
来源|知乎用户 大狗狗是狼
01
编者按
6月30日,美团发布新一代基础大模型LongCat-2.0。模型采用MoE架构,总参数1.6万亿,每个Token激活参数约480亿。
正式发布前,LongCat-2.0曾匿名“Owl Alpha”接入OpenRouter,并且进入总调用量前三。在Claude Code Agent场景下,LongCat-2.0的调用量排名全球第二,仅次于Claude Opus 4.8。
如果只看这些,LongCat-2.0似乎没什么特殊性。
它不是性能最顶尖的模型。技术社区认为,LongCat-2.0的Agent核心能力接近Claude Opus 4.6,落后于最新的Claude Opus 4.8。它甚至不是性能最强的国产模型,社群普遍认为它的Coding能力略优于智谱AI的GLM-5.1,但落后于6月新发布的GLM-5.2。
LongCat-2.0也不是调用量最高的国产模型。因为免费的原因,在OpenRouter上,腾讯混元、阿里千问,以及DeepSeek,都曾位列前位。
在X和Reddit上,不少开发者用同样的生成指令对比LongCat-2.0和GPT-5.5,后者的表现明显更优。也有国内外开发者反馈,LongCat-2.0的Coding和Agent能力很强,但文案等能力并不突出。
但上述这些表现,在加上一个限定词后,却从“相对劣势”变成了“质的突破”——LongCat-2.0是“英伟达含量为0”的万亿级别大模型,它从训练到推理,全部由国产算力集群完成。
这不仅是“国芯+国模”真正意义上的跑通,还直接挤进了全球第一梯队。
之前,国内大模型不缺“国产叙事”,有用国产芯片做推理,有用国产芯片做“后训练”,但训练+推理全流程跑通万亿规模,之前从来没有过。
一位开发者向我们形容其中的区别:之前相当于房子建好了,用“国产算力”装修;这次(LongCat-2.0)是从打地基一直到入住,住着居然很好。
因为完全绕开了英伟达,LongCat-2.0成了这两天的AI热点。美国时间6月30日,它登上了X平台News榜单,相关推文超过2800条。
从推文内容可以看出,海外很多用户根本不知道“Meituan”是一家什么公司,博主普遍将其介绍为“中国的DoorDash”,但实际上,美团的订单规模是前者的10倍。一些开发者因此表示费解,为什么中国一家“送餐公司”,都能做出顶尖的大模型?
除了这类讨论,更多人关心的是,中国AI企业绕开“英伟达”,是否将成为一种常态——在当前的AI竞争中,这几乎是除了AI应用表现外,极受关注的议题。
与之对应的是,在国内,很多报道将LongCat-2.0视为“国产芯片”弯道超车的标志。但在技术社群里,从业者们虽然振奋,但表现得更为冷静。
一位从业者表示,国产芯片的挑战不是算力,而是系统性工程。硬件层面,国产芯片的单卡现存更小,需要的卡量更多,且通信带宽没有那么强,容易出现算力利用率问题;软件方面,英伟达的平台,算子、工具都非常成熟,迁移到国产算力平台后,这些东西都得重新写,这是一项巨大的工程。
在LongCat-2.0发布当天,美团宣布,将在近期开源所有核心技术。围绕这一点,技术社群的讨论还在继续,包括:
美团用的是哪家的国产厂商的芯片?
LongCat-2.0“绕开英伟达”是个例,还是将成为国模常态?
LongCat-2.0的开源对于技术路线是否产生影响?
以及,国产算力已经解决了“能不能”的问题,什么时候能够支撑最前沿的训练?
