
在过去的十多年里,以 GPU 为核心的数字计算统治了 AI 领域,更大的集群、更高的带宽、更强的 GPU、更密集的数据中心,似乎是通向下一代 AI 的主流路径。
可随着模型参数量迈向万亿级,行业开始频繁提及「能耗」一词,甚至一个更为底层的问题也随之而来:如果 AI 继续按现有方式扩张,电从哪里来?
无疑,AI 「电费账单」与能源消耗,已逐步从运营成本演变为制约整个行业发展的「结构性瓶颈」。
面对这一迫在眉睫的能源危机,前 Databricks AI 负责人、硅谷传奇创业者 Naveen Rao 带着他的全新硬科技初创公司 Unconventional AI 走到了聚光灯下。
今日,Unconventional AI 官宣发布它的第一个模型 Un-0,一个由「模拟耦合振子系统」驱动的图像生成模型,可以看作是一种新兴物理计算底座的样例。在 ImageNet 64×64 上,Un-0 达到 FID 6.74,质量已经接近一些主流传统图像生成方法刚发布时的水平。
Naveen Rao 称其是「第一个以物理作为计算原语构建的大规模生成模型」。
「这标志着基于物理的模型迎来了一个『Hello World』时刻。我们利用物理系统天然随时间变化的行为,让它替我们完成计算。最终结果是一种全新的计算机构建方式,并且有望在能效上实现大幅提升。」

甚至,在接受媒体采访时,Naveen Rao 给出了一个更为大胆的「小目标」:未来,或将 AI 推理能耗降低到现有系统的千分之一。
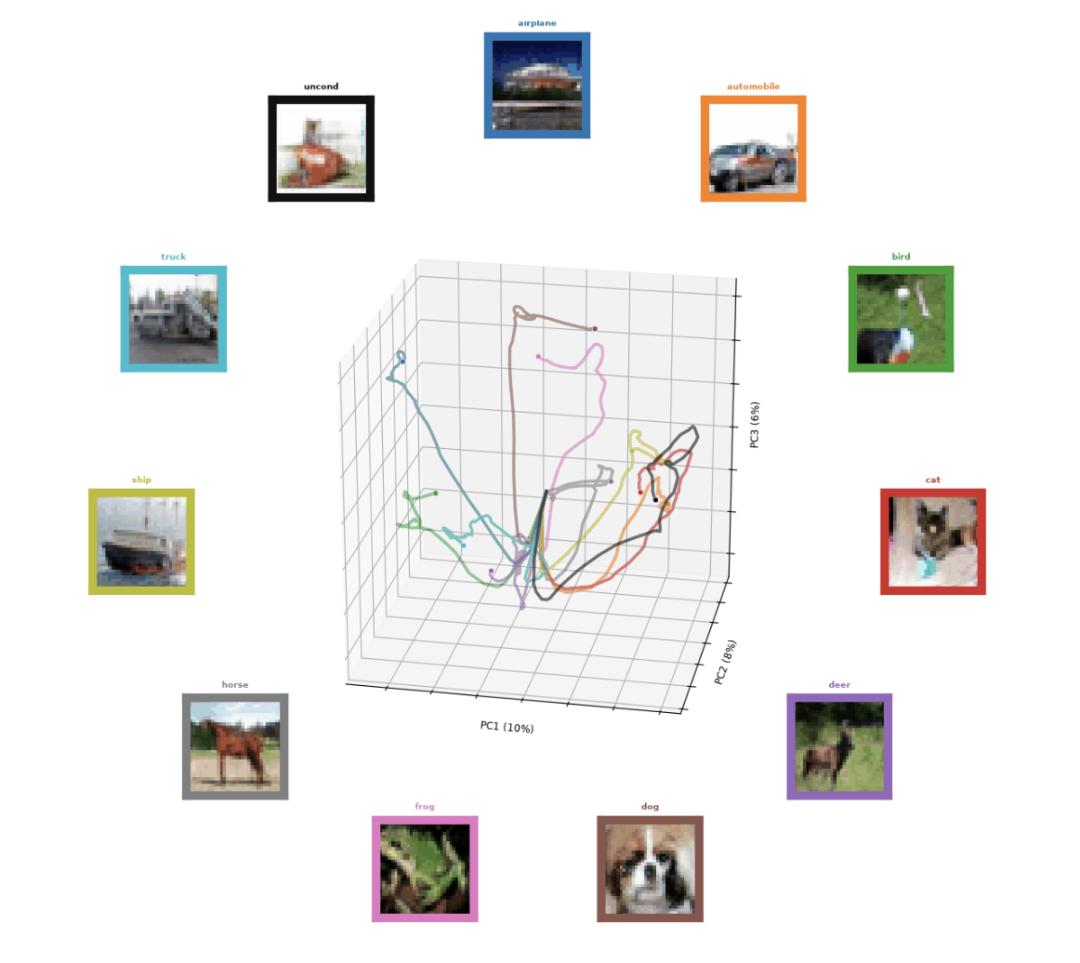
Un-0 生成过程随时间演化的轨迹样本。每条线的颜色都对应一个颜色相近的方框,方框中标注了类别,并展示了该类别图像随时间逐步生成的过程。
官方发布了一篇博客来介绍 Un-0,接下来具体了解一下。
Un-0 的出发点:用物理系统重做 AI 计算
