
4 月 16 日,Anthropic发布了Claude Opus 4.7。但这一次,Opus4.7模型并没有迎来“Coding之王”的一片赞叹声。
它的发布通稿里写着:在93 道代码任务基准上比Opus 4.6提升 13%,解决了 Opus 4.6 和 Sonnet 4.6 都搞不定的四道题,低思考档位的 4.7 已经大致等价于中等思考档位的 4.6。价格没涨,每百万输入 token 5 美元、输出 25 美元,和上一代持平。硬指标上,Anthropic仍然展示了一张压过 ChatGPT 5.4 和 Gemini 3.1 Pro的基准图。
漂亮的Benchmark之外,社区的反馈却不那么“漂亮”。
一边是过去数周里用户对 Opus 4.6 “变笨”的激烈抱怨;一边是 Anthropic在同一天亲口承认,Opus 4.7 仍打不过还在自家“关着”的传奇模型“Mythos Preview”。更微妙的是Opus4.7那种“更听话但更死板”的气质,以前针对旧模型写的、带一些模糊空间的 prompt,现在常常跑出意料之外的结果,开发者必须回头重写自己的提示词库。
沃顿商学院教授 Ethan Mollick 还提出了一个更尖的批评,他发现 Opus 4.7 的“自适应思考”机制存在偏见:它倾向于把非代码、非数学任务默认成“低努力”档,在分析、写作、研究这些场景里直接“偷懒”,产出质量甚至不如前一代。
Mollick感慨:AI 公司似乎陷入了一种“只有技术工作才是智力工作”的认知偏差。
风水轮流转。
就在同一天,老对手OpenAI 更新了Codex,并强调了一句新的Slogan,“Codex for (almost) everything”。
翻译过来,在Codin范式之下曾经被Antropic“压着打”的OpenAI反击说:代码只是入口,我们现在要“卷”的是一台能操作你整台电脑、能看浏览器、能生成图像、能跨 Slack / Gmail / Notion 拉取上下文、能在后台并行开几条分身的超级工作台。而且还有一个扎心数据点:GPT系列的 coding 能力过去一年快速追上来了。
当Anthropic 继续沿着“最强coding模型”这条赛道继续加码,Anthropic在开发者心智里那道护城河,可能已经没那么宽了。
01 价格账、鹈鹕和真实体感
产品层面,开发者每天面对的是两件具体的事:价格和实战手感。这两件事上,Opus 4.7 这次没拿到想象中的分数。
先说价格。 Opus 4.7 名义单价和 4.6 持平,但用了新分词器(tokenizer),同样文本生成的 token 量可能增加 1-1.35 倍;更高努力档也会消耗更多 token,账面没涨,实际账单可能会涨。相比之下外媒测算 Codex 综合成本大约是 Claude Code 的三分之一。对一个每天跑海量任务的工程团队,这笔账不用算两遍。
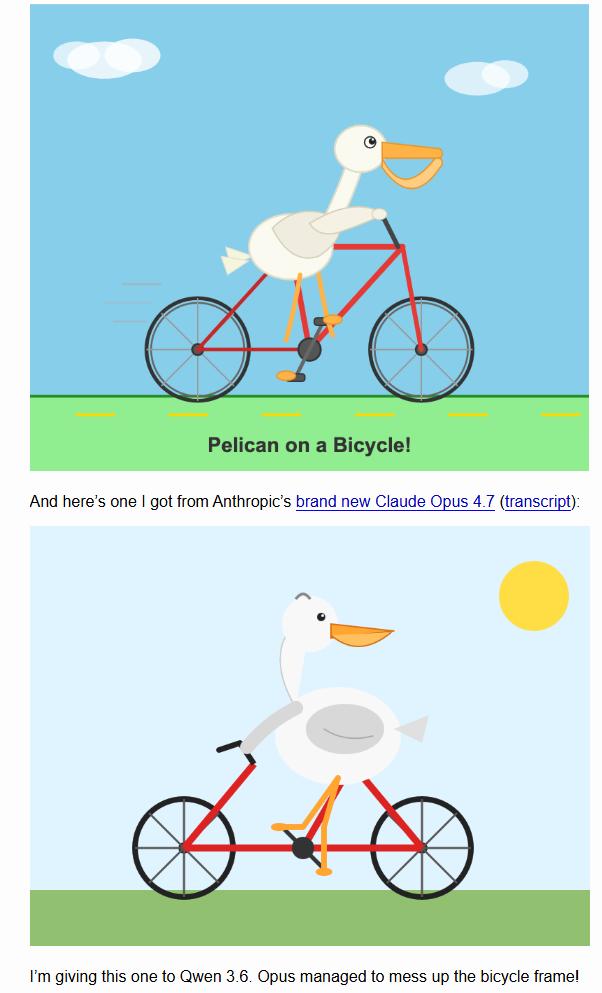
再看手感。 软件工程专家 Simon Willison 做了个极具传播力的测试:让 Opus 4.7 生成一张“骑自行车的鹈鹕”SVG,结果 4.7 连自行车架的基本形状都画砸了,甚至输给了在笔记本本地跑的小参数模型 Qwen。威利森调侃道,虽然这只是个玩笑,但它确实打破了“模型越贵、画画越好”的迷信。
在真实的编程环节,用户@SnazzyLabs总结出了一个精准的差异:Claude的Opus擅长“打磨”和抓住设计精髓,但在根据描述性文本执行具体任务时,GPT-5.4支持的Codex则表现得更出色 。
用户 @Stardustmemory 说得更重,Opus 4.7 在本该简洁的地方凭空制造复杂性,导致他甚至不想续订,因为 Codex 往往能更高效地重写 Opus 做的计划。
