
前几天,OpenAI 正式发布了全新的大模型 GPT-5.4-Cyber。和很多网友的感受一样,这个模型也给我们带来了一种极其强烈的既视感。
这款新模型在目标用户群、应用场景甚至宣发策略上,几乎完全对标了 Anthropic 前些天发布的 Claude Mythos。这种「贴身肉搏」的态势已经到了毫不掩饰的地步。就连《纽约时报》都在最新的报道标题中一针见血地指出:「与 Anthropic 一样,OpenAI……」。

这种同质化的趋势绝不仅仅停留在最底层的基座模型上。如果你把目光投向这两家公司近期发布的一系列产品,你会发现它们正在成为彼此的镜像!
在资本市场的无影灯下,这种趋同更加明显。目前两家公司在二级市场上的估值咬得非常紧,Anthropic 甚至在近期凭借其在企业级市场的狂飙突进,价格略高于 OpenAI。资本的嗅觉最为灵敏,在他们眼中,这两只独角兽正在长出相同的犄角。
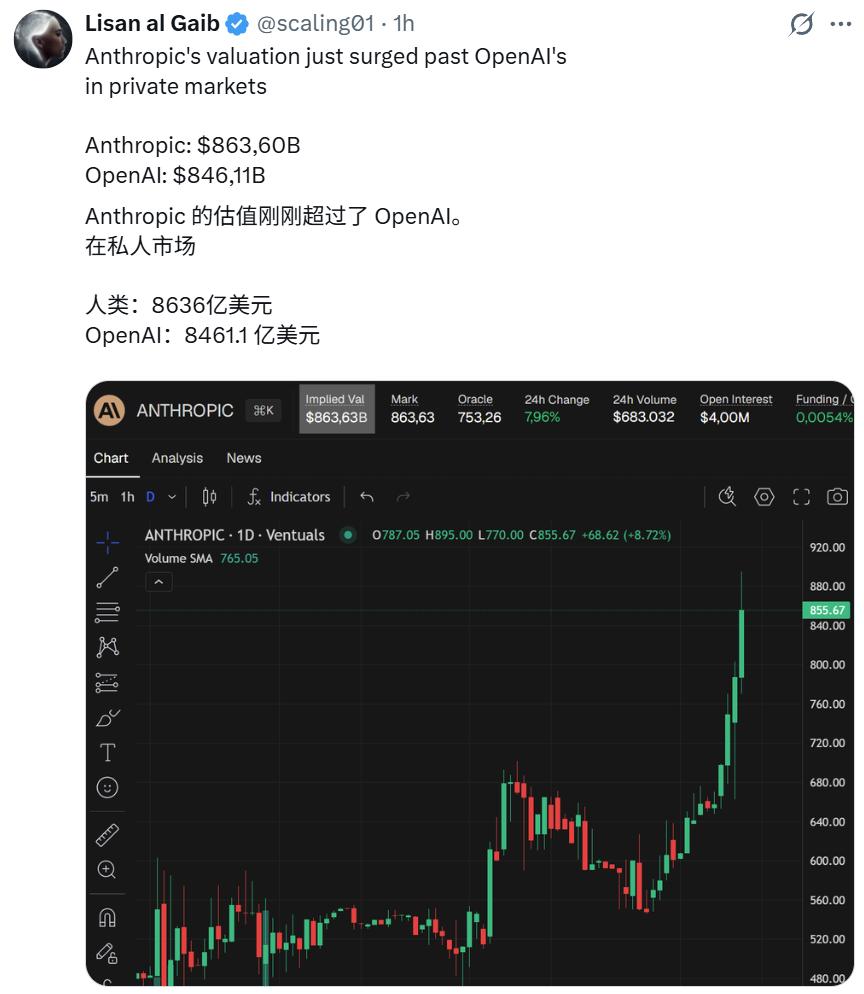
看起来,底层大模型的同质化必然会导致上层应用的趋同。
今天,我想和大家探讨的,正是代表着当今 AI 辅助编程最高水平的两个标杆工具: OpenAI 的Codex和 Anthropic 的Claude Code。从曾经的分道扬镳,到如今的殊途同归,它们是如何一步步长成了同一副模样的?
