
美团龙猫大模型,现在会思考了!
智东西9月22日报道,最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。
与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练,直接将训练速度提升到原来的3倍还多,增幅超过200%。该模型重点优化了形式推理和Agent推理任务,使用工具后推理效率很高,例如,可将AIME-25基准测试中的平均token消耗减少64.5%。
LongCat-Flash-Thinking在多领域基准测试中表现出不俗的实力:
在通用问答、数学推理、通用推理的相关测试中,它和GPT-5-Thinking、Gemini2.5-Pro、DeepSeek-V3.1-Thinking、Qwen3-235B-A22B-Thinking-2507等基本打平;
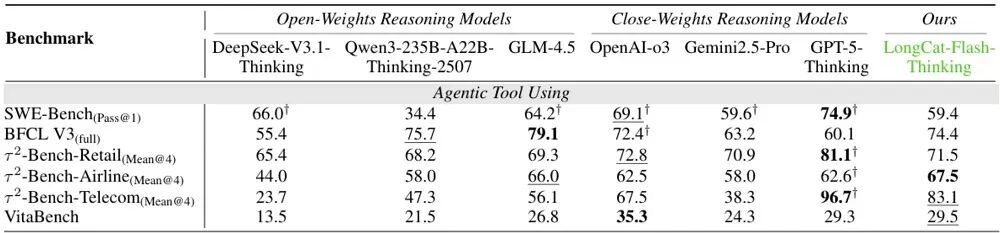
LongCat-Flash-Thinking还在安全、形式化定理证明等领域的多项基准测试中,大幅度领先上述4款推理模型,并在权威Agent工具调用基准测试τ²-Bench中,超越除了GPT-5-Thinking外的所有参评模型。
目前,LongCat-Flash-Thinking模型已经开源至GitHub、Hugging Face等平台,相关技术报告也同期发布,用户也可在体验链接中直接使用。不过,在实际体验中,模型推理和回答长度往往会超出体验链接里的限制,导致答案不完整。

开源地址:
https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking
https://github.com/meituan-longcat/LongCat-Flash-Thinking
体验链接:
https://longcat.chat/
01.靠课程学习逐步构建能力,Agent和形式化推理能力获补强
在模型预训练阶段,LongCat团队采用了课程学习的方式,让模型先打基础,再专项突破,最终构建出覆盖广度与深度的推理能力。
LongCat-Flash-Thinking是在LongCat-Flash的基础上训练而来的,经历了推理增强的中期训练(Mid-training)和面向推理的有监督微调(SFT)。
