
全球首个具身数据独角兽光轮智能,2026年一季度狂揽5.5亿元订单,刷新具身数据行业纪录,直接引爆“具身数据元年”。
把订单拆开来看,背后浮现出的并非单一需求,而是两股力量在今年第一次清晰交汇。
一边,是具身大模型与世界模型对高质量数据、仿真环境和规模化评测的需求集中释放;另一边,则是工业、物流、农业、家电、汽车等产业场景,开始为机器人在真实世界中的训练、验证与部署投入真金白银。
前者推动模型跨过从“演示”到“训练”的门槛,后者则把行业推向另一个更现实的问题:机器人进入真实场景之后,如何在持续运行中不断优化。
而光轮智能,恰好站在这两个需求曲线的交汇点上。
它所连接的,既是训练机器人的数据,也是围绕数据展开的评测和部署的基础设施体系。到了物理AI时代,这恰如一条铺设好的公路。
5.5亿元订单之于光轮智能,远非终点,而是走向产业更深处的起点。
具身大模型,率先拉动数据需求
过去一年,具身智能领域的竞争,更多还停留在模型与算法层面。
但到了2026年,行业的重心开始悄然前移。越来越多团队发现,决定模型上限的已不只是参数规模,数据的重要性迅速抬升。数据的多样性、物理保真度以及闭环迭代能力,开始成为新的关键变量。
于是,今年被业内视作“具身数据规模化元年”。随着全球头部具身智能团队纷纷抛出百万乃至千万小时级的数据采集目标,数据迅速成为各家竞逐的基础性战略资源。
当前,无论是世界模型,还是VLA,都被迅速推向更复杂、更真实的任务空间。它们面对的,不再只是图像与语言理解,而是要在真实物理世界中完成长时序、多步骤的复杂任务,包括物体操作、环境交互,以及不确定条件下的持续决策与规划。
这一趋势已经在前沿模型上得到验证。以Generalist AI的Gen-1模型为例,该模型依托50万小时规模的人类视频数据进行模型预训练,进一步验证了具身智能领域正在出现的Scaling Law:当高质量、可规模化的数据持续供给,模型的泛化能力就有机会跨过新的门槛。这也表明,真实人类视频数据并不是边缘补充,而正在成为具身预训练阶段最重要的数据来源之一。
不过,随着机器人逐步迈向更复杂任务,新的行业瓶颈也在显现。人类视频数据固然解决了具身预训练中的行为先验问题,却还不足以独立支撑后续的规模化学习与规模化评测。
实际上,当前具身大模型面临的核心瓶颈,并不只是“缺数据”,更准确地说,是一种结构性的短缺。
一方面,人类视频数据与仿真合成数据之间,还没有形成足够有效的互补机制;另一方面,行业里也少有能够把两类数据真正整合起来,并持续驱动模型迭代的数据体系,也就是所谓“数据飞轮”。其难点在于规模化评测,没有统一、可量化的评测标准,数据就很难有效反哺模型迭代,所谓闭环也难以真正建立。而光轮智能所做的,正是把人类视频数据、仿真合成数据与规模化评测打通,形成一套可闭环、可量化、可持续迭代的数据基础设施。
眼下,能搭建完整“数据飞轮”体系的企业仍是少数,需求正加速向具备体系化供给能力的公司集中。
这也解释了,为什么光轮智能能在短时间内手握5.5亿元订单。
为什么是光轮智能?
