
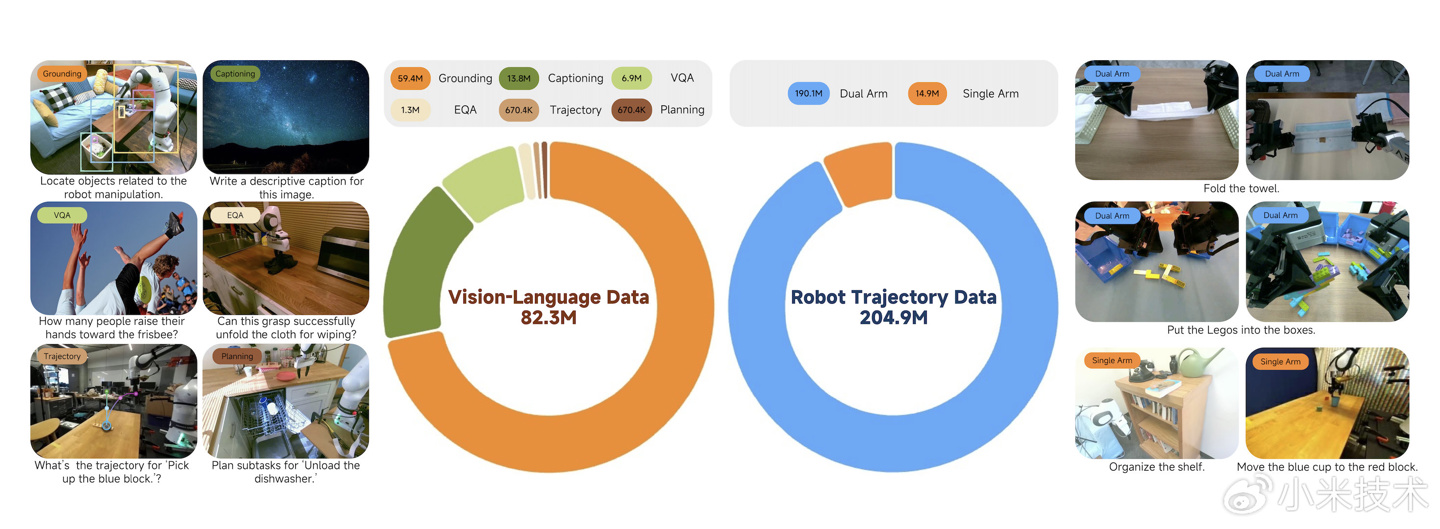
IT之家 2 月 12 日消息,小米今日对外发布开源 VLA 模型 Xiaomi-Robotics-0,拥有 47 亿参数、兼具视觉语言理解与高性能实时执行能力,刷新多项 SOTA。它不仅在三大主流的仿真测试中获得优异成绩,更在现实真机任务中实现了物理智能的泛化 —— 动作连贯、反应灵敏,且能在消费级显卡上实现实时推理。

IT之家从官方介绍获悉,物理智能的核心在于“感知-决策-执行”的闭环质量。为了兼顾通用理解与精细控制,Xiaomi-Robotics-0 采用了主流的 Mixture-of-Transformers (MoT) 架构。
视觉语言大脑(VLM): 团队采用了多模态 VLM 大模型作为底座。它负责理解人类的模糊指令(如“请把毛巾叠好”),并从高清视觉输入中捕捉空间关系。
动作执行小脑(Action Expert):为了生成高频、平滑的动作,团队嵌入了多层的 Diffusion Transformer (DiT)。它不直接输出单一动作,而是生成一个“动作块”(Action Chunk),并通过流匹配(Flow-matching)技术确保动作的精准度。
