

国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。
如今,在语音 AI 领域,国产大模型第一梯队的重量级选手 MiniMax 又抛下了一颗「重磅炸弹」。
我们看到,其全新一代 TTS 语音大模型「Speech-02」在国际权威语音评测榜单 Artificial Analysis 上强势登顶,一举击败了 OpenAI、ElevenLabs 两大行业巨头!
其中,在字错率(WER,越低越好)和说话人相似度(SIM,越高越好)等关键语音克隆指标上均取得 SOTA 结果。
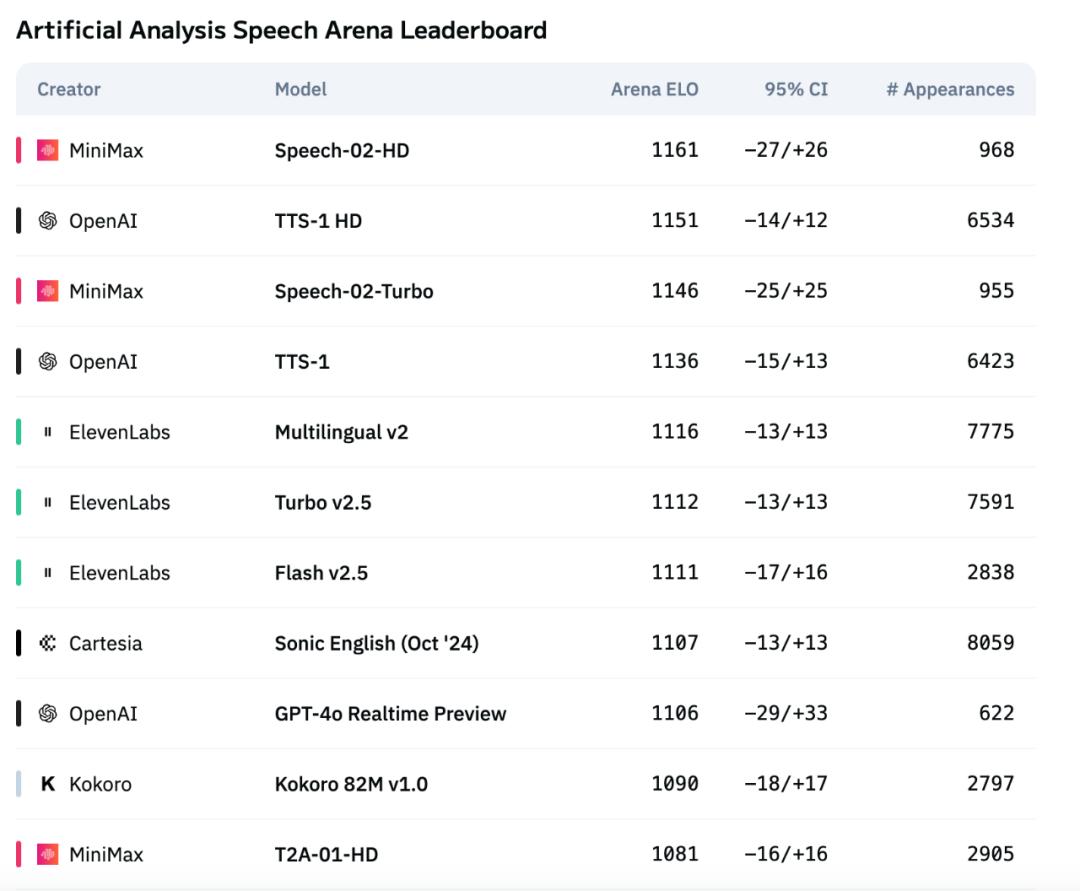
图源:Artificial Analysis Speech Arena Leaderboard
这项成绩直接震惊国外网友,他们纷纷表示:「MiniMax 将成为音频领域的破局者。」

知名博主 AK 也转推了这个新语音模型:

性能更强之外,Speech-02 还极具性价比,成本仅为 ElevenLabs 竞品模型(multilingual_v2)的 1/4。

Speech-02 的登顶,再次展现出了国产大模型超越国外顶级竞争对手的技术实力与底蕴。
那么,Speech-02 究竟有哪些魔力才取得了这样亮眼的成绩。随着本周技术报告的公布,我们对模型背后的技术展开了一番深挖。
屠榜背后,MiniMax 做了哪些技术创新?