Unconventional AI 表示,他们的目标是构建一种新型计算机,让它利用物理规律完成计算,希望未来现代 AI 可以在远低于今天机器能耗的情况下运行,目标大约是降低 1000 倍能耗。
因此,他们提出了一个问题:能不能训练一个物理动力系统,让它在规模化任务上生成图像?
如今,最强的 AI 模型基本都是传统深度网络,尤其是以 Transformer 为骨干的模型。但在主流路线之外,长期以来也有很多研究试图借助物理系统的动态行为来提高能效,比如模拟电路中的噪声、时间变化、电压和电流等。这类方法不是用传统数字数值进行计算,而是利用物理系统自己的演化过程。
比如神经形态计算、Hopfield 网络以及 Reservoir Computing 等,以及近年发展出的 Hamiltonian Networks、Liquid Networks、Neural Wave Machines、Thermodynamic Computing,以及 Kuramoto Oscillators 等。
Un-0 就是在这些非传统计算路径上的一次新尝试。但核心难点在于:要想利用这些替代计算方式,AI 任务必须被有效映射到物理系统的动态过程里。 Un-0 想验证的就是,现代 AI 工作负载是否可以被放到物理底座上运行,并最终比今天的硬件更高效。
Un-0 的工作原理
官方表示,可以想象两个节拍器并排滴答作响,如下图所示。
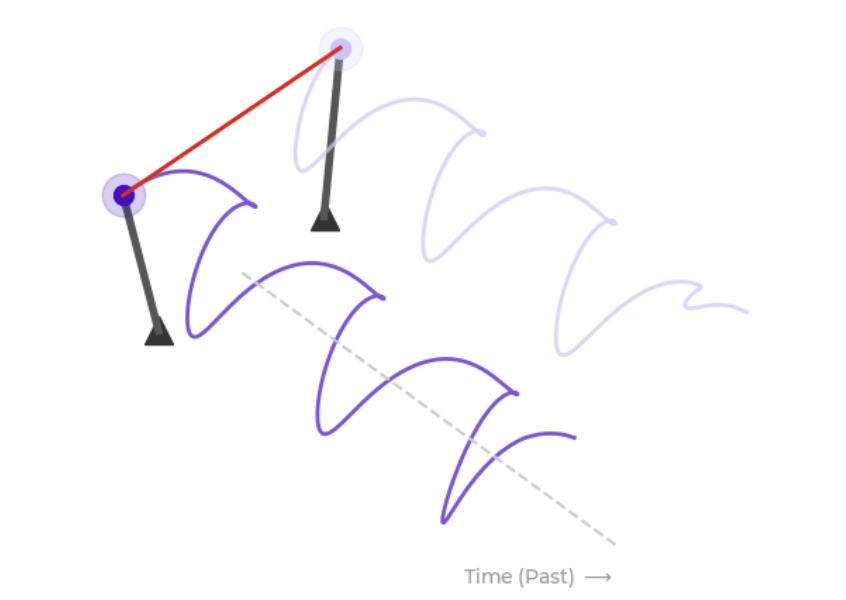
每个节拍器在任意时刻都有一个「相位」,也就是摆臂当前处在摆动周期里的位置。如果两个节拍器放在同一张桌子上,它们会通过桌面彼此影响。根据相互作用强弱,也就是耦合强度,它们可能逐渐同步,也可能进入相反相位的同步状态。
这就是振子的基本概念:每个振子都有自己的相位,并且倾向于按照自身频率旋转,但同时会受到邻近振子的影响。
