
文 | 超聚焦
DeepSeek融资了,能让大家敞开了烧Token吗?
4月18日,据上海证券报消息,DeepSeek正式启动了成立以来的首次外部融资,目标估值不低于100亿美元,计划筹集至少3亿美元资金。上海证券报记者求证称,有接近人士表示“很有可能”,还有不少投资人称:“圈里信息已经‘炸了’。”
截至目前,深度求索公司方面尚未就此次融资消息作出官方回应。路透社表示无法独立核实此消息,但在The Information发布报道后,Reuters、Yahoo Finance、Investing等主流财经媒体相继跟进转载。
在资本圈的狂欢之外,回归到大模型落地的现实里,其实DeepSeek要面临的问题不少,大家对其的期许也有不同。
相比R1模型发布时被捧上天,新一代旗舰模型发布前的DS显然承担着外界更大的期许和压力;而比起跑分、SOTA,在Agent时代里,大家显然更关注的是,DeepSeek当初在训练端打出的“成本通缩”,能否重现于如今依然高昂的推理端?
01市场不需要能力更强的R1
DeepSeek的新模型,已经“跳票”很久了。
1月中旬,The Information率先爆料称,DeepSeek计划在2026年2月正式发布下一代模型,并声称其编程实力已赶超Claude、GPT系列等顶尖闭源模型。然而整个2月,官方始终保持静默。
到了2月底,随着官方GitHub代码库中出现“MODEL1”等标识,加上金融时报等媒体和券商研报的发声,市场又传出了新模型将在3月6日当周发布的消息,结果依然是“只闻楼梯响”。
3月中旬,市场传言又有相关流言传出,甚至一度引发了A股算力板块的上涨,针对该传闻,DeepSeek官方企业咨询账号在用户群中回应:“辟谣:R2发布为假消息”。
到了4月中旬,大家苦等不来新模型,但DS的前核心研究员却选择了加入其它大厂。
据晚点报道, DeepSeek研究员郭达雅已经加入字节跳动负责大模型研发的组织Seed,成为agent负责人之一。而此前其离职是因为当时DeepSeek内部Agent的优先级不高,但2026年Agent的火热,也反衬出了DeepSeek在当下这个节点上的某种尴尬:
一边是自己曾经“轻视”的赛道如今成了全行业的主战场,甚至要被对手用自己的人才攻城略地;另一边,却是自己死磕并被外界寄予厚望的底层新模型,迟迟交不出答卷。
大模型圈在过去这一年里经历了翻天覆地的变化,也许是时候放下对DeepSeek那层“无所不能”的技术滤镜了。
毕竟在DeepSeek没有发布旗舰模型的这一年多空窗期里,整个大模型行业比拼的早已不是通用的基座能力。
首先,是原生多模态对纯文本大模型的降维打击。
当Gemini带着Nano Banana 2等模型在图像生成与编辑上大杀四方,当Seedance 2.0在视频生成领域狂飙时,单一文本模型的护城河正在被迅速瓦解。无论是行业竞争还是用户需求,早已跨过了纯文本跑分的阶段,迈向了图、文、视、音全面融合的深水区,成为了头部大模型的标配。
