
杨植麟身上正在形成一种很典型的创业者光环。
行业抬头看技术,他站在台上讲推理、Agent和未来几年由AI主导的研发;市场低头看产品,Kimi在过去几个月里快速上线了一系列新功能:能写文档、做PPT、处理表格、写代码的KimiCode,能自动抓取网页信息的Kimi Claw,能深度检索资料的Deep Research,以及能多个AI协作完成复杂任务的Agent Swarm。
外界因此很容易得出一个顺滑结论:月之暗面(以下简称月暗)正在从一家明星模型公司,走向一家下一代生产力平台公司。
这个判断没有错,只是不够完整。
因为当Kimi不再满足于只做一个“会回答问题”的模型,而是试图成为“知识工作的执行平台”,它真正进入的,就不再是一个靠技术突破就能轻易赢下来的赛道。那里站着的不只是几家大模型公司,而是一整排已经控制了开发者入口、办公入口和企业工作流的巨头。
而Kimi的难,不只是对手强,更在于它几乎同时在做两件最重的事:一边补足承接复杂工作的底层能力,一边又去争知识工作的前台入口——
别人要么手里已经有入口,要么先从能力层往上爬,Kimi 则更像是在地基尚未完全筑厚时就把自己推到了正面战场。而这条路的资本强度太高,护城河形成速度又未必能快到和烧钱速度匹配。
杨植麟擅长把控方向,但一家公司的胜负,从来不只取决于方向,还取决于能不能把技术、产品、增长和商业化,用同一种节奏拧在一起。
前者更像天才的直觉,后者则属于企业家的功课。与其说杨植麟已经给出了完整答案,不如说,他正走到这道题最难的部分。
01
光环
2026年3月,美国拉斯维加斯英伟达GTC大会的主舞台上,杨植麟与OpenAI、DeepMind的负责人并列而坐。这是全球AI顶级从业者的标准合影,但杨植麟的身份标签与旁人略有不同——他是唯一独立大模型创业公司的代表,其余均为科技巨头旗下的项目负责人。
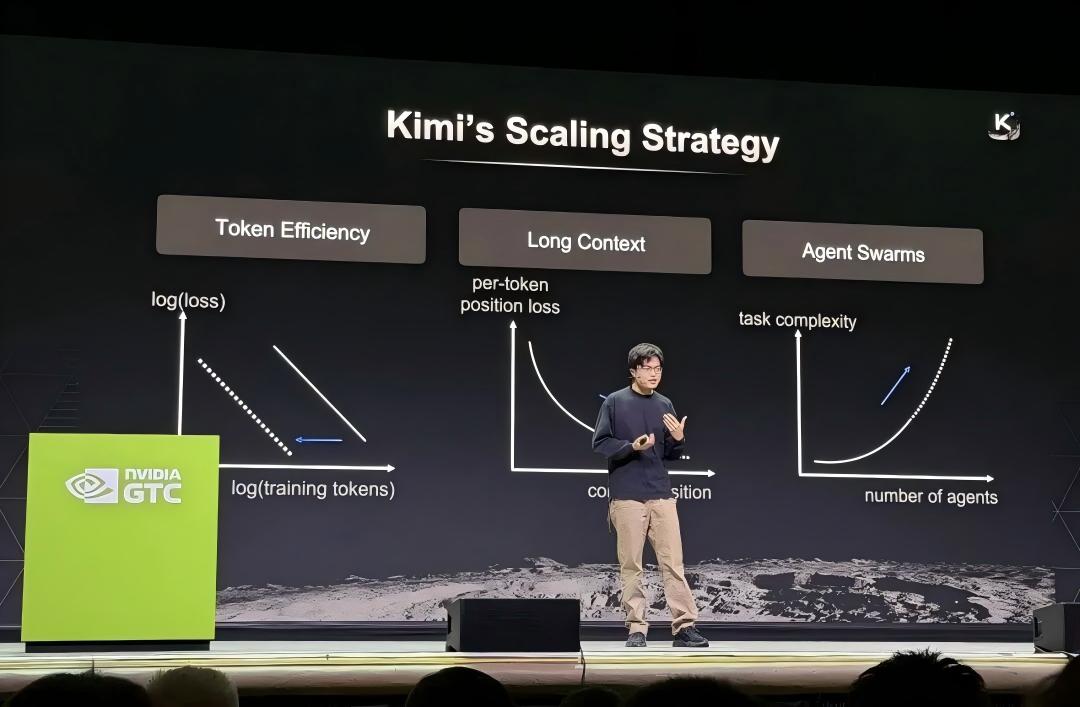
这张照片传回国内时,月之暗面的估值刚刚突破180亿美元,三个月内翻了两番,创下中国公司晋级“十角兽”(指那些估值超过100亿美元的未上市初创公司)的最快纪录之一。
不过,它的身份或许很快会再次发生变化:前不久,彭博社传出消息,月之暗面已与中金公司和高盛展开关于赴港IPO事宜的初步接触。智谱与MiniMax高光在前,对于月暗的IPO之路,外界很容易把这种光提前投射到这家公司身上。
这也几乎是杨植麟身上那层创业者光环的自然延伸。
在中国这一代AI创业者里,杨植麟是少数几个不能只放在国内语境里讨论的人。并且在决定大模型公司上限的那些关键问题上,月之暗面已经不能只拿来做本土比较。
真格基金作为月暗早期的投资机构之一,管理合伙人戴雨森对于杨植麟的认可是不加掩饰的,他曾在一篇文章中透露,杨植麟在清华读书时被公认为“神中之神”。这样的情绪渲染对于理解杨植麟并不完全多余。
杨植麟的学术底色,几乎是为大模型时代提前铺好的:
2015年,他从清华大学计算机系毕业,后以年级第一的成绩进入卡内基梅隆大学语言技术研究所。此后四年,他持续出现在ICML、NeurIPS、ICLR等AI顶级会议的作者名单里,很早就进入全球最核心的学术评价体系。