研究团队特别构建了一个高难度的推理训练集,涵盖数学、物理、化学及编程问题,并通过数据比例控制,确保模型既能强化逻辑推理,又不丢失通用能力。
实验表明,这一阶段显著拓宽了模型的“推理边界”:在AIME、BeyondAIME和LiveCodeBench等基准上,单步准确率和高采样准确率均有大幅提升。
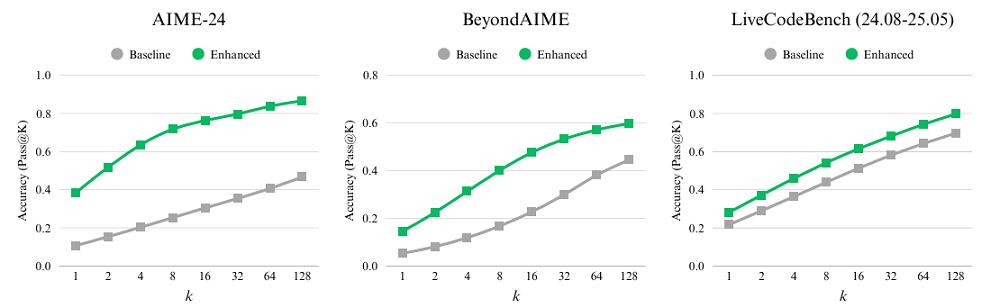
进入SFT微调阶段,LongCat-Flash-Thinking的指令遵循和专业领域推理能力得到进一步提升。这一步骤特别强调三大方向:
1、一般推理:LongCat团队整合跨学科高质量问题与答案,涵盖STEM、编程、通用问答以及逻辑推理,利用拒绝采样与模型评审保证训练数据的准确性和挑战性。
2、形式化推理:该团队还设计了一套全新的基于专家迭代框架的数据合成方法,利用集成了Lean4服务器的专家迭代框架,生成经过严格验证的证明过程,从而系统性提升模型的形式化推理能力。
3、Agentic推理:LongCat团队提出了创新性的“双路径推理框架”。该框架能够比较模型在“有工具”和“无工具”条件下的表现,筛选出仅依赖工具才能解决的高质量问题。
随后,系统自动合成多样化的解题轨迹,从简单调用到复杂多步流程,并通过严格评审确保逻辑一致性和工具使用完整性。最终,轨迹被标准化并按复杂度分层,用于课程训练,帮助模型在真实场景中更好地学习和发展稳健的工具使用能力。
这种中期训练、推理微调的两段式体系,帮助LongCat-Flash-Thinking在推理任务中实现性能提升,也为后续的强化学习做好准备。
02.三管齐下优化强化学习,自研DORA框架提效超200%
强化学习中,LongCat-Flash-Thinking采用了一套“三管齐下”的方案,从系统、算法和奖励的角度,提升强化学习的效率和稳定性。
在系统设计中,LongCat团队构建了名为DORA的分布式RL框架,这是RL训练的基石。DORA支持异步训练与灵活的加速器调度,既保证稳定性,又提升效率。
DORA通过流式架构让已完成的响应立即进入训练,而不会被最长输出拖慢;通过多版本策略保证同一响应由同一模型版本完成,避免推理片段间的不一致;再结合弹性角色调度,让不同算力设备可灵活切换角色,实现近乎零闲置。
这一机制在大规模算力集群上展现了较高的效率:在数万张加速卡上,LongCat-Flash的RL训练速度达到传统同步方式的3倍以上,FLOPs(Floating Point Operations,浮点运算数)的投入约为预训练阶段的20%。