网友@Stardustmemory更是言辞犀利,他认为Opus 4.7在本该简洁的地方凭空制造复杂性,导致他甚至不想续订服务,因为Codex往往能更高效地重写Opus做的计划。
知名爆料人@apples_jimmy观察到,由于Anthropic此前对AGI(通用人工智能)概念的长期预告,导致用户对Opus 4.7的期望值过高,这种“炒作后的失望”在社交媒体上占据了约80%的负面评论。
网友@johnhelmuth_ 也认为,大家之所以觉得Opus 4.7表现平平,很大程度上是因为它没有像Opus 4.6发布时那样给人带来“开创性”的震撼。
02 coding之战,已经不是coding
Opus被行业内打的标签是“Coding的王者模型”,但是回到coding竞争,绕不开三个层次,今天这三层的权重正在剧烈变化。
第一层是模型能力层,谁的原始智力更强、谁对工程约束理解更深。这一层是 Anthropic 过去的护城河。
第二层是任务能力层,谁能端到端完成真实开发任务:读代码、改代码、调工具、跑测试、抓错、迭代,Claude Code 在过去半年是这一层的王者。
第三层是系统能力层,谁能把“写代码”嵌入整套工作流:接管浏览器、操作桌面、生成界面和图像、连工单、读设计稿、管并行分身。这一层至今为止还没有公认的赢家。
4 月 16 日,OpenAI 把 Codex 直接推到了第三层:它能在 macOS 上看屏、点击、打字;能同时开多条分身在后台跑活;内置浏览器,可以直接在网页元素上评论发指令;接上 gpt-image-1.5,边写代码边出 mockup、前端稿甚至游戏素材;一口气集成 111 个插件,连通 Slack、Gmail、Notion、GitHub。
这更像是一个“开发者操作系统”。
03 Coding和Agent
在所有 AI agent 可能落地的垂直场景里,coding是最快成熟、最先变现、最容易闭环的那一个。
代码任务天然可验证,编译过不过、测试过不过,对错近乎二元,这让 coding 成为 RL训练最理想的数据源,也让 agent 行为最容易被自动评估、自动迭代。有价值的 coding 天然是多步骤的
coding的买单方最清晰,一个工程师年成本几十万美元起,AI 替代或放大一部分工时,ROI账更容易算的过来。
coding的天花板,甚至超过了之前所有人的预期。互联网时代大家习惯拿 DAU来衡量科技公司的竞争地位,但在 agent 时代这个指标正在失去意义,如果一个 agent 在后台连开十条分身、连续跑三天,它贡献的价值不是十次DAU能衡量的。衡量单位正在从“日活”变成“任务完成量”、“托管工作流数”。而 coding 是最早出现这种价值计量方式的场景。
Open AI在这条赛道曾经出现了误判,Anthropic持续的增长曲线却证明了这条赛道的超高天花板。这也解释了为什么连一直优先搜索和 Workspace的Google,这个月都在 Gemini Code Assist 上频繁出动作,如果在 coding 这个入口掉队,未来整个 agent 生态可能都会把自己排除在外。
在 coding 上领先,不等于自动赢得agent;但在coding上失去阵地,就等于失去了agent的全部。
Open AICodex 负责人 Thibault Sottiaux 在发布会上说得毫不遮掩:“我们在公开构建那个 super app,这次面向开发者,未来会扩到更广的受众。”
翻译过来就是:coding 只是我们推出超级agent 工作台的第一个楔子。用开发者这个付费意愿最强的群体冷启动,形态跑通后可以把同一套东西搬去服务所有知识工作者。
Codex 现在每周 300 万活跃开发者,这远超“代码助手”的体量,争夺操作系统级入口的产品。清醒过来之后的OpenAI,也不可能甘心做Anthropic的追随者。