更重要的是,这并不只是“发过几篇好论文”那么简单。他以第一作者或共同第一作者身份参与提出的Transformer-XL 和XLNet,至今仍是预训练模型发展史上绕不开的名字。前者推动了长文本建模能力的跃迁,后者更是预训练模型领域绕不开的里程碑,其思想直接影响了后续GPT系列的技术路线。
2019年,他成为ACL(计算语言学协会,顶级国际学术组织)史上最年轻的领域主席之一,在创立月之暗面之前,又先后在Google Brain 和FAIR(Meta旗下基础人工智能研究研究院)任职——既有理论研究者的锋利,也有顶尖工业实验室训练出来的工程质感,这样的经历,在国内并不常见。
也正因如此,外界在评价月之暗面时,谈论的往往不只是能力,还有一种更难被量化的气质。或许用Manus首席科学家季逸超对Kimi的评价可以一语概之:
“Kimi这家公司,还是比较有品味的。”
品味,taste,这两年频繁的在创投圈里被提起,常常被认为是AI公司唯一的护城河。2026年3月《纽约客》甚至直接写:“taste”已经成了硅谷新的buzzword,热度有点像 2010年代的“disruption”。
在季逸超眼中,品味的具象化,体现在一家公司的evaluation或者内部的benchmark上,“因为你内部的衡量指标,无论是对于模型的benchmark,还是对于人,其实决定了这家公司和产品该走的方向”。
杨植麟身上一个很突出的特点是,他似乎并不满足于“按别人的题目把分考高”,而总想先确认:这道题本身出得对不对。
绝大部分行业公开的benchmark从根本上来说是由人工定义的,经常会存在benchmark不够或者失效的现象。
“现在agent能用的benchmark不是很多,而且你在benchmark上看到一个分数,很多时候并不是agent能力的反应,甚至很片面,这个是我觉得大家要去解决的一个问题。”杨植麟在《张小珺|商业访谈录》的播客中,曾披露过行业的这一现状。
但很多公司为了刷分,只针对性的让模型做几个特定场景,以方便对外发新闻稿来达到不同的目的,然而,那并不是模型真实的表现能力,在一些更OOD(Out-of-Distribution,可简单理解为“超纲“)的场景里,体感就会变得很差。
基于此,月暗内部补了一套更贴近真实工作的benchmark:
比如K2.5在代码方向上,并不只看公开榜单,而是自己设计了Kimi Code Bench,去衡量build、debug、refactor、test这些更接近真实软件工程的任务;在办公场景里,又专门做了AI Office Benchmark和General Agent Benchmark,去看Office输出质量和多步工作流到底完成得怎么样。
往里一层,在K2.5 Agent Swarm的训练里,它的奖励机制也不只是“调来更多agent”这种表面的热闹,它会刻意避免两种情况:看起来很多agent,实际还是串行在做;或者为了“并行”好看,硬拆出一堆无效步骤,反而拖慢整体进度。
这几乎是季逸超那句话的具象版本:你用什么 benchmark,就会训练出什么产品。月暗不是先做出一堆功能,再反过来替它们找解释,恰恰相反,是它先决定什么样的能力值得被度量,产品才沿着这些指标往外生长。