而如果把两个振子扩展到几千个振子,整个系统就会变得更有意思。大量振子之间存在不同强度的耦合关系,它们会通过相互作用自组织成某种模式,如下图所示。

Un-0 的计算引擎就是这样一个大规模振子群,振子之间的耦合强度是模型最主要的可学习参数。
这些耦合振子通常被建模为「Kuramoto 振子」。
具体来说,每个振子的运动都遵循一条简单规则,并且这条规则会随着时间连续生效:它一方面按照自身的自然频率旋转,另一方面又会受到其他所有振子的牵引而发生偏移。
下面这个常微分方程(ODE)描述的,就是这些振子随时间演化的过程:
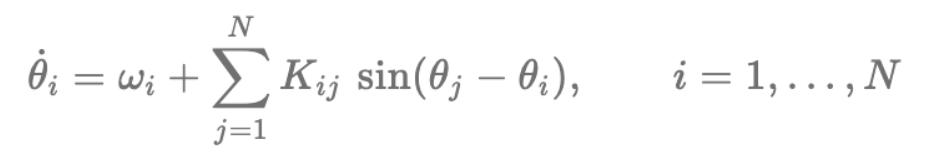
每个振子 i 都带有一个相位
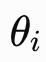
∈[0,2π),其中
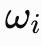
表示它的自然频率。矩阵
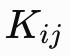
则指定了耦合强度,用来决定振子 j 会以多大力度将振子 i 拉向同步状态,或推离同步状态。
Un-0 需要学习的,正是耦合矩阵 K 和自然频率 ω,这些参数共同定义了物理系统本身。
而之所以选择振子,Unconventional AI 给出了两个理由:
- 第一个理由来自大脑:大脑中广泛存在节律活动和同步现象,长期以来,人们认为这些现象可能参与了计算过程,比如把分散的特征绑定成一个连贯的感知结果、控制脑区之间的信息交流、组织神经脉冲的时间结构等。耦合振子是描述这类行为最简单的数学模型之一,因此自然适合作为神经启发式计算模型的基础单元。
- 第二个理由更为工程化:振子可以被实现为一种物理电路原语。Unconventional AI 认为,可以在 CMOS 或其他物理底座上直接实现耦合振子系统,让系统的物理行为本身计算动力学演化。
