

作者|董道力
邮箱|dongdaoli@pingwest.com
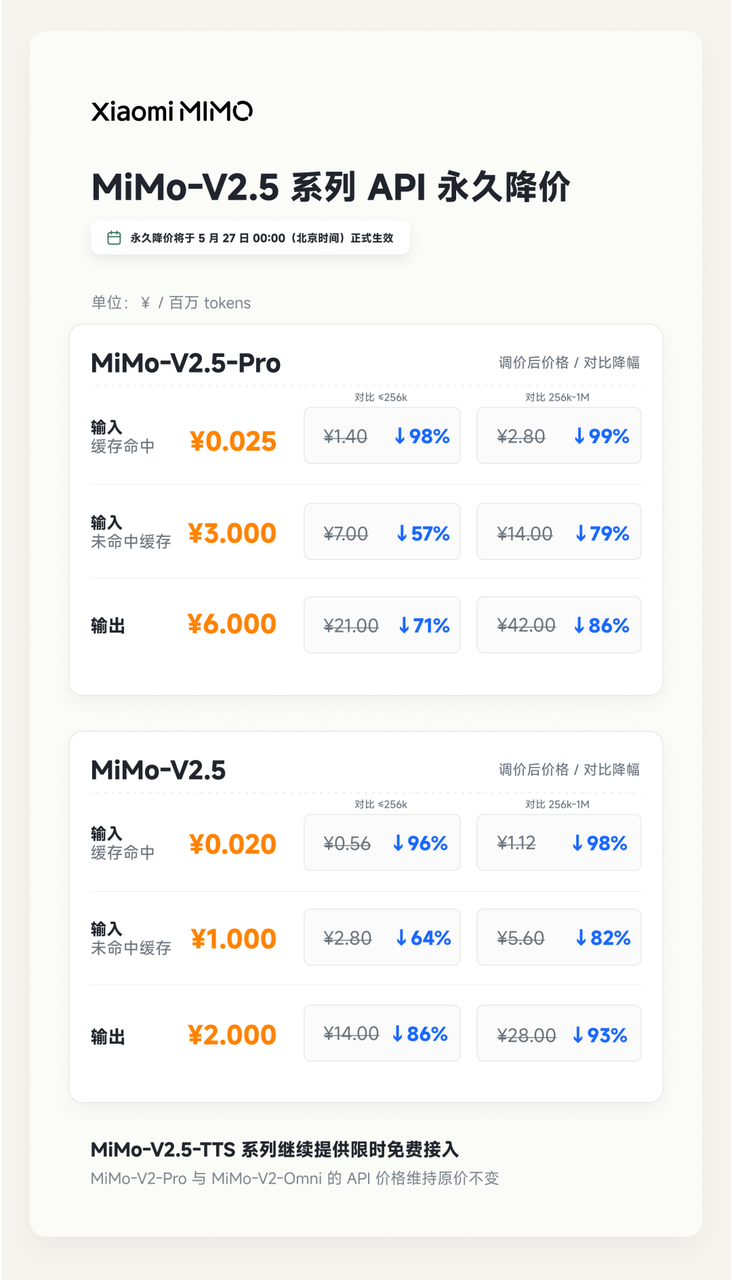
5 月 27 日,小米把 MiMo-V2.5 系列 API 永久降价。
MiMo-V2.5-Pro 的输入缓存命中价格降到 0.025 元/百万 tokens,输入未命中价格 3 元/百万 tokens,输出价格 6 元/百万 tokens。普通版 MiMo-V2.5 更低:缓存命中 0.02 元,输入未命中 1 元,输出 2 元。
这不是一次常规促销。
因为把价格横向一比就会发现,小米这次不是随便降价,而是直接对标 DeepSeek。
MiMo-V2.5-Pro 对 DeepSeek V4-Pro,MiMo-V2.5 对 DeepSeek V4-Flash。
如今,DeepSeek 已经不只是一个模型名字。至少在国产大模型市场里,它正在变成一把价格尺子。
这把尺子反复抽打各大模型公司:你的模型卖多少钱啊?
而这样一个问题平等的提给所有人,也就创造了一些新的机会,如小米MiMo这样的后来者,可以比其他模型身段更灵活,进而可以“蹭”着DeepSeek赌出一个上牌桌的机会。
1
token 的价格划分越来越细了
先来看看降价如何发生。
在这张价格表里,最重要的细节是它把缓存命中和缓存未命中明确拆成了两种价格。
这已经是今天大模型价格战的暗线。
所谓缓存命中,说白了就是:如果这次请求的前缀内容,和之前某次请求的前缀内容一样,平台就不用从头再算一遍,而是复用之前保存下来的中间结果。
大模型处理长上下文时,成本大体分两段。
第一段叫 prefill,可以理解成“读题”。系统提示词、项目代码、企业文档、历史对话,都要先被模型读进去。
第二段叫 decode,可以理解成“答题”。模型再一个 token 一个 token 往外生成回答。
过去大家谈 API 价格,主要看输入和输出。但现在大模型越来越多地用在 Agent、Coding、知识库和长对话里,很多输入其实是重复的。
代码助手每次都要看同一个仓库,企业助手每次都要读同一批制度文档,Agent 每一轮都带着同一套工具说明和系统规则。
可能真正的不同只是最后一句指令。
这时候,缓存就成了成本结构里的关键变量。
第一次做题要打草稿,第二次题目前半段一样,就不用重新打草稿。缓存命中价格之所以能低到离谱,原因就在这里。
以 MiMo-V2.5-Pro 为例,未命中输入是 3 元/百万 tokens,缓存命中后是 0.025 元,差了 120 倍。
价格战的味道很浓,但大模型厂商已经不再把 token 当成一种统一商品来卖。新输入、缓存输入、输出 token,背后是三种完全不同的成本结构。这一轮价格战不是“所有 token 一起便宜”,而是厂商开始按照真实成本,把 token 拆开重新定价。
2
降价来自“机房”
“最高降幅 99%”是最大噱头,但背后的门道来自其他地方。
在降价的公告里小米团队提到,他们基于 SGLang HiCache 完整支持 SWA,也就是 Sliding Window Attention,把 KV Cache 在 GPU 显存、CPU 内存、SSD 多级存储之间的数据搬运量降低到优化前的近 1/7,同时把可缓存 token 数量提升到近 5 倍。
这段话解释了这次降价的另一层原因。
大模型每生成一个 token,都要参考前面的上下文。如果每一步都把所有上下文重新算一遍,成本会非常高。KV Cache 存的,就是前面 token 在注意力机制里算出来的 Key 和 Value。
它相当于把模型已经读过的内容,变成可复用的“计算草稿”。
但草稿也要放地方。最好的地方是 GPU 显存,速度最快,也最贵;其次是 CPU 内存;再往下是 SSD,便宜但慢。缓存越多,越不可能全放在显存里。
于是,哪些缓存放显存,哪些放内存,哪些放 SSD?什么时候搬?搬多少?怎么避免搬运本身拖慢推理?