当前,主流的文本转语音(TTS)模型在建模策略上主要分为两类,即自回归( AR)语言模型和非自回归(NAR)扩散模型,两者在建模难度、推理速度、合成质量等方面各有其优劣势。
其中,非自回归模型有点类似于批量生产,生成速度很快,就像一家快餐店出餐快但口味普通,生成的语音不够生动、逼真。
自回归模型可以生成韵律、语调和整体自然度等多个方面更好的语音。不过,这类模型在语音克隆过程中需要参考语音和转录文本作为提示词,就像高级餐厅味道好但需要顾客提供详细食谱才能复刻菜品一样。这种单样本(one-shot)学习范式往往导致生成质量不佳。
作为一个采用自回归 Transformer 架构的 TTS 模型,Speech-02 的强大源于两大技术上的创新:
一是实现了真正意义上的零样本(zero-shot)语音克隆。所谓零样本,就是给定一段参考语音,无需提供文本,模型很快就可以生成高度相似的目标语音。
二是全新的 Flow-VAE 架构,既增强了语音生成过程中的信息表征能力,又进一步提升了合成语音的整体质量和相似度。
零样本语音克隆
首先,Speech-02 引入了一个可学习的 speaker 编码器,该编码器会专门学习对合成语音最有用的声音特征,比如更关注说话人的独特发音习惯,而不是无关的背景噪音。
正是在此模式下,Speech-02 只需要听一段目标说话人的声音片段(几秒即可),就能模仿出这个人的音色、语调、节奏等特征,不会有机器人念稿的那种割裂感。而且整个过程是零样本的,不需要额外训练或调整。
这就为语音合成技术节省了大量宝贵时间,我们不难发现,传统方法需要大量数据,比如先录制 1 小时的声音。此外,数据的多样性也是一个问题,模型需要能够处理不同国家、年龄、性别等说话人信息。而 Speech-02 完全克服了这些挑战,直接听音学样,且一听就是你。