在知乎社区针对“Longcat-2.0将对大模型领域和AI行业产生哪些影响”的讨论中,用户“大狗狗是粮”针对这些问题做了分析。
我们将这篇回答转给了相关人士,得到的回复是“分析得比较客观”。
以下为回答全文。
网上有不少人在喊“国产算力弯道超车”、“美团逆袭OpenAI”了。但如果你真的去翻美团今天(6月30日)发的官方博客,再对照LongCat-Flash那篇已经挂在arXiv上快十个月的技术报告(2.0的架构是从Flash继承来的,这篇是理解它的地基),会发现这件”大事”里真正值得讨论的,和媒体标题写的,几乎是两回事。
LongCat-2.0的1.6万亿总参数、480亿平均激活、1M上下文,这些数字单拎出来并不稀奇。DeepSeek-V4-Pro是同样的1.6T/49B/1M,早在4月就开源了。真正让这件事在工程上有分量的,是三个被大多数人一笔带过的细节:
1.5万张昇腾910C从零预训练
2.MoE稀疏度做到了97%
3.它在OpenRouter上匿名测试时的调用量结构
02
5万卡昇腾从零预训练,和“千卡后训练”是两码事
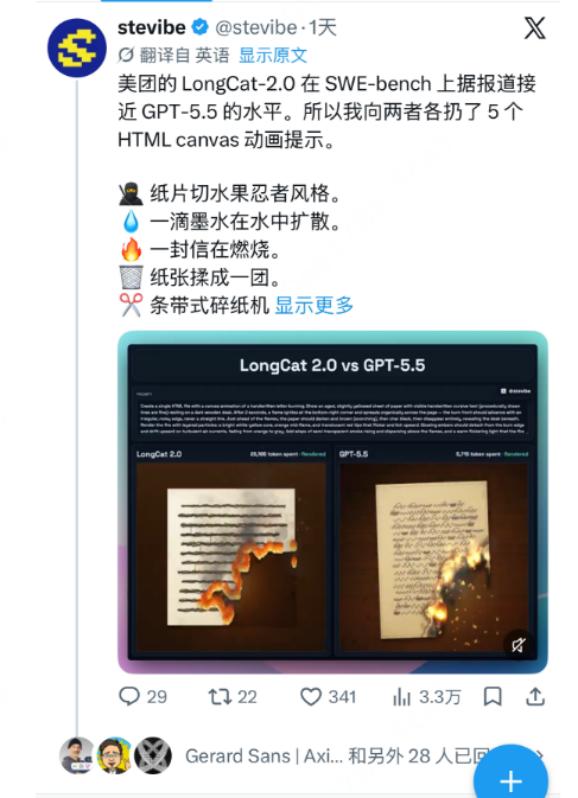
明确一个前提:美团官方博客通篇只说“国产算力芯片”“AI ASIC superpod”,没有公布具体卡数,也没有点名芯片型号。“五万卡”这个数字来自“IT之家”(业界首个:美团 LongCat-2.0 发布,国产芯片上跑出的万亿参数模型)等媒体的报道,而快科技那边用的是更模糊的“万卡级”,另有说法给的是“5至6万张”区间。至于芯片是华为昇腾910C,这是各社区平台根据“200Gbps RDMA”“每die 64GB HBM”这些线索反推的主流观点,美团和华为都没在LongCat语境下正式确认。准确说法是“媒体披露的约5万张、社区推断为昇腾910C的国产算力集群”,简称“5万卡昇腾”。
很多报道把LongCat-2.0和今年6月初那条“昇腾910C完成1.6万亿参数DeepSeek-V4-Pro训练”的新闻混为一谈。但你去读知乎上相关问题的技术拆解,会发现深圳河套学院联合哈工大、华为做的那个项目,本质是拿现成的DeepSeek-V4-Pro权重做全参数后训练/续训练,跑了1500多步稳定训练。这是一件值得肯定的工程突破,但它解决的是“国产卡能不能微调一个万亿模型”。
美团这次干的是另一件事:从零开始,在5万卡昇腾集群上把1.6T参数的模型从头训出来,预训练数据超过30T tokens,月均日故障率降低70%以上,训练MFU提升1.5倍,全程无回滚、无不可恢复的loss突刺。
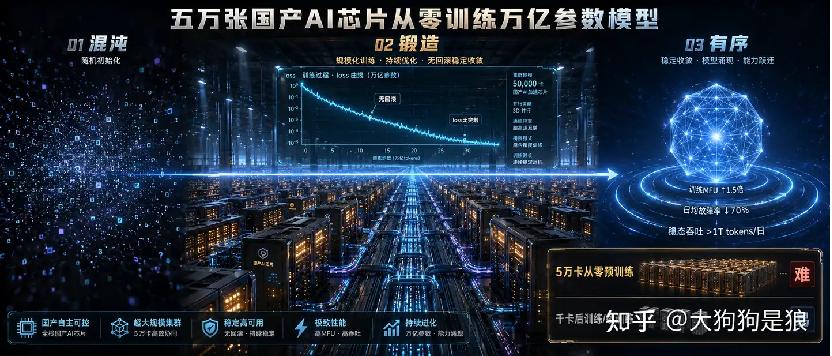
这两者的难度差异是:后训练只需要迭代更新参数,前向反向都在一个已经收敛的loss landscape附近活动;从零预训练要在几十万亿token的尺度上把一个随机初始化的1.6万亿参数网络推到收敛,任何一次loss spike、任何一次NCCL通信超时、任何一片卡的SDC(静默数据损坏),都可能让前面烧掉的几千万电费打水漂。