Un-0 背后的赌注就是:如果物理规律可以直接计算 AI 工作负载,那么未来的执行底座就可能和今天的 GPU 非常不同。
Un-0 的模型架构
Un-0 生成一张图像,大致分为五步:
- 随机初始化:将所有振荡器的相位设置为随机角度(类似于扩散模型中的随机噪声);
- 输入类别引导:用一组较小的「条件振荡器」输入类别标签(如「火山」「雏菊」),引导主体振荡器集群向特定方向演化;
- 让物理自然运行:释放系统,让振荡器在物理动力学的作用下相互拉扯、演化,并最终稳定下来;
- 捕捉快照:在特定时间 T 记录所有振荡器的相位,形成一个隐空间(Latent)数字网格;
- 渲染像素:通过一个只占模型不到 13% 参数量的传统解码器,将相位网格转化为最终的图像像素。
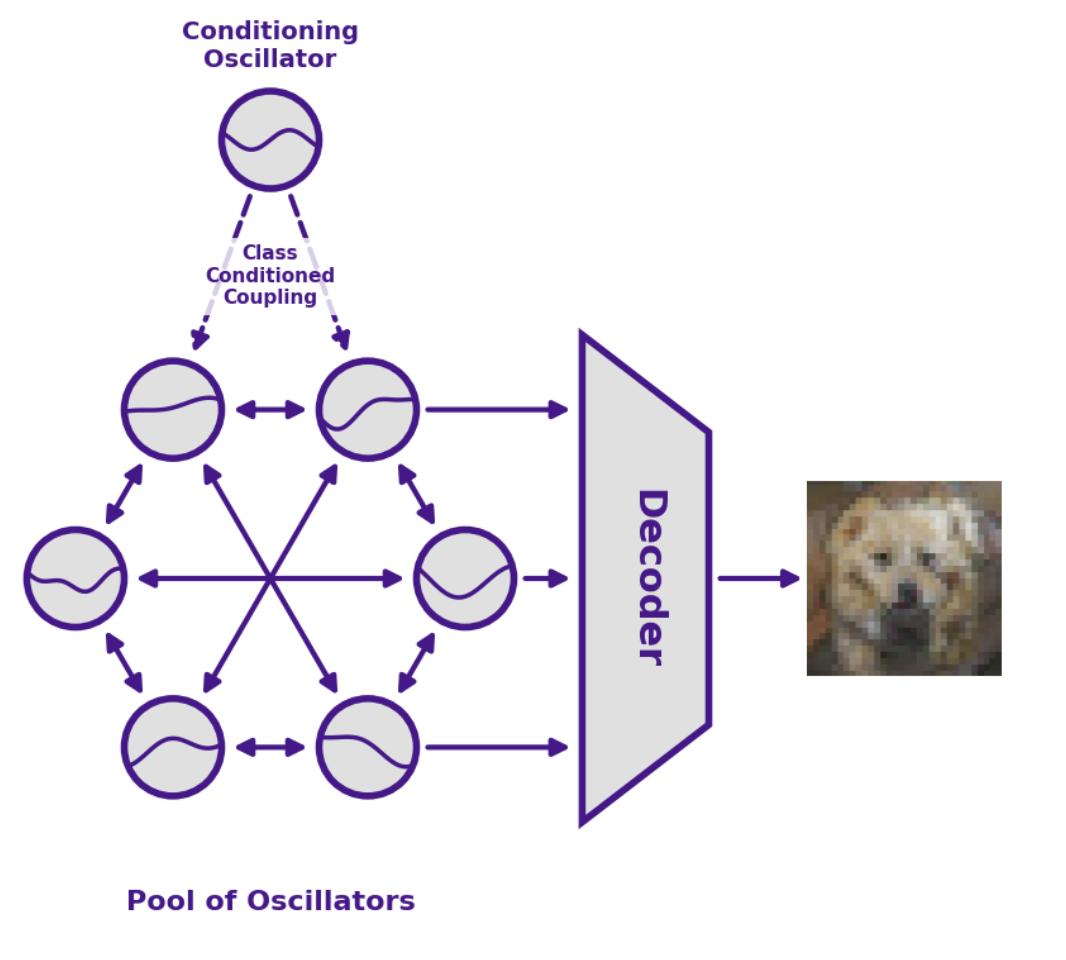
耦合振子在训练得到的耦合关系作用下随时间演化。其中,条件振子到主振子池之间存在一个单向的低秩类别条件矩阵,用于注入类别信息。在时间点 T ,系统通过一个解码器读取振子状态,并生成图像。通过多次采样不同的初始条件,就可以生成对应的图像分布。
训练过程中,模型主要学习三类参数:振子之间如何耦合,也就是矩阵 K;每个振子的自然频率
;以及解码器的权重。整体上,振子系统承担了原本可能由传统神经网络层完成的计算。
Unconventional AI 解释,之所以选择这种架构,是为了让动力系统本身有最大自由度来完成计算。
在训练的前向传播里,模型只需要设置耦合矩阵、振子频率和初始相位,然后让动力系统演化,最后读取图像潜变量。
这和扩散模型、Flow Matching 等动态生成方法有所不同,扩散和 Flow Matching 通常会在训练过程中显式指导动力系统如何演化,而 Un-0 的方法更像是只看最终生成样本,再通过损失函数反过来优化整个动力系统。
代价是,它需要一种更复杂的损失函数,因为训练信号主要来自生成样本本身。
如何训练 Un-0?
