
前不久,Anthropic 停止允许订阅用户通过 OpenClaw 等第三方工具接入 Claude API。理由并不复杂,一个OpenClaw 代理运行一天,消耗的算力成本在1000美元到5000美元之间,而用户每月只付了200美元。
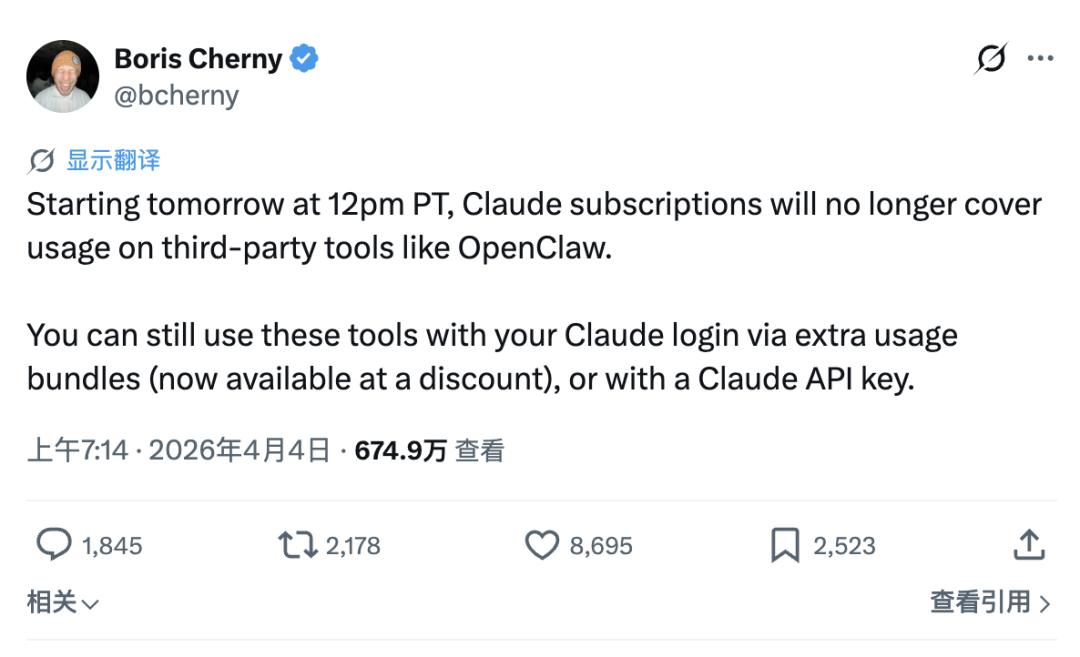
Claude Code 负责人 Boris Cherny在 声明里说,订阅服务“并非为这些第三方工具的使用模式而设计”。这句话没有错,但它遮住了一个更基础的问题:没有任何订阅服务能被设计成覆盖这种使用模式。Agent 场景下的 Token 消耗量没有上限,也没有历史数据可以参考,任何固定月费都是在对一个无法建模的变量做猜测。
3月底,中国国家数据局公布了另一组数字:中国日均 Token 调用量突破140万亿,两年增长超千倍。同期,字节的 Token 调用量跻身全球三甲,与 OpenAI、谷歌并列。无问芯穹CEO 夏立雪在一场行业论坛上描述这个增速时说,上一次看到类似的曲线,是3G时代手机流量从每月100MB开始普及的时候。当时没有人预料到,流量放开之后会跑出抖音、微信和外卖。
两件事放在一起,描述的是同一个现实:Token的消耗正在以罕见的速度增长,但支撑整个行业运转的定价逻辑,依然建立在两年前聊天机器人时代的假设之上,即用户的使用量是可以被历史数据预测的,轻度用户会自然地覆盖重度用户,整体成本可以被摊平。
智能体们打破了这个假设的每一个前提,市场变化的速度,超过了任何定价模型的响应能力。纵观过去两年 Token 市场的演化,每一个优势窗口的终结,都由同一个逻辑驱动,即当竞争者能够复制优势——规模可以被追赶,算法可以被开源,场景可以被大平台的分发能力碾压。
目前唯一难以被快速复制的,是将 Token 效率内化为产品架构、定价逻辑和工程文化的能力。而在这件事上真正做到体系化的,只有 Anthropic。
失去意义的平均价格
Token 之所以不同于电力、钢铁等传统生产要素,在于它具备独一无二的“可编程性”。没有任何一种传统生产要素,能仅凭“指令不同”就将自身价值改变十万倍。这种可编程性,是 Token 作为新型生产要素的本质特征,也是理解当前 AI 经济混乱的前提。
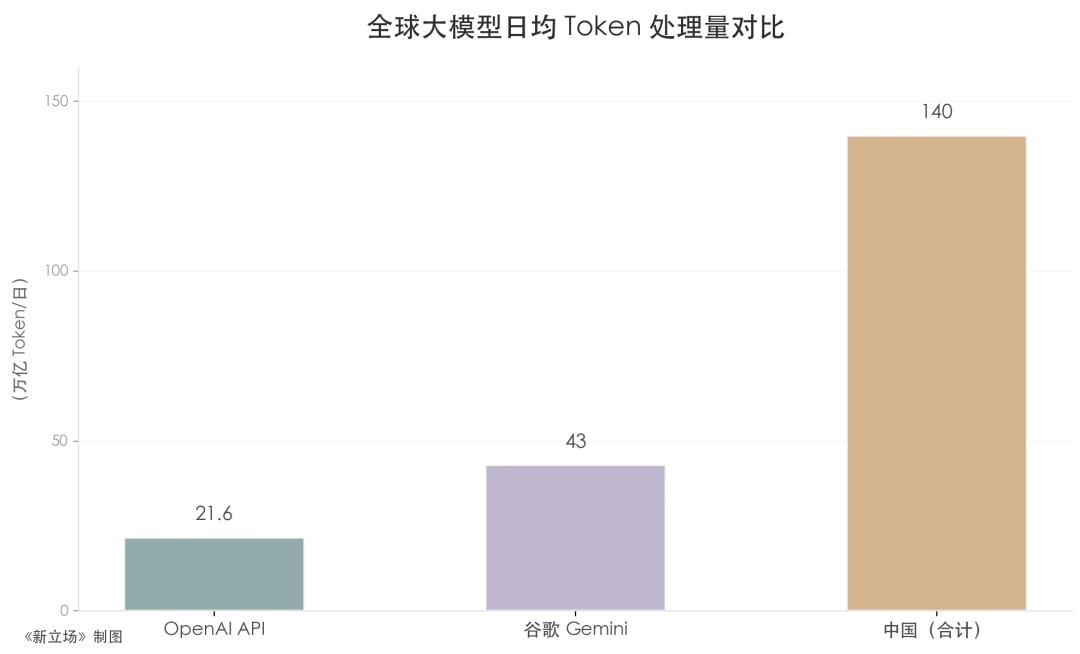
理解这一点,需要先建立量级感。36氪报道,OpenAI API 日均处理约21.6万亿 Token,谷歌Gemini 日均约43万亿,而中国的140万亿约为前两者之和的两倍有余。摩根大通预测,仅中国的AI推理 Token 消耗,就将在五年内再增370倍。这个量级本身说明了,Token 已经是一个经济规模指标。