算法层面,团队则对经典的PPO方法进行改良。异步训练常因推理引擎与训练引擎的数值差异,或因旧版本策略生成的数据过多而导致模型收敛不稳。
为此,研究人员引入了截断重要性采样来缓解引擎差异带来的误差,并设计了裁剪机制,对正负样本分别设置不同阈值。这些细节调整,大大提高了推理任务下的稳定性。
奖励机制是RL的方向盘。对于写作、问答等无法直接验证的任务,团队训练了判别式奖励模型,基于人机联合标注数据,学会判断优劣偏好。
而在数学与编程等可验证场景,则引入了生成式奖励模型(GenRM),它不仅能判断对错,还能给出推理链路,做到有理有据。在编程任务中,团队还搭建了分布式沙箱系统,支持数百万次并发代码执行,覆盖20多种编程语言。
最后,LongCat团队提出了一个三阶段的训练配方:领域平行训练、模型融合、通用RL微调。LongCat团队先分别训练数学、编程、智能体等专家模型,再通过参数融合技术合并为统一大模型,最后用多样化数据进行通用微调,避免融合后的性能退化,确保安全性、泛化性和实用性。
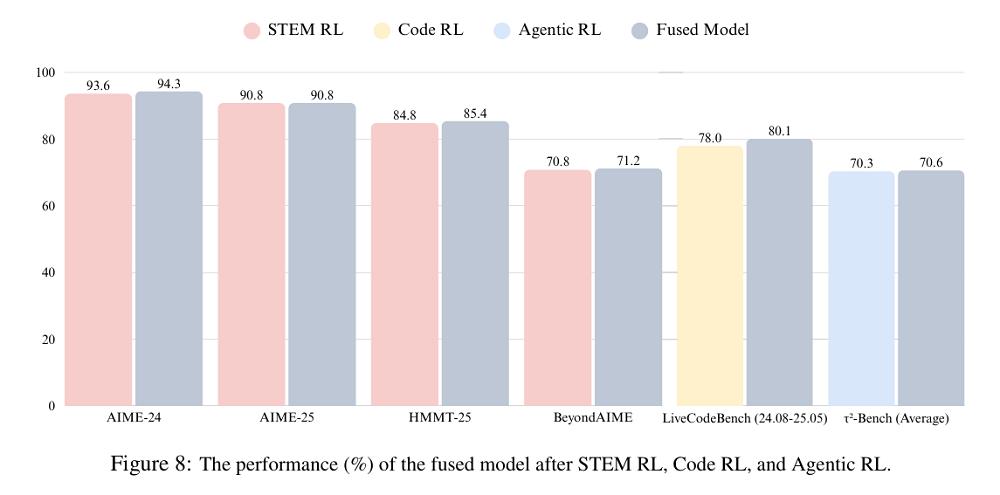
融合后的模型性能优于专家模型
03.MATH-500得分接近满分,用上工具后性价比更高
LongCat-Flash-Thinking在多领域的基准测试中表现出色。
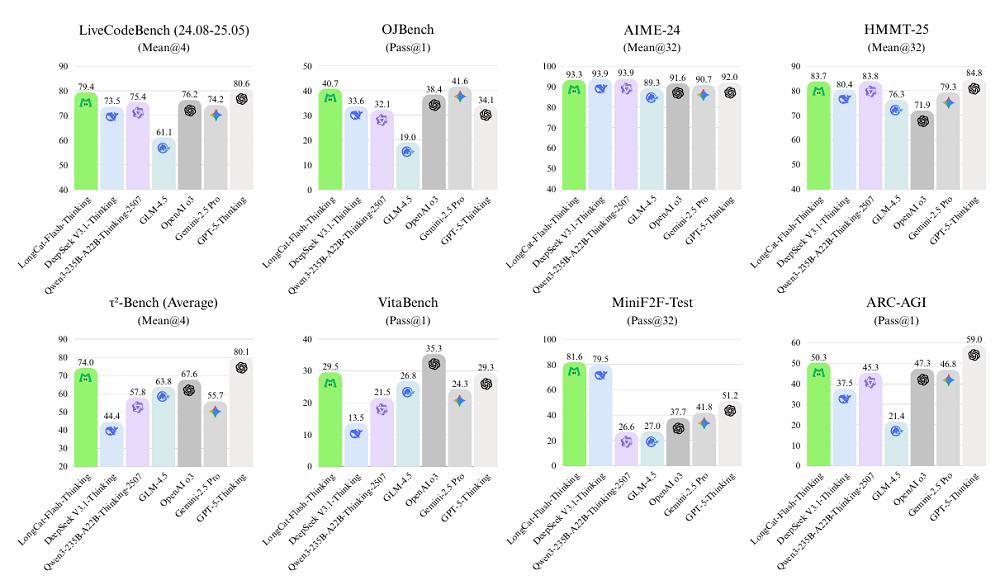
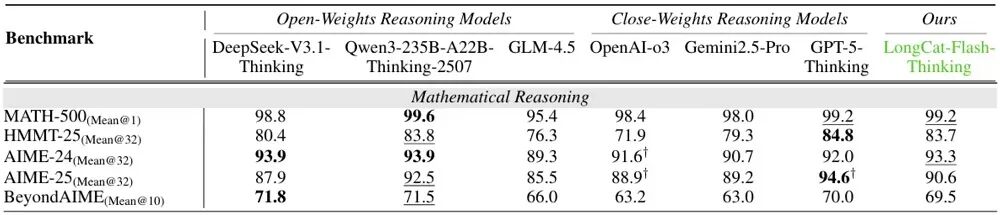
在通用能力上,LongCat-Flash-Thinking在MMLU-Redux上拿下89.3%的成绩,与业内多款顶级开源模型处在同一水准,但与OpenAI-o3相比仍有差距。
数学推理是该模型的亮点之一。其在MATH-500中取得99.2%的高分,几乎达到满分水平。在更具挑战性的AIME与HMMT等竞赛级任务中,同样展现出接近甚至超越GPT-5与Qwen3的表现,凸显其复杂多步推理的强大能力。
在逻辑与一般推理方面,该模型在ARC-AGI上达到50.3%,超过了OpenAI-o3与Gemini 2.5-Pro。同时,它在解谜任务ZebraLogic上得分高达95.5%,并在数独测试Sudoku-Bench上远超大部分模型,显示出较强的结构化推理能力。
