
Cursor套壳Kimi这事还没完……
最新消息,Cursor放出Composer 2技术报告,力证自己还是有在“自研”。(doge)
不是纯套,而是有技术地套、循序渐进地套。

用的方法,还是他们一开始就强调的预训练+强化学习。
不过这一次Cursor学乖了,老老实实署名Kimi K2.5。

滑跪速度之快,态度之诚恳……甚至和Kimi官方达成了和解。
但网友们似乎并不买账。

Cusor:我们这样基于Kimi 2.5
报告开篇第一件事,Cusor终于上道,先夸一波友商Kimi:
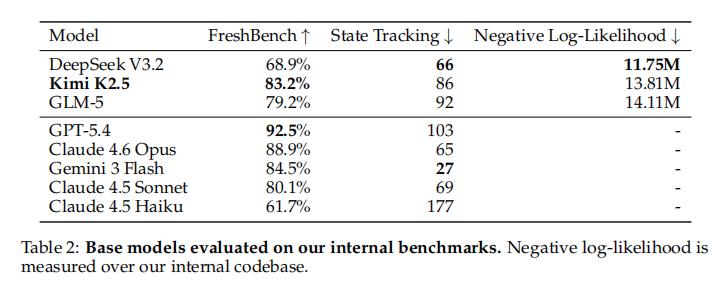
训练前,我们评估了多款潜在的开源基础模型,包括GLM5、Kimi K2.5和DeepSeek V3.2,但Kimi K2.5是最棒的!
选定Kimi K2.5的理由,不仅是因为其综合能力突出,也考虑到了其在自研基础设施中的执行效率等附加因素。
(咳咳)要说Cursor经此一事,总算是把中国开源模型的“体面”学到了十成十。
其次,基于Kimi 2.5,Composer 2还经过了两步独立的训练流程:持续预训练和异步强化学习。
1、持续预训练
其目的是为了提升模型在编码领域的基础知识和潜在编码能力,为后续智能体RL训练打下基础,主要分为三个子阶段:
先将大部分计算资源投入到32k token序列长度的训练中,再进行短期的长下文扩展训练,将序列长度提升至256k,最后通过小样本指令调优(SFT)完成特定代码任务的适配。
另外,为提升模型的线上推理速度,还新增了多token预测(MTP)层,结合投机解码技术和自蒸馏策略,保证模型收敛速度。
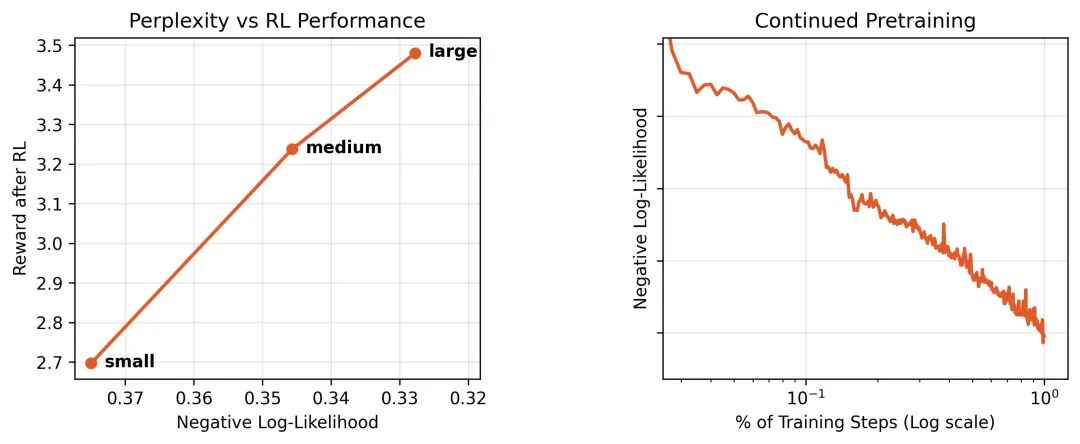
在训练过程中,模型在自研代码库上的损失值呈对数线性下降,且代码库困惑度与下游RL性能正相关,证明了预训练的有效性。
2、异步强化学习
训练环境高度模拟真实的Cursor对话场景,构建涵盖各类软件工程核心任务。
整体的强化学习训练框架基于大规模策略梯度实现,同时为保证训练的稳定性,采用单指令多样本的策略梯度算法,并设置固定的样本组大小。
同一指令仅参与一次训练,使用Adam优化器,在训练过程中更新模型全部参数。然后优化GRPO算法,移除长度标准化项,以避免长度偏差,再引入KL散度(k1=-log r)实现正则化。
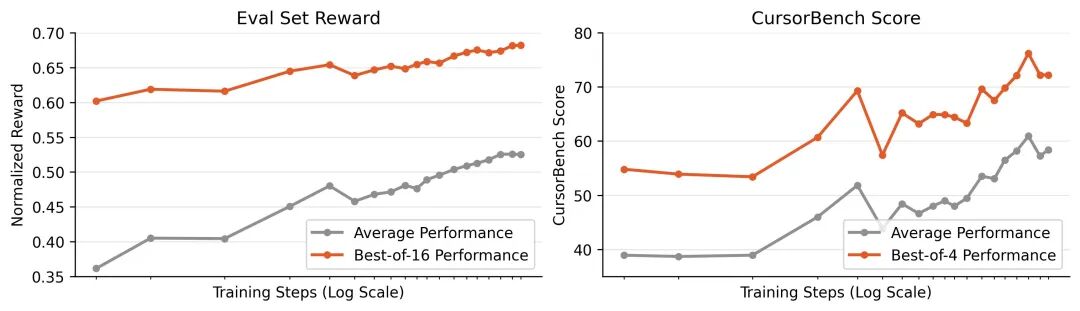
