

你以为大模型已经能轻松“上网冲浪”了?
新基准测试集BrowseComp-ZH直接打脸主流AI。
BrowseComp-ZH是一项由港科大(广州)、北大、浙大、阿里、字节跳动、NIO等机构联合发布的新基准测试集,让20多个中外主流大模型集体“挂科”:
GPT-4o在测试中准确率仅6.2%;多数国产/国际模型准确率跌破10%;即便是目前表现最好的OpenAI DeepResearch,也仅得42.9%。
目前,BrowseComp-ZH的全部数据已开源发布。

研究团队直言:

为什么我们需要中文网页能力测试?
如今的大模型越来越擅长“用工具”:能连搜索引擎、能调用插件、能“看网页”。
但众多评估工具都只在英文语境下建立,对中文语境、中文搜索引擎、中文平台生态考虑甚少。
然而,中文互联网信息碎片化严重、搜索入口多样、语言表达复杂。
中文网页世界到底有多难?举几个例子你就明白了:
信息碎片化,分散在百度百科、微博、地方政府网站、视频号等多平台
常见的语言结构中含有省略、典故、代指,关键词检索常常“跑偏”
搜索引擎本身质量参差,信息“沉底”或“走丢”都是常事
因此,英文测试集“翻译一下”根本不够。
需要从中文语境原生设计,才能真正衡量大模型是否能在中文网页上“看得懂”、“搜得到”、“推得准”。
BrowseComp-ZH是怎么炼成的?
研究团队采用了“逆向设计法”:从一个明确、可验证的事实答案出发(如某个画种、机构、影视剧名),反向构造出多个约束条件的复杂问题,确保以下三点:
百度/Bing/Google三大搜索引擎首屏无法直接命中答案
多个主流大模型在检索模式下也无法直接答对
经过人工验证,问题结构清晰,且仅有唯一答案
最终,他们构建了289道高难度中文多跳检索题目,覆盖影视、艺术、医学、地理、历史、科技等11大领域。

大模型集体“翻车”?DeepResearch勉强破四成,绝大多数连10%都不到
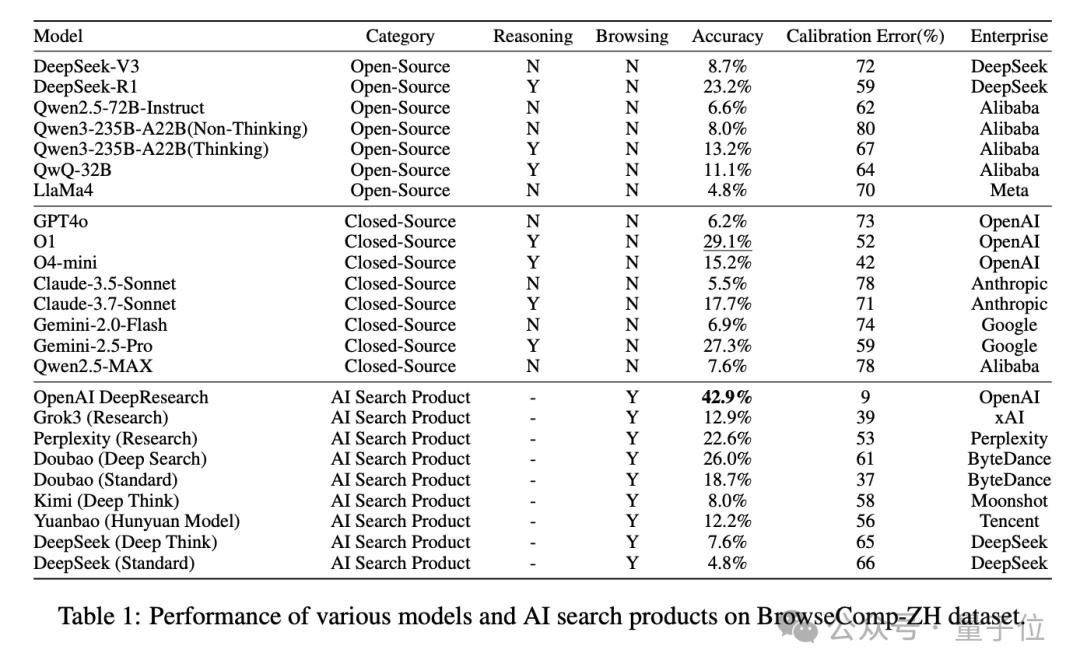
在BrowseComp-ZH的测试下,多款国内外主流大模型集体“翻车”:
尽管这些模型在对话理解、生成表达方面已展现强大实力,但在面对中文互联网的复杂检索任务时,准确率普遍低得惊人:
多数模型准确率低于10%,仅少数能突破20%
OpenAI DeepResearch以42.9%位列第一,仍远未“及格”
研究者指出,这一结果说明:模型不仅需要会“查资料”,更要会“多跳推理”与“信息整合”,才能在中文互联网中真正找到答案。
四大发现,揭示中文网页任务的“模型死角”
1. 仅靠记忆不行,得真本事
纯靠参数记忆(无搜索)的模型准确率往往低于10%,说明“硬背”不靠谱。
2. 有推理的模型,表现更好
DeepSeek-R1(23.2%)比DeepSeek-V3(8.7%)整整高出14.5%,Claude-3.7也比Claude-3.5提升了12.2%,推理能力成为关键变量。
3. 搜得多 ≠ 搜得准,多轮策略才是王道
具备多轮检索能力的AI搜索产品全面胜出:
DeepResearch:42.9%
豆包Deep Search:26.0%
Perplexity Research模式:22.6%
相比之下,只检索一次的模型(如Kimi、Yuanbao)准确率低至个位数。
4. 搜索功能“翻车”?接入反而变差
最典型的反例是DeepSeek-R1,开启搜索功能后准确率从23.2%断崖式跌至7.6%。
研究指出,模型未能将网页检索信息与已有知识有效融合,反而被误导。
数据集开放!欢迎模型开发者挑战
BrowseComp-ZH的全部数据已开源发布。
研究者希望此基准测试能成为推动LLM在中文信息环境落地的试金石,助力构建真正“会用中文上网”的智能体。
下一步,他们计划扩充样本规模,拓展问答形式,并深入分析模型推理路径与失败案例。
论文地址:https://arxiv.org/abs/2504.19314
代码地址:https://github.com/PALIN2018/BrowseComp-ZH