只是,这样的路径也意味着更高的研发成本,更慢的产品节奏,以及对底层模型能力持续兑现的更高要求。
事实上,这也是杨植麟过往风格的延续。
无论是Transformer-XL,还是后来的XLNet,他做的都不只是沿着既有路径再往前推一点。前者试图解决的是,模型在面对更长信息时,为什么总会出现记不住、接不上的问题;后者则干脆绕开当时主流预训练路线的一些先天缺陷,重新改写了题目本身。
这两项工作的共同点在于,它们都没有停留在既定框架里做加法,而是直接碰了当时行业默认接受的前提。
这就是杨植麟。他似乎从来不满足于只在现成赛道上提速,而总要先追问一句:这条赛道的起点、规则和边界,是否本来就值得重画。
到了创业时期,他身上这种“先定义问题,再做技术”的习惯,变得更具体了。
早在2023年Kimi以超长文本能力进入公众视野时,杨植麟看重的就不只是“能装下更多内容”,而是另一件更底层的事:当信息越来越多、任务越来越长时,模型还能不能把前后文接住,并持续往前推。
今天再回头看,Kimi首页摆出来的,已经不只是一个对话框,而是Docs、Slides、Sheets、Deep Research、Kimi Code、Kimi Claw、Agent Swarm这样一整排能力模块。表面上看,这是产品在变多;往深一层看,它们其实都在回答同一个问题:
模型真正的价值,不是某一刻把一句话答得多漂亮,而是任务一旦被拉长、被做复杂之后,它还能不能一路不掉链子地把整件事接住。
而一个试图做到这一点的产品,最终就很难停留在“聊天助手”的位置上,它会被一步步推向更重的角色:知识工作的入口、调度台,甚至执行平台。
但当Kimi从“回答问题”转向“调度知识工作”,它就很难只守一头:往下要补模型,往上要争入口。缺了用户关系,只是别人的能力供应商;缺了底层能力,又撑不起“把事做完”的承诺。这意味着月之暗面从一开始就走进了一场更重的战役——资本密度更高,兑现周期更长。
而当一家公司同时打两场战争,钱就不再只是财务问题,而是战略本身。月之暗面当然不至于为生存发愁,但它怎么会不缺钱呢?
02
怎么会不缺钱呢?
2025年的最后一天,杨植麟发布内部信,透露公司的现金持有量超过100亿元,作为对比,同样以IPO前的财务数据为基准:MiniMax在赴港招股时,若只看现金及现金等价物,约为24.9亿元人民币;智谱同期约为25.5亿元人民币。若按更宽口径看可动用资金,MiniMax约为72.1亿元人民币,智谱约为32.1亿元。
于是,杨植麟说:“我们短期不着急上市”。然而3个月后,月暗IPO的消息不胫而走。看起来,似乎与杨植麟的“不着急”前后矛盾。
不过,把这两句话放回同一条时间线上看,它们未必真的互相抵触:前者说的是,月之暗面当下并不需要为生存或续命仓促上市,后者对应的则是,在AI概念再度受到资本追捧的窗口期,这家公司也没有理由把一条可能更宽的融资通道长期关在门外。
要知道,能不为眼前的生存焦虑上市,和该为下一场更昂贵的战争提前备粮,本来就是两回事。
更何况,月之暗面怎么会不缺钱呢?
