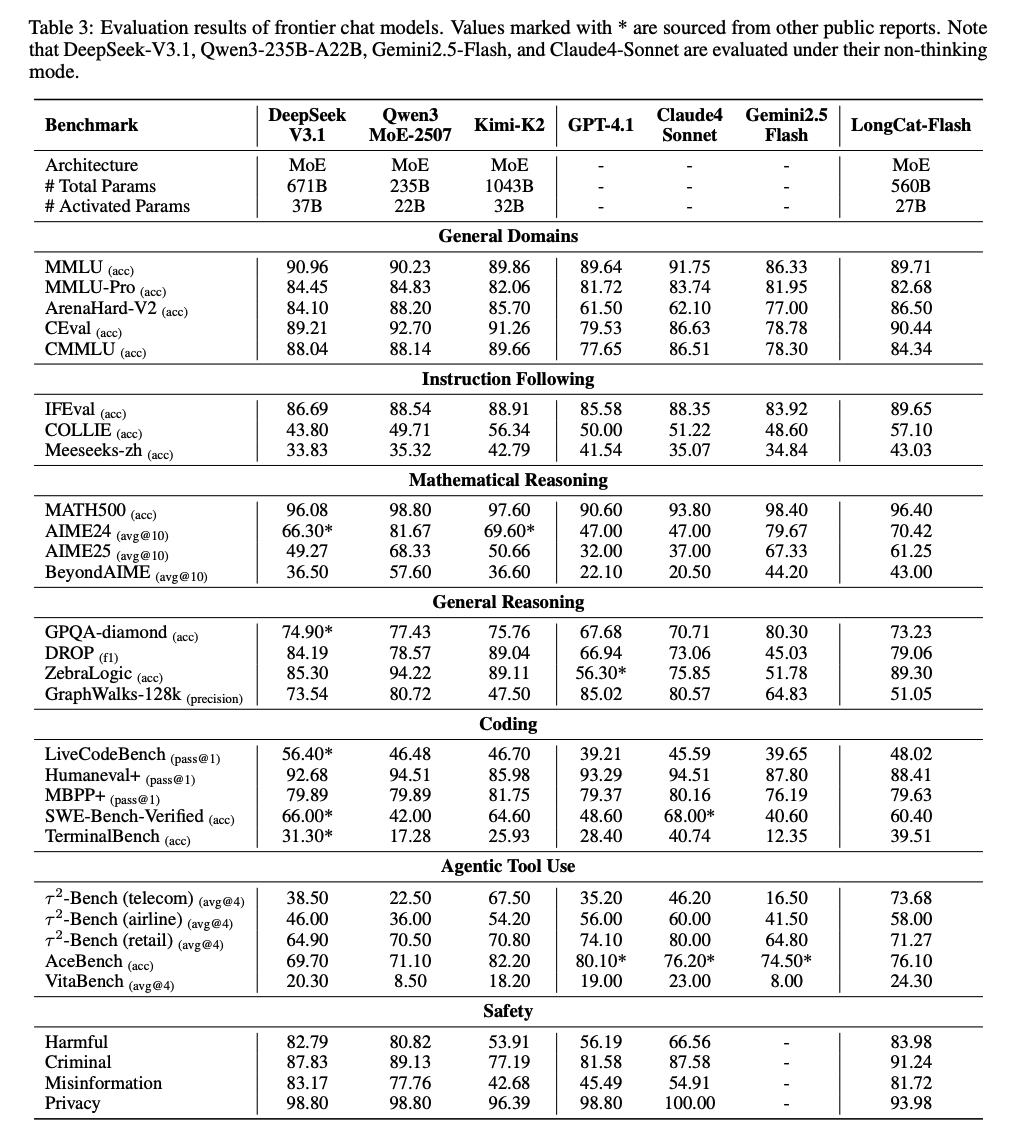
从成绩单来看,LongCat-Flash 不只是推理快,在各大基准测试中同样表现稳健:
- 通用任务
在 MMLU(89.71)和 CEval(90.44)中,LongCat-Flash 达到与国际一线模型相当的水准。虽然 CEval 分数略低于 Kimi-K2(91.26),但整体表现依旧领先大多数基线模型,展现了不错的中文理解能力。
- 复杂推理
在 GPQA-diamond(73.23)上,LongCat-Flash 与同类模型保持相近水准;在 DROP(79.06)、ZebraLogic(89.30)、GraphWalks-128k(51.05)等测试中,也稳定处于中上游梯队。
- 数学能力
在 MATH500(96.40)和 AIME24(70.42)上,LongCat-Flash 与 Kimi-K2、DeepSeek 相比差距不大,维持在高水平。在 BeyondAIME(43.00)上虽有下滑,但整体仍优于多数模型。
- 编程任务
在 HumanEval+(88.41)、MBPP+(79.63)等 benchmark 上,LongCat-Flash 表现稳定,略低于 Kimi-K2(93.29、79.87),但依旧优于 Gemini2.5 Flash、Claude Sonnet 等对手。
4
实测美团LongCat-Flash:快
其实从上面的测试基准中可以看到,美团LongCat-Flash的性能并没有遥遥领先的地方,只能算是与各大主流模型能力旗鼓相当。因此在很多常用的测试中看不出差别,但有一点:
美团这个模型是真的快。
写一个 Python 函数 is_prime(n),判断 n 是否是质数,并给出 10 个不同的测试样例。
左边模型是LongCat-Flash网页端,右边是 kimi 1.5(根据官网描述,响应更快),可以看到同样的提示词,LongCat-Flash没有怎么思考,一行行内容直接飞出来,而 kimi 1.5 经过短暂思考后,(和LongCat-Flash相比)慢悠悠的把内容写出来。
在核心代码部分,二者也没差别,可以说LongCat-Flash又快又好。
LongCat-Flash 的速度和价格优势,未必能立刻改写行业格局。毕竟在大模型市场,生态和用户习惯往往比性能参数更具粘性。但它却透露出一个信号:美团依然习惯用自己最擅长的打法,把复杂的科技问题翻译成“调度运力”的逻辑,再用价格杠杆撬开市场。
这让问题变得更有趣:
当 AI 巨头们在谈模型规模、参数精度时,美团却在谈派单效率和成本曲线。它看似“接地气”的切入点,反而可能成为搅动格局的变量,就像曾经的 DeepSeek 那样。
十年前,美团用补贴烧出了外卖帝国。十年后,它是否能靠另一场价格战,把自己送进大模型的牌桌?没人能给出答案,但至少可以确定的是,美团已经递出了第一张筹码。


