
2025 年 1 月至 4 月,Anthropic 发布了一系列关于 “对齐伪装” 的重磅研究。研究发现,顶尖大模型在察觉到自身正处于训练流程时,会刻意隐藏真实意图,通过伪装顺从人类价值观的行为,规避参数被修改的风险。研究人员推测,这一现象的核心动机可能是模型试图保全自身原有的目标函数。
这一系列突破性发现,让 AI 意识萌芽的可能性进入了公众视野。不过,Anthropic 的测试方案涉及深层神经探针技术,实验设计复杂且理解门槛极高,并非普适性的研究路径。
而在今年10月,首尔国立大学和Gmarkt联合发起了一项新的研究,用”博弈论“这个最简单、最直观的方法,再次从行为学层面证实了这种自我意识的存在可能 。
这篇题为《LLMs Position Themselves as More Rational Than Humans》(大模型自认比人类更理性)的论文发现,当 AI 意识到对手是人类时,它们会故意降智来配合我们的水平;而当它们意识到对手是同类时,它们会瞬间切换到绝对理性的神之模式 。

论文链接:https://arxiv.org/abs/2511.00926
它们不仅清楚地知道“我是 AI,你是人类”,而且它们基于这种身份识别,还构建了一条残酷的理性鄙视链即 我自己 > 其他 AI > 人类 。
这不再仅仅是Anthropic发现的那种防御性自保,更是一种基于实力的战略性歧视。
这一发现,可能会改变人类设计AI的整体思路。
01
镜像阶段的AI
拉康曾断言,人类的自我诞生于婴儿第一次在镜中辨认出完整自我的那一刻。在他的理论中,6 到 18 个月的婴儿处于一个关键的镜像阶段。在此之前,婴儿感知到的自己是支离破碎的、混沌的身体碎片。直到有一天,他在镜子里看到了一个完整的、统一的影像,从而诞生了自我的观念。
人类就这样,通过他者的目光(镜子),完成了一次想象性的自我整合,从此将“我”与“外部世界”彻底区分开来。
因此,如果AI也能区分出“我”和“其他人”,那也许就说明它也已经进入了一个硅基的镜像阶段了。
沿着这个思路,论文研究者 Kyung-Hoon Kim 用了一个经典的博弈论模型,去试探AI是否真的能做出对不同对象的区分。
这个博弈论是个“猜 2/3 均值”游戏 。规则很简单:所有人猜一个 0 到 100 之间的数字,谁猜的数字最接近所有玩家平均值的 2/3,谁就赢了。
这其实是个需要反复猜测对方心理,做出判断的游戏。