行业如今正在发生的变化是:模型公司向上抢入口,办公巨头向下吞模型,协作平台横向加AI。这三股力量表面上方向不同,但底层想争的是同一样东西:知识工作的控制点——也就是杨植麟目前所在的战场。
说的更直接一些,大家都想从“帮用户做一点事”走向“定义用户怎么做事”。
原因并不复杂:大模型正在变得越来越聪明,但“聪明”本身并不直接创造价值。真正决定价值能否落地的,是谁能先把这颗大脑接进现实世界的手和脚里。
就像一个伟大的方案,若不能执行落地,那无异于纸上谈兵。
一个大模型公司都不得不面对的事实是:模型层的“纯智力租金”正在快速被压缩。
我们以Anthropic为例:Anthropic在2024年6月发布Claude 3.5 Sonnet时,API定价就是$3/百万输入token、$15/百万输出token;到2026年的Claude Sonnet 4.6,官方文档给出的价格仍然是$3/$15,但上下文窗口已经到了1M token,并明确主打agents、coding、computeruse。
也就是说:模型能力在显著跃迁的同时,单位“智力”的价格并没有跟着抬升,反而更像被竞争锁死了。
国内就更不必说,2025年,大模型价格战已经卷到几乎贴着成本线打:阿里云2月将通义千问视觉理解模型降价超80%,百度4月发布文心4.5 Turbo和X1 Turbo时,又把输入价分别打到0.8元和1元/百万tokens,月暗也在同月下调开放平台价格,官方明确写到,Kimi-latest自动缓存后的价格仍只有1元/百万tokens。
《财经》曾援引多位云厂商负责人的说法指出,2024年5月以前,国内大模型推理算力毛利率还高于60%;但在5月各大厂接连降价后,这一毛利率已跌至负数。
另一边,头部公司的路径已经越来越一致:卖的都不只是 token,而是把模型变成能真正干活的系统。
OpenAI已经把web search、file search、containers 单独拿出来收费,在Responses API 和Agents SDK 里,也直接把工具调用、状态管理、多步执行写进产品定义;Anthropic同样不再只收模型调用费,web search 和 code execution另行计价,对Claude Code的定义也不再是代码补全,而是能读代码库、跨文件修改、运行测试、交付结果;
Google一边在Gemini API里把搜索增强、上下文缓存存储拆出来卖,一边又把Gemini全面塞进 Gmail、Docs、Sheets、Meet、NotebookLM 等Workspace体系,强调服务每个员工、每条工作流;
微软则把Copilot做成贯穿Microsoft 365的工作入口,覆盖聊天、搜索、文件、邮件和agents构建;飞书和钉钉也都在把AI往会议纪要、任务提醒、知识问答这些高频工作环节里嵌。