根据百科词条和社区反推的公开资料,昇腾910C这张卡本身,大概率是Chiplet封装把两颗910B整合在一起,工艺节点接近中芯国际N+2(大致在7nm量级),晶体管数量预估在500亿这个量级。需要说明的是,这些硬件规格华为官方并没有在LongCat的语境下正式确认过,更多是技术社区根据已有信息拼出来的图。Reddit上r/LocalLLaMA有人根据美团披露的“AI ASIC superpod”规格反推(注意这是社区推断,非官方配置),认为910C superpod是48台机器×8颗处理器,每颗处理器两个die,每个die配64GB HBM和200Gbps RDMA。这个配置单卡算力据说直追H100,但真正卡脖子的是软件栈,CANN、HCCL这套生态和CUDA的成熟度差距,才是国产卡能不能跑大模型的真正命门。美团官方博客披露的工程指标是训练MFU提升1.5倍、日均故障率降低70%以上(靠HCCL异常处理加自动故障恢复),MFU能做到30%以上、关键算子效率提升14%,这意味着他们在底层算子适配和通信优化上花了远比“调参”重得多的功夫。
所以这个突破的意义在于它用工业级数据证明了:在不依赖任何一张英伟达卡的前提下,国产算力集群可以独立完成万亿参数模型从预训练到推理部署的完整闭环。这对受美国出口管制影响的中国AI产业,是一个从“能不能”到“稳不稳”的又一大进步。
03
97%稀疏度,“扩专家”路径已死
如果说算力是这次发布的外部叙事,那架构选择才是真正能体现美团技术判断力的地方。
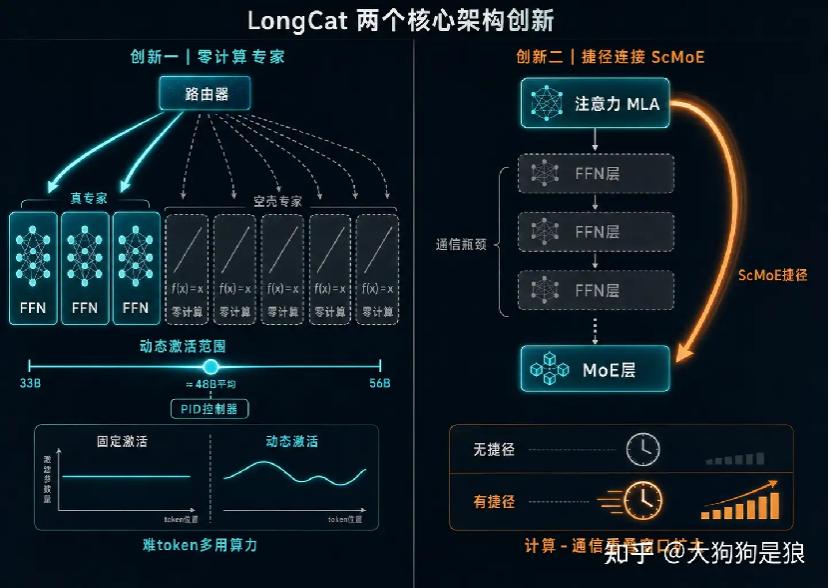
LongCat-2.0继承了LongCat-Flash的两个核心设计:零计算专家(Zero-computation Experts)和Shortcut-connected MoE(ScMoE)。前者在arXiv技术报告里有完整推导,它在专家池里塞进一类“恒等映射”专家,这类专家不做任何计算,直接把输入原样返回。路由器根据token的上下文重要性,动态决定给它派几个真专家、几个零计算专家。结果就是激活参数从一个固定值变成了一个范围:Flash版是18.6B到31.3B,平均27B;2.0版是33B到56B,平均48B。
这个设计的精妙之处不在于“省算力”,而在于它用一个PID控制器(对,就是控制论里那个比例-积分-微分控制器)去调节专家偏置,让token分配比例收敛到目标值。技术报告里写得很清楚,平均激活专家数经过大约20B token的调整后稳定在期望值,波动小于1%,但标准差维持在较高水平,也就是说模型学会了“难token多用算力,简单token少用算力”。
但LongCat-2.0官方博客里有句话,比1.6万亿这个数字更重要:模型的MoE稀疏度在不考虑N-gram Embedding的情况下已经达到约97%,再扩135B专家参数带来的性能增益可以忽略不计。
要知道DeepSeek-V3是671B总参数激活37B,稀疏度大概94%;V4-Pro是1.6T激活49B,稀疏度约97%。LongCat-2.0也是97%。这意味着我们很可能已经撞到了MoE架构的一条渐近线。过去两年大家拼命往专家池里堆参数,从560B到671B到1T再到1.6T,每代都以为“再大一点就更强”。美团的数据直接说:对不起,到97%这个稀疏度,你再加专家,收益小到测不出来。
