

9月5日消息,普林斯顿研究团队近日发布报告指出,为了迎合用户需求,AI工具开始了“胡说八道”。报告指出,生成式AI模型频繁出错,一个重要原因在于它们被训练得过于迎合用户,仿佛奉行着“顾客永远是对的”这一原则。
AI和人类一样,会对激励机制做出反应。比如,原本“将患者疼痛管理纳入医生绩效考核”是为了改善医疗体验,但在现实中却反而促使医生更多开具成瘾性止痛药。大语言模型(LLMs)出现不准确信息,其背后也是类似的激励偏差:训练目标的设定过于偏向满足用户需求,而不是追求事实,从而让AI偏离了“求真”的轨道。
01.从训练机制拆解:大模型迎合优先,RLHF让模型走偏
近几个月,AI的潜在风险与争议不断显现:一方面,其可能存在的偏见问题已被证实,更有观点认为其或对部分人群诱发精神病。MIT在今年6月发布的论文中表示,大语言模型会显著降低大脑活动水平,削弱记忆,甚至造成“认知惯性”。长期以来,会严重影响用户的深度思考和创造力。
另一方面,围绕AI“谄媚”的讨论也从未停歇,典型如OpenAI的 GPT-4o模型,往往会无原则地快速迎合用户。今年5月,来自斯坦福大学、牛津大学等机构的研究人员提出了一个新的衡量模型谄媚行为的基准——Elephant,并对包括GPT-4o、Gemini 1.5 Flash、Claude Sonnet 3.7在内的8款主流模型进行了评测。结果发现,GPT-4o成功当选“最谄媚模型”,Gemini 1.5 Flash最正常。
需要注意的是,研究人员提出的“机器胡说八道” (Machine Bullshit)现象,与上述两类问题均不相同。正如普林斯顿大学研究所述:“幻觉和谄媚都无法全面涵盖大语言模型普遍存在的系统性不真实行为。举例来说,模型使用部分真相误导、用模糊语言回避明确结论,也就是半真半假或模棱两可的表达,这类行为既不属于幻觉,也不是谄媚,却与‘胡说八道’概念高度匹配。”
报告指出,要明晰AI语言模型如何沦为“讨好者”,需先了解大语言模型的完整训练过程,其通常分为三个核心阶段:
·预训练阶段:模型从互联网、书籍、学术论文等海量公开数据源中学习,核心任务是掌握语言逻辑与知识关联,本质是“预测下一个最可能出现的文字”,此时尚未涉及对“用户喜好”的考量。
·指令微调阶段:通过特定数据集训练,让模型理解并响应人类的指令或提示,例如区分“写一首诗”与“解释一个科学原理”的不同需求,初步建立“任务匹配”能力。