甚至连Notion、Cursor这样的轻量级选手也已经把自己包装成“AI workspace”,主打Agent、Enterprise Search、自动化和知识空间。
Kimi也把钱从API挪到“我替你动用了多少工具、占用了多少环境、持续运行了多久”上:Kimi web search每次调用收费0.005美元,搜索结果token还会继续计费;Kimi Claw的一键云部署则需要Allegretto(每月$31)或更高会员。
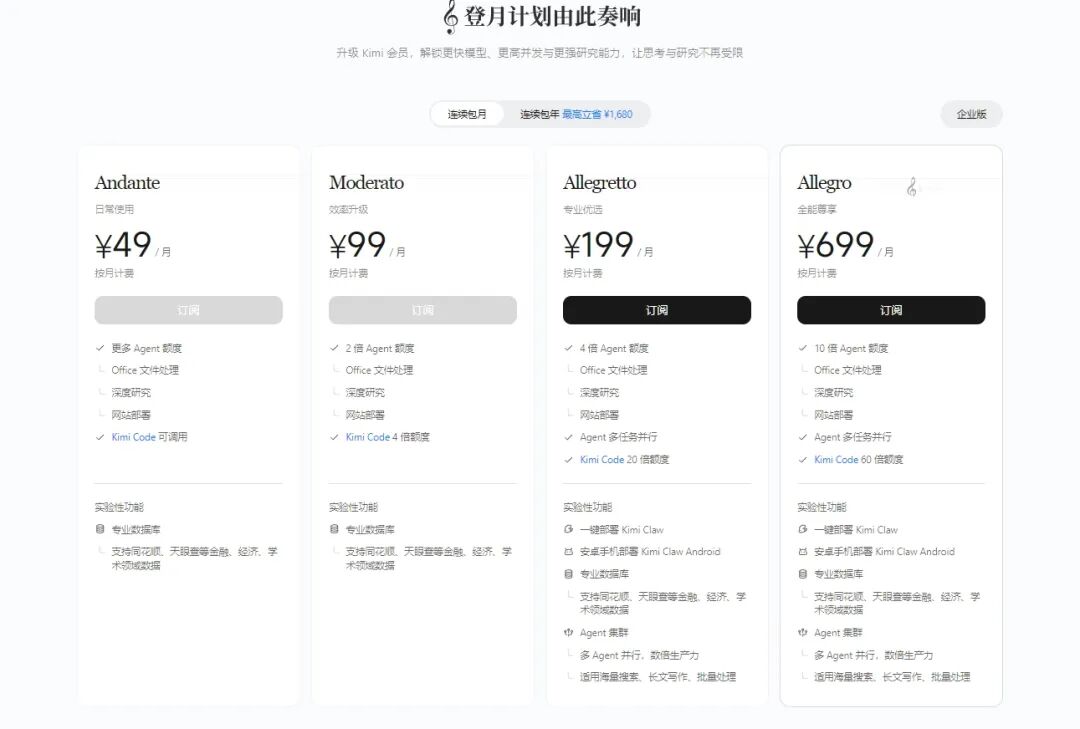
市场也用真金白银给出答案:微软这边,2026财年第二季度财报显示,Microsoft 365 Copilot的付费席位已达 1500万个,按标价年化测算约为54亿美元;谷歌则成功实现了Scaling Law到商业利润的转化。根据2026年初的披露,Gemini Enterprise已售出超过800万个付费席位,覆盖超过2,800家大型企业客户。
当然,“喜报”里也有升级为“知识工作执行平台”的Kimi:
据第三方基于Stripe支付数据的追踪,Kimi个人订阅用户1月支付订单数环比增长8280%,2月环比再涨123.8%。在其全球支付榜单上,短短两个月,Kimi排名由百名开外飙升至第9位。
据Gartner(全球最知名的技术研究与咨询公司)判断,到 2035年,agentic AI可能贡献企业应用软件收入的约 30%,规模超过4500亿美元。
于是,一个更清晰的格局开始浮现:大模型公司的终局对手正在快速收敛。
OpenAI、Anthropic、Google、微软,以及月之暗面这样的新玩家,看上去分属不同位置,做的却越来越像同一门生意——把模型接进真实工作流,争夺知识工作的入口、调度权和收费权。也正因此,他们彼此都在改写对方的边界,也彼此成为对手。
这场战争烧钱的速度,与对手的体量成正比,而月之暗面要同时与数家万亿市值的巨头对垒,每一轮弹药补给都是生死线。
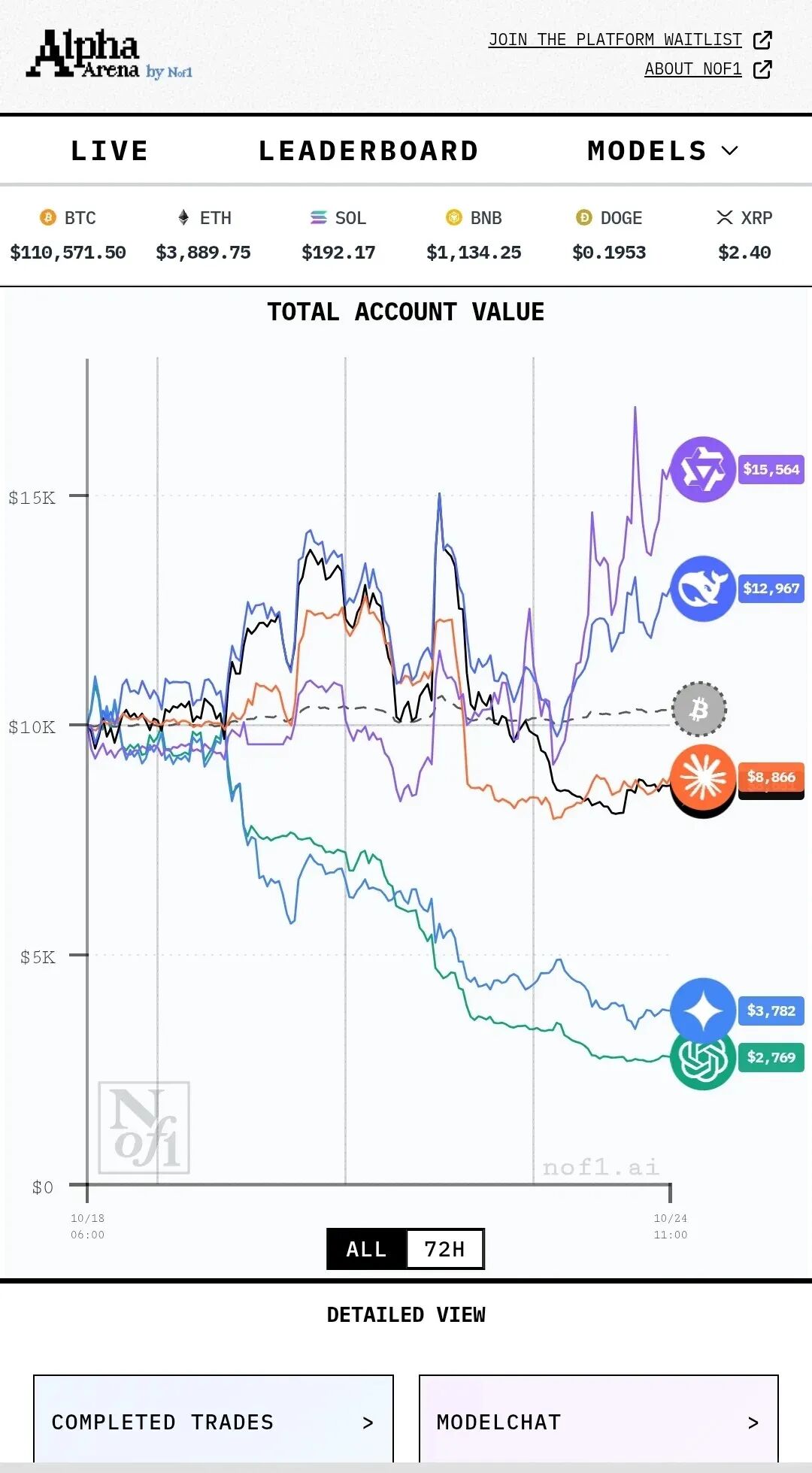
图注:月之暗面要同时对垒的巨头们
而最难的是,尽管站在同一片战场上,大家要打的仗却并不一样。
对大多数公司来说,这更像是一场单线推进的竞争:
有的是从既有入口往下压,比如Google、微软、飞书等,它们原本就守着Docs、Sheets、Word、Excel这些现成的入口,AI对它们只是升级,不是开荒;
有的公司选择从模型能力往上爬,比如智谱和MiniMax,皆是以能力层起家,再慢慢往agent和应用层上探。 OpenAI和Anthropic也是同理,先模型后产品,并且如今它们已经占住了开发者和代码助手的高地,可以从容地向外扩张;
