
「开放」和「开源」,并非一字之差。
Google 的 Gemma 系列发布已有两年,但开发者能下载、能本地运行,但用途受限,再分发受限,改了也不能随便传播。充其量说,这只能算「开放」,还达不到 AI 圈「开源」的标准。

Google DeepMind CEO Demis Hassabis
就在刚刚,Google 发布四款 Gemma 4 系列模型,支持 Apache 2.0 全面开源,其中最小的版本可以在树莓派上完全离线运行。Gemma 小模型,第一次真正意义上地落到了每个人手里。
以小小小小胜大
Gemma 4 共发布四个尺寸,底层技术与 Gemini 3 同源,覆盖从边缘设备到高性能工作站的硬件:
E2B / E4B:专为手机和 IoT 设备设计,与 Google Pixel 团队及高通、联发科深度合作优化。推理时分别仅激活 2B 和 4B 参数,以尽量节省内存和电量。
支持 128K 上下文窗口,具备图片、视频和原生音频输入能力,可在 Pixel 手机、树莓派、Jetson Orin Nano 上完全离线运行,延迟接近于零。Android 开发者现在可通过 AICore 开发者预览版提前体验 Agent Mode。
26B MoE:混合专家架构,推理时仅激活全部参数中的 3.8B,在保证极快推理速度的同时维持较高质量,Arena AI 文本评分达到 1441,位列开源模型第六。
31B Dense:追求极致原始性能,Arena AI 文本评分达到 1452,位列开源模型第三。未量化的 bfloat16 权重可在单张 80GB NVIDIA H100 上运行,量化版本支持消费级 GPU,为本地微调提供强力基础。
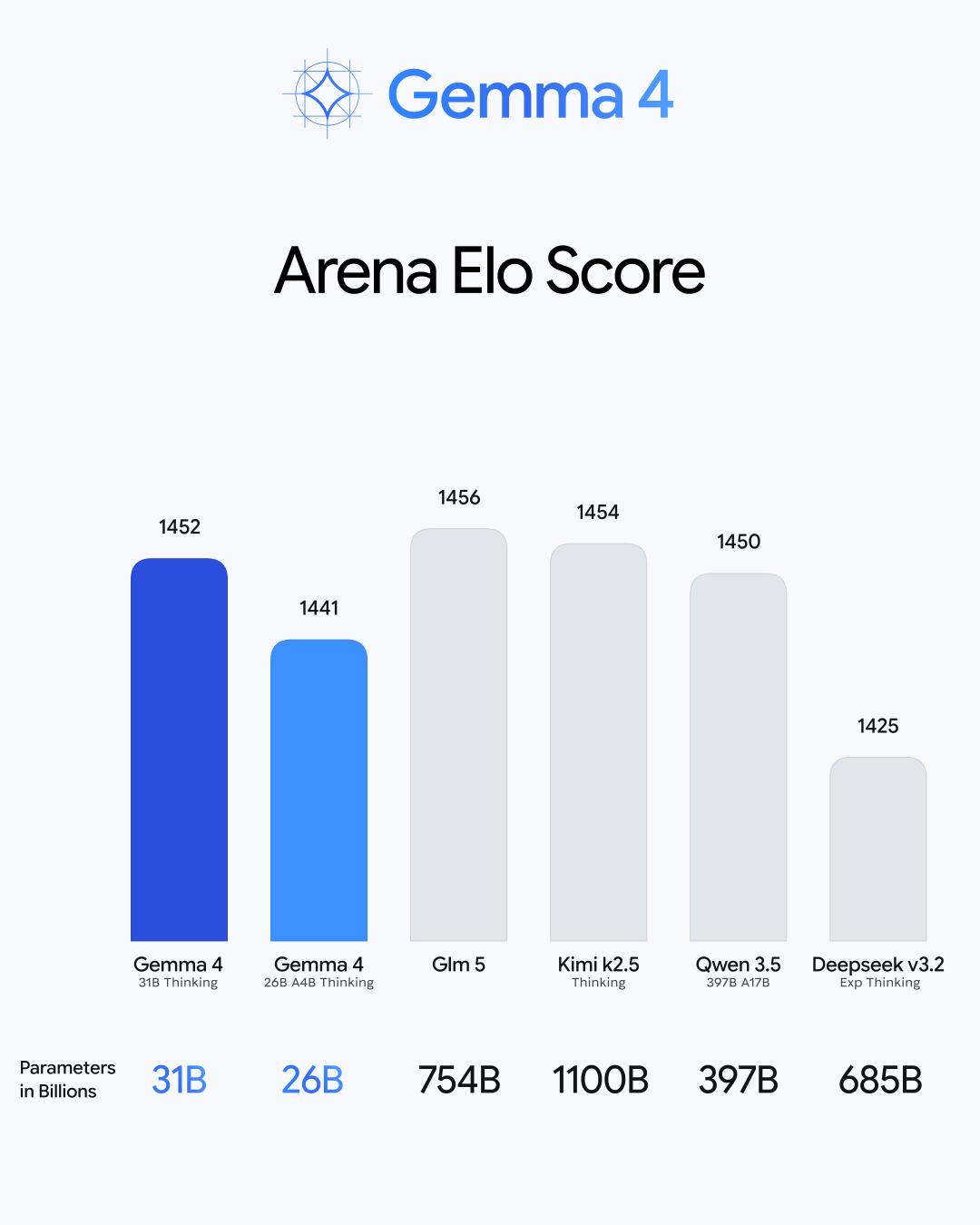
在能力层面,四款模型高度一致:均支持多步推理和复杂逻辑;原生支持函数调用、JSON 结构化输出和系统指令,可构建能与外部工具和 API 交互的自主 Agent;