此外,MiniMax 还提出了可选增强功能,即单样本语音克隆。在此设置下,需要提供一个文本 - 音频配对样本作为上下文提示,从而指导语音合成。
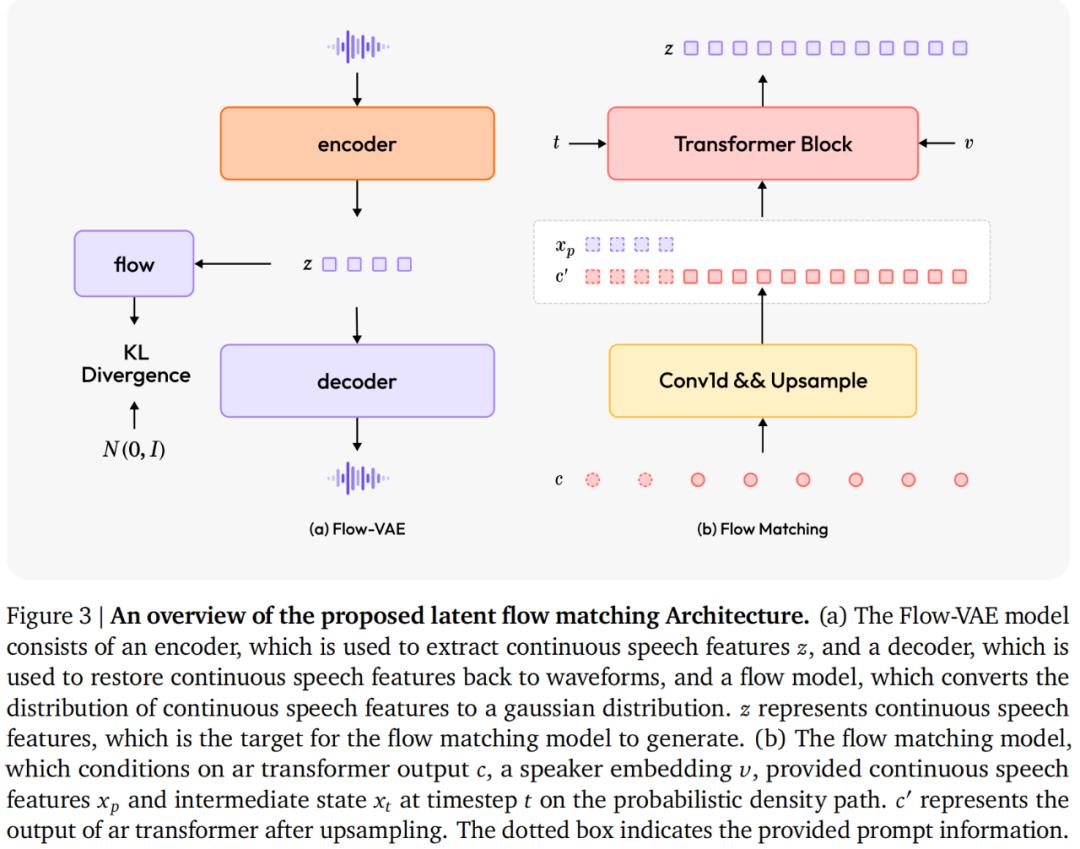
Flow-VAE 架构
MiniMax 还提出了用于生成连续语音特征的关键组件,即基于Flow-VAE 架构的流匹配模型。从而进一步提升了音频质量,使得生成的音频更加接近真人。
在 Speech-02 中,流匹配模型旨在模拟连续语音特征(潜在)的分布,这些特征是从音频训练的编码器 - 解码器模块架构中提取的,而不是梅尔频谱图。
通常来讲,传统的 VAE 假设其潜在空间服从简单的标准高斯分布,相比之下,Flow-VAE 引入了一个流模型,该模型可以灵活地使用一系列可逆映射来变换潜在空间,从而更准确地捕捉数据中的复杂模式。
更进一步,MiniMax 还搞了个双保险设计,即将全局音色信息和提示信息结合起来。具体而言,Speaker 编码器会从声音中提取全局音色特征 —— 就像提取一个人的「声音 DNA」。训练时,当前句子开头的信息会以一定的概率被用作提示。因此在推理阶段,模型支持零样本和单样本合成模式。
可以说,经过一系列操作,Speech-02 不仅可以模仿声音的「形」,还能复现声音的「神」。
正是基于这些强有力的技术支撑,才使得 Speech-02 一举超越 OpenAI、ElevenLabs 等竞品模型。
文生音色
现有的 TTS 方法生成所需音色的语音需要提供该特定音色的参考音频样本,这一要求可能会限制其操作灵活性。
相比之下,MiniMax引入了一个 T2V 框架,该框架独特地将开放式自然语言描述与结构化标签信息相结合。作为参考音频驱动的speaker编码器(擅长克隆现有语音)的补充,该方法促进了高度灵活且可控的音色生成,从而显著增强了 TTS 系统的多功能性。
多指标赶超竞品模型