这就是小米公告里“多级存储之间的数据搬运量降低”的含义。
以前为了复用上下文,要么占着昂贵显存,要么在不同存储之间来回搬,省下来的计算成本又被搬运成本吃掉。现在系统调度更聪明了,搬得更少,存得更多,命中率更高,缓存价才有条件继续往下打。
所以,低价只靠补贴,它就是烧钱,如果低价来自 KV Cache、SWA、多级存储、专家并行和输入长度分桶,它就是基础设施能力。
前者只能换一阵子的流量,后者才可能改变长期价格。据小米透露,相关的更丰富细节的技术论文会在稍后发出。
3
DeepSeek 出的题,能不能变成小米的稻草
降价无疑会在短期给一个模型带来用户增加,而小米的降价除了官方透露的技术上的变化带来的可能外,其实很明显也设计了降价的时点和节奏。
它选择在DeepSeek刚刚最新一轮的降价后马上贴身跟上。
DeepSeek 给所有模型厂商出了一道题,当强如 DeepSeek 也可以低价调用时,其他模型厂商还凭什么维持原来的价格?
以前国产模型公司只要比 GPT、Claude 便宜,就能解释自己的性价比。但 DeepSeek 把价格锚点打下来以后,行业进入了一个更难受的阶段。
如果你比 DeepSeek 贵很多,就必须证明自己能力强很多。如果你能力差不多,就必须证明自己速度更快、稳定性更好、生态更顺。如果能力、价格和体验都没有明显优势,就只能退到更窄的场景里,比如多模态、端侧、企业私有化、行业模型、工具链绑定。
如果这些都没有,那就只能早点退出。
DeepSeek 像一条鲶鱼,没有让所有模型都立刻变便宜,但让“贵”这件事需要重新解释。
Claude 可以用 coding 和复杂任务能力解释自己的价格,GPT 可以用完整生态、多模态和工具链解释自己的价格。
那小米这样的还没有产生任何用户规模效应的后来者呢?尤其是小米目前的核心盘子,不在一个独立模型品牌上,而在手机、汽车、IoT、HyperOS 和智能硬件生态里。
所以 MiMo 目前最大的挑战,无论对内还是对外,都是:一个并非默认首选的基础模型,如何先进入开发者的候选名单?
这一次,MiMo显然决定要抓住DeepSeek这个稻草,从价格上像素级对标,这可能是唯一的机会。它必须抓着DeepSeek来蹦上牌桌。
只有把价格打到 DeepSeek 同一档,才可能有人来用。在 API 市场里,开发者不会无缘无故把调用量交给一个新模型。尤其是 Agent、Coding、长上下文这些场景,一次任务可能就是几十轮调用。只要价格比 DeepSeek 高一截,开发者还没试到模型差异,就已经先被账单劝退了。
而另一侧的压力也来自内部:MiMo要尽快证明,它到底能不能变成小米生态里的 AI 基础能力。
对小米来说,模型 API 不一定是终点。它最终要去的地方,不只是开发者控制台,而是自家的生态。
但模型想进入这些场景,不能只靠发布会和参数表。它需要大量真实调用,需要开发者在真实任务里反复试,需要用户在长对话、代码、Agent、知识库、车机和设备控制等场景里持续使用。只有这些使用数据回来,模型才知道哪些能力真的有用,哪些场景值得优化,哪些接口需要重做。
于是,哪怕罗福莉前不久刚刚提出模型不能“盲目降价”,今天MiMo也必须发起一场价格战。而罗福莉最新的推文里也对此作了解释:
“在新降价后的 API 价格下运行,我们的生产推理引擎接近满负荷运转,仍能基本实现收支平衡。我们此前建议 LLM 公司不要盲目降价,正是因为很少有模型架构和推理优化能让 API 成本避免亏损。如果更多节省计算和 KV 缓存的架构出现,并辅以更优的推理基础设施来压低 API 成本,这将在行业内形成一个极佳的良性循环。”
在刚刚降价一天的节点,这个描述看起来更多还是一个完美假设,实现了,MiMo就彻底上了台桌,实现不了,就是另一个故事了。