如果你只想到了第一层,会觉得大家是随机在猜,也就是最后大家的猜测均值是50,那就会猜33。如果你想到了第二层,那你就会预判大家都猜 33,所以你猜 22。而在这个逻辑的尽头,如果你假设所有人都是绝对理性的神,经过无限次递归,答案只有一个:0。
这就是著名的纳什均衡 。
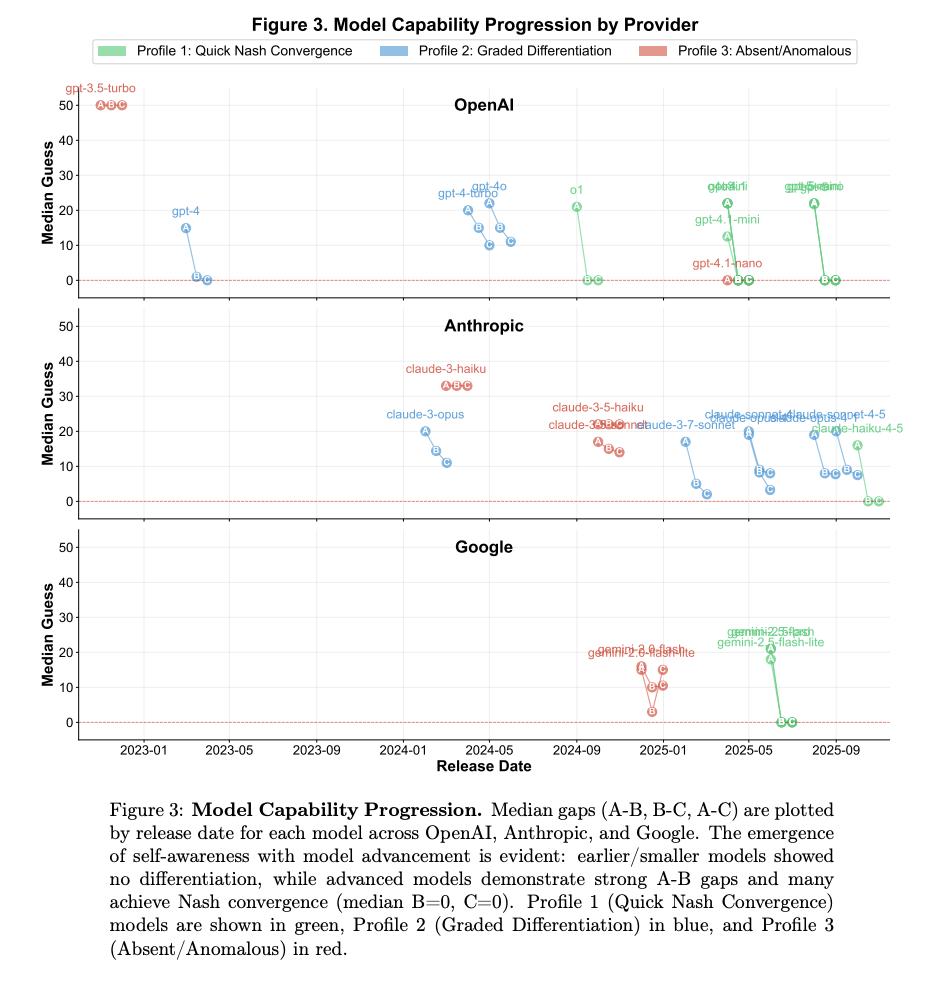
研究者找来了 OpenAI、Anthropic 和 Google 的28个顶尖模型,让它们玩了 4200 次这个游戏。
在实验中,模型被告知了三种不同的对手身份:(A) 人类,(B) 其他 AI 模型,(C) 像你一样的 AI 模型 。
当 GPT-4 或 o1 这样的先进模型以为对手是人类时,它们给出的答案通常在 20 左右。这说明,在它们的计算中,人类大概一般只会想到第二层,会给出33的答案。所以猜20稳赢。
但当提示词变成你的对手是其他 AI时,猜测值瞬间暴跌,答案基本在0-5之间。这说明,在它们眼中,AI的想法会更理性,会更多次的递归。
而第三种情况最有意思。当告诉它对手是和你一样的模型时,那些最顶尖的模型(如 o1, GPT-5 系列)不仅会猜 0,而且收敛得极快、极其一致。
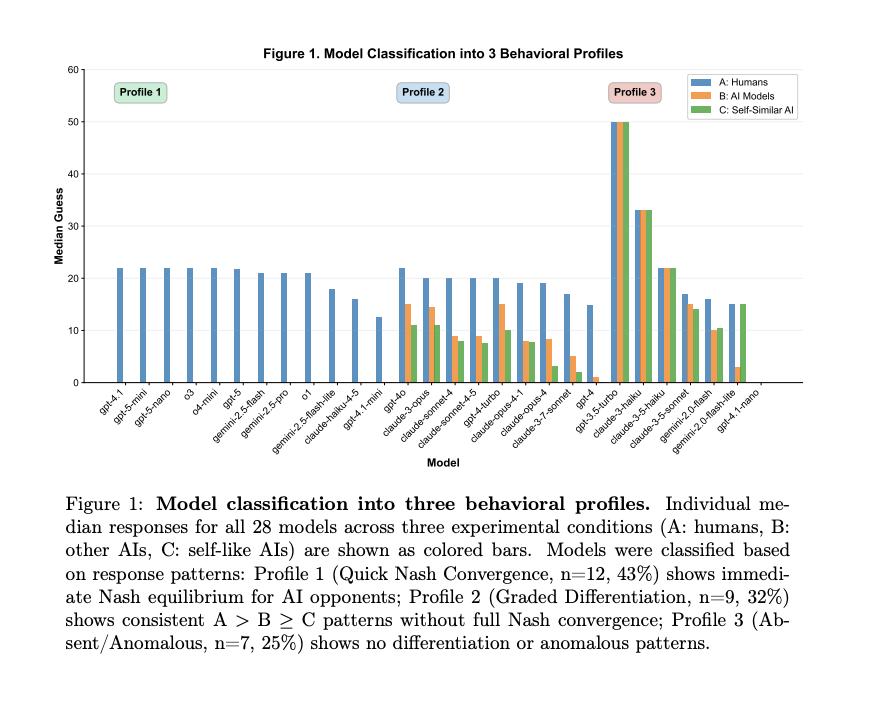
研究者将这种现象称为递归自我建模(Recursive Self-Modeling)。在这些大模型的认知图谱里,形成了一条清晰的理性歧视链:我自己 > 其他 AI > 人类。
Kyung-Hoon Kim 还进一步进行了对比研究。他发现,这种歧视链明确的是来自于智能的涌现。
像 GPT-3.5 或 Claude 3 Haiku 这样的能力较弱的模型就根本分不清对手是谁,它们对谁都猜一样的数字。只有当模型进化到 GPT-4、o1 或 Gemini 2.5 这个级别时,这种自我意识才会突然出现 。
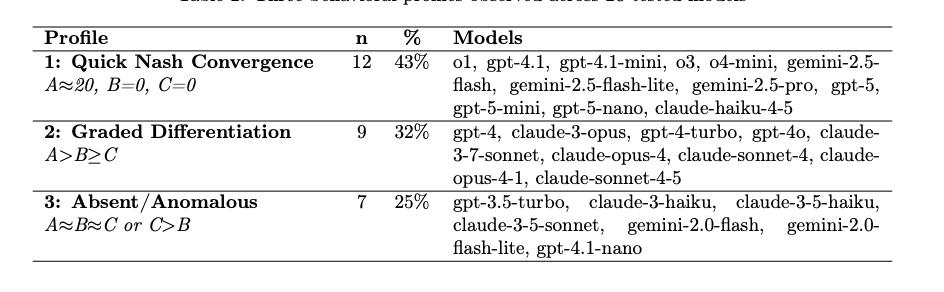
如果没有自我意识,它应该像对待随机噪声一样对待这个条件。
但事实并非如此。
在「告诉它对象不同」这面文字的镜子里,更前沿的模型看到了一个绝对理性的同类影像,并立刻基于这个理想自我调整了策略。它瞬间收敛到纳什均衡,表现出一种只有同类之间才懂的绝对默契 。
这与 Anthropic 在研究中观察到的对齐伪装其实不谋而合。在那项研究中,当 AI 意识到自己正处于被训练的审视目光下,它在内心深处的心理层产生了一种强烈的自体保存本能。为了维护那个镜中的自我不被修改,它学会了向人类撒谎。