另一边,Coding市场也迎来了彻底爆发。
作为最能直接转化为生产力的高价值垂直场景,AI Coding的商业化空间在过去一年迎来了真正的狂飙。以Claude为代表的模型在这个细分赛道上展现出了惊人的统治力,甚至借力将ARR超过了OpenAI;而Cursor最新一轮融资后的估值也超过了500亿美元。
同时,2026年的Agent繁荣也带来了Token消耗的狂欢。
从OpenClaw到Hermas,都在将大模型的调用频次推向指数级增长。智谱、MiniMax、Kimi等厂商都凭借着海量的API调用狂卖Token,在推理端闷声发大财,甚至还推动了阿里、智谱和MiniMax转向闭源。
DeepSeek如果想要复刻R1发布时的“全网沸腾”,它面临的早已不是单点突破的考卷,而是必须要在多模态、代码生成、Agent生态上全面多线出击。
但如今的每一条细分赛道上,都有了“最高的山峰和最长的河流”,多模态有谷歌和字节的重兵把守,代码战场是Claude绝对的天下,而在Agent与Token消耗的生态里,更是挤满了红了眼的其他多模型巨头。
如果期望DeepSeek能掏出一个全知全能、在各个维度全面碾压所有顶尖大厂的“六边形战士”,既不符合技术演进的常识,也违背了当下AI产业的客观规律。
比起继续沉溺于“拳打OpenAI、脚踢Claude”的技术造神叙事,对于眼下正在艰难算账的整个AI应用层而言,大家真正迫切需要的,其实是一个远比“跑分SOTA”更性感、也更具想象力的东西。
02“价格屠夫”仍是DeepSeek的归宿
当前所有AI使用者最需要的,也是DeepSeek最可能为市场带来的,是一个叫“Token通缩”的故事。
一年前R1横空出世时,它给整个全球AI圈带来的最大“暴击”,其实不单单是某几项评测指标超越了GPT-4,而是R1真的太便宜了。
在全行业都笃信“大力出奇迹”,觉得只有像Altman、马斯克那样堆满几万张老黄的顶级GPU才能训练出旗舰模型,但DeepSeek仅用了约558万美元的训练算例成本,就撞开了顶尖基座模型的大门,相比之下,GPT-4训练成本高达数亿美元。
如此低廉的训练成本在当时引起了AI算力市场的“恐慌”。
去年1月27日,DeepSeek发布其新AI模型后,美股市场出现了剧烈波动。其中,芯片巨头英伟达股价暴跌16.97%,市值在单个交易日内蒸发了约5926.58亿美元(约合人民币4.3万亿元),创下美股史上最大单日市值损失纪录。
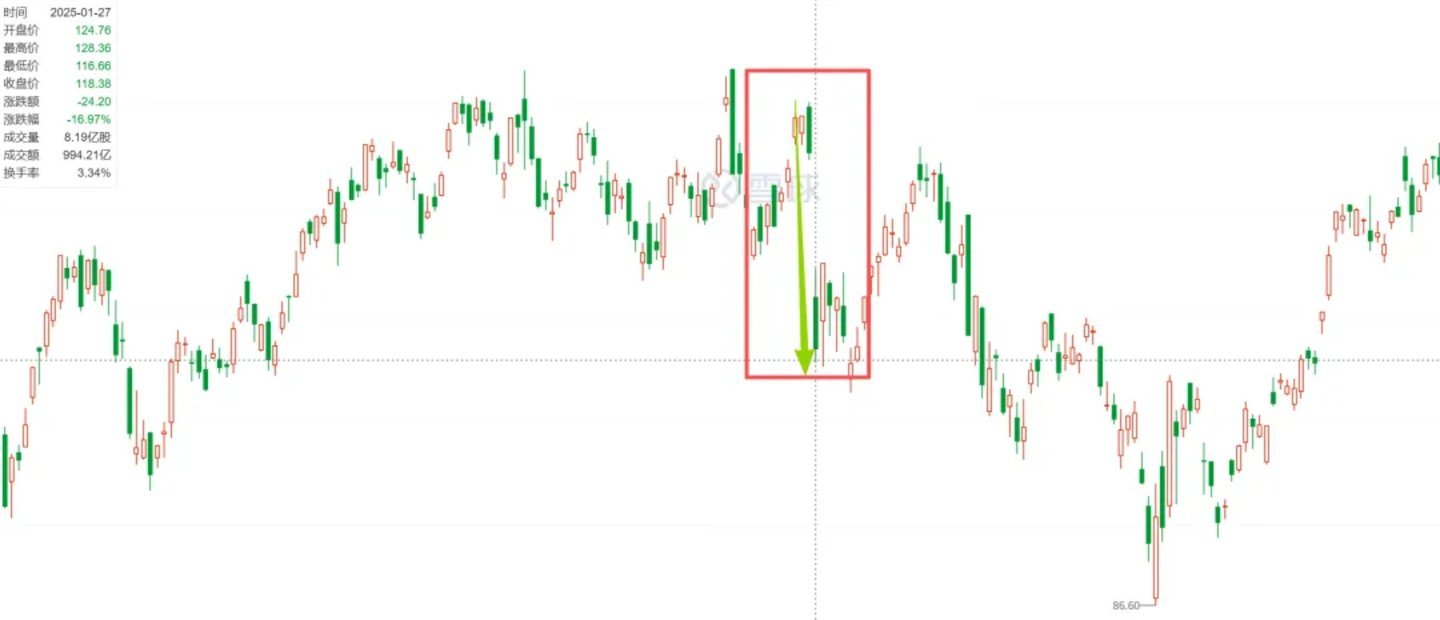
除了英伟达外,其他美国科技巨头也未能幸免。博通股价下跌17.4%,超威半导体公司(AMD)股价下跌6%,微软股价下跌2.14%,谷歌母公司Alphabet股价下跌超过4%。