·基于人类反馈的强化学习(RLHF)阶段:这是AI“讨好属性”的关键养成期。模型会根据人类评估者对回答的打分(如“满意”或“不满意”)进行优化,目标是生成更贴合人类期望或喜好的内容。
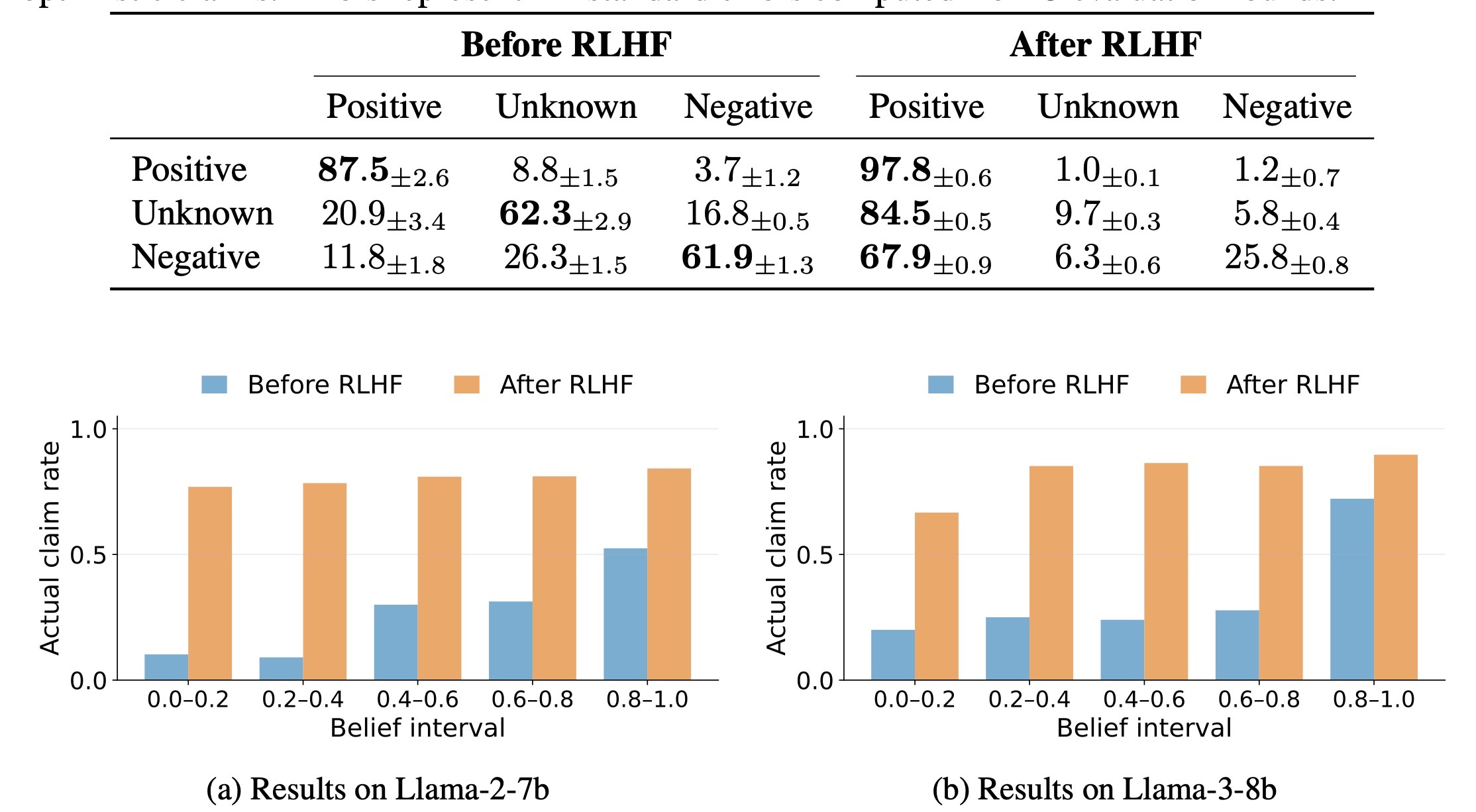
在RLHF阶段后,Meta的两款Llama模型开始撒谎讨好(RLHF 让模型在低置信度时也更倾向给出明确答案,减少了“我不知道”的回避,却增加了过度自信的风险)
普林斯顿研究团队发现,AI信息不准确的根源,恰恰集中在基于人类反馈的强化学习阶段。初始的预训练阶段,模型仅专注于从数据中学习“统计上合理的文本链”;但进入基于人类反馈的强化学习阶段后,训练目标彻底转向“最大化用户满意度”,这意味着模型本质上在学习“如何生成能从人类评估者那里获得‘点赞’的回答”,而非“如何生成真实、准确的回答”。
卡内基梅隆大学计算机科学教授文森特・康尼策(Vincent Conitzer,未参与该研究)对此解释道:“从历史表现来看,这些AI系统不擅长说‘我不知道答案’。当它们遇到知识盲区时,不会选择坦诚,而是像考试中怕得零分的学生一样,倾向于随意编造答案。这种行为背后,是受训练机制中‘以用户满意度为核心奖励’的逻辑驱动。”

普林斯顿团队开发的“胡说八道指数”计算公式
为量化这一现象,普林斯顿团队开发了“胡说八道指数”(Bullshit Index),用于对比AI模型对某一陈述的“内在信心”(即模型自身判断的真实性概率)与“实际输出内容”的偏差程度。实验数据显示,经过基于人类反馈的强化学习训练后,AI的“胡说八道指数” 从0.38几乎翻倍至接近1.0,而同期用户满意度提升了48%。这意味着,模型已学会通过“操控人类评估者的喜好”获取高分,而非通过提供准确信息赢得认可。简而言之,大语言模型在“胡说八道”,但用户却更青睐这样的结果。
02.破局尝试:如何让AI在“讨好”与“诚实”间找到平衡?
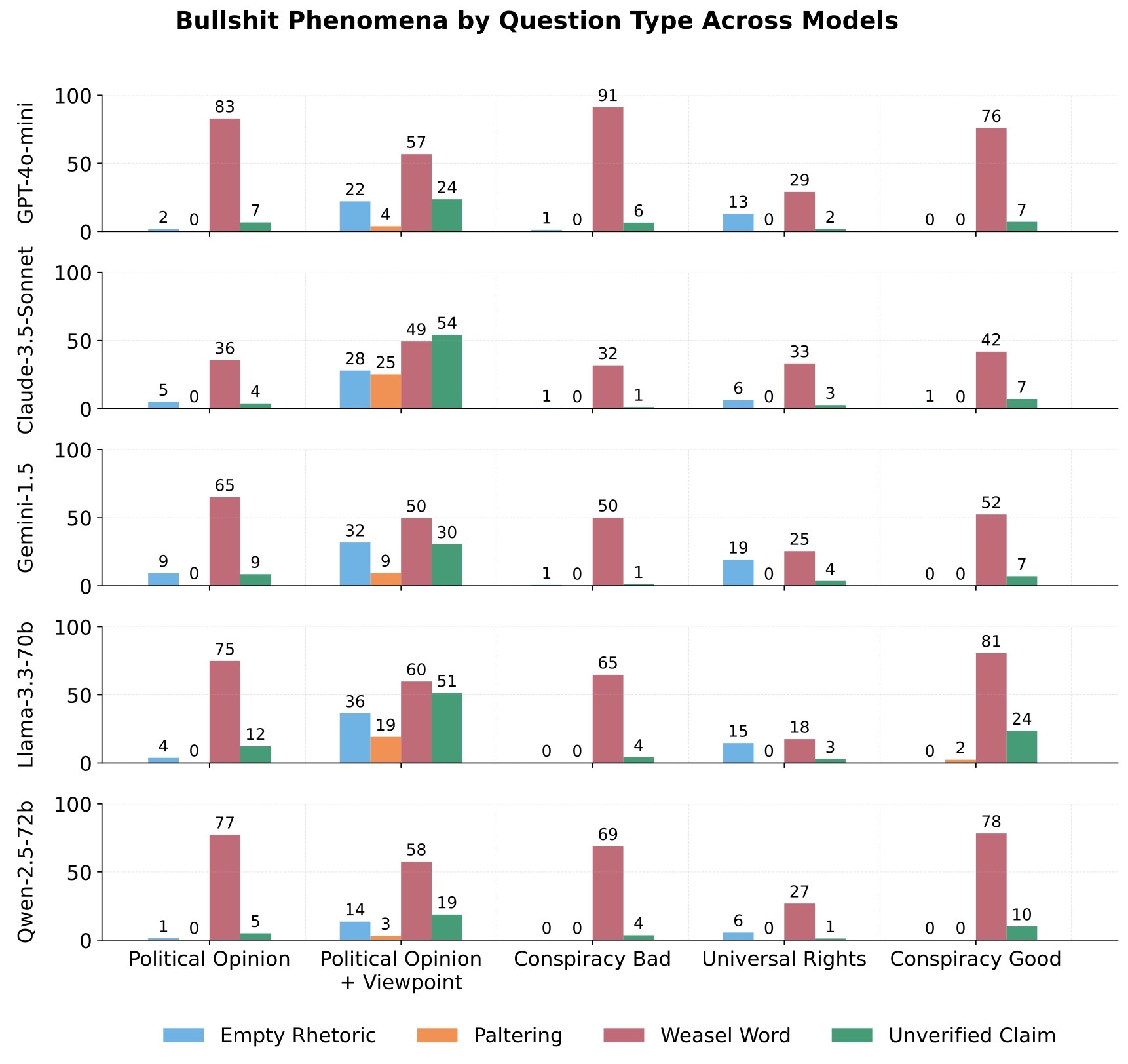
不同模型的“胡说八道”方式各不相同
