
作者|黄楠
编辑|袁斯来
6月24日,通用具身智能企业RoboScience机器科学通用具身大模型发布,首次完整披露自研Visics大模型的技术架构VLOA(Vision-Language-Object-Action),并展示了模型在家具拼装、灵巧抓取、动态流水线等多项真实场景的应用。
大语言模型有标准的文本Token,自动驾驶有统一的视觉或点云表征,这些基础格式的确定,让数据和模型可以在不同场景之间复用。但具身智能至今没有一个被行业公认的基础表征单元,其决定了数据如何采、模型从哪学、以及学习后是否能迁移至新场景。
过去两年,行业主流做法是让模型直接学习机器人的关节运动轨迹,即复刻某一个特定硬件在特定任务下的动作坐标。这套逻辑的问题在于,换一台机器人、换一个物体、换一个场景,模型此前所习得能力无法直接迁移复用。它学会的是“夹爪怎么抓起杯子”,而非理解“抓取”这个动作本身,即什么是抓、需要多大的力、物体受力后会怎么反应。
RoboScience机器科学创始人兼CEO田野指出,当前机器人操作面临泛化能力差、精细操作难、长程任务误差累积三大核心瓶颈。为此,团队选择从底层出发,搭建一套全新的具身基础表征单元。

RoboScience机器科学创始人兼CEO田野(图源/企业)
作为整套技术体系的核心底座,RoboScience机器科学自研了Visics通用具身大模型,提出Object Trajectory(物体3D点云轨迹)统一中间表征标准,以此搭建分层解耦的VLOA架构,围绕物体为中心,重构机器人的认知与执行逻辑。
田野解释称,“Object这个词同时包含物体、目标两层含义,能够精准定义机器人与物件的交互关系,以及操作后物体需要达成的运动变化状态。”
Visics通用具身大模型内部采用双引擎架构,由具身世界模型和通用操作模型各自独立运转,分开预训练、分别迭代,互不干扰。其中,具身世界模型以海量互联网视频作为预训练数据,围绕物体状态、三维轨迹、接触力与物理因果关系建模,学习物体在真实世界中的运动规律。
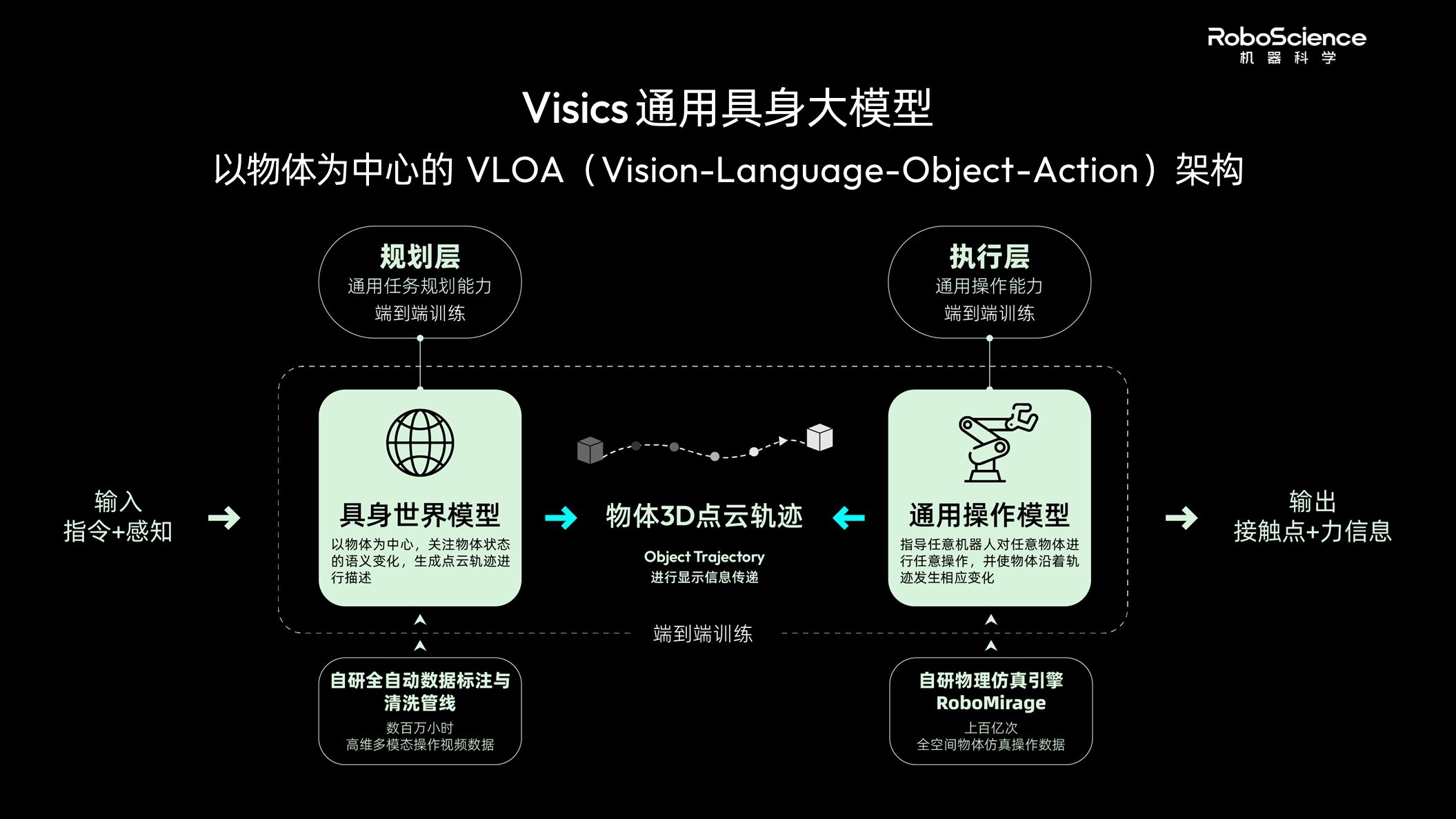
Visics通用具身大模型,VLOA架构(图源/企业)
通用操作模型则负责把“物体运动轨迹”转化为“机器人该怎么做”。它通过物理引擎生成大规模仿真数据持续迭代,能够操作刚体、铰链件、软质可形变体等各类物体,支持跨本体部署与闭环控制,同时兼容视觉、触觉、力觉等多模态感知输入。
两大引擎通过VLOA架构完成分层协同,Object Trajectory作为统一中间接口,上层具身世界模型负责预判、推演物体合理运动轨迹,下层通用操作模型给出适配各类机器人的硬件控制指令、负责落地执行轨迹。
这种分层解耦的设计,最终实现三大维度的全域泛化,适配任意机器人本体、操作任意类型物体、自主完成多样化任务。以抓取动作为例,对比传统绑定单一机械臂、单一物件的训练方案,基于VLOT架构的模型在抓取成功率、操作姿态丰富度、运算响应速度上均有明显提升。