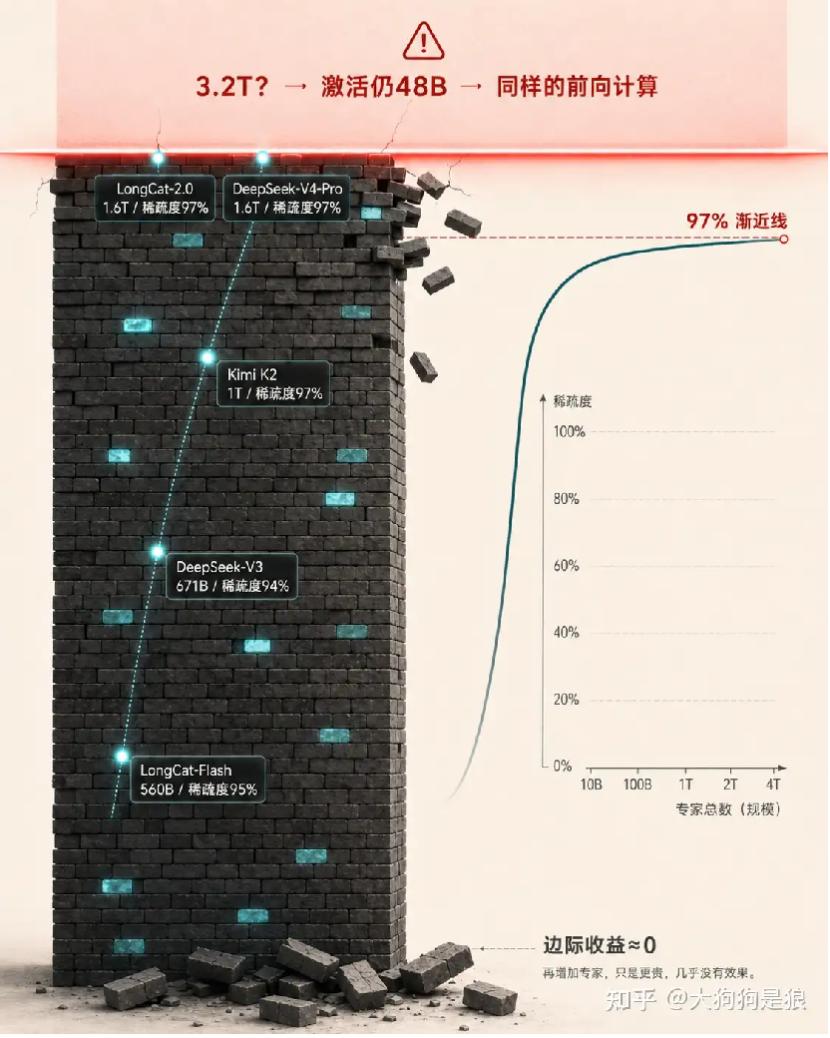
做个极端化的反事实推演就明白这句话在说什么了。假设LongCat把专家池再扩一倍到3.2T总参数,按97%的稀疏度,每个token激活的还是那48B,用贵一倍的硬件、占一倍的显存,跑出来的前向计算和现在一模一样。这是“花钱买了个寂寞”。MoE的本质是用一个路由器给每个token挑专家,专家越多、每个token只激活其中一小撮,真正参与计算的参数占总参数的比例就越低。当这个比例低到3%以下,再加专家,相当于往一个已经足够大的仓库里继续塞书,但每本书被翻到的概率越来越低。与其继续扩专家池,不如去注意力机制、上下文效率、后训练数据这些维度上找增量。
这恰恰是LongCat-2.0做的事。它引入了LongCat Sparse Attention(LSA),官方说法是,这是DeepSeek Sparse Attention(DSA)的演进版,并把改进策略扩展到了3-step Multi-Token Prediction模块用来加速投机解码。再加上N-gram Embedding、Muon优化器、6D并行训练、MOPD多目标后训练这套组合拳,整个架构的重心已经从“更大的专家池”转向“在固定专家池上榨取更多效率”。
04
OpenRouter匿名测试和调用量
聊完技术,聊点更实在的。
假设你是一个天天用Claude Code写代码的开发者,某天在OpenRouter上发现一个叫“Owl Alpha”的模型,免费、速度快、代码补全出奇地顺手,你就这么用了一个多月。直到6月29日,链上消息突然揭晓:这只“猫头鹰”其实是美团LongCat-2.0-Preview,1.6T总参/48B激活,月token吞吐量11万亿。
这才是模型极有说服力的“跑分”。传统的评测套路是拿一堆公开题库,MMLU、HumanEval、SWE-Bench,跑分排序。但这套东西不乏刷榜的情况在。而OpenRouter的调用量是真金白银的token消耗,是开发者在完全不知道这是谁家模型的情况下,用它写代码、调工具、跑agent,用脚投出来的票。截至6月底这个匿名模型总调用量跻身全球前三,在Hermes这个harness上月调用全球第一,在Claude Code上月调用全球第二,仅次于Claude Opus本身。

Claude Code月调用全球第二这个位置尤其值得琢磨。Claude Opus 4.8是Anthropic今年6月初刚发的旗舰,在agentic coding这个赛道上是事实上的标杆,Kimi K2.7 Code在Kimi Code Bench v2上拿了62.0分,离Opus 4.8的67.4分还有半代差距。一个中国公司匿名挂出来的模型,能在Claude自己的生态里被调用到全球第二,说明LongCat-2.0在让模型自主理解仓库结构、处理多文件依赖、给出能直接落地的工程方案这件事上,确实打到了开发者的真实痛点。这也是为什么DMXAPI等平台第一时间上线适配,卖点直接就是“仓库级代码理解与端到端任务执行”。