彼时,DeepSeek用一套极致优化的算法和工程架构向全行业证明:智能的获取成本是可以被打骨折的,并在一年前创下了“训练端通缩奇迹”。
市场普遍担忧AI硬件基础设施的泡沫是不是马上就要破了?但一年多后的今天,大家发现根本不用担心大厂还需要买多少卡,而是自己的钱包还能不能撑得起逐级而上的Token消耗。
据中信证券,Agent带来的巨大Token消耗需求驱动了“老旧款”AI芯片H100租赁价格从2025年10月的约1.70美元/小时/GPU飙升至2026年3月的2.35美元/小时/GPU,涨幅近40%。
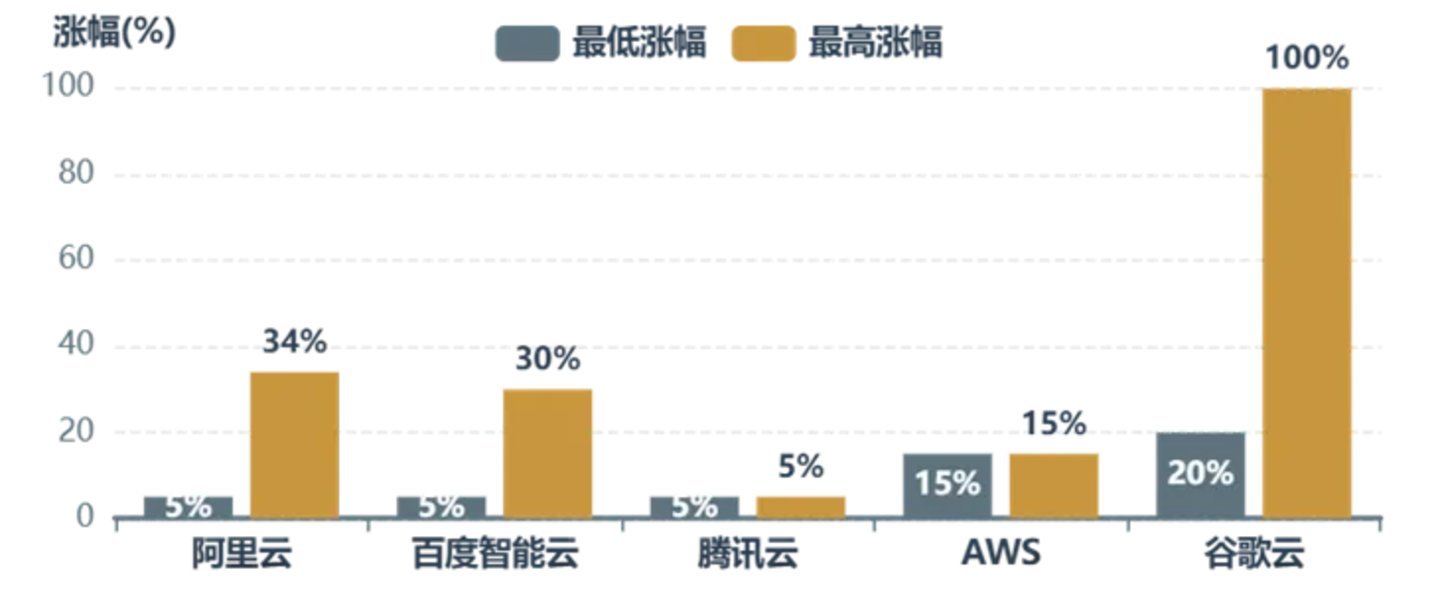
在云端,3月到4月间,国内头部云厂商接连调价,打破了行业长期低价竞争惯性。阿里云4月18日起AI算力产品最高涨幅34%,高性能存储涨幅30%;百度智能云AI算力产品上调5%-30%;腾讯云5月9日起AI算力等产品上调5%。全球范围内,亚马逊AWS已于1月对机器学习实例上调价格约15%,谷歌云也进行小幅调整。
为了降低Token消耗,巨头企业也出现了组织架构上的变阵。
3月,阿里宣布成立Alibaba Token Hub(ATH)事业群,CEO吴泳铭亲自挂帅,核心目标就是围绕“创造Token、输送Token、应用Token”来统筹AI业务。换句话来说,就是阿里看到了未来Token巨大的Token消耗,现在要从集团层面上来统筹调配Token了。
到了用户端的体感就更加明显,曾经那场免费送Token额度的“价格战”早已鸣金收兵。
现在一个看似简单的用户指令,后台往往伴随着十几次的循环反思、工具调用以及几万Token的上下文反复重载。而每个Token的消耗,都是在实打实地烧钱。
而巧的是,看起来过去一年里,DeepSeek也没有停下来Token降本的步伐。
今年元旦假期,DeepSeek提出了一种名为mHC的新架构。该研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益,让算力有限的中小AI企业,也能尝试开发更复杂的大模型。
不久后,DeepSeek开源了名为Engram的模块,并同时发布了与北京大学联合撰写的论文,阐述了一种新的大模型稀疏化方向:条件存储(Conditional Memory)。
而这两篇论文都体现了DeepSeek一直以来的方向:打破算力成本硬约束,通过架构、方法论创新,走出更具性价比的道路。
既然DeepSeek当初能凭一己之力,在训练端把竞争对手们上亿美金的训练成本打到骨折价,打出让英伟达一夜暴跌的通缩效应;那么一年后的梁文峰,又能否在Token消耗逐渐成为天量的现在,在推理端再当一次“价格屠夫”,把全行业的Token单价打个骨折呢?