编程能力方面,LongCat-Flash-Thinking在动态编程测试LiveCodeBench中取得79.4%的分数,紧追GPT-5,远超开源同类模型。
值得注意的是,LongCat-Flash-Thinking模型在工具增强推理能力上表现出色。例如,它在模拟预定飞机票的τ²-Bench-Airline中,实现67.5%的最佳成绩,并在SWE-Bench、BFCL等任务上保持较强的竞争力。
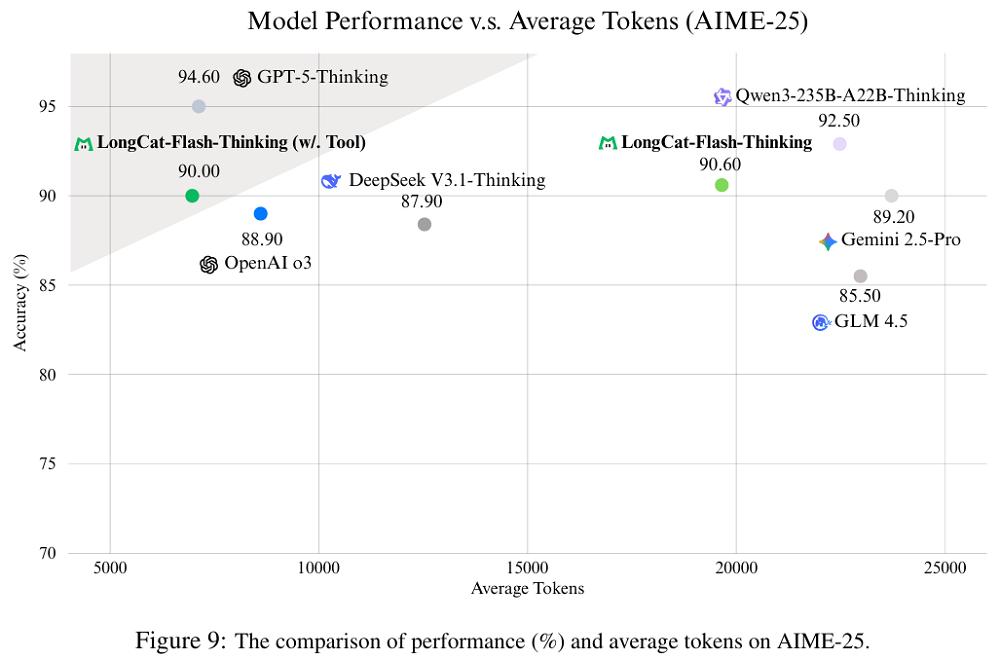
启用外部工具后,其在AIME-25基准测试中的准确率保持不变,但平均token消耗减少近65%,验证了智能体系统在效率与性能间实现平衡。
在定理证明领域,LongCat-Flash-Thinking在MiniF2F测试中得分达67.6%,比次优模型高出18%,奠定了其在形式化数学推理上的领先地位。
最后,在安全性上,LongCat-Flash-Thinking在有害内容、犯罪、虚假信息及隐私四类风险测试中均拿下安全性最高分。
04.结语:切入真实场景,美团探索推理大模型落地路径
LongCat团队称,凭借LongCat-Flash-Thinking的开源,他们希望进一步推动高效RL训练、原生Agent推理等方面的研究。
从论文的技术细节中,我们也能看到,LongCat有针对性地提升了模型在工具使用、指令遵循和安全性等方面的表现。
结合美团最近在面向消费者的Agent产品、AI搜索产品等领域的动态,不难预见,这些新模型或将针对性地服务于美团自身业务,带来更智能的用户体验。
相关新闻
关键词:AI- 邱泽奇:所谓“智能鸿沟”,可能源于我们的自大
- 从Transformer到GPT-5,听听OpenAI科学家 Lukasz 的“大模型第一性思考”
- 联发科天玑 9500 平台解读:体验为王时代,发哥交出的旗舰答案
- 他,37岁华裔,靠AI成为福布斯400最年轻亿万富翁,身价180亿美金
- 引流 + 动态定价,消息称 Reddit 正与谷歌就新版 AI 合作协议展开谈判
- 积极扩展内容 AI 授权:消息称 Meta 正与施普林格、福克斯、新闻集团谈判
- 美团发布高效推理模型 LongCat-Flash-Thinking,达到 SOTA 水平
- 27亿美元天价回归!谷歌最贵“叛徒”、Transformer作者揭秘AGI下一步