Unconventional AI 在 CIFAR-10 和 ImageNet 64×64 上分别训练了三种规模的模型,结果如下:

在 CIFAR-10 上的训练结果

在 ImageNet 64×64 的训练结果
从结果看,随着振子数量增加,模型 FID 评分持续改善。最大 ImageNet 64×64 模型使用 16384 个振子,总参数约 3.22 亿,FID 达到 6.74。
在训练方法上,使用了一种新提出的「漂移损失」(Drifting Loss)函数,配合 DINOv2 特征提取器和 AdamW 优化器进行端到端训练。
评测方面,CIFAR-10 使用 5 万张生成样本,并用标准包和评测流程与 CIFAR-10 参考统计进行比较;ImageNet 64×64 同样使用 5 万张生成样本,并通过 ADM evaluation suite 计算 FID。
算力方面,所有 CIFAR-10 模型在 1 张 B200 GPU 上训练,而所有 ImageNet 64×64 模型则在 8 张 B200 GPU 上训练。最大 CIFAR-10 模型训练消耗 20 个 B200 小时,最大 ImageNet 64×64 模型训练消耗 640 个 B200 小时。
官方表示,训练瓶颈主要来自「漂移损失」函数的计算,因为它需要使用传统图像特征提取器,并在多个特征视图上计算。
Un-0 在图像生成领域处在什么位置?
为了更好展现 Un-0 的性能表现,Unconventional AI 把 Un-0 放在「生成质量 vs 参数数量」的曲线上,与传统模型和非传统模型进行比较。
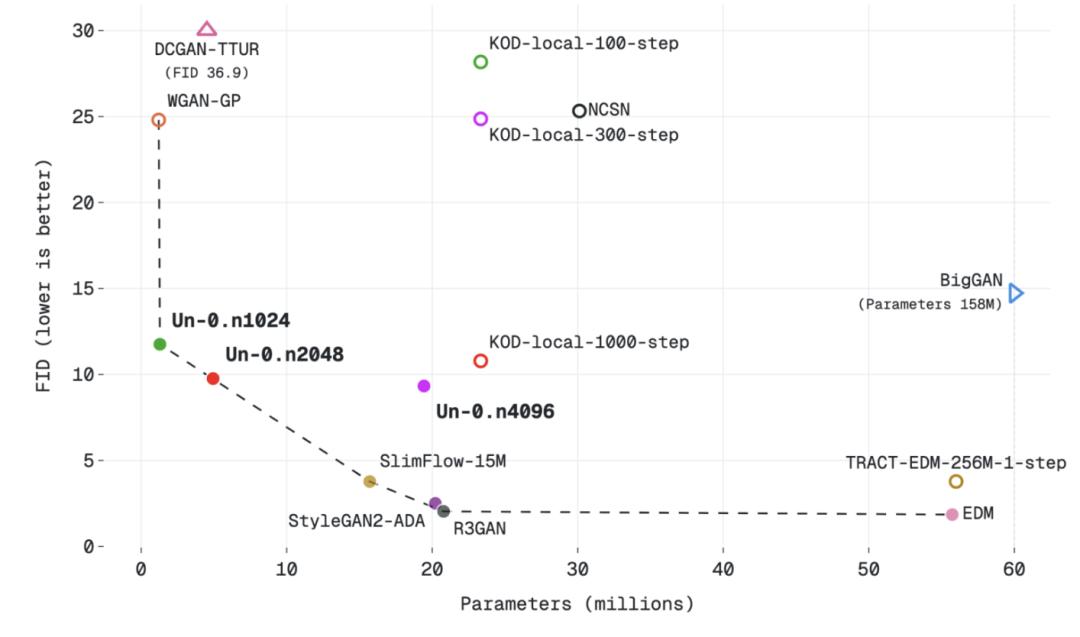
CIFAR-10 数据集中的参数数量与 FID 值的对应关系
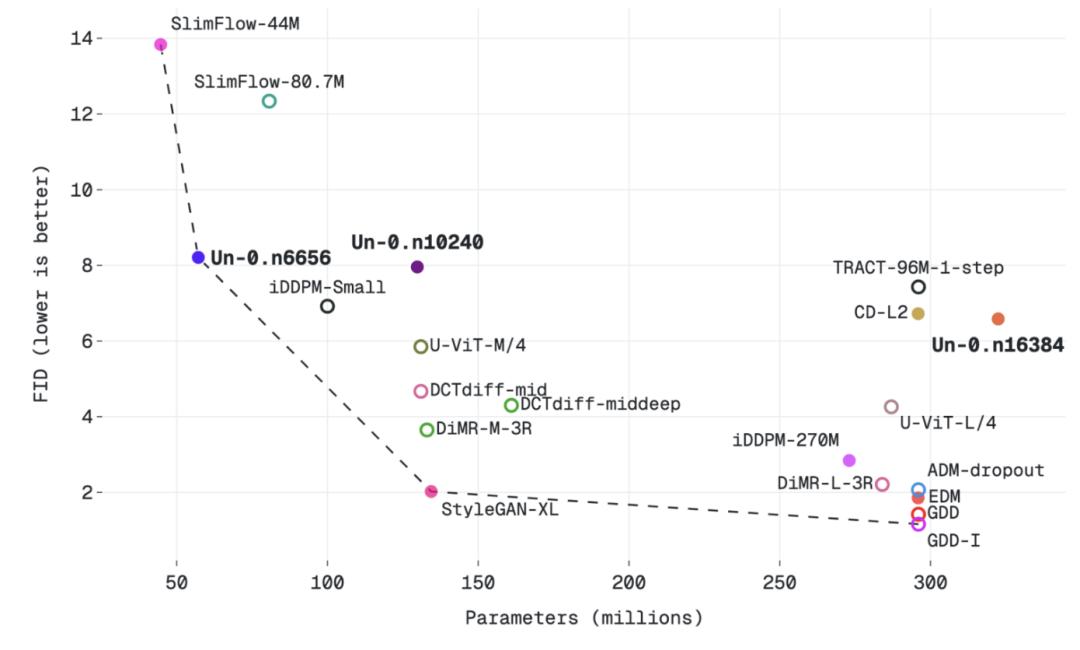
在 64×64 尺寸的图像中,参数数量与 FID 值的对应关系
结论是:Un-0 的质量已经可以和一些早期传统生成器相当,甚至在某些对比中更好,比如 NCSN、DCGAN-TTUR、WGAN-GP、BigGAN、iDDPM、Consistency Models、TRACT 等。但它仍然落后于后来的高性能传统模型,比如 EDM 和 GDD。