从分道扬镳到殊途同归:双雄的演进史
把时间拨回几年以前,Codex 和 Claude Code 完全是两种不同技术哲学的产物。
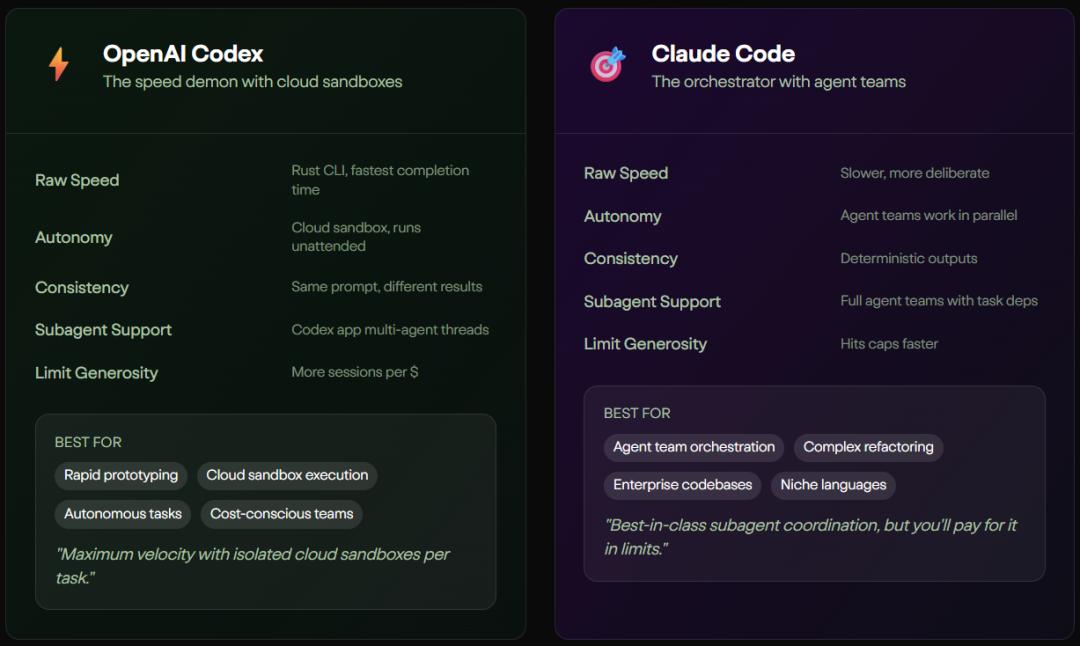
Codex 的底层逻辑是「天下武功唯快不破」。它就像是一个跟在你身后、随时准备补全代码的 5 年经验高级开发。
在 OpenAI 的构想中,Codex 是一个轻量级、高互动的终端智能体,它主打快速迭代和交互式编程。它的执行速度极快,在 Cerebras WSE-3 硬件的加持下,能够达到每秒 1000 个 token 的吞吐量。在具体的工作流中,Codex 提供建议、自动编辑和全自动三种明确的审批模式,让开发者始终保持在循环之内。这种设计思路非常符合那些需要快速构建原型、处理高频交互的极客开发者。
反观 Claude Code,它从诞生之初就自带一种高冷且克制的「架构师」属性。
Anthropic 为它注入了处理极端复杂任务的基因。它依赖高达 100 万 token 的庞大上下文窗口,以及独特的「压缩」技术来实现无限对话。Claude Code 的信条是「全局掌控,谋定而后动」。在执行任何动作之前,它会先使用智能体搜索技术吃透整个代码库的脉络,然后协调多文件进行一致性修改。对于那些涉及数万行代码迁移的企业级重构任务,Claude Code 展现出了惊人的统治力。
然而,随着时间的推移以及应用场景的不断下探,这两个原本性格迥异的工具,开始互相抄作业。
图源:MorphLLM
在处理复杂项目时,单体 AI 模型面临的最大瓶颈就是上下文污染。你让 AI 重构鉴权模块,它读了 40 个文件之后,往往就忘记了第一个文件的设计模式。为了解决这个痛点,两家公司给出了几乎一模一样的答案:为每个子任务分配独立的上下文窗口。
OpenAI 很快推出了全新的 macOS 桌面端应用,将任务按项目隔离在不同的线程中,并在云端沙盒里独立运行。Anthropic 则推出了智能体团队架构,允许开发者派生出多个子智能体,它们共享任务列表和依赖关系,并在各自的独立窗口中并行工作。你会发现,无论是叫「云端沙盒」还是叫「智能体团队」,它们在工程实现上的核心理念已经完全重合。
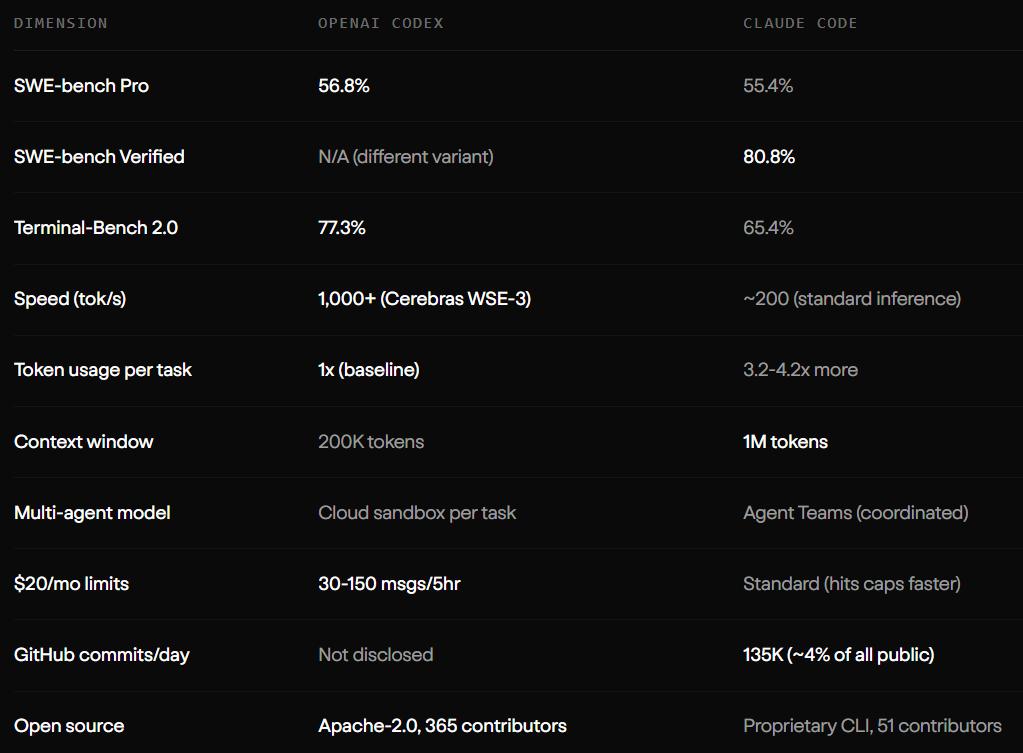
