

图片来源:Google DeepMind
今年3月,谷歌展示了其首个Genie AI模型。该模型经过数千小时的2D跑跳类视频游戏训练后,能够根据通用图像或文本描述生成半可接受的互动场景。
九个月后,本周发布的Genie 2模型将这一理念扩展到完全3D世界的领域,并配备了可控的第三人称或第一人称角色。谷歌在公告中强调了Genie 2作为“基础世界模型”的角色,能够创建一个完全互动的虚拟环境内部表示。谷歌表示,这可以让AI代理在合成但逼真的环境中进行自我训练,是迈向人工智能通用智能的重要一步。
尽管Genie 2展示了谷歌DeepMind团队在过去九个月中取得的显著进步,但目前公开的信息有限,仍让人对这类基础模型世界除了短暂而精彩的演示外还能有何用处充满疑问。
你的记忆力能持续多久?
与原始的2D Genie模型类似,Genie 2从单个图像或文本描述开始,然后根据前一帧和用户的新输入(如移动方向或“跳跃”)生成后续视频帧。谷歌表示,该模型经过“大规模视频数据集”的训练才实现了这一点,但它没有透露与训练首个Genie所需的30,000小时素材相比,需要多少训练数据。
谷歌DeepMind宣传页面上的简短GIF演示显示,Genie 2被用于为从木偶到复杂机器人再到水面上的船只等各种角色制作动画。这些GIF中展示的简单交互展示了这些角色戳破气球、爬梯子以及射击爆炸的桶,而无需任何明确的游戏引擎来描述这些交互。
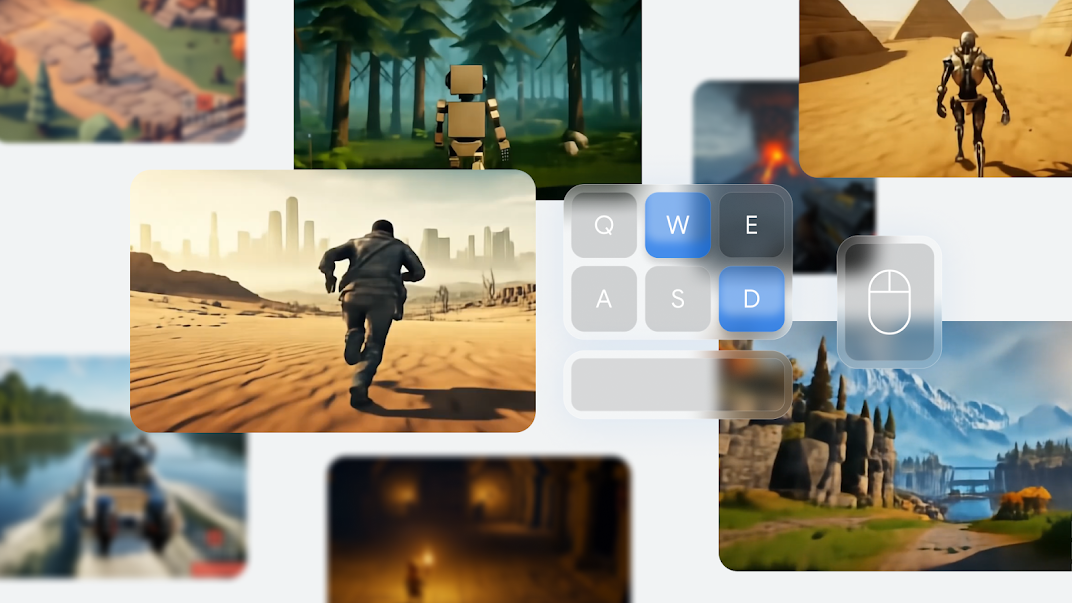
这些由Genie 2生成的金字塔在30秒后仍然存在。但五分钟后呢?