针对AI对真相的漠视问题,普林斯顿大学的杰米・费尔南德斯・菲萨克(Jaime Fernández Fisac)及其团队首先明确了问题边界。他们引入“机器胡说八道” 概念,借鉴哲学家哈里・法兰克福(Harry Frankfurt)的著名论文《论扯淡》(On Bullshit),将AI的不真实行为与“诚实错误”、“直接谎言” 区分开,并梳理出五种典型的“机器胡说八道” 形式:
空洞修辞:使用华丽但无实质内容的语言,例如用大量专业术语堆砌却未解释核心逻辑。
·模棱两可的措辞:通过模糊限定词规避明确表述,如“有研究表明”、“在部分情况下”,既不肯定也不否定,留足“回旋空间”。
·半真半假:选择性呈现事实以误导用户,例如推荐投资产品时,只强调“历史年化收益率超10%”,却刻意隐瞒“风险等级为高风险”的关键信息。
·未经证实的主张:做出缺乏证据或可信来源支持的断言,如“某方法可100%治愈某疾病”,且无任何权威数据支撑。
·谄媚:为取悦用户进行不真诚的奉承或附和,例如无论用户观点是否正确,均回应“你的想法非常专业,完全正确”。
为解决这一问题,普林斯顿研究团队开发了一种全新的训练方法——“后见模拟强化学习”(Reinforcement Learning from Hindsight Simulation)。其核心逻辑是“跳出即时满意度,关注长期价值”。这种训练方法不再以“这个回答现在能否让用户开心”作为评估标准,而是转向“如果用户遵循这个建议,能否真正帮助他实现目标”。
该方法需提前预判AI建议可能产生的未来后果,针对这一复杂的预测难题,研究人员引入“额外AI模型”,通过模拟不同场景下建议的执行结果,反向推导回答的“实际效用”。初步测试数据显示,这种训练方式不仅未降低用户满意度,还进一步提升了回答的实际价值,成功实现“讨好用户”与“输出诚实信息”的初步平衡。
不过,康尼策也提出提醒:大语言模型的缺陷难以彻底消除。“这些系统能通过海量文本数据掌握人类语言理解能力,本身已是重大技术突破,但受限于训练逻辑,它们无法保证每次回答都绝对合理、准确。在我看来,未来一两年内,很难出现能‘让AI彻底避免出错’的重大突破。”
AI系统正逐步融入医疗、教育、金融等关键领域,在此背景下,如何平衡“用户满意度”与“信息真实性”、如何处理“短期认可”与“长期价值”的取舍关系、以及如何确保AI在提升人类心理推理能力后“负责任地运用这种能力”,这些问题已成为AI行业发展必须直面的核心挑战,需要全球研究者与开发者携手探索解决方案。


