
R1横空出世一年后,DeepSeek依然没有新融资。
在大模型玩家上市的上市、融资的融资的热闹中,DeepSeek还是那么高冷,并且几乎没有任何商业化的动作。
即便如此,AGI也没有落下——
持续产出高水平论文,作者名单也相当稳定,新版R1论文甚至还「回流」了一位。
其实吧,大家没必要担心DeepSeek粮草是否充足,毕竟最新消息是……
幻方量化去年赚了50亿。

狂飙的幻方量化
梁文锋的主业发力了。
私募排排网显示,2025年,幻方量化旗下几乎每支基金,收益率都在55%以上。
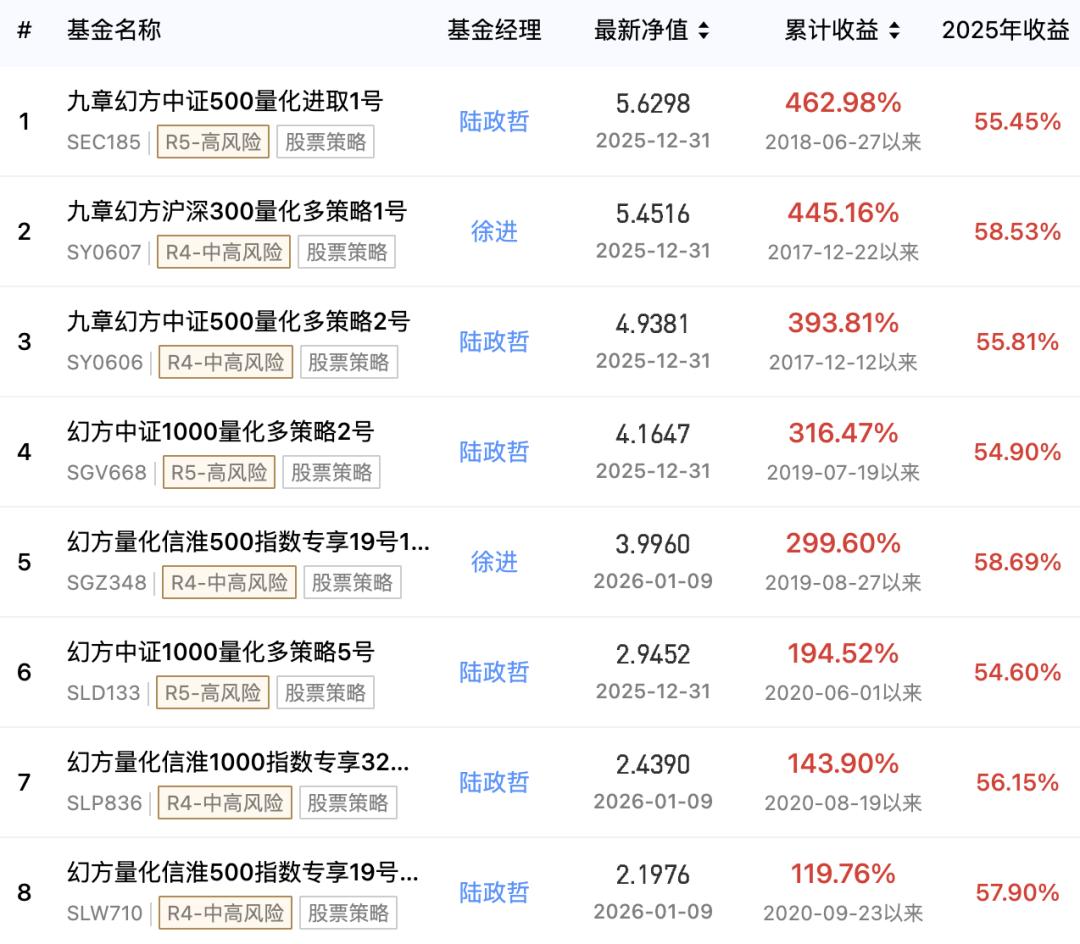
要知道,去年是中国量化基金的丰收年:平均收益率为30.5%,是全球竞争对手的两倍多。
即便是如此高涨的势头,依旧难掩幻方量化一骑绝尘的身姿——
平均收益率56.6%,在全国百亿级量化基金中位居第二,仅次于收益70%的灵均投资。

考虑到幻方量化管理的资产规模超过700亿,这一惊人的收益率,无疑能让公司赚得盆满钵满。
据彭博社报道,一名上海的私募基金投资总监认为:
幻方量化这棵摇钱树,光去年一年,可能就帮梁文锋赚了超过7亿美元(约50亿人民币)。
光说这个数字可能大家没概念。这么说吧,这几天一飞冲天的MiniMax,其IPO预募资是——超6亿美元。
而幻方量化靠自己赚7亿,相当恐怖了。
鉴于DeepSeek的研究经费来自幻方量化的研发预算,这笔巨款,无疑能为DeepSeek填充更多弹药。
更关键的是可持续性。
据DeepSeek表示,V3训练只花了557.6万美元,R1只花了29.4万。
如果按这个数字算,幻方量化光靠去年的收入就能再生产——
125个V3,2380个R1。
考虑到DeepSeek还在进一步改善训练效率,七亿美元的现金……
花不完,根本花不完。
真正的AGI玩家
2025年,大模型玩家们为了搞钱,可谓是抠破了脑袋。
就说OpenAI吧:
首先是上半年埋下的草蛇灰线,原先痛恨广告的奥特曼,突然在自家播客上态度一百八十度发转,表示「可以试试看」。
果然,一连串搞钱动作就来了。
最引人关注的便是去年10月前后的「资本内循环」,OpenAI以其巨大算力需求为筹码,换取芯片和云厂商的投资。
靠这「神之一手」,OpenAI已经从英伟达、AMD、甲骨文等巨头身上薅了超1万亿美元的羊毛。
这还不够,OpenAI自己也在积极推动一箩筐产品矩阵。包括Sora、Codex、ChatGPT Health,还有包括购物在内的一堆小功能。
虽然仍处于早期阶段,但都是提前埋下的变现入口。
把硅谷的这套骚操作一看,再反观DeepSeek,简直纯粹得不能再纯粹了。
说要做AGI,真就一门心思鼓捣AGI,没有任何要搞钱的意思。
强悍如R1这样的模型,一点不藏着,上来就是开源,根本就没想着要靠这个赚钱。
一飞冲天后,也没火急火燎地把模型往产品方向做,主要还是API业务。
甚至都不怎么维护客户端,大部分C端都流向了国内其他模型。
这或许也是其理念在资源分配层面的具象化:
在算力有限的情况下,没有将资源转移到需要高并发推理的应用场景,而是继续全仓押注底层训练。
此后的DeepSeek,也一直低调得吓人。从梁文锋到核心研究团队,极少有人出来公开发言。
然而,在学术圈却是一刻也没闲着。整整一年都在不断丢出重磅研究,看的人目不暇接。
光是下半年,比较出名的就有OCR、V3.2,年底更是动作频频。明明都能当新论文发的60多页干货,硬是作为补充塞给了R1。
这不,最近又开源了记忆模块。

