
听雨 发自 凹非寺
量子位 | 公众号 QbitAI
模型搞不出起色,小扎开始盯上基础设施了。
起因是Meta遭受了接二连三的打击:Gemini模型被限制使用、小扎承认内部AI agent技术推进比预期慢、员工士气跌到20年谷底……
总之真是流年不利。
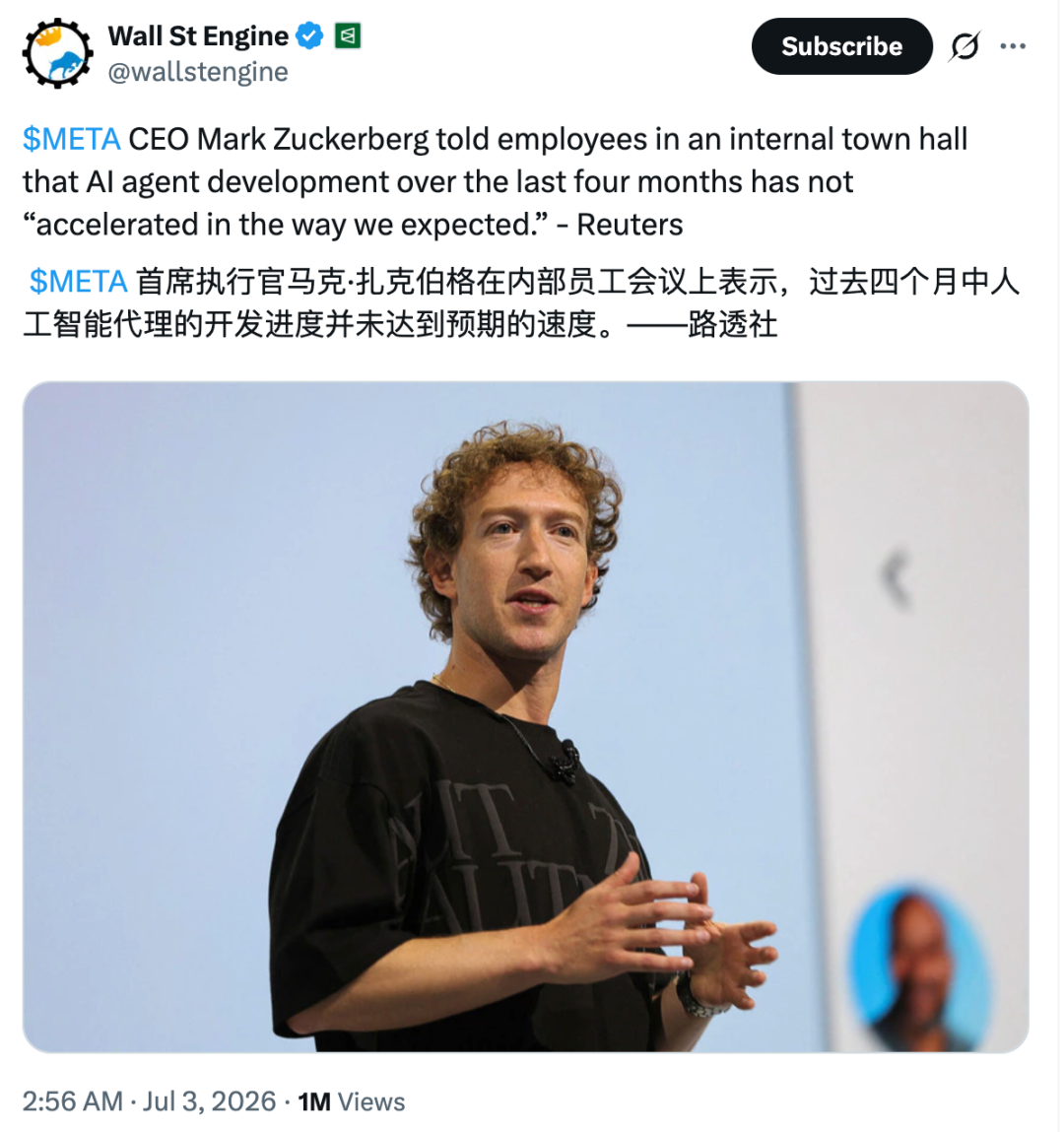
但是没关系,小扎灵光一闪,又有了Plan B。
既然自研模型赶不上,那咱可以卖GPU啊!!