此外,Token 的大量消耗使用发生在公有云的统计口径之外。金融机构在本地服务器上跑票据识别,车端智能座舱的对话在车内闭环完成,工业机器人的视觉模型以毫秒级响应运行在边缘设备上,这些都不会出现在任何公开数据里。一位从业者估算,非公有云API的调用量至少是公有云的五到十倍。
规模之外,Token 的价值结构与生产成本更应该关注。黄仁勋今年3月在一篇署名文章里把AI产业拆成五层:能源、芯片、基础设施、模型、应用,并将 Token 定义为现代 AI 的基本单位,也是AI的语言和货币。这个定义的精妙之处在于,它同时指向了Token的两种属性:作为语言,它是计算过程的原子;作为货币,它是价值流通的媒介。
但生产一个 Token 的代价,远比这个定义看起来复杂。据 Sam Altman 和 Epoch AI 披露,ChatGPT 发送一条文本提示大约消耗0.3瓦时。谷歌搜索的耗电量(0.03瓦时)仅为其一小部分。谷歌2025年也曾披露,Gemini发送一条典型的文本提示大约消耗0.24瓦时,并产生约 0.03 克二氧化碳。
随着模型复杂度的增加,推理成本也相应上升。GPT-5级别的系统每次查询可能消耗约18瓦时,而进行扩展推理时则可能消耗高达40瓦时。 差距来自两个地方,一是模型大小,参数越多,生成每一个Token所需的计算量就越大;二是推理模式,新一代模型在输出每一个可见 Token 之前,会在内部进行大量隐式推演,用户看到一个字,模型内部可能已经“想”了上百步。单个可见 Token 的真实成本,被这个思考过程成倍放大了。
这是 Token 与电力、石油这类生产要素的根本区别,Token的价值并不由生产成本决定,而完全由使用场景决定。同样一百万个 Token,用于闲聊,市场价约0.01美元;用于代码生成,可以值200美元;用于法律文件审查,价值可能超过1000美元,价值差距达十万倍。耶鲁大学研究者将这一特征描述为 Token 的“可合同化”属性:数量可以精确计量,但价值取决于它被编程去做什么。
当整个行业用同一个价格逻辑去覆盖价值差距十万倍的使用场景时,系统性的定价混乱就不是偶然,而是必然。
因此,所谓平均 Token 价格,就像用平均客单价来描述一个既有路边摊又有米其林餐厅的商圈,即便数字正确,但毫无意义。Collis 和 Brynjolfsson 曾在2025年的估算显示,生成式AI在2024年仅为美国消费者创造的消费者剩余就高达约970亿美元,用户实际获得的价值,远超过他们支付的金额。这个数字的绝大部分,集中在高价值应用场景。
Token经济的窗口期正在合拢
在 Token 经济中,竞争优势是跟随技术跃迁、产品形态转变与市场结构共同决定的时间窗口。每一个窗口的受益者,都在无意识中为下一个颠覆者铺路,而能在多个窗口连续卡位的玩家,才是真正的赢家。