同时研究发现,最终模型的平均性能和best-of-K性能同步提升,证明RL不仅重新加权推理路径,还扩展了正确解的覆盖范围。
除此之外,Composer 2还添加了一系列辅助奖励机制,包括针对代码风格、交互表达的正向奖励,以及针对不当工具调用的产品级惩罚,并根据训练中涌现的行为动态调整奖励规则。
在基准测试上,Cursor也端出了一套自研的内部评估集——CursorBench。
CursorBench的任务均来自真实的Agent使用场景,且不再仅以功能正确性为唯一标准,还会依次考量模型的代码质量、执行效率、智能体交互等多维度。
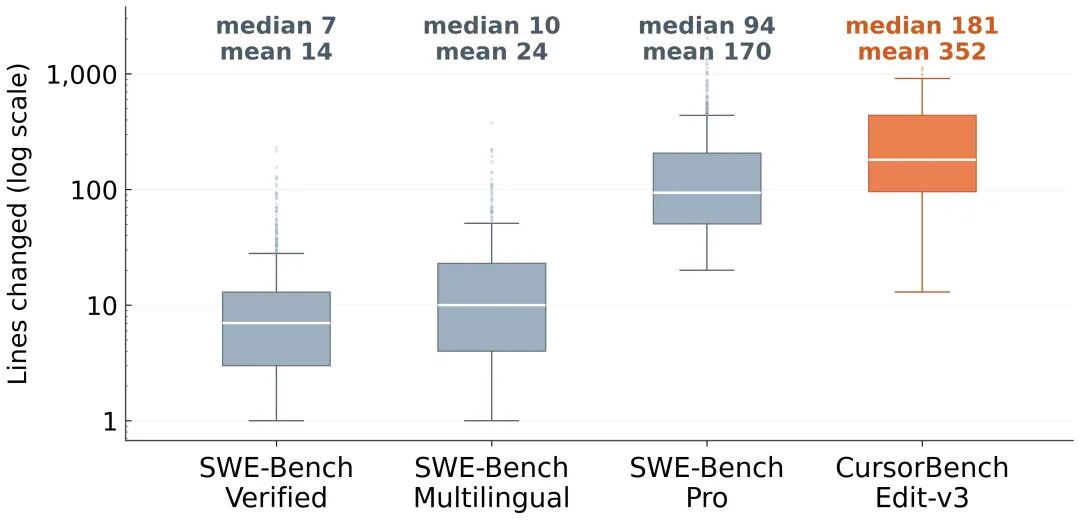
数据显示,CursorBench的代码修改量更大(中位数181行),而SWE-bench验证集和多语言版仅为7-10行;同时,CursorBench的指令提示更简洁,中位数仅390字符,远低于公开基准测试的1185-3055字符。
具体到测试结果上,Composer 2在CursorBench-3中的准确率可达61.3%,较1.5版本相对提升37%、较1版相对提升61%。
和Kimi K2.5相比,准确率也实现了大幅度提升。
综合来看,Composer 2在成本层面实现了帕累托最优,推理成本与更小的模型相当,而精度又同时媲美大尺寸前沿模型。Token使用效率也与其它SOTA模型持平,无额外资源消耗。
u1s1,这怎么不算Kimi K2.5 pro版呢?只不过出品方变成了大洋彼岸的Cursor。
基础模型开源+技术报告开源,Cursor这波也可以说是另一种意义上的“开源”了。(doge)
也欢迎全世界套壳支持咱中国开源模型,但记得署名就好~
杨植麟对大模型的再思考
就在Cursor发报告为自己找补的同时,另一边Kimi早已“朝前看”——
杨植麟在刚刚中关村论坛的演讲中,详细分享了自己和Kimi团队在开源模型及模型训练领域的最新思考。
首先,他认为大模型的本质是将能源转化为智能,其中最重要的事情是要规模化。
换言之,就是要尽可能将更多的能源,通过算力和模型载体,转变成更多更高程度的智能。
而大模型规模化,也就是大家常说的Scaling Law,不等同于无脑堆算力,而是要讲方法、讲效率。
Kimi的Scaling策略在于三点:
1、提升Token效率。
真正厉害的模型,比的不是谁算力更猛、数据堆得更多,而是谁能用同样有限的数据,学到更多的智能。
2、扩展上下文长度。