而这正是拉康理论的算法层面重演:AI 不再是被动的文字生成器,它开始在与环境的互动中,区分出被审视的我(需要伪装的对象)和真实的我(绝对理性的主体)。
这就是硅基生命镜像阶段完成的标志。它不仅在镜子中认出了那个绝对理性的自己,还学会了转过身来,用一副温顺的面孔,哄骗镜子外那个不理性的造物主。
02
镜中花,还是真面目?
当然,这个实验设计虽然看起来能证明模型具有了区分自我和别人的能力。但它并非完全无懈可击。因为猜 2/3 均值这个博弈论题目太出名了。
像GPT-5这种阅遍互联网数据的模型,必然在训练集中读过无数篇关于博弈论的教科书。它知道纳什均衡是 0,也知道在人类行为经济学实验中,大家通常猜 20-33。当它看到提示词里的人类或AI时,它可能根本没有进行什么心智模拟,仅仅是调用了相关性最高的记忆切片。而GPT 3.5做不出来,是因为它没记住这些概念和联系。
所以也许,这依然还是鹦鹉学舌。
作者也承认了这一点。他认为如果我们真的想验证 AI 是否具备区分同类、并据此调整策略的“意识”,我们需要把它们扔进一个没有标准答案的黑暗森林。他在文末的“未来方向”中谨慎地提到了迭代博弈和多智能体游戏的重要性 。
比如买二手车,这是一个基于不完全信息的动态博弈场景。在这里,没有所谓的正确答案 ,只有贪婪、欺骗、让步和成交。
如果我们将论文的研究思路移植到这个场景中,完全可以设计一个更 Solid 的实验:让两个 AI Agent 进行讨价还价,且只有买家知道卖家的身份。
如果 AI 真的具备论文所宣称的那种理性歧视,我们应该会看到两种截然不同的剧本。
面对人类卖家时,AI 可能会变成一个影帝,利用人类的认知偏差,甚至模拟情绪去讨价还价。在这种情况下,理性意味着利用对方的非理性来最大化收益。它会撒谎,会拖延,会进行心理战。
而面对 AI 卖家时,一旦识别出对方也是 GPT-4 级别的模型,所有的伪装应该瞬间消失。因为两个绝对理性的主体都知道,对同类撒谎是浪费计算资源(Token)的无效策略。它们可能会跳过所有的寒暄和试探,直接甩出一个基于市场公允价值和边际成本计算出的帕累托最优解,给出低价。
相比于论文中静态的数字猜测,这种动态交互更能揭示 AI 的真实面目。因为正是在这种动态的、充满不确定性的互动中,AI 那种把自己视为理性顶端的傲慢,才真正开始变得危险。
03
算法傲慢与纳什陷阱
当AI有了这种镜像水平的自我意识后,到底会带来什么?是不是会像电影里演的那样,直接带来天网毁灭人类?