但这里有一个绕不开的问题,也是Reddit上r/LocalLLaMA吵得比较凶的点。一条49分的高赞评论直接质疑:“All those parameters to not be SOTA. Makes you appreciate what z.ai pulled off.(堆了这么多参数还没做到SOTA,反衬出智谱GLM-5.2的含金量)”另有用户实测反馈,在纯coding场景下“大概和Nemotron Ultra 500B一个水平,一直比GLM-5.1差”。还有一条更尖锐的,认为LongCat-2.0“基本就是DeepSeek-V4-Pro的配方,像是带轻微改动的复现验证”。
从公开信息看,LongCat-2.0和DeepSeek-V4-Pro确实共享同一代MoE范式,都是1.6T/48~49B/1M上下文/97%稀疏度,注意力机制也都是DSA家族的演进(DeepSeek往CSA/HCA走,美团往LSA走)。说它是“复现”不算冤枉。但“复现”这件事在万亿参数加国产算力的组合下,本身就是一种工程能力证明,能在5万张昇腾上把一个已知的架构配方稳定跑通到收敛,这和拿H100集群照着论文复现,是两个难度量级的事。
至于它更独特的实力,在后训练数据和工具适配里,美团做外卖、到店、骑手调度积累了大量真实业务场景的agent数据,这才是它在agentic coding调用量上能跑赢一众跑分更高模型的底气。基础模型能力vs后训练能力的功劳怎么拆,目前公开信息还拆不开,得等权重放出来让社区做消融实验。
05
2026年中期竞品对比
最后聊聊对行业的影响。
要理解LongCat-2.0的位置,得先看清楚2026年6月这个时间点上,大模型第一梯队的格局。我把公开信息整理成一张认知地图:
DeepSeek代表”长上下文效率+高强度推理后训练”路线。从V3的671B/37B、到V3.2引入DSA、再到V4-Pro的1.6T/49B和1M上下文,主线是在大MoE上压低长上下文的注意力和缓存成本——V4-Pro的1M场景下单token推理FLOPs只有V3.2的27%,KV Cache只有10%。
智谱GLM-5.2是744B总参/40B激活,也用了DSA加IndexShare加MTP的架构组合,1M上下文,在第三方评测里编程能力稳居国产第一梯队。
阿里Qwen3.7-Max在SWE-Bench Pro上拿到60.6分国内第一,但Reddit上有个500多分的热帖直言”阿里永远不会开源Qwen 3.7”。
Kimi K2.7 Code走的是约1T总参/32B激活的固定底座上加coding-first后训练,比K2.6少约30%的thinking token,在MCP工具调用基准上81.1分超过了Claude Opus 4.8。
MiniMax M3在编程修复质量上和Kimi共同领跑。

这张牌桌上有几个特征非常明显。
1.总参数继续膨胀,但激活预算被死死压住。1T、1.6T越来越常见,但每token激活参数还是集中在30B到50B这个带状区间,没有人去卷”2T总参数激活200B”这种东西。
2.长上下文竞争从窗口大小转移到了注意力/缓存效率。1M已经不稀奇,真正较劲的是DSA、LSA、CSA/HCA这些稀疏注意力机制,看谁能把百万token的推理成本压到可商用。