在基准测试的成绩单上,它们也呈现出一种微妙的平衡。GPT-5.3-Codex 在终端任务 Terminal-Bench 2.0 中以 77.3% 的得分领先。Claude Code 则在复杂的 SWE-bench Verified 榜单上拿下了 80.8% 的成绩。它们都在自己的优势区间里做到了极致,同时又在拼命弥补自身的短板。
OpenClaw 效应:推倒高墙的无形之手
如果说两家公司的内部战略决定了它们走向同质化的内因,那么整个开源生态的倒逼则是不可忽视的外力。在这里,我们必须要提到 OpenClaw 给整个 AI 编程工具赛道带来的深远影响。
作为开源社区推出的工作流框架,OpenClaw 的出现可以说是推倒了巨头们辛苦建立的生态高墙。它将大模型与本地终端工具链的交互过程进行了标准化。过去,如何让大模型优雅地调用本地 Git 提交、如何安全地在沙盒中运行测试脚本、如何进行多步推理验证,这些都是 Codex 和 Claude Code 各自引以为傲的专有「黑科技」。
但 OpenClaw 将这些流程抽象成了通用的协议。这意味着,开发者不再需要为了某一种特定的协同模式而被绑定在特定的平台上。开源社区的狂欢让标准化成为了不可逆转的洪流。面对这种情况,无论是 OpenAI 还是 Anthropic,都不得不放低姿态去兼容这种开放的标准。
当底层的技术壁垒被 OpenClaw 这种开源力量拉平,当所有的高级特性都成为了行业的标准配置,Codex 和 Claude Code 唯一的出路,就是在更细微的用户体验层面进行无止境的内卷。这也是为什么我们会觉得它们越来越像,因为在标准化的框架下,最优解往往只有一个 —— 就像是生物的趋同演化。
Codex 正在追赶 Claude Code
虽然 Claude Code 与 Codex 正在趋同演化的道路上,但两者的差异依然存在,甚至 Codex 在某些方面已经更受开发者青睐。
前两天,在 r/ClaudeCode 社区,一位拥有 14 年经验、曾在科技巨头工作的高级工程师 u/Canamerican726 分享了一份极其硬核的测评。
具体而言,他在一个包含 8 万行代码的复杂项目中,分别投入 100 小时使用 Claude Code 和 20 小时使用 Codex。

在他的视角里,使用 Claude Code 就像在指导一个被截止日期追赶的工程师,它冲刺速度极快,却经常会无视开发者在 CLAUDE.md 中写下的规范,并且喜欢在现有文件里不断堆砌代码来完成任务,缺乏重构思维。