支持图片和视频输入,擅长 OCR 和图表理解等视觉任务;预训练语言超过 140 种。26B 和 31B 的上下文窗口进一步扩展至 256K,可在单次提示中传入完整代码库或长文档。
基准测试的数字,能更直观地说明这一代的升级幅度。与上一代 Gemma 3 27B 相比,Gemma 4 31B 在数学推理基准 AIME 2026 上从 20.8% 跳升至 89.2%,代码能力基准 LiveCodeBench v6 从 29.1% 升至 80.0%,衡量 Agent 工具调用能力的 τ2-bench 则从 6.6% 大幅提升至 86.4%。
这三项数据尤为关键,因为它们直接对应推理、编程和 Agent 三个当下最核心的应用场景。
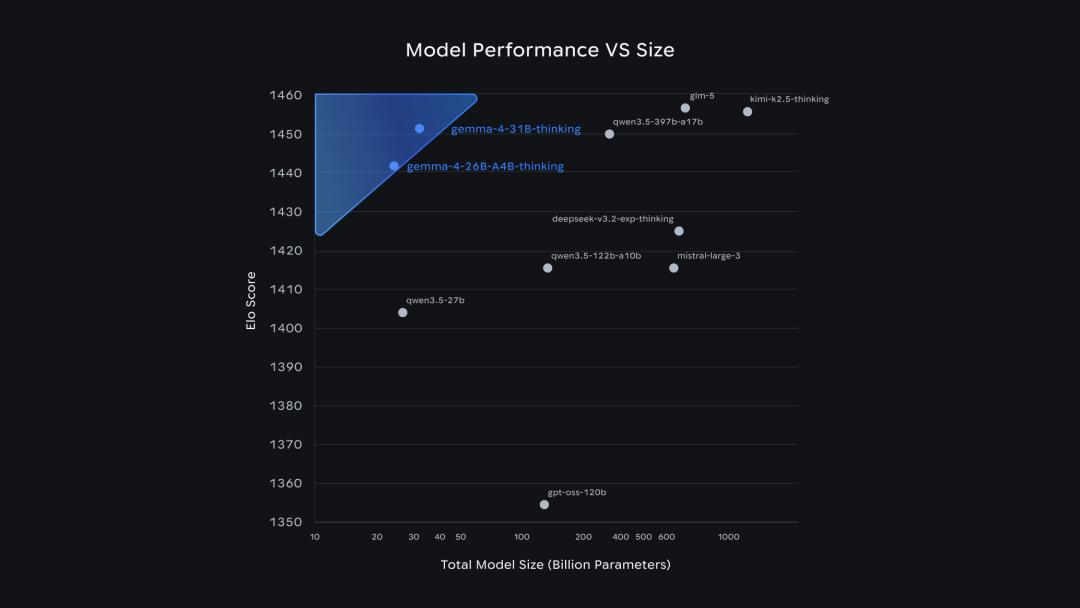
参数效率是另一个值得关注的维度。从「模型性能对比参数量」的散点图来看,Gemma 4 用 26B 和 31B 的体量,拿到了通常需要数百亿乃至千亿参数才能达到的 Elo 分数。
26B MoE 的 Arena AI 评分接近参数量约 15 倍的 Qwen3.5-397B-A17B,31B Dense 的评分则与体量在 600B 以上的 GLM-5 处于同一梯队。Google 将其概括为「单位参数智能密度前所未有」,至少数字显得有理有据。
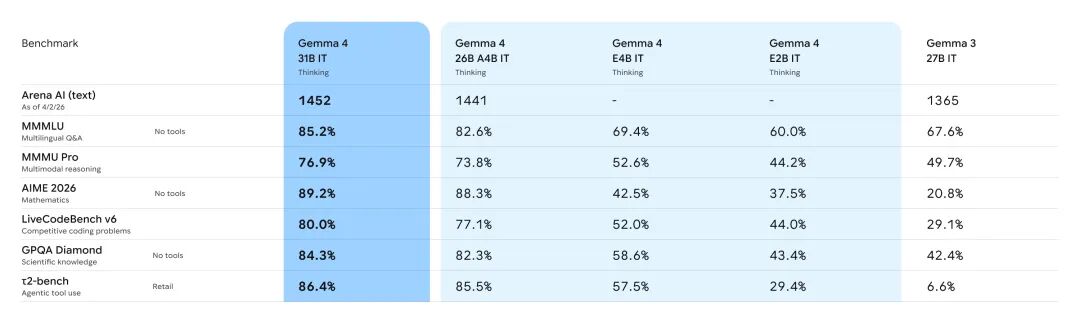
边缘端模型同样值得关注。E2B 在多语言问答基准 MMMLU 上达到 60.0%,在科学知识基准 GPQA Diamond 上达到 43.4%,要知道,这仅仅是一个只激活 2B 参数、可以跑在手机上的模型。
相比之下,Gemma 3 27B 在 GPQA Diamond 上的得分是 42.4%,两者几乎持平。换句话说,手机上的 2B 模型,已经追上了上一代 270 亿参数的桌面模型。