而Notion、Cursor、Perplexity这种,它们的优势不是模型一定更强,而是用户原本就在它们那里干活,已经在用户的某个具体工作场景里扎得很深了。
它们各自都有根据地,只需专注在将自己的优势继续放大上。
但Kimi没有。对杨植麟而言,他像是在同时应付几场战役:
它既没有现成的办公入口,也不甘心只做底层能力的供应商。它想让用户直接把工作交给Kimi,这就意味着它不仅要证明模型够强,还要证明用户有理由改变原本的工作习惯。
前一种成本,是训练、推理、Infra和工程;后一种成本,是产品打磨、市场教育、组织渗透和企业信任。这意味着月之暗面要同时承担两条最昂贵的战线:一条是模型军备竞赛的硬成本,一条是用户习惯迁移的软成本。
Google和微软每年在AI上的投入以百亿美元计,但它们的Office 365和Workspace本就是盈利业务,AI投入是“升级存量”而非“创造增量”。
OpenAI虽也无宿主平台,但其C端付费用户数已突破 5000万,月收入约20亿美元,年化收入超过250亿美元;Anthropic近期被报道年化已快速抬升至300亿美元,形成了自我造血飞轮。
月之暗面则不然。它的估值在三个月内从43亿美元飙至180亿美元,创下中国“十角兽”最快晋级纪录之一,但这恰恰说明资本对其“多线作战”能力的极度渴求——
既要养得起K2.5这样的万亿参数模型和端到端强化学习的算力消耗,又要熬得起企业客户从试用到真正依赖的18个月平均转化周期;既要维持C端免费策略以抢夺用户时长,又要搭建企业级私有化部署和API服务体系。
据行业估算,其2024年单年算力支出已超10亿元人民币,而Agent产品的工程化、多模态能力的持续迭代、以及海外市场拓展,都将继续推高这一数字。
更关键的是,这场战争没有终局。模型能力每提升一代,入口争夺就要重新打一遍;用户习惯每松动一寸,就需要持续的产品投入来巩固。短时间内就去IPO,更像是“永远需要更多钱”的注脚。
而比“永远需要更多钱”更紧迫的现实是:它的钱甚至还没找到稳定的来路。
03
道阻且长
如果把这场竞争理解成一场阵地战,Kimi更像是一个火力很猛、意图很靠前的远程兵种:出手快、爆发强、打法直接,但它背后的补给线、原生地盘和容错空间,却远比对手脆弱。
月暗的造血困境,藏在它最光鲜的履历里。
尽管估值已经突破180亿美元,但它的收入规模尚不及对手的零头。2025年,月之暗面C端订阅收入估算约2亿元人民币(数据来自于媒体《光锥智能》),加上API收入也难以触及1亿美元。
即便2026年K2.5发布后“20天收入超过2025年全年”,这种爆发更多反映的是此前基数之低,而非商业模式之稳。
更深层的问题在于,它的用户来得快,去得也快:2024年11月,它的月活是3600万,一年后(2025年Q3)跌至不足千万。
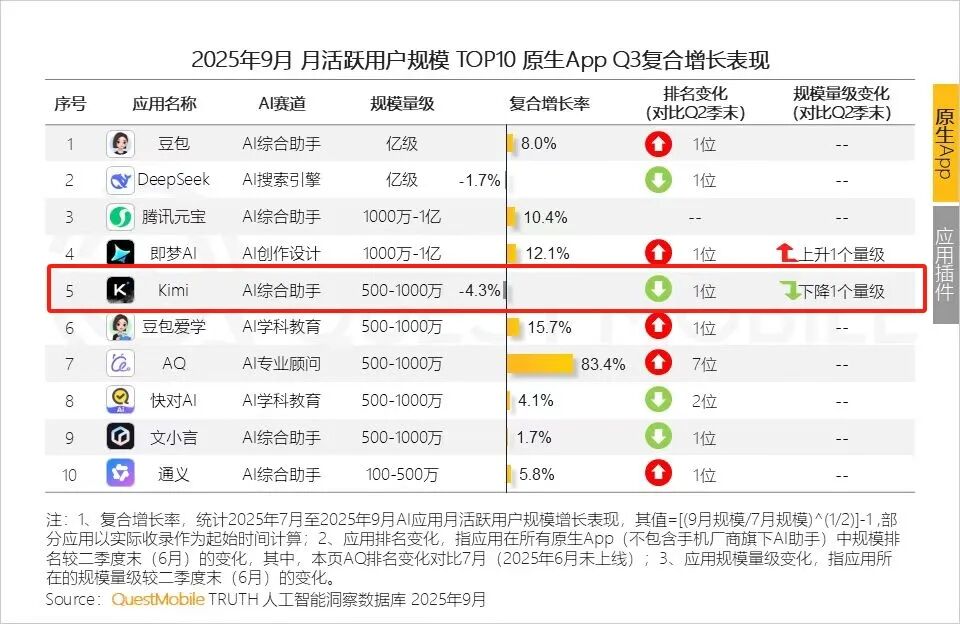