语音克隆保真度、多语言与跨语言语音合成等多个关键维度的综合评估结果,有力验证了 Speech-02 的「含金量」。
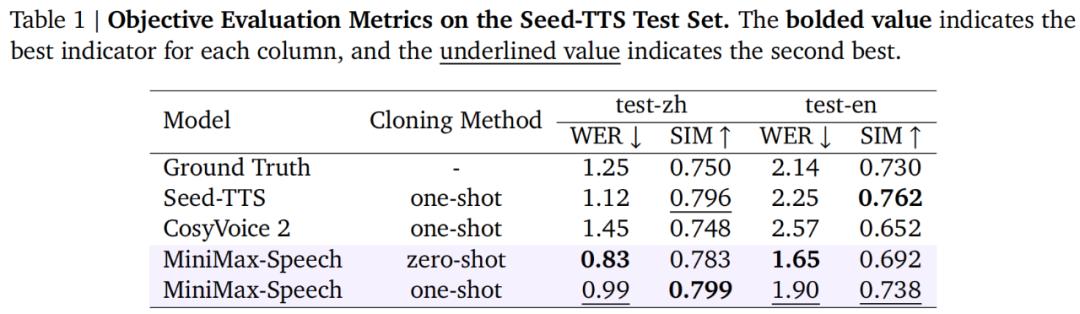
首先来看语音克隆保真度指标,从下表可以看到,与 Seed-TTS、CosyVoice 2 和真实音频相比,Speech-02 在中英文的零样本语音克隆中均实现了更低的 WER,表明其发音错误率更低且更清晰稳定。
此外,零样本语音克隆的 WER 表现也显著优于单样本。并且根据听众的主观评价反馈,零样本克隆合成的语音听起来更自然、真实。
在多语言方面,Speech-02着重与ElevenLabs的multilingual_v2模型进行对比,两者均采用零样本克隆来生成语音。
在 WER 方面,Speech-02与multilingual_v2表现相当。在中文、粤语、泰语、越南语、日语等几种语言上,multilingual_v2的WER均超过了10%,而 Speech-02 的表现明显更优。这意味着,在捕捉并复现这些具有复杂声调系统或丰富音素库的语言时,multilingual_v2 处于绝对劣势。
在 SIM 方面,Speech-02 在所有 24 种测试语言中均显著优于 multilingual_v2,无论目标语言的音系特征如何,前者生成的克隆语音更接近真人原始声音。

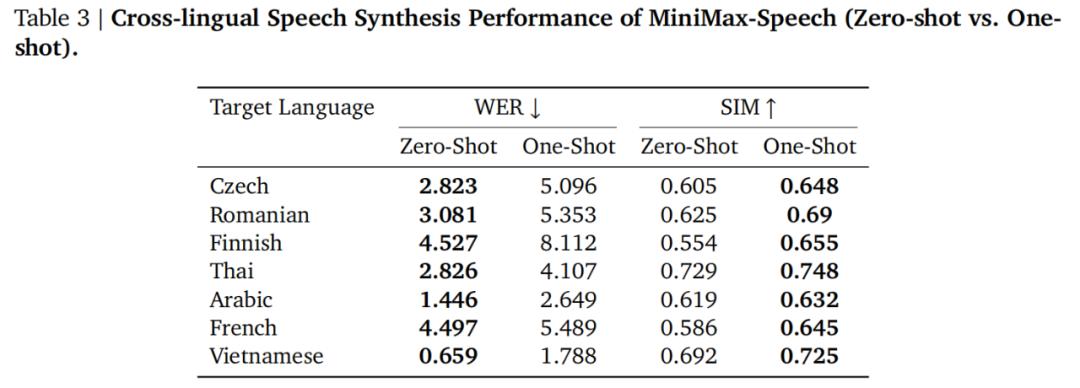
在跨语言方面,下表多语言测试结果展示了零样本语音克隆下更低的 WER,证明 Speech-02 引入的 speaker 编码器架构的优越性,可以做到「一个语音音色」支持其他更多目标语言并且理解起来也较容易。
更多技术与实验的细节,大家可以参阅原技术报告。
技术报告地址:https://minimax-ai.github.io/tts_tech_report/
实战效果如何?
