
负责 Copilot 业务的微软高管查尔斯·拉曼纳最近向媒体表示,Copilot Cowork 没法再提供「无限用」的套餐了,理由听上去有点凡尔赛:太受欢迎了。
微软四月底披露 Microsoft 365 Copilot 付费席位突破 2000 万,单季度净增 500 万,光埃森哲一家就签了 74 万席位,超过 90% 的财富 500 强在用某种形式的 Copilot。

作为套壳产品,Copliot 借着微软办公套件的生态优势,实现「捆绑销售」,成为了企业级部署赛道上,装机量第一的选手。
可代价是成本也高,有的用户一周能让 Cowork 跑几百个任务,效率高得惊人。于是微软决定,Copilot Cowork 将改成按用量计费,用得多付得多。
同时,它正在悄悄给这自己找一台更平价的「引擎」,一个自家托管、经过微调的开源模型,候选之一,便是 DeepSeek V4。
一个「太能干」的烦恼
最早的 Copilot,是像刻板印象中的那样,嵌在 Word、Excel、PowerPoint、Outlook、Teams 里,在当前 app 内完成任务:写文档、做表格、总结邮件、生成纪要。本质还是「一问一答 + 在本 app 里帮你动手」,谈不上真正的跨工具自动化。
Copilot Cowork 如今已经完成了 agent 化的转型,从聊天机器人转为能完成系列任务的 AI 助手。,而且范围不只是办公三件套,而是整个 M365 生态(Word / Excel / PPT / Outlook / Teams / SharePoint),还能通过连接器接到 Gmail、Google Drive、OneDrive 等外部源。并且靠 Work IQ + Microsoft Graph 实现全局上下文存储和调用,让 Cowork 能读到你工作里散落在各处的资料。
能干是真能干,烧钱也是真烧钱。agent 每多调一次模型、多读一段上下文、多用一个工具,账单就要多一行。
过去微软的 Copilot 主要靠 OpenAI 和 Anthropic 的顶级模型撑场子,这些模型聪明,但也贵。当 Cowork 要面向千千万万企业用户,还要日夜不停地干活,每一次调用都乘以一个庞大的使用量,成本就会滚成一个吓人的数字。
于是微软的算盘是,能不能在那些不那么烧脑的日常任务上,换一台便宜点的引擎。
今年四月,DeepSeek 一口气放出两个开源模型,V4-Pro 和 V4-Flash,都支持一百万 token 的超长上下文。Pro 版本有一万六千亿参数,是目前公开权重里最大的模型之一,性能被认为已经逼近 OpenAI 和 Anthropic 的顶级闭源模型,用的却是最宽松的 MIT 开源许可。

超强的性能及性价比,让 DeepSeek 成为了基座模型中的「斩杀线」:比它强的没它便宜,比它便宜的没它强。
DeepSeek 采用「混合专家」的架构,模型虽然总参数巨大,但每处理一个任务只唤醒其中一小部分参数运作,于是单次推理的开销被大幅压了下来。这正好戳中微软的痛点。Cowork 那种没日没夜调模型的活儿,最怕的就是单次调用太贵,而 DeepSeek 这类模型天生就是冲着「便宜地跑起来」设计的。