2025年初,算法是 Token 第一个窗口。DeepSeek V3 发布后,混合专家架构(MoE)将同等能力的推理成本压低了一个数量级:模型内部包含多个专家子模块,每次推理只激活其中一小部分,在保留完整模型能力的同时,将单次推理的实际计算量大幅压缩,将推理成本下降了一个数量级。
但算法窗口的悖论在于,打开它的那把钥匙,同时也是关上它的锁。DeepSeek 选择了开源,将核心模型权重和架构设计公开,吸引全球开发者接入生态。这个选择在短期内快速扩大了市场份额,在中长期则主动压缩了算法领先的窗口期。当架构创新被开源,整个行业的 Token 成本基准被同步重置,算法优势也就从专有壁垒变成了公共基础设施。
同年底,规模成为第二个窗口。火山引擎将互联网流量战的打法平移了过来,用大规模的机场广告宣告自己在 Token 市场的存在。谭待在4月2日的最新的业务进展分享中提到,两年之内,火山引擎的 Token 调用量增长了1000倍,万亿级 Token 消耗企业增至140家。

不过规模优势存在一定时效性,谭待在接受《第一财经》的采访时也谈到,在 Token 大规模调用量中,包含了大量无效算力。谭待以解数学题为例:枚举法计算量大,模型能力不足就会采用类似方式,造成无谓消耗;更优秀的模型能找到简洁解法,优化空间很大。规模数字的背面,是大量本可以避免的算力浪费。当竞争从“消耗了多少”转向“每个Token创造了多少价值”时,规模窗口就开始关闭。
场景,是当前 Token 竞争最激烈的地方。智谱、MiniMax、月之暗面没有字节的流量规模,也没有阿里、腾讯的云计算生态,但它们在 To B 高价值场景里找到了立足点。智谱与 MiniMax 的市值一度超过快手等传统互联网公司,充分说明场景窗口在特定阶段能创造的估值溢价有多大。
但这个窗口如今也正在收窄。在一场行业论坛上,杨植麟问智谱CEO 张鹏:你们为什么涨价?张鹏的回答是,完成一个 Agent 任务消耗的 Token 量,是回答简单问题的十倍甚至百倍;长期依赖低价竞争,对整个行业都没有好处。
这场对话背后,一场更大规模的场景争夺战正在展开。字节通过飞书和扣子(Coze)平台,将大模型能力直接嵌入企业的协同工作流与海量流量节点;腾讯依托微信生态与企业微信,掌握着企业触达并服务客户的最短社交链路;阿里则将旗下 AI 业务统筹为 ATH 事业群,Token 消耗被直接打包成企业数字化底座的一部分。
这三家公司拥有在企业端已经建立多年的信任关系和系统整合能力。独立厂商依赖模型质量差异维系的场景优势,正在被这种结构性优势快速压缩。