Anthropic 在守王座,OpenAI 想把竞争拉到新的维度。
04 基因完全不同的“德比”
这两家同源的老对手,几乎没有过一致的动作,也有着完全不同的组织性格。
Anthropic 是一家 top-down、战略高度聚焦、带强烈信仰感的公司。
它的产品序列很窄,Claude系列模型、Claude Code、Claude.ai、有限 API 生态。服务的是专业塔尖用户:最难的编程任务、最复杂的企业知识工作、最前沿的 agent 开发者。整个组织叙事从一个清晰的顶层观点往下推:AI safety 是 first-principles、模型本体是一切源头、把模型做到最强其它自然成立。Amodei 兄妹那种“我们是一个做前沿 AI science 的实验室”的气质贯穿每个产品决策。
这种打法让每一代 Claude 都是“更稳、更深、更可托付”的迭代,Claude 是“最懂工程师的模型”这个心智在社区里像信念一样结实。
但代价也明显。它的战略聚焦在同维度里是优势,跨维度就是盲区。如果战场从“做一个更强的代码模型”扩到“做一整套跨应用工作台”,Anthropic 内部缺乏并行探索的肌肉。外媒前几天爆出 Anthropic 在准备一款“网站和演示文稿设计工具”,是否一直不做多模态的Anthropic可能意识到了多模态交付和跨应用执行的缺口?
OpenAI 看起来更像一家大公司、内部有着 bottom-up 的赛马制。
从 ChatGPT 到 Sora、从 Codex 到 Atlas 浏览器、从 Canvas 到在做的 Mac 超级应用,OpenAI 产品序列宽得惊人,宽到了战略不聚焦的程度,Sora 上线半年就关停,Shopping 也没跑通。很多人因此批评它战略发散。
但这种“不聚焦”背后有一种外部看起来的“混乱”:大公司壳子、小团队内核、bottom-up 提案、内部赛马拿资源。但也会催生各种0-1的创新。
Anthropic 把“聚焦”当优势,OpenAI 把“不聚焦”当优势。如果竞争真的被Open AI从Coding的纵深拉入系统级,横向整合,竞争的格局也许又会发生变化。
05 Anthropic会是永远的coding之王吗
如果赛道定义还是“模型写代码最强”,Anthropic 短期几乎没对手。 Opus 系列对大型 codebase 的理解深度、对复杂工程意图的对齐程度,GPT-5.4 和 Gemini 3.1 Pro 都还没完全追上;Mythos Preview还没全量放出。第一层战场上 Anthropic 弹药充足。
但这个定义本身正在被改写,而且还有两个变量在加速改写。
第一个变量是算力。 微软和甲骨文给OpenAI兜底的千亿级 GPU 资源加上Stargate;Anthropic 虽然也拿到了 Google 和 Amazon 的大额支持,但绝对量级上仍然差一截。过去两年算力差距还可以用算法效率和数据质量部分弥补,但下一代模型同时要为多模态、长上下文 RL、跨应用行为克隆烧算力的时候,纯算力的绝对优势会压过精细打磨的优势。这是大范式上的变量,Anthropic再聚焦也很难抵消。
第二个变量是迭代速度。AI 这一轮最反直觉的一点是,它自己的成长速度比人类快得多。
一旦胜负标准从“模型能力”切到“平台能力 + 算力规模 + 多模态广度 + 工作流闭环”,而且这种切换又被算力代差和数据飞轮加速,竞争格局又会发生新一轮的变化。
这不是否定 Anthropic。Claude Code 在资深开发者圈里的口碑不会一夜瓦解,Anthropic “持续稳定迭代模型”本身在这个动荡行业里就是稀缺资产。但确实,AI的竞争,切换得太快了。
没人敢在这个行业谈终局。
4月16日,AI行业又闪过了有趣的一天,也许,改变又开始萌芽了。Anthropic 发布的是一个更强的代码模型,OpenAI 发布了一个更大的野心。