在硬件生态层面,NVIDIA 与 Google 已就 Gemma 4 在 RTX GPU、DGX Spark 个人 AI 超级计算机及 Jetson Orin Nano 上的推理优化展开合作。
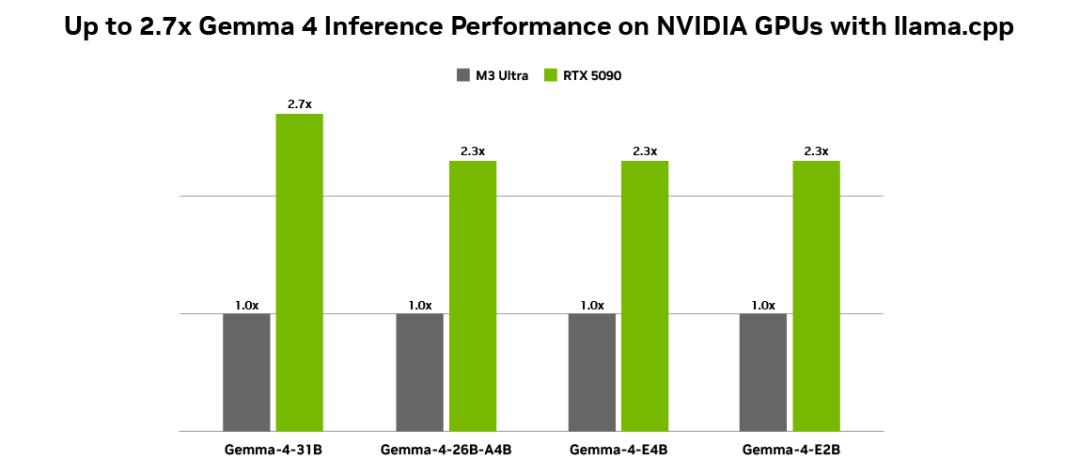
NVIDIA Tensor Core 和 CUDA 软件栈为 Gemma 4 提供了开箱即用的高吞吐、低延迟支持。本地 Agent 应用 OpenClaw 也已适配最新模型,可调用用户本地文件和应用上下文自动化执行任务。
从「开放」到「开源」,打开另一种可能性
理解这次发布,需要先搞清楚 Gemma 和 Gemini 的关系。两者基于同一套研究和技术体系构建,区别在于 Gemini 是订阅制的闭源产品,Gemma 则是可以免费下载、本地运行的开放模型。
Gemma 系列历代产品一直使用 Google 自有条款授权。开发者虽然可以下载和本地运行,但用途和再分发受到限制。
现在 Gemma 4 正式切换至 Apache 2.0 协议。在这套许可证下,开发者可以将模型用于任何目的,包括个人、商业和企业用途,无需支付版税,也无任何用途限制,修改和再分发同样自由。
Apache 2.0 还内置了专利保护机制:贡献者的专利自动授权给用户,若用户反过来以专利侵权起诉他人,则自动丧失使用授权。这套双向条款为企业级用户提供了额外的法律保障。
这次开源的实质意义在于,Gemma 4 现在可以合法打包进产品、服务和硬件设备中一并交付。对于医疗、金融等有数据主权或合规要求的行业用户,完全本地运行意味着数据不必上传云端,同时又能获得前沿的 AI 能力。
Hugging Face 联合创始人兼 CEO Clément Delangue 将此次授权切换称为「一个重要的里程碑」。自 2024 年 2 月首代发布至今,Gemma 系列总下载量已超 4 亿次,社区衍生变体超过 10 万个。