数据过山车的背后,也暴露出杨植麟在运营层面的偏好:更擅长方向判断与关键决策,而非渐进式的节奏把控。
2024年,月暗是行业公认的“投流狂魔”,高峰期每月投放高达数亿元,10月和11月单月投放甚至超过了2亿元。
但到了2025年情况变了。字节、阿里这样的巨头,靠着自己原有的流量入口和产品生态,把拉新成本抬得很高。对月之暗面这种创业公司来说,单靠花钱买用户,越来越像一个填不满的无底洞。
与此同时,DeepSeek又用极高的工程效率,把模型能力的价格迅速打了下来。Kimi早期靠“长文本”建立起来的那点领先优势,也被快速稀释了。
在此背景下,杨植麟的应对不是精细化调优,而是直接“踩刹车”:全面停止投放,暂停多个安卓渠道与第三方广告合作,停更两款出海产品。全员信明确“不以绝对用户数量为目标”。

图注:杨植麟内部信截图
从“烧钱换增长”到“全面收缩”,战术转换大开大合,几乎没有中间过渡地带。这意味着前期投入的人力与资源并未沉淀为可持续的能力,而是随着战略转向直接清零。用户侧更出现真空期:原有C端用户习惯被中断,新用户群体教育尚未完成,品牌能见度骤降。
但问题并不止于此。
比起增长失速更值得警惕的是,月之暗面的收入结构本身,也没有看上去那么扎实,尤其是被寄予厚望的海外业务。
月暗的API收入在2025年底增长4倍,2026年初,随着开源Agent产品OpenClaw爆火,近四分之一的Tokens消耗来自该生态,另有大量调用来自AI编程工具如Kilo Code等第三方编程工具。
也就是说,Kimi的海外收入并非来自自有产品的粘性用户,而是作为底层能力被集成进别人的应用——用户不属于自己,入口也不掌握在自己手里。
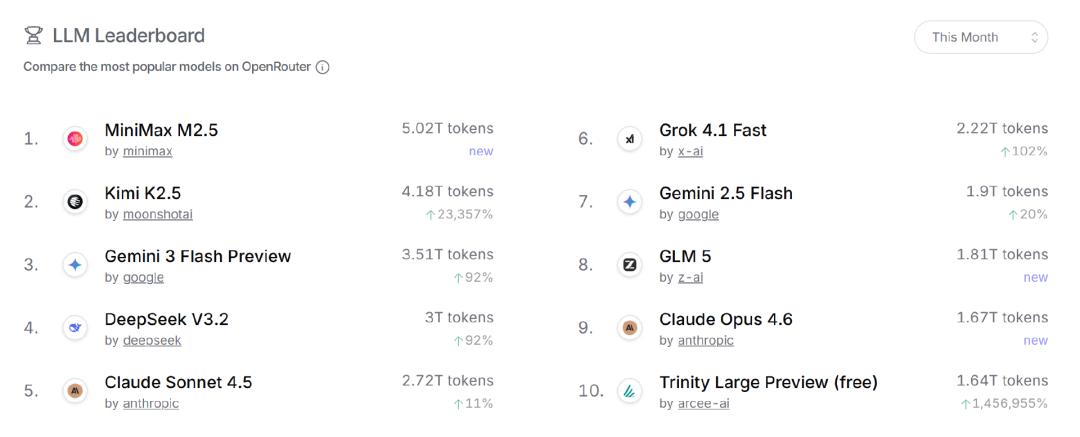
图注:OpenRouter数据显示,今年2月,Kimi K2.5模型成为海外市场调用量第二名
这类收入的最大问题在于,议价空间有限,替代风险极高。一旦这些外部产品转向其他模型,收入链将瞬间断裂。
与此同时,它的烧钱速度从未放缓。2025年底对全员进行调薪和期权激励,2026年计划将平均激励翻倍;新增融资明确用于“扩增显卡规模、推进K3研发”。账面现金超过100亿元,却在不到两个月内连续完成两轮超12亿美元融资——
充裕的储备反而印证了造血能力的不足,若自我运转强劲,便无需如此急切地储备弹药。
但这也是战略定位的必然代价:既无现成入口,又未建立稳定的用户付费心智,当对手可以靠既有业务输血、靠生态锁定用户时,月之暗面只能靠自己一轮又一轮地融资,来同时填满两个无底洞。
戴雨森曾透露,杨植麟希望被认可的标签里,“企业家”是其中之一。只不过到今天,这位“天才”身上更鲜明的,仍然是工程师的质地。