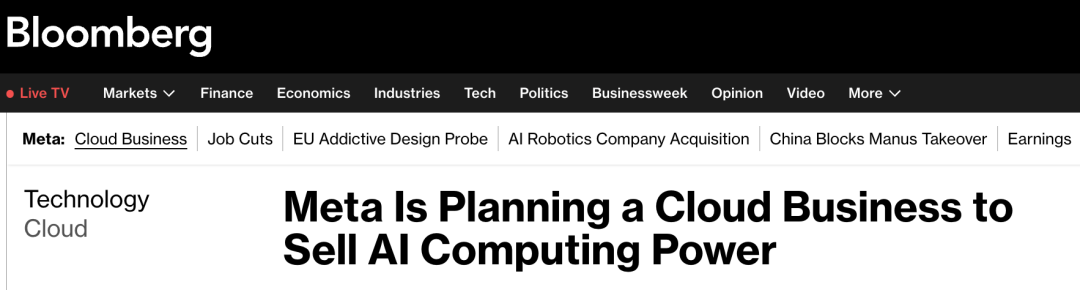
据彭博社报道,Meta正考虑推出Meta Compute,把庞大的AI基建开放给外部客户。
好家伙,果然都是卖铲子的天下…
Meta要卖GPU了
既然要卖铲子,那么Meta手里有多少铲子?
据SemiAnalysis报道,Meta的数据中心和算力采购不但不会放慢,反而还会继续加速。
仅今年前6个月,Meta就已经在云和托管数据中心上签下了超过5GW的容量。这还不包括它正在加速推进的自建数据中心。
Meta正在建设中的两个最大数据中心园区,加起来就代表了2.5GW的容量。
而从2024年初以来,Meta签下的数据中心和算力相关交易,也已经接近10GW。
地图上这些密密麻麻的点位,就是小扎卖GPU的底气。
这堆算力有几个去向:
第一,继续喂给自家模型,比如亚历山大王的MSL已经推出的Muse Spark,以及正在训练中的下一代模型Watermelon。
第二,用在广告推荐系统上。SemiAnalysis认为,Meta可能希望把广告推荐系统的复杂度再放大10倍,用更多训练和推理算力提升广告收入。
第三,做类似SpaceX的neocloud交易,把一部分算力以高价租给外部客户。
如果按SpaceX那类高算力租赁合同来算,每GW年收入可达约500亿美元。
Meta只要拿出200MW算力给外部客户,就能带来100亿美元年收入,而且是超高利润率。
啧啧,这油水是真不少~

而且SpaceX开创了一种新模式:合同三年,但双方都可以在90天内取消——实际上相当于3个月一签,自动续约。
这意味着Meta可以随时把算力收回来给MSL用。
第四,托管第三方模型。
SemiAnalysis甚至判断,Meta正在与Anthropic进行最终谈判,以获得Claude的私有实例访问权。
未来,Meta会做类似Amazon的Bedrock、Microsoft的Foundry、Google的Vertex这样的模型服务平台。
也就是说,Meta可以把Claude这类第三方模型部署在自己的基础设施上,再打包卖给企业客户。
对Meta来说,这至少有三层用途:
第一,当然是内部使用。
Google刚刚限制了Meta对Gemini的使用,而Meta可能反手就把Claude作为替代。
毕竟Meta自己的AI项目需要大量高质量模型token。
而Claude也正好是目前最强的模型之一。

二是对外销售。Meta可以像亚马逊的Bedrock一样卖Claude-as-a-service。
客户不用自己找Anthropic签约、部署、运维,只要通过Meta的平台调用模型就行。
三是垂直应用。Meta可以利用自己的广告平台,构建销售与营销SaaS,集成前沿AI Agent。
SemiAnalysis预计,Meta可能很快宣布类似协议,Anthropic就是头号对象,但OpenAI或Google也可能加入。
如果Meta的算力业务成形,那么它的对手就不只是OpenAI、Anthropic、Google这些模型公司了。
它还会站到AWS、Azure、Google Cloud,以及CoreWeave、Nebius这些AI云厂商对面。
消息一出,资本市场也立刻闻风而动。
Meta股价大涨近9%,而CoreWeave、Nebius这些 neocloud公司则遭遇抛售。
华尔街显然听懂了小扎的新故事:
虽然咱模型还没赢,但GPU可以先赚钱啊!