风口来了,并不意味着谁都能接得住。
尤其是具身智能这样一个仍处于早期、标准尚未完全统一的产业,真正能承接头部需求的,往往不是声量最大的那个人,而是最早把底层能力打磨出来的人。
乍看之下,光轮业务覆盖人类数据、仿真合成数据和仿真评测,像是同时做几件不同的事。但顺着底层逻辑看,其实始终只做一件事:构建一套可闭环、可迭代、可规模化的具身数据基础设施。
具体而言,这套体系可以拆解为三个相互支撑的层次:世界World、行为Behavior、评测Eval。
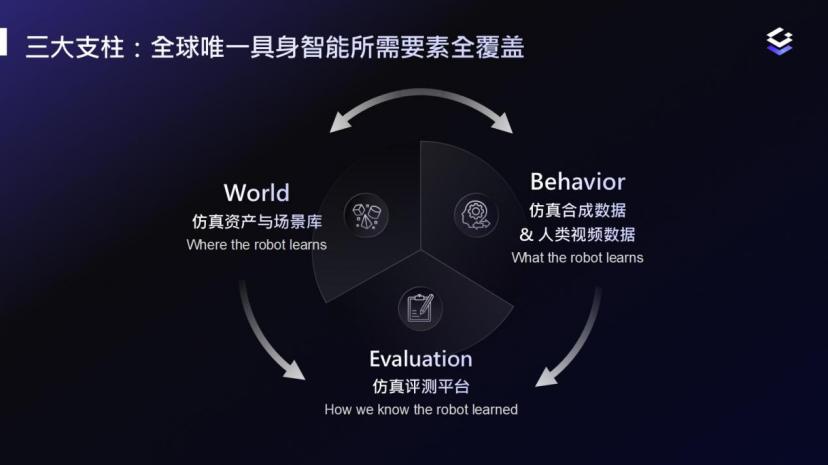
世界层,是机器人进行学习、训练与评测的物理世界。它不是普通的3D资产库,也不是偏展示性的游戏式场景,而是一个在物理规律上尽可能贴近现实的仿真环境:物体可以被抓取,门有阻尼和磁吸,布料会形变,线缆能够弯折并承受作用力。
行为层,负责持续生产行为数据。既有大规模仿真合成数据,也有来自真实世界的人类第一视角视频、遥操作轨迹和其他真实行为先验。前者解决规模问题,后者提供约束与校准,二者共同构成模型学习的基础。
评测层,是整套体系里易被忽视却愈发关键的一环。具身智能的真正难点不是做出一个Demo,而是稳定地判断模型能力是否真正得到提升。没有统一、可复现、可并行、可量化的评测体系,数据很难有效指导训练,模型也难以持续迭代。
这三层并非简单并列,而是构成了一个持续运转的飞轮:世界层提供环境,行为层生成数据并拓展任务分布,评测层持续暴露模型短板,再反向决定下一轮数据采集、生成与覆盖的重点。由此,数据、仿真与评测形成一个持续运转的系统。
再往下看,这套闭环之所以能够成立,更关键的支撑来自“求解—测量—生成”三位一体全栈自研仿真技术底座。测量真实世界的物理属性,生成可复用、可扩展的SimReady世界,随后借助自研solver与仿真能力,在虚拟环境中跑出物理上可信、行为上可执行的结果。

也正因此,光轮智能承接的,已不是零散的数据采购需求,而是逐渐清晰的基础设施型需求。
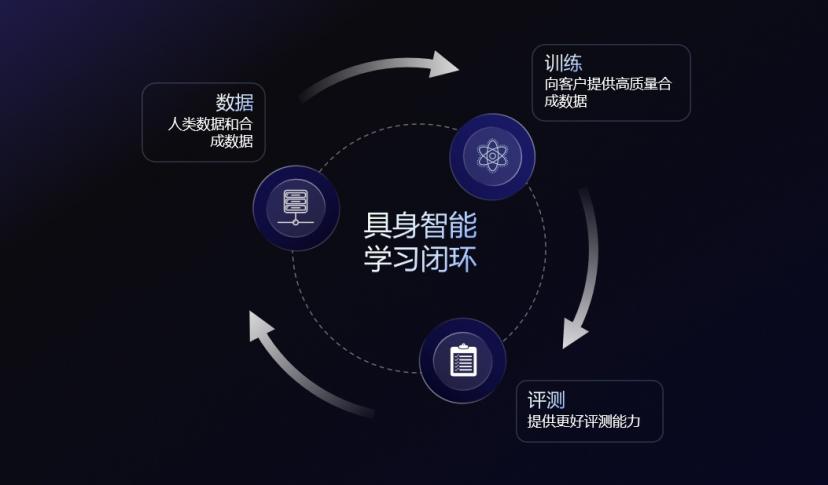
这是光轮智能一直在强调的核心区别:它想做的,不是一家数据工厂,而是一台数据引擎。
相比之下,传统数据公司更像数据工厂:客户提需求,平台交付数据,项目结束,价值也随之终止。光轮构建的则是持续运转的引擎:真实世界的数据与测量进入系统,经由仿真世界被放大、重组,行为数据在其中持续生成;评测体系再把模型的失败模式与能力边界反馈回来,反向驱动下一轮数据采集、场景生成与任务定义,最终再服务于真实部署。

把这套逻辑看明白,再去看光轮的订单表现,答案其实已经写在结果里。投资界了解到,按具身数据销售额计,光轮已位居全球前列,且已在人类数据、仿真合成数据、仿真评测三大领域拿下国际交付冠军。
先看人类数据。光轮搭建起可规模化的人类第一视角数据解决方案EgoSuite,数据节点覆盖25000多个环境,执行超过10万种任务,累计交付超150万小时高质量人类数据。
再看仿真合成数据。光轮已建成全球交付规模最大的仿真合成数据AutoDataGen。国际主要具身智能团队中,超过80% 的仿真资产体系建立在光轮提供的资产与合成数据之上。
在仿真评测领域,光轮推出工业级机器人规模化评测平台RoboFinals,已形成涵盖数十个高价值行业、万余个真实Real2Sim2Real场景的评测基础设施。并携手通义千问共建可复现、可诊断的工业级评测闭环,合力推动具身智能评测行业基座的确立。
凭借体系化能力持续积累,光轮智能正以物理AI仿真基础设施为支点,进一步引领国际仿真标准的制定与演进。