换句话说,Un-0 不是当前最强的图像生成模型,它更像是一个新路线的起点:其表现已经接近多个经典生成模型刚被提出时的水平,但要追上传统路线的最新前沿,还需要算法、架构和物理原语层面的持续优化。
从整体上来看,Un-0 证明了利用物理动力学系统进行现代 AI 大规模图像生成的可行性。虽然目前在软件模拟下的性能还未达到常规 AI 的顶峰,但它为未来实现千倍能效比的「非传统 AI 硬件」开辟了一条充满希望的道路……
而 Naveen Rao 也强调,Un-0 的出现,说明「计算并不是人类独有的发明。」它存在于自然与物理世界的各个角落。所有物理实体的物理过程都包含时间维度,但今天的计算系统却没有真正利用这一点。
「我们正在开发的,正是这个时间维度。」
而这和能效的关系在于,在现有冯・诺依曼架构机器中,大部分能量都消耗在内存与计算单元之间的信息搬运上,动力系统则把计算和记忆合并到同一个实体之中。更重要的是,动力系统可以容忍噪声,这进一步打开了节省通信能耗的新机会。
Un-0 代表着计算范式向动力系统转变迈出的重要第一步。「通过这次模型发布,我们正在把智能与动力学连接起来。」对于 AI 计算而言,动力学是一种天然的表达框架,神经网络本质上也可以看作动力系统,因此二者之间的映射会更加直接。
「大脑里并没有线性代数这种抽象,所以某种意义上,我们是在绕过中间环节。」
而在贴文下面,很多网友也表示了期待。
「实际上,这种性能效率的提升非常巨大。如果这种技术能够得到广泛应用,那么很多在本地运行的应用程序都可能变得可行起来。」

「如果这种技术能够上市的话,那真是一项极其先进的脑科技啊。」

参考链接:
https://x.com/NaveenGRao/status/2070184079199494583
https://unconv.ai/blog/introducing-un-0-generating-images-with-coupled-oscillators/
https://techcrunch.com/2026/06/25/databricks-former-ai-chief-thinks-he-can-cut-ais-power-bill-by-1000x/