一个把性能做到接近前沿、把价格打到地板、还干脆开源放出来的模型,对一个正在为账单发愁的巨头来说,吸引力不言而喻。
DeepSeek:我们的征程是星辰大海
有意思的是,几乎就在微软透露要用 DeepSeek 的同一周,DeepSeek 自己也上了头条。
本月 16 日,这家此前多年坚持不要外部投资的公司,完成了有史以来第一轮外部融资,进账超过七十四亿美元,投后估值冲到五百亿美元以上,这是中国创业史上最大的单笔融资之一。
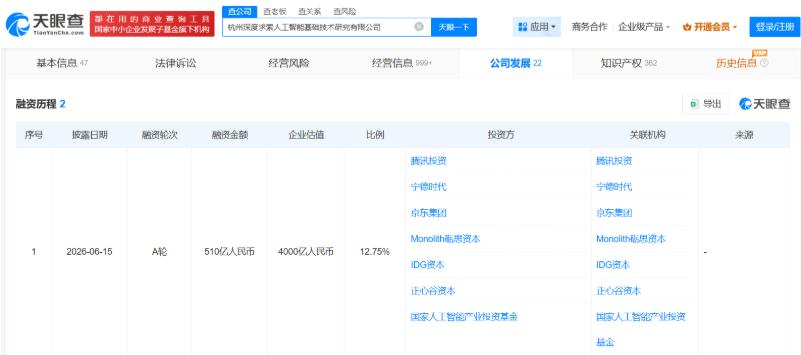
DeepSeek 本次提出特殊的融资结构,创始人梁文锋自己是最大的出资人,他没有趁机套现,反而在用真金白银给自己的公司加仓。整轮投资人不到十家,腾讯、宁德时代这些产业巨头在列,基金要求需为纯人民币基金。梁文锋还表示,公司会继续走开源路线、追求通用人工智能,而不是急着变现。
独特的融资结构显示出,不是梁文锋需要基金,而是基金们需要梁文锋。DeepSeek 刚拿到的那笔钱,某种程度上就是市场对这条路线投下的信任票。它不靠卖 token 赚大钱,所以敢把价格打到地板,敢把模型白送出去。而正是这份不靠卖 token 赚钱的底气,让它在这场成本战里,站到了一个让别人羡慕的位置。
「多模型」时代的生意逻辑
微软强调,即便引入 DeepSeek,版本会全程托管在自家的 Azure 云上,数据不出微软的体系,并做了合规和减少偏见的处理。引入 DeepSeek,是微软往篮子里又多放了一个鸡蛋,不把宝押在任何一家模型上,手里攥着一堆模型。早两年大家还在争论谁家模型最强,如今微软用行动给出了答案,模型是用来干活的,不是用来站队的。
模型对厂商来说,正在从信仰变成零件,这也改变了产品设计的思路。
GitHub Copilot 是目前商业表现最好的协作产品,470 万付费订阅、年增 75%、已经被 90% 的财富 100 强公司引入。
在 GitHub Copilot 里开发者有一个模型菜单,每个模型旁边明码标着要花多少额度,贵的更强、便宜的更省,自己掂量。它还专门设了一个叫 Auto 的档位,系统自动路由,替你挑一个够用又便宜的,价格打折,等于用钱包引导你别动不动就上最贵的。
搜索起家的 Perplexity 也走这条路,让用户在一堆模型里自选,还更进一步推出了一个让三个模型同时回答、再由一个模型综合的功能,赌的是多个模型互相校验能减少盲点,把多模型当成了提高答案质量的手段。
Notion 也是一个典型,作为「小白友好」类型的产品,它主打一个随时切换底层模型还不丢上下文,把心思全花在跟工作区数据的打通上,把模型的选择交给用户。同时它也是和 Anthropic 合作最为紧密的公司之一,在 Fable 上线的当天,就让这个顶级模型出现在了自家产品的列表里。
明牌是一种做法,还有一种是隐藏基础模型。Cursor 默认让系统自动路由,日常任务交给自家训练的便宜模型兜底,几乎不限量,只有你手动点名要最前沿的模型,才从额度里扣钱。用自家便宜模型扛住大部分调用,把贵的留给真正需要的时刻。
AI 刚火那两年,Sam Altman 说过一句很有名的话,未来智能会「便宜到不用计量」。那时候各家比的是谁更慷慨,免费额度给得越多越好,包月套餐恨不得标上「无限」两个字,仿佛智能这东西取之不尽,用之不竭。
然而事实是,算力是有成本的,电费是要交的,芯片是要买的,再财大气粗如微软,也必须学会精打细算,那个又免费又无限的 AI 蜜月期,正在结束。