近日,光轮已受邀作为核心指导委员加入开源GPU加速物理引擎 Newton,在关键具身仿真技术方向上发挥主导作用,与NVIDIA, Google DeepMind, Disney Research, Toyota Research Institute 等顶尖机构引领推动下一代开源物理AI仿真标准。
与此同时,光轮自研的LeIsaac已被Hugging Face官方文档采纳为具身仿真的标准框架,成为全球开发者进入该领域的统一工程范式,直接定义了大规模开发实践的起点与边界。
需求爆发后
产业端开始接过第二棒
如果说具身大模型公司和机器人公司点燃了第一波需求,那么产业端正在接过第二棒。
相比模型团队倾向于让机器人“学会”,产业客户关心的是落地:部署、执行、验证、迭代与复制这一整套能力能否真正跑通。
这意味着,当机器人进入工厂、仓储、物流、农业、医院、汽车等真实场景时,产业侧需要的已不再是局部能力,而是一整套打通数据、评测与部署的基础设施体系。

真实产业场景里,本就蕴含巨大的“数据金矿”。一条产线、一个仓库、一座工厂,背后沉淀着大量尚未被开采的物理交互经验:动作如何完成,机器人容易在哪些步骤失效,哪些接触力、路径修正和恢复策略更关键,哪些任务能够标准化,哪些长尾场景又必须依靠仿真扩展覆盖。
问题在于,过去这些经验大多停留在现场,难以被结构化,也难以进一步转化为可复用、可评测、可持续迭代的资产。而产业端真正需要的,正是将这些经验转化为机器人能力。
于是,行业讨论的重点,已经从“要不要机器人”,转向如何持续开采并放大场景中的数据价值。
这也解释了,为什么产业客户越来越需要一套围绕场景展开的基础设施。先在真实场景中提取高价值数据与约束,再通过仿真把场景扩展成一个可训练、可覆盖长尾、可规模化评测的平行世界;随后借助评测体系识别哪些能力已经稳定,哪些能力仍需继续迭代,最终再把验证过的能力部署回真实场景。
放到产业端来看,世界、行为、评测这三层的意义也变得更具体。世界层对应的是为真实场景建立一个可扩展的数字平行世界,行为层负责把产业现场的经验转化为可学习的行为数据,评测层则成为机器人进入真实场景前的能力诊断。
落到商业化层面,变化已然明了:订单来源正从具身大模型团队,进一步扩展到真实产业场景中的客户。
据投资界了解,目前已有上百家场景方企业正与光轮接触或推进合作,覆盖制造业、农业、物流、家电、汽车等多个领域。与此同时,周度新增接洽企业仍达数十家。真实场景对具身数据基础设施的需求,已经明显提速。
这一趋势也体现在资本层面。就在上个月,光轮智能完成10亿元A++及A+++轮融资,摘得全球首个具身独角兽桂冠,引入新希望集团、奥克斯等具备深厚产业资源的战略投资者,产融协同的格局初步显现。
而光轮智能也在逐步把这套能力落地为标准化、平台化、可规模复制的基础设施。可预见的是,未来接入的产业场景越多,这种能力就越关键。
物理AI时代,数据就是“水电煤”
回过头看,这5.5亿元订单的意义,早已不只是金额本身。
它更像一个信号。透过光轮智能,具身智能产业正在显露出新的重心。
相比以往行业比拼的是算力和模型,如今进入物理AI时代,随着机器人一步步走向真实世界,支撑其持续学习、持续迭代、持续部署的底层基础设施,开始被重新看见。
如果说算力是上一轮AI竞赛里的“电网”,模型是机器的大脑,那么到了物理AI时代,数据更像是“水电煤”——看不见,却决定了整套系统能否真正运转起来,并规模化落地。
沿着这条线往下看,接下来的竞争焦点也愈加明了。谁能在真实场景中持续供给数据,谁能让训练、评测与部署真正形成闭环,并持续、稳定地为机器提供学习与进化的能力,谁就更有机会走到前面。
而光轮智能,已经抢得先机。