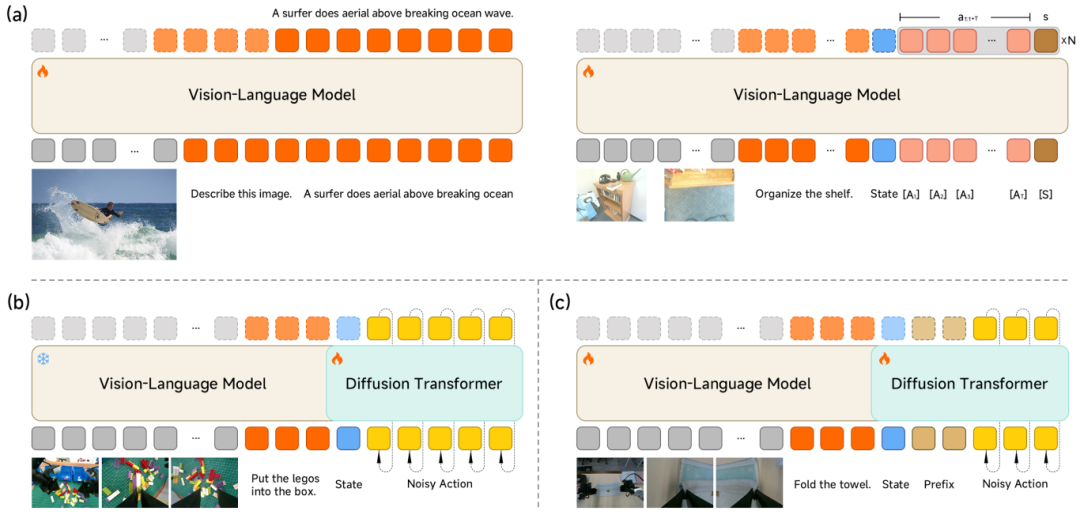
大部分 VLA 模型在学动作时往往会“变笨”,失去本身的理解能力。我们通过多模态与动作数据的混合训练,让模型在学会操作的同时,依然保持强大的物体检测、视觉问答和逻辑推理能力。
VLM 协同训练:首先引入了 Action Proposal 机制,强迫 VLM 模型在理解图像的同时预测多种动作分布。这一步是为了让 VLM 的特征空间与动作空间对齐,不再仅仅是“纸上谈兵”。
DiT 专项训练:随后冻结 VLM,专注于训练 DiT,学习如何从噪声中恢复出精准的动作序列。这一阶段,我们去除了 VLM 的离散 Token,完全依赖 KV 特征进行条件生成。通过 DiT 专项训练,模型可以生成高度平滑、精准的的动作序列。
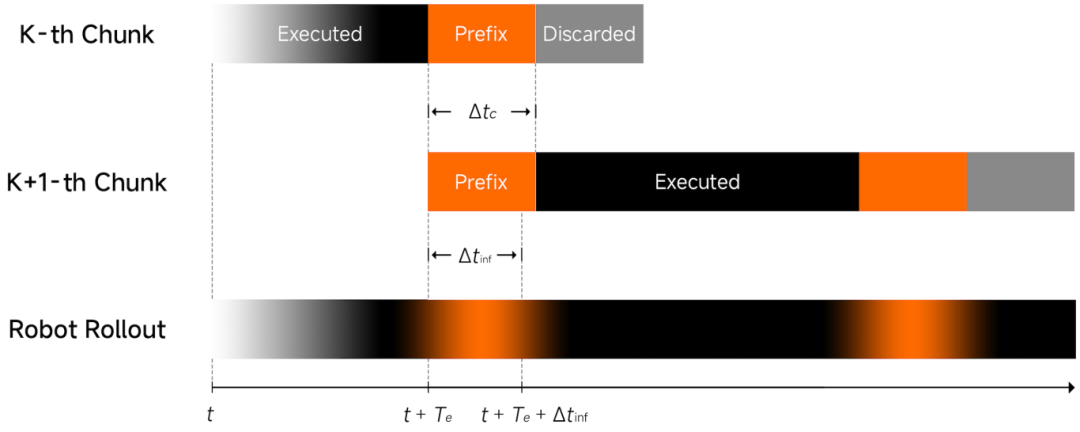
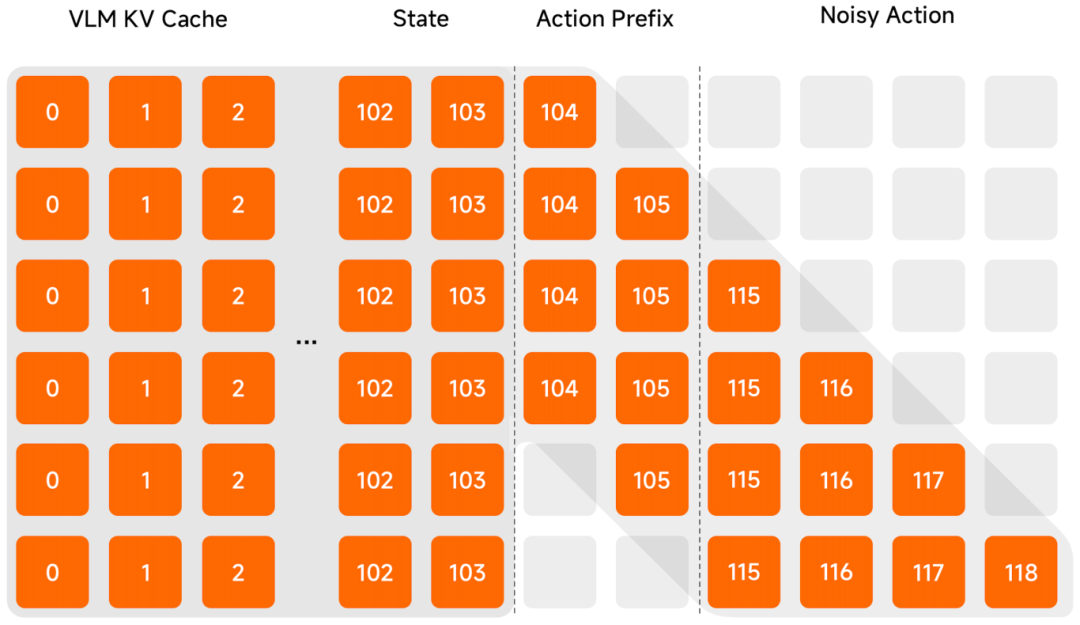
针对推理延迟引发的真机“动作断层”问题,团队采用异步推理模式 —— 让模型推理与机器人运行脱离同步约束、异步执行,从机制上保障动作连贯流畅。为进一步强化模型对环境变化的响应敏捷性与运行稳定性,我们引入了:
Clean Action Prefix:将前一时刻预测的动作作为输入,确保动作轨迹在时间维度上是连续的、不抖动的,进一步增加流畅性。
Λ-shape Attention Mask:通过特殊的注意力掩码,强制模型更关注当前的视觉反馈,而不是沉溺于历史惯性。这让机器人在面对环境突发变化时,能够展现出极强的反应性物理智能。
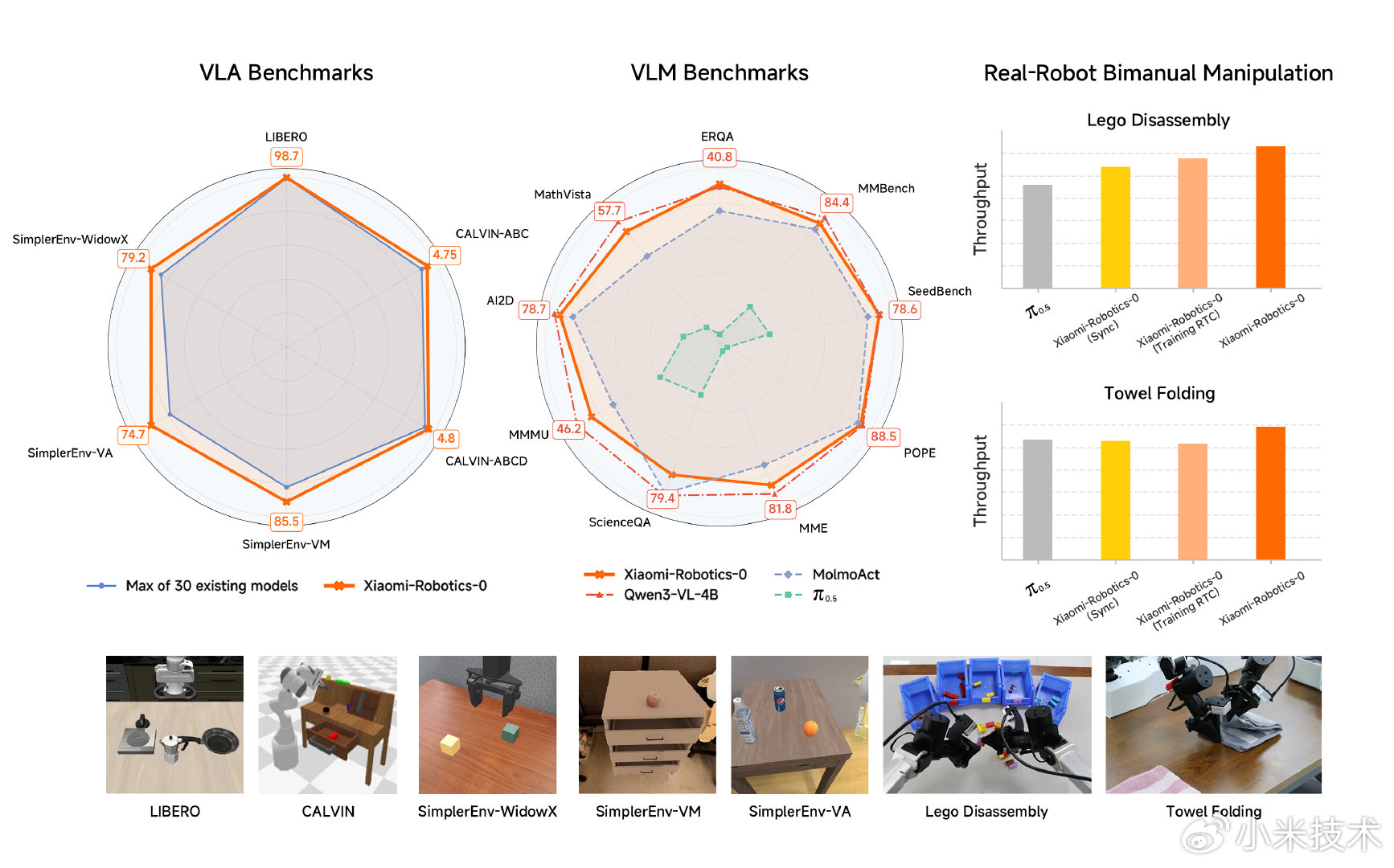
在多维度的测试中,Xiaomi-Robotics-0 展现出优异的表现:
仿真标杆: 在 LIBERO、CALVIN 和 SimplerEnv 测试中,模型在所有的 Benchmark、30 种模型对比中,均取得了当前最优的结果。
真实挑战: 团队在双臂机器人平台上部署了模型并与行业标杆进行了横向对比。在积木拆解和叠毛巾这种长周期、高度挑战的任务中,机器人展现出了极高的手眼协调性。无论是刚性的积木还是柔性的织物,都能处理得游刃有余。
多模态能力:模型保留了 VLM 本身的多模态理解能力,尤其是在具身更相关的 benchmark 中表现优异,这是之前的 VLA 模型所不具备的。
小米宣布将模型进行开源:
技术主页:https://xiaomi-robotics-0.github.io
开源代码:https://github.com/XiaomiRobotics/Xiaomi-Robotics-0
模型权重:https://huggingface.co/XiaomiRobotics
相关新闻
关键词:小米- 雷军回应小米手机是否涨价:会想各种方法,尽量降低消费者接受的难度
- 玄戒O2稳了!采用台积电3nm工艺 小米最强Soc蓄势待发
- 荣耀机器人“太空步”秀巴展,小米机器人上岗汽车工厂,小鹏升级自动驾驶,比亚迪颠覆技术,谁会走得更远?
- 消息称某厂子系天玑 9500 性能旗舰暂定 4 月见,预计为小米 REDMI K90 至尊版
- 卢伟冰称已做好内存涨价准备:小米面对涨价有优势
- 卢伟冰谈存储涨价:史无前例,预计涨到 2027 年底,目前小米没有面临缺货现象
- 小米 Vision Gran Turismo 双门超跑设计细节首曝:由风塑型,是风阻与下压力的平衡
- 小米 AI 超轻薄旗舰笔记本曝光:Ultra 5 325/Ultra X7 358H 处理器,重量 1kg±