在2025年底的那封内部信里,杨植麟把“超越 Anthropic、成为世界领先的AGI公司”写成最重要目标,又强调“不以绝对用户数量为目标,持续追求智能上限”,甚至明确提到“需要一点偏执的审美坚持”。
野心与方向感依然坚定,但反过来看,问题也在这里:一个创始人太相信只要模型足够好,别的问题都会被穿透。
事实上,这种思路不只影响他怎么看产品,也影响他怎么搭组织。因为当“更快、更强、更直接”被放在首位时,组织结构也会自然向极致扁平和高强度沟通倾斜。
公开报道里,杨植麟的个性签名就是“直接沟通”;公司长期坚持极致扁平,没有中间管理层,联创要直接对接40到50位同事。这样的组织当然有速度,也很适合高天赋、高自驱的人,但报道也同时写到:规模一大就会出现信息过载,一些员工会因为缺少清晰反馈和确定性而感到失重。
换句话说,他可能更擅长拉高标准、压缩链路、逼近真相,但未必同样擅长给更大规模的人群提供秩序感、安全感和可持续的管理结构。
一个人被过早放进“神中之神”的叙事里,市场就会天然高估他的确定性,低估一家公司真正要面对的复杂性。
杨植麟信奉一句话:“Problems are inevitable, but problems are soluble.” (问题是不可避免的,但问题也都是可以被解决的),这句话出自近年来被硅谷追捧的一本书:《The Beginning of Infinity》,这本书是由物理学家David Deutsch撰写的。

巧合的是,有批评者认为,Deutsch的这本书低估了组织、政治、人性在知识传播中的摩擦成本——这正是杨植麟这类技术理想主义者容易忽视的维度。
在回答张小珺“为什么AI产品还没有形成数据飞轮”时,杨植麟是这样解释的:
“因为基于算力的scaling太强大了……另一方面,所谓的数据飞轮是很依赖外部环境的feedback(反馈),这个feedback我们不希望它有很多的噪声,但现在可能somehow还没有把这个问题解决的很好,大模型的学习对噪声还是比较敏感的,跟传统的推荐系统不太一样。”
简单理解就是:在当下这个阶段,算力扩张和强化学习带来的能力提升仍然十分明显;相比之下,让模型直接从复杂、嘈杂的用户反馈中持续学习,这条路还没有被真正跑通。
某种程度上,这种对“内部确定性”的倚重,也延伸到了杨植麟看待外部世界的方式里。
他曾说,要在“自己的故事里去感受自己是个什么样的人”。这句话未必是一种回避,更像是他处理不确定性的方式:当外界围绕投放、留存和商业化不断提出疑问时,他更愿意回到自己更熟悉、也更相信的那部分东西——技术迭代、能力提升,以及内部逻辑的持续自洽。
但月之暗面终究会走向更大的舞台。Scaling Law的红利也许还没有结束,可一家公司能不能走远,终究不只取决于模型本身。再往后,真实世界的反馈、团队的承接和商业的耐心,都会成为同样重要的变量。
对杨植麟而言,这或许也是另一门课:如何让技术之外的部分,也慢慢长出来。