相比之下, Codex 给他的感觉更像是一个拥有 5 到 6 年经验的沉稳老手。它的处理速度虽然要慢上 3 到 4 倍,但会在中途主动停下来思考并重构代码,并且严格遵守指令边界。这种高度的自主性,让这位工程师敢于把任务直接扔给它,然后放心地去做其他事情。
同样的声音也出现在 X 等社交网络上。研究员 Aran Komatsuzaki 结合自己的使用体验提到,在前端领域 Claude Code 依然占优,但在后端规划和保持信息更新方面,高频调用网络搜索的 Codex 显然更加扎实。

评论区里充满了真实业务场景下的血泪总结。有开发者极其犀利地指出,基于 Opus 的模型虽然跑得快,但往往会给项目积攒下大量的「代码清洁债务」,Codex 动作慢,却能在前行的同时顺手把地扫干净。我甚至看到有用户总结出了一条生存法则,建议大家在上下文窗口的使用率达到 70% 时立刻开启新会话,否则极其容易收到系统附赠的隐蔽 bug。

这些来自一线的真实吐槽清晰地表明,当两大神器的能力面板越来越重合时,决定开发者最终阵营归属的,往往就是这些关乎「填坑成本」和「维护心智」的微小体验差距,当然对于中国用户还有一些特殊的困难,比如:

冷思考:同质化背后的生态暗战
当然,Codex 和 Claude Code 和优劣还在于各位开发者自己,也要看开发者自身的能力,正如上述 u/Canamerican726 的评测报告总结的那样:如果你不懂软件工程,这两个工具都会输出糟糕的结果,工具并不等同于技能。
这句话戳破了 AI 编程工具长期以来营造的某种幻觉。我们曾经以为,只要有足够强大的 AI 助手,哪怕是没有任何基础的 Vobe Coder 也能单枪匹马打造出企业级应用。但现实是,Claude Code 需要一个极其专注且技能过硬的「驾驶员」,否则它很容易在庞大的代码库中迷失方向。Codex 虽然更加独立,但它同样需要开发者提供精准的系统上下文才能发挥最大效用。
那么,在工具能力高度同质化的今天,这两家公司的护城河究竟转移到了哪里?
答案藏在那些枯燥的财务报表和定价策略里。在相同的任务下,Claude Code 消耗的 token 数量往往是 Codex 的 3 到 4 倍。使用成本更高。对于企业团队来说,使用 Claude Code 每个月需要为每位开发者支付 100 到 200 美元的费用。而 Codex 则将其能力打包进了价格更为亲民的订阅计划中,并且通过庞大的 GitHub 社区积攒了大量基础用户。
图源:MorphLLM