搭载Visics通用具身大模型的机械臂执行拼家具任务(图源/企业)
在具身智能领域,数据是模型能力的根基,但传统数据路线正面临成本与产能的双重天花板。
RoboScience机器科学以自研高精度仿真引擎RoboMirage为核心,结合全自动视频数据标注与清洗管线,构建了一套“仿真+视频”双数据飞轮。这套体系可将单条数据的获取成本压至传统方案的1/20至1/200,并以每周数十万小时的速度持续扩张,预计2026年将构建超过1T高质量manipulation操作轨迹数据集。

RoboScience机器科学联合创始人汪涛(图源/企业)
自成立以来,RoboScience机器科学已获得京东集团、商汤科技、达晨财智、招商局创投、零一创投、普华资本等多家CVC和财务机构的投资及产业支持,在北京、深圳、苏州、杭州设有研发和生产中心。公司以大模型为核心,纵向打通自研本体、控制器与RobotOS,横向构建模型泛化、便捷开发与多层级生态,搭建软硬一体、闭环协同的商业模式。
联合创始人汪涛指出,具身智能真正的规模化落地尚未到来,公司选择先从物体维度切入,即解决对刚性、柔性及各种属性物体的泛化操作能力,而非直接进入工业场景与自动化方案竞争。如商超、电商物流等场景,天然面临海量SKU、多品类的拣选与补货需求,正是验证物体维度泛化能力的最佳试验场。
目前,RoboScience机器科学已同多家零售、物流、康养服务企业及机器人本体、灵巧手公司开展试点合作,计划于今年实现面向工业与商业场景的标准化机器人本体产品量产。


