
IT之家 4 月 2 日消息,科技媒体 Wccftech 昨日(4 月 1 日)发布博文,报道称在被誉为“AI 界最严苛大考”的 MLPerf v6.0 AI 推理基准测试中,英伟达再次交出满分答卷。
相比较此前的 v5.1 版本,本月(2026 年 4 月)发布的 MLPerf v6.0 引入了多种前沿的生成式 AI 模型,并重点升级推理交互性和大规模多节点系统。

IT之家援引英伟达新闻稿,MLPerf v6.0 为反映当前 AI 工业界的真实应用趋势,引入了多个模型,并重点考察了密集型大语言模型和视觉语言模型:
GPT-OSS-120B:新增的大型开源权重语言模型,专注于数学、科学推理和代码编写能力测试。
DeepSeek-R1 交互模式:在 v5.1 引入 DeepSeek-R1 后,v6.0 增加了交互式场景(Interactive scenario)。该场景对首字响应时间(TTFT)和每 Token 速率有更高要求,更贴近真实聊天机器人体验。
Qwen3-VL-235B:该套件中首个多模态视觉语言模型(VLM),用于测试将非结构化多模态数据转换为结构化元数据的能力。
WAN-2.2(Text-to-Video):套件中首个文生视频基准测试。考虑到生成视频的计算量极大,该测试弃用了传统的 Server 模式,改用 SingleStream 模式以更准确地衡量延迟。
DLRMv3:第三代推荐系统基准,由 Meta 贡献,从传统的 DCNv2 升级为基于 Transformer 的架构,提升了模型规模和计算强度。
YOLOv11 Large:针对边缘计算场景,将目标检测基准更新为 Ultralytics 的最新 YOLOv11 模型。