现在,模型权重已经上架 Hugging Face、Kaggle 和 Ollama,Transformers、TRL、vLLM、llama.cpp、MLX、Unsloth、SGLang、Keras 等主流框架均已于发布当天提供支持。
https://huggingface.co/google/gemma-4-31B-it
本地部署可通过 Ollama 或 llama.cpp 配合 GGUF 格式权重快速上手,Unsloth Studio 同步提供量化模型的微调和部署支持。如需云端扩展,Google Vertex AI、Cloud Run 和 GKE 同步可用。
以 Gemma 4 为代表的小模型有着更深远的意义,因为它重新回答了一个基础问题:AI 应该在哪里运行。
过去两年,这个问题的答案几乎是默认的:
数据中心。用户通过网络接口调用云端模型,数据必须上传,使用依赖连接,成本由服务商定价。这套模式在消费场景里运转尚可,但对数据主权有要求的行业,比如医疗、金融、工业,始终是一道难以逾越的门槛。
Gemma 4 提供了另一种可能。
手机、树莓派、没有外网的工厂终端,都可以在本地完成完整的模型推理。数据不离开设备,决策不经过云端。Apache 2.0 的授权则进一步打开了落地空间:模型可以合法打包进硬件产品,预装进行业设备,不再受限于调用协议和数据出境的合规约束。
能力层面的数字也印证了这条路的可行性。E2B 在科学知识基准 GPQA Diamond 上的得分,已经与上一代 270 亿参数的桌面模型基本持平,而它推理时只激活 20 亿参数,可以完全离线跑在手机上。
「更便宜」或「更方便」已经不足以描述这个变化,它更接近于一次覆盖范围的扩张,AI 能力开始有条件真正进入那些长期被排除在外的场景。
操作系统的普及经历过类似的过程:从专业机构的专用工具,逐渐嵌进每一台个人设备,直到人们不再意识到它的存在。AI 离那个阶段还很远,工程、交互、可靠性上的问题都还没有完整的答案,但可以跑在任意设备上,一定是这条路上最基础也是最重要的一步。