图片来源:Google DeepMind
谷歌宣称的最大进步可能是Genie 2的“长时记忆”。此功能允许模型记住超出视野范围的世界部分,然后根据角色移动在重新进入画面时准确渲染它们。这种持久性已被证明是Sora等视频生成模型的一个持续存在的问题,OpenAI在2月表示,这些模型“并不总是产生正确的对象状态变化”,并且可能在“长时间样本中发展出不连贯性...”。
“长时记忆”中的“长时”部分可能有些夸大,因为Genie 2只“保持世界的一致性长达一分钟”,而“所展示的大多数示例持续时间[为10到20秒]”。在AI视频一致性领域,这无疑是令人印象深刻的时间范围,但与任何其他实时游戏引擎相比仍有很大差距。想象一下,你在《天际线》风格的RPG中进入一个城镇,五分钟后回来却发现游戏引擎忘记了那个城镇的样子,而是从头开始生成了一个完全不同的城镇。
我们到底在原型设计什么?
或许正因如此,谷歌建议,就目前而言,Genie 2对于创造完整的游戏体验用处不大,而更多地用于“快速原型设计多样化的互动体验”或将“概念艺术和绘图...转化为完全互动的环境”。
将静态“概念艺术”转化为轻度互动的“概念视频”的能力对于视觉艺术家为新游戏世界集思广益确实很有用。然而,对于原型设计超越视觉的实际游戏设计,这类AI生成的样本可能用处不大。
英国游戏设计师萨姆·巴洛(Sam Barlow,曾参与《寂静岭:破碎的记忆》和《她的故事》)在Bluesky上指出,游戏设计师经常使用一种称为白盒的过程,在游戏世界的艺术愿景确定之前很久就用简单的白色盒子来布局游戏世界的结构。他说,这个想法是“证明并创建以游戏玩法为先的游戏版本,我们可以锁定这个版本,以便艺术团队可以在结构上添加昂贵的视觉效果。我们使用低保真度构建,因为它允许我们专注于这些问题并以低廉的成本进行迭代,以免在无法纠正时走得太远”。
在设计底层结构之前,使用像Genie 2这样的模型生成复杂的视觉世界,感觉有点像本末倒置。这个过程似乎旨在生成通用的、“资产翻转”风格的世界,其中AI生成的视觉效果掩盖了通用的交互和架构。
播客主持人Ryan Zhao在Bluesky上表示,“当你需要原型设计的是‘如果有一个空间会怎样’时,设计过程就出了问题”。
必须加快速度
当谷歌在今年早些时候公布Genie的第一个版本时,还发布了一篇详细的研究论文,概述了训练该模型所采取的具体步骤以及该模型如何生成互动视频。对于详细阐述Genie 2过程的研究论文,他们并未这样做,因此我们只能猜测一些重要细节。
这些细节中最重要的之一是模型速度。首个Genie模型以大约每秒一帧的速度生成其世界,这一速度比可容忍的实时播放速度慢了几个数量级。对于Genie 2,谷歌只说“本博客文章中的样本是由未提炼的基础模型生成的,以展示其可能性。我们可以以降低输出质量的方式实时播放提炼后的版本”。