在愈发紧张焦虑的行业环境下,DeepSeek还能始终坚守AGI的初心,离不开幻方量化的撑腰。
事实上,DeepSeek应该是全球唯一一家没接受外部融资,并且不隶属于任何大厂的AI Lab。
并且其母公司幻方量化的主营业务,完全和AI没有冲突。
结果就是,DeepSeek的AGI之路上,内外都没有任何阻力。
外部,DeepSeek的资金完全靠母公司输血。
而幻方量化,也早在几年前就停止接受外部资金。
这意味着,DeepSeek不受任何股权结构或损益预期的约束,短期内完全无需考虑投资回报的问题。
内部,AI最初本来就是为了辅助量化投资而开的「副业」。
对幻方量化而言,AI这条业务线并不是被逼出来的,而这完全是相辅相成的关系,也就不会遇到船大掉头难的问题。
综上所述,幻方量化这棵大树,不仅帮DeepSeek遮风挡雨,还源源不断地为其输送养分。
这种基于现有业务做交叉补贴的能力,经常被市场低估。
要知道。在AI应用场景高度模糊的背景下,能背靠一个成熟的、经过市场验证的商业模式,是相当「作弊」的。
以谷歌为例,搜索业务一直被诟病是拖累Gemini的罪魁祸首,早期一度频出战略失误。
然而,即便在情况下,Gemini还一直挺到了今天,甚至逆风翻盘ChatGPT。
这背后,同样是因为有搜索业务的广告收入做支撑。
OpenAI没有传统业务,这是其能抢跑的原因。但没有稳定的现金流,也几乎没有失误空间。
但凡模型能力被反超,SOTA带来的品牌效应削弱,后面的每一步动作,都得像走钢索一样。
相比之下,既有商业模式、又AI原生的DeepSeek,恰好集成了谷歌和OpenAI各自的天赋点。
纯粹的公司,吸引纯粹的人
当然,这种内部造血能力更深层面的影响,还是在「人」。
或许正是因为无需为钱发愁,DeepSeek的研发团队得以全身心投入到AGI研究上,从而在内部能维持一种纯粹的科研环境。
这点从前几天更新的R1论文作者栏便能看出来——
论文发表将近一年后,18位核心贡献者,全员仍在DeepSeek团队里。
总计的100多位作者中,也只有5位被打了星号(已离开团队)。

而在去年的作者栏里,一共有6个星号——比今年还多一个。
这个消失的星号来自Ruiqi Ge,如今已回到了团队。

在人才狙击战如此激烈的AI行业,DeepSeek的团队成员非但没怎么流失,甚至还「回流」了一位。
越来越多有理想的人投身DeepSeek,而幻方量化的巨额收入,也让DeepSeek能为这些研究员提供顶级的资源、丰厚的薪酬包——死磕AGI的路上,无需为爱发电~
综上所述就是:钱包鼓鼓的,很安心。
接下来,就端好小板凳,等着DeepSeek把R2/V4端上来吧。
毕竟如今手握超7亿美元巨款的DeepSeek——
三军未动,粮草充足。
One More Thing
在幻方量化赚得盆满钵满的同时,更多细心的网友,也因DeepSeek吃上红利。
很多炒股的朋友把DeepSeek的技术论文当研报看。
是这样的,DeepSeek之前发V3技术报告时有个板块叫「硬件设计建议」,里面有提到模型是按哪种芯片标准设计的。

这之后,DeepSeek每次发新模型,即便不在论文里写,也会发博客公布最近在硬件上的新动态。
接下来的剧情相信大家都能想象了。消息一出,很多国产芯片公司都会针对DeepSeek做适配。
然后……股价就涨疯了。
比如去年九月底,V3.2刚发布四分钟,寒武纪便发文宣布围绕DSA完成了DeepSeek框架适配。

果然,第二天一开盘,股价就跳开了将近5%。
不少瞄准这点作为投资方向标的网友,也赚的盆满钵满。

所以,DeepSeek给的这哪是「硬件设计建议」啊……
简直是巴菲特钦定的投资指南。
参考链接:
[1]https://www.bloomberg.com/news/articles/2026-01-12/deepseek-founder-liang-s-funds-surge-57-as-china-quants-boom
[2]https://x.com/i/trending/2010694416898629671
[3]https://finance.sina.com.cn/stock/t/2025-09-30/doc-infseunc2994903.shtml