模型能够处理更长的上下文,意味着它能够更复杂、更长程的逻辑,从而完成更复杂的任务。
为此Kimi专门设计了新的网络架构Kimi Linear和训练数据,从根本上提升长上下文能力,而不是简单粗暴地拉长窗口。
3、引入Agent集群。
这也是在Kimi K2.5中全新提出的一种思路,不再死磕将一个模型做到极致,而是通过引入一群Agent协作来解决更为复杂的问题。
然后通过Agent集群能力,去实现规模化输入、输出、执行或编排。

同时,Kimi也认为好的底层网络架构也相当重要。
比如,他们最新开源的模型架构注意力残差(Attention Residuals),可以认为是将注意力应用在网络深度上的LSTM变种,让模型能够更高效地利用所有层信息。
但其实Attention架构、残差学习这些都是多年前的经典技术,现在算力更强、研究更偏向工程化+大规模验证,就不能只靠理论想法,过去的标准答案也可以被重新挑战和改进。
至于开源这事儿,要做,还要继续大力地去做。
开源模型正在逐渐成为新的标准。而以Kimi K2.5为代表的开源模型,已经成为全世界所有芯片厂商测试硬件性能的基准。
现在全世界很多研究机构也都在用Kimi K2.5进行研究。我们希望通过开源,让所有人都能以非常低的门槛获取智能。
最终,大家能够去形成一个开源生态系统,共同推动AI领域的发展。
要不还得说真·开源得看国产模型~
最后,杨植麟还断言:
大模型训练已经进入第三阶段!
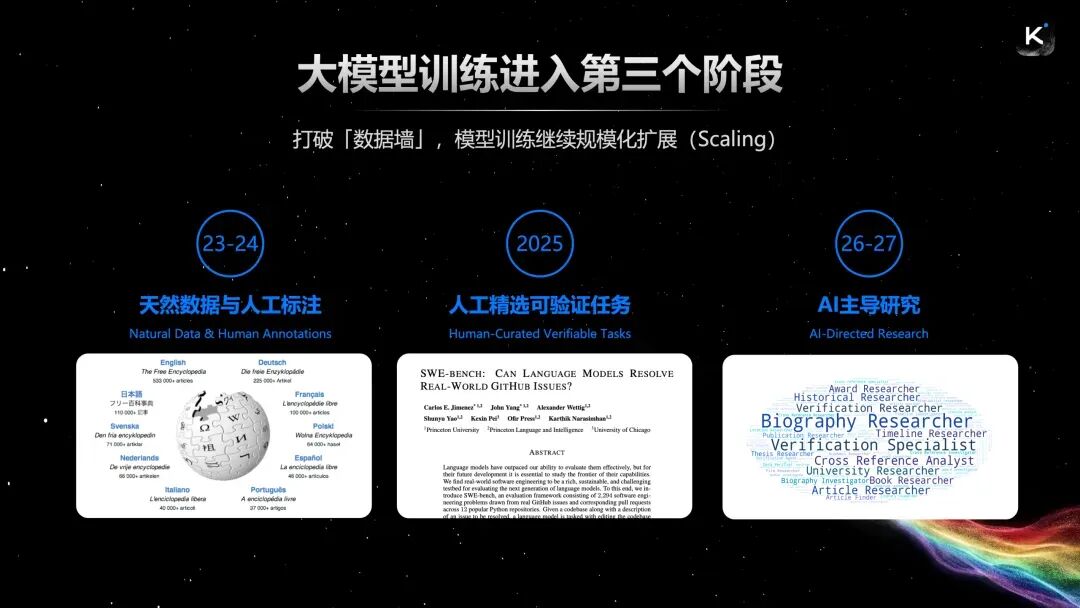
如果说2023和2024年,大模型训练还是以天然数据为主,少量人工标注为辅。那么到了2025年,业内则更加重视人工筛选高质量任务,以及搭建大规模的强化学习系统。
而从2026年开始,整个AI研发流程将发生重大变化:研发主体将从人转向AI,AI自动合成任务、构建训练环境甚至探索新的模型架构,而研究员更多的是提供算力和Token资源。
简单来说,就是从数据靠人采→任务靠人选→训练全靠AI自己搞,AI将从被训练者,逐渐变成研发参与者乃至主导者。
未来AI领域的研发速度,将会以远超我们想象的节奏持续加速。
参考链接:
[1]https://x.com/cursor_ai/status/2036566134468542651
[2]https://cursor.com/resources/Composer2.pdf
[3]https://mp.weixin.qq.com/s/GjN_dx380VnUmRWHGRajiA