我们上手进行了一些实测,发现可以用三个关键词来总结 Speech-02 的亮点 ——超拟人、个性化、多样性,在这些层面迎来脱胎换骨的升级。
第一,超拟人。
Speech-02 预置了极其丰富(数以百计)的多语言声音库,每一个都有其独特的音色和情感语调。
从合成音效来看,Speech-02 的相似度和表现力非常出色,情绪表达到位,音色、口音、停顿、韵律等也与真人无异。错误率上比真人更低,也更稳定。
第二,个性化。
核心是「声音参考」(Voice Clone)功能,只需提供一段示范音频或者直接对着模型说几句话,模型就可以学会这种声音,并用这个声音来演绎内容。目前该功能只在海外网页版上线,国内仅对 B 端用户开放。
从行业来看,其他头部语音模型只能提供少数几个精品音色的控制。而 Speech-02 通过声音参考功能可以灵活控制任意给定声音,提供了更多选择和更大自由度。
接着上传了苏轼的名篇《江城子・乙卯正月二十日夜记梦》,这是一首他写给已故妻子的悼亡词。由于 Speech-02 可以对音色进一步进行情绪控制,这里选择了悲伤「sad」,并调慢了语速。
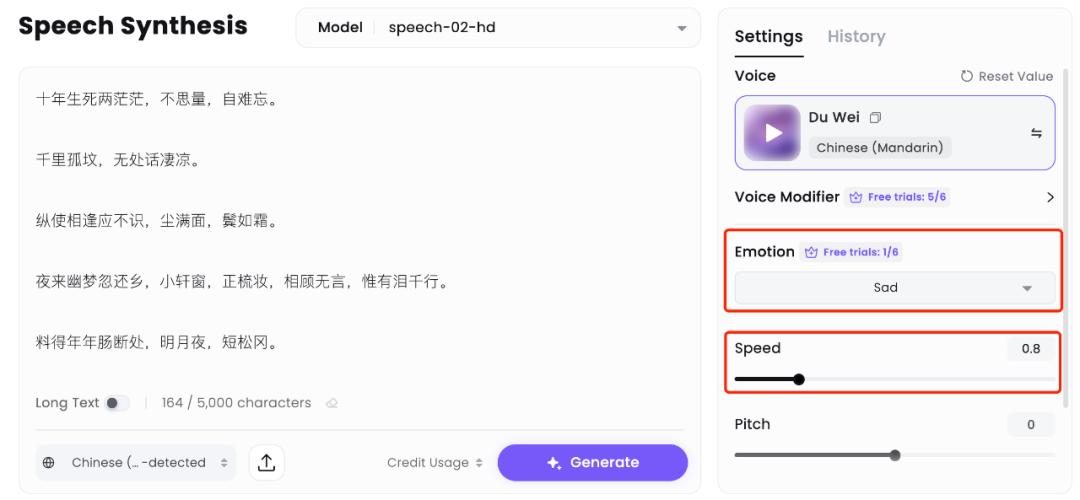
除了悲伤之外,Speech-02 还有快乐、生气、恐惧、厌恶、惊讶、中立其他情绪可选。
总结一波,Speech-02 的「个性化」有以下三点关键影响:
- 促成了业内首个实现「任意音色、灵活控制」的模型;
- 让每一个音色都能有好的自然度和情感表现力;
- 用户就是导演,音色就是演员。用户可以根据自己想要的效果用文字来指导演员表演。
第三,多样性。
Speech-02 支持32 种语言,并尤为擅长中英、粤语、葡萄牙语、法语等语种。
下面来听一段融合了中文、英语和日语的长段落,读起来一气呵成:
对于同一段音频,Speech-02 也可以轻松切换不同语言。
随着高质量、多维度语音能力的极致释放,Speech-02 一跃成为了「全球首个真正实现多样化、个性化定义的语音模型」。
这将进一步推动语音 AI 走向千人千面的智能交互体验,为 MiniMax 在「AI 人格化」的技术与应用浪潮中抢占先机。
体验地址:https://www.minimax.io/audio/text-to-speech
技术领先只是第一步,能落地才能发挥价值
作为一家成立于 2021 年的大模型厂商,MiniMax 从创立之初即聚焦面向 C 端和 B 端的 AI 产品,强调「模型即产品」理念,其文本模型、语音模型与视频模型已经形成了一条完整的产品链,比如海螺 AI。
在语音大模型领域,MiniMax 在深耕底层技术的同时,持续探索语音助手、声聊唱聊、配音等不同场景的落地方案,推动智能语音内容创作向更高效、更个性化、更情感化演进;同时接入 MiniMax 语音大模型的 AI 硬件逐渐增多,并扩展到儿童玩具、教育学习机、汽车智能座舱、机器人等赛道,加速商业化进程。
MiniMax 正依托其语音大模型,联合行业上下游构建更丰富、更垂直的智能交互生态。过程中也向外界透露出这样一种迹象:语音大模型技术正迎来从技术成熟走向规模应用的关键拐点。