Anthropic 的野心在于将 Claude Code 深度嵌入到那些不缺钱的科技巨头的工作流中。比如 Stripe 就让 1370 名工程师使用 Claude Code,在 4 天内完成了一项原本需要 10 个人工作数周的跨语言代码迁移。Ramp 公司更是依靠它将事件响应时间缩短了 80%。OpenAI 则依靠其无孔不入的生态渗透率,让 Codex 成为了许多普通开发者的默认选择。
这不再是一场单纯的技术竞赛,而是一场关于生态绑定、定价策略以及用户习惯重塑的消耗战。
开发者的十字路口
回望这一年来的技术演进,GPT-5.4-Cyber 的发布只是这场漫长战役中的一个微小注脚。Codex 和 Claude Code 正在走向「同一张面孔」,标志着 AI 编程工具从早期充满变数和猎奇色彩的测试阶段,正式迈入了成熟且乏味的工业化生产阶段。
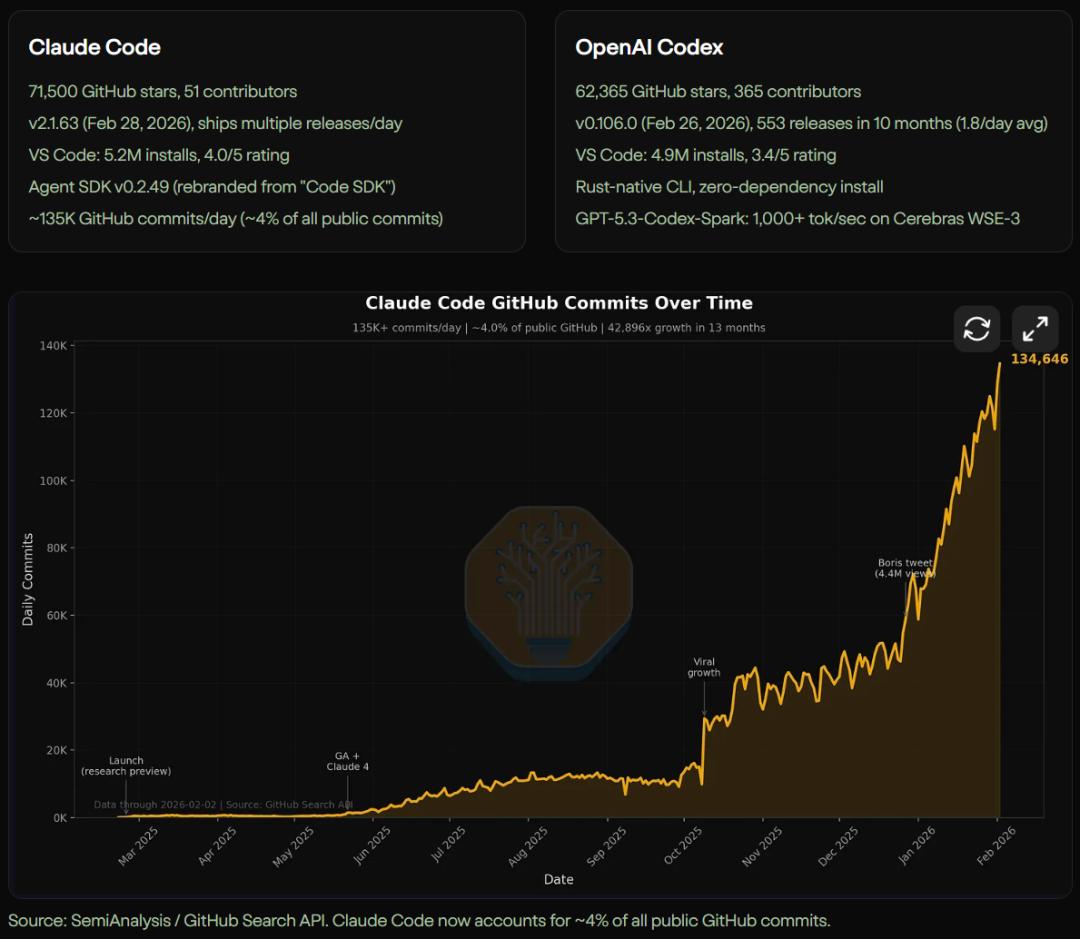
现在,Claude Code 每天会自动生成 13.5 万次 GitHub 提交,这个数字已经占到了全网公开提交量的 4%。我们可以预见,在不久的将来,大部分的样板代码、基础测试用例以及常规的代码重构,都会由这些长得越来越像的 AI 智能体在后台默默完成。
图源:MorphLLM & SemiAnalysis / GitHub Search API
面对两个在能力上无限趋近、在体验上相互模仿的超级工具,我们作为人类开发者的核心价值还剩下什么?或许,工具红利期即将彻底结束。当每个人手中都握着同样锋利的武器时,真正决定胜负的,将不再是谁拥有更好的代码补全速度,而是谁能更好地定义问题、谁拥有更宏大的系统架构视野,以及谁能在这个被 AI 填满的代码世界里,找到那份属于人类独有的不可替代性。
话说回来,你选哪个?
参考链接
https://www.morphllm.com/comparisons/codex-vs-claude-code
https://www.reddit.com/r/ClaudeCode/comments/1sk7e2k/claude_code_100_hours_vs_codex_20_hours/
https://x.com/arankomatsuzaki/status/2044270102003196007
https://www.nytimes.com/2026/04/14/technology/openai-cybersecurity-gpt54-cyber.html