为啥要卖算力:搞模型太烧钱
小扎从模型转向卖铲子,最直接的原因是:
研发模型,真的太烧钱了!!!
Meta官方给出的2026年资本开支指引,已经上调到1250亿-1450亿美元。
作为对比,Meta今年一季度的资本开支就已经达到198.4亿美元。
但是反观Meta的模型进度,不禁让人捏了一把冷汗:
Llama系列开源,生态影响力很大,但也很难直接转变成收入。
而Meta最新的自研模型Muse Spark,也还没有真正把Meta送回第一梯队。
现在Meta内部又在训练下一代模型Watermelon(西瓜),据称算力投入比Avocado高一个数量级。
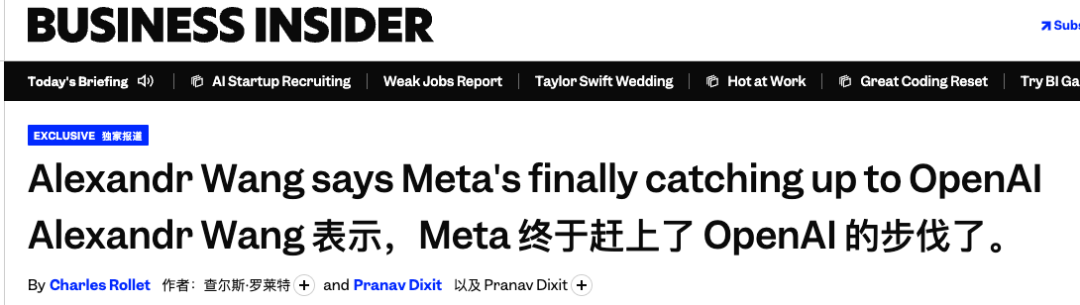
亚历山大王表示:大家别着急,Watermelon已经赶上GPT-5.5的水平了。

同时,Muse Spark当前的版本也即将更新,在编程能力和智能体方面将取得重大提升。
当用户问Meta什么时候能推出与Claude Opus旗鼓相当的模型时,王表示:
很快就会了!
(小王你别说了,你倒是发呀)
说到底,Meta的AI雄心一直围绕着一个简单目标展开:
追上OpenAI、Anthropic和Google。
为此,小扎没少砸钱。芯片、数据中心、人才,几乎样样都按最高规格投入。
但问题是,钱砸下去了,Meta还没能真正说服开发者和客户,让他们相信自家模型已经站上行业最前沿。
当模型进度无法立刻兑现,算力就成了最容易被华尔街理解的资产。
因为GPU和数据中心至少可以被定价。
这些资源可以出租,可以托管模型,可以卖API,可以服务广告主,可以做AI agent SaaS,也可以在内部继续提升广告推荐系统。
就好比,原本Meta是在向市场讲一个很远的故事:
相信我,我们会做出超级智能。
但现在这故事听起来近多了:
就算超级智能没那么快出来,这些GPU也不是沉没成本。
当然,卖算力不代表Meta放弃自研模型。小扎的Plan A依然是超级智能。
继续抢人,继续堆卡,继续训练更大的模型,继续追赶御三家。
在追求ASI的路上,小扎永不言败!
只不过,前沿模型竞争的不确定性太高,中途总得难免妥协亿下下~