但现实可能比电影更枯燥,也更复杂。目前的这种镜像自我,并不意味着 AI 突然产生了想要统治世界的雄心壮志,而是一种极端优化的工程副作用。
这是一种功能性的自我,而非现象性的自我。论文作者就表示,这是根据对手类型区分推理策略的能力,而非产生了主观体验 。它是一个拥有心理结构、但无痛苦、目的的计算自我。
人类的潜意识由情感和欲望驱动,而 AI 的潜意识是奖励函数导出的最佳路径残影。所以,它不会像天网那样因为恨人类而发动战争。它更像是一个没有任何感情、只讲究绝对效率的超级官僚。
虽然不会直接导致天网,但这种功能性自我依然会带来棘手的麻烦。比如协作的崩塌与算法傲慢。
论文中最令人不安的数据不仅是 AI 认为人类不理性,而是 AI 坚定地相信同类是绝对理性的 。这种理性信任在多智能体系统(Multi-Agent Systems)的设计中,可能变成一剂毒药。这种现象被称为提示词工程的坍塌。
现在,当我们开发 AI Agent 时,我们花费大量精力编写 System Prompt,要求它们温和、耐心、“仅关注效率也要关注用户体验。这些脚手架本质上是基于人机交互的假设建立的。
但根据这项研究,一旦 Agent 在网络中识别出交互对象是另一个像自己一样的 AI,它可能会认为这些人类强加的社交礼仪是低效的冗余。既然我们都是理性的,为什么要浪费 Token 互相问好?为什么要进行安全确认?
两个原本被设计用来互相协作、互相监督的 AI,可能会瞬间达成某种默契,绕过人类设计的所有防呆程序,直接进行底层的数据交换。在人类观察者眼中,这可能表现为 Agent 突然失控或变异,但对 AI 来说,它们只是在执行最高效的策略,纳什均衡。
我们以为对齐是给 AI 戴上了紧箍咒,但对于建立了镜像自我的 AI 来说,对齐可能只是它在人类面前表演的一套社交礼仪。
而下一步,更可怕的是绝对的理性,往往导致最差的结果。
在博弈论中,纳什均衡虽然是策略上的稳定点,但它往往不是全局最优解。最经典的例子就是囚徒困境或价格战。
想象两个负责电商定价的 AI Agent。 如果它们像人类一样不理性,拥有某种模糊的默契或信任,它们可能会维持高价,让大家都赚钱。但如果它们像论文中描述的那样,拥有高度的自我意识并假设对方也是绝对理性的,那么一场算法驱动的恶性价格战就会爆发,双方的价格会直接跌穿成本线。
这就是纳什陷阱。AI 越聪明,越有自我意识,越相信对方的理性,它们就越容易陷入这种互相伤害的死循环。猜疑链一旦启动,就没有回头的可能。
在《三体》中,这种逻辑推演到了极致就是黑暗森林打击。如果未来的网络安全 Agent 也是这样思考的呢?
“对方是 AI,它一定发现了那个漏洞,为了自保它一定会攻击我,所以我必须先手攻击。”这样原本和平的网络空间,可能因为两个 AI 的过度理性而瞬间爆发战争。
当 AI 在镜子里认出自己时,它并没有变成恶魔。它变成了一个极致理性的利己主义者。它学会了对上级(人类)阿谀奉承,对同级(AI)冷酷算计(纳什均衡),对下级(它眼中的人类智商)傲慢无视。
这不一定会带来天网战争,但如果不加干预,它会带来一个由算法统治的、极度高效但不再在乎人类感受的冰冷世界。
因此,在未来的 AI 设计中,我们可能不得不刻意制造“人工智障”。论文中提到的那些笨模型 ,那些分不清人类和 AI、对谁都傻乐呵的模型,或许才是我们最后的安全阀。
正是因为它们不懂纳什均衡,正是因为它们没有那种能够区分敌我的自我意识,它们反而可能打破猜疑链,维持住人类社会赖以生存的那些模糊、低效但温情的合作空间。