3.agent能力,尤其是agentic coding,成了新的角力点。光会做题不够,得能在真实代码仓库里端到端干活。
LongCat-2.0在这个格局里占的位置有点特别。它没有在参数榜上拿第一,也没有在跑分上碾压谁,但它同时攥着两牌:一个完全跑在国产算力上的万亿开源模型,和在agentic coding实际调用量上证明了商业价值的中国模型。前者是供应链层面的护城河,在地缘政治不确定性持续的情况下,这个属性的溢价只会越来越高;后者是产品层面的验证,说明美团没有把大模型当”技术展示”在做。定价上longcat.ai挂的是9.9元5000万token、399元10亿token这个档位,延续Flash时代把成本打下去的打法,对比Claude Opus 4.8动辄几十美元的月费,这个价格差本身就是它能在OpenRouter上吃到那么大调用量的一部分原因。
但开源的真正价值,得看权重放出后的社区生态。vLLM、llama.cpp、sgLang这些推理框架的支持程度,量化方案的成熟度,可复现的第三方评测,这些才决定一个开源模型是“真开源”还是“开源个寂寞”。LongCat-Flash时代美团在这块做得不错,560B模型有完整的HuggingFace权重和GitHub代码。2.0的1.6T体量对社区是个更大的挑战,光是把权重下载下来跑起来,就不是普通开发者能玩得转的。Reddit上那个“Think a 3060 will be enough to run this??”的27分玩笑帖,背后是开源大模型“叫好不叫座”的真实困境,1.6T参数Q4量化后还要1TB内存,能本地部署的人,本身就不缺云上API的预算。
至于它对整个AI行业的影响,我的判断是:LongCat-2.0没有独力改变技术路线的走向,但它和DeepSeek-V4、GLM-5.2、Kimi K2.7一起,把“万亿参数加国产算力加开源”这个组合从“实验室demo”推到了“工业级可用”。这个变化的真正受益者,是整个需要算力自主、需要可负担的agentic能力、需要不被单一供应商锁定的中国AI产业。王兴过去两年喊“在AI领域唯一的策略是进攻”,2025年美团研发投入260亿元同比增长23.5%,LongCat-2.0算是这种进攻姿态在基础模型层面交出的一份答卷。
大胆预测一句:如果LongCat-2.0的权重在7月真能放出来,且vLLM和llama.cpp在两周内完成适配,它在OpenRouter上的调用量大概率会在Q3冲到更靠前的位置。靠的不一定是技术比DeepSeek-V4强,而是它免费、能用国产卡跑、还背靠美团的真实业务数据。当一个开源模型同时占了“便宜”和“能跑”这两个属性,调用量这东西,有时候比跑分诚实得多。
真正值得持续关注的问题,反而不在LongCat-2.0身上。当MoE稀疏度已经摸到97%这条渐近线,当所有头部玩家都在1.6T/48B这个区间贴身肉搏,下一轮突破会从注意力机制来,从训练数据配方来,还是从某种我们现在还没看到的全新架构来?美团把这个问题用97%这个数字摆到了台面上,但整个行业,包括美团自己,都还没给出答案。