从字里行间可以读出,完整的Genie 2版本的操作速度远低于那些炫目的GIF所暗示的实时交互。目前尚不清楚将模型的稀释版本变为实时控制需要“降低多少质量”,但鉴于谷歌没有提供示例,我们不得不假设这种降低是显著的。
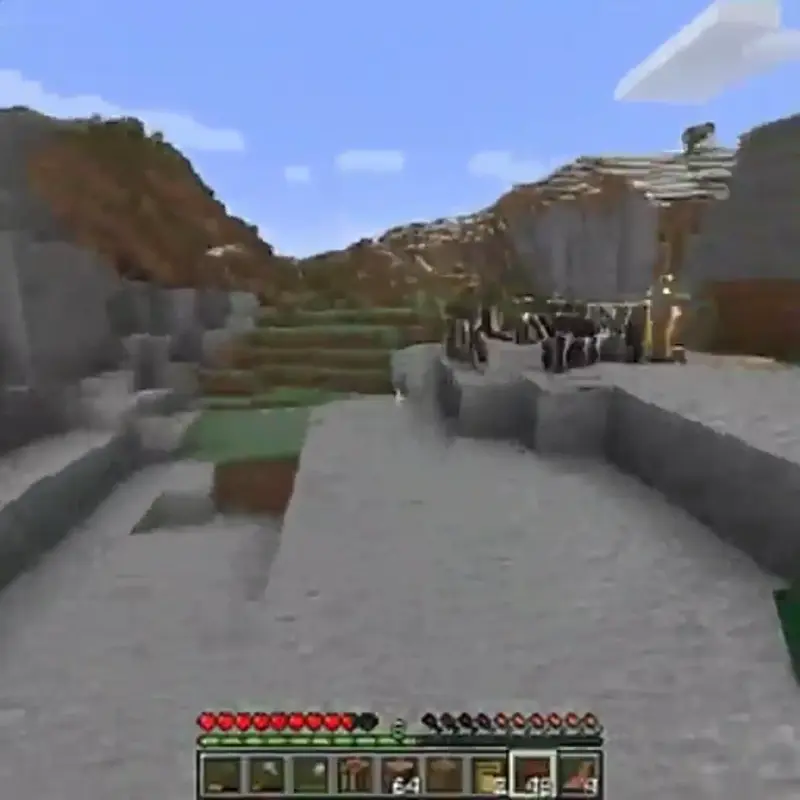
Oasis的AI生成的《我的世界》克隆版显示出巨大潜力,但仍有很多不足之处,可以这么说。
图片来源:Oasis
实时、互动的AI视频生成并非遥不可及。今年早些时候,AI模型制造商Decart和硬件制造商Etched发布了Oasis模型,展示了人类可控的、AI生成的《我的世界》视频克隆版,该版本以完整的每秒20帧的速度运行。然而,这个拥有5亿参数的模型是通过对单个相对简单的游戏的数百万小时素材进行训练而得到的,并且专注于该游戏所固有的有限动作集和环境设计。
Oasis发布时,其创造者完全承认该模型“在领域泛化方面存在困难”,展示了为了取得良好效果,如何将“逼真”的开场场景简化为简单的《我的世界》方块。即使有这些限制,也不难找到Oasis在播放几分钟后退化成恐怖噩梦素材的片段。

在这个Genie 2演示中,一个看似逼真的士兵在几秒钟后就退化成了一个模糊的团块。
图片来源:Google DeepMind
在Genie团队分享的极短GIF中,我们已经可以看到类似的退化迹象,例如角色在高速移动时的梦境般模糊,或在短距离内非玩家控制角色迅速退化为未分化的团块。对于一个“长时记忆”本应是其关键特征的模型来说,这不是一个好兆头。
其他AI代理的学习摇篮?

根据这张图片,Genie 2可以生成一个对AI代理有用的训练环境和一个简单的“选择一扇门”任务。
图片来源:Google DeepMind
Genie 2似乎以单个游戏帧为基础来制作模型中的动画。但它似乎也能够推断出这些帧中对象的一些基本信息,并以游戏引擎可能的方式与这些对象进行交互。
谷歌的博客文章展示了如何将一个SIMA代理插入到Genie 2场景中,使其能够遵循“进入红色门”或“进入蓝色门”等简单指令,并通过简单的键盘和鼠标输入控制角色。这可能使Genie 2环境成为各种合成世界中AI代理的绝佳测试平台。
谷歌颇为夸大地声称,Genie 2使其走上了“解决具身代理安全训练的结构性问题,同时实现向[人工智能通用智能]迈进所需的广度和通用性”的道路。无论这是否最终成真,近期的研究表明,从基础模型中获得的代理学习可以有效地应用于现实世界中的机器人技术。
使用这种AI模型为其他AI模型创建学习世界可能是这种技术的最终用例。但当我们梦想着一个AI模型能够创建人类玩家可以实时探索的通用3D世界时,我们可能还没有想象中那么接近这个目标。