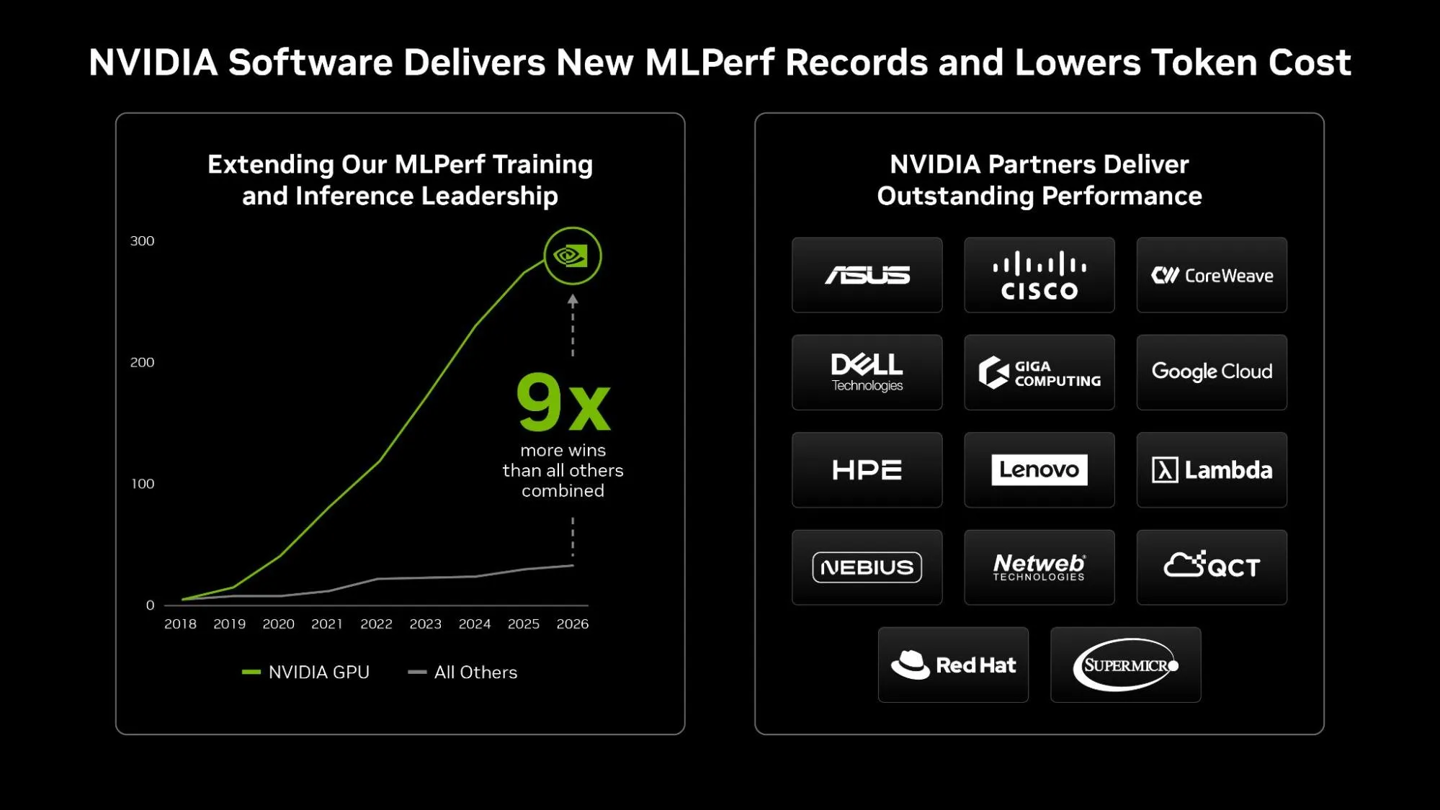
官方最新公布的 MLPerf 推理 v6.0 测试结果显示,英伟达凭借 Blackwell Ultra 架构(GB300 NVL72),实现了全方位的性能碾压,其 AI 推理成绩不仅位列第一,其推理训练 Wins 数量更领先最接近的竞争对手 9 倍。
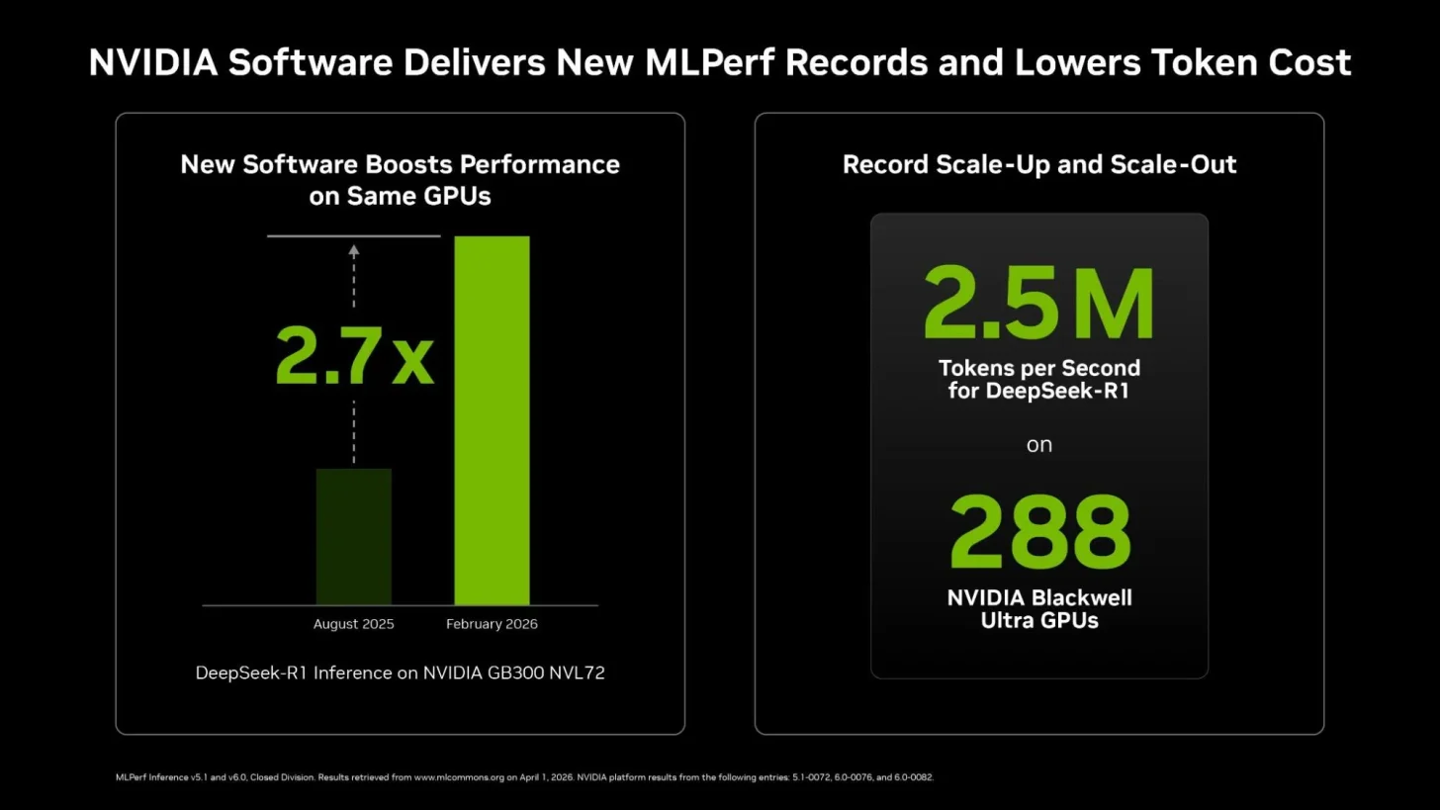
在备受瞩目的 DeepSeek-R1 服务器端测试中,英伟达交出了每秒每 GPU 处理 8064 个词元(token)的成绩。与之前的 v5.1 版本相比,处理速度大幅飙升 2.77 倍。
此外,在 Llama 3.1 405B 模型的服务器与离线测试中,英伟达也分别实现了 1.52 倍和 1.21 倍的性能提升。
| 跑分 | GB300 NVL72 v5.1 | GB300 NVL72v6.0 | 提速 |
| DeepSeek-R1(Server) | 2,907 tokens/sec/gpu | 8,064 tokens/sec/gpu | 2.77x |
| DeepSeek-R1(Offline) | 5,842 tokens/sec/gpu | 9,821 tokens/sec/gpu | 1.68x |
| Llama 3.1 405B(Server) | 170 tokens/sec/gpu | 259 tokens/sec/gpu | 1.52x |
| Llama 3.1 405B(Offline) | 224 tokens/sec/gpu | 271 tokens/sec/gpu | 1.21x |