Token效率是当前正在形成的第四个窗口,也是最难被快速复制的一个。这一窗口的竞争,目前集中在 Coding 场景。Anthropic 封禁第三方工具后,大量习惯于低成本接入 Claude 的用户开始寻找替代方案。OpenAI 迅速将自己定位成更易上手的选择。但 Anthropic 押注的是训练和运行模型的效率,OpenAI 的心态是奥特曼总能筹集到更多资金支持算力规模。
用资本堆算力换市场份额,是一种可以奏效但难以持续的策略。截至今年3月底,OpenAI 的 API 每分钟处理量已突破150亿 Token,而2025年10月这个数字还是60亿。但算力供给的增速远远跟不上,GPU 租赁价格在两个月内涨了48%,英伟达最新一代 Blackwell 芯片的每小时租用费用已升至4.08美元,数据中心的建设周期以年计算。OpenAI 甚至部分暂停了 Sora 视频生成工具,腾出计算资源给编码和企业级产品。
Anthropic 看到的是 Harness Engineering 这条路,通过重新设计 Agent 的调度架构,从系统层面减少无效 Token 消耗,让更少的算力做更多的事。这是在算力稀缺的现实约束下,重新定义效率本身的含义。
而在中国市场,阿里云也开始切入效率窗口,其将 Token 的定价、调用追踪与企业账单管理整合进统一的云计算基础设施。吴泳铭提到,很多企业已经不把 Token 消耗当IT预算,而是当作生产资料和研发成本来核算。这是一种更慢的建法,但也更难被颠覆。
在算力供给触及物理极限、需求仍在加速增长的现实下,真正稀缺的不是便宜的 Token,而是在有限算力约束下能产出最高价值密度的 Token。
封禁OpenClaw,只是结果
在算力稀缺、定价体系失效、Agent 消耗失控的多重压力下,Anthropic 是迄今为止唯一一家不只是调整了定价策略,还从工程架构层面重新回答了“Agent应该怎么运行”这个问题的公司。封禁是被动应对,Managed Agents 才是主动给出的答案。
Harness 是 Agent 框架的调度层,负责决定何时调用模型、如何管理上下文、出错时怎么处理。在 Chatbot 时代,这套逻辑相对简单。进入 Agent 时代后,Harness 开始承载更复杂的任务,也开始产生大量本不必要的 Token 消耗。

Anthropic 工程博客提供了一个具体案例,Claude Sonnet 4.5,存在一种被工程师称为“上下文焦虑”的行为当模型感知到上下文窗口接近上限时,会提前终止任务。Harness为此添加了上下文重置机制,在适当时机强制清除并重载上下文,以确保任务继续。这在当时是合理的工程补丁。
问题发生在 Claude Opus 4.5 上线之后。新模型已经不再出现“上下文焦虑”,但旧的重置机制仍在每次执行时触发,消耗着不必要的 Token,增加着不必要的延迟。这些机制从解决问题的补丁,变成了制造成本的负担。Anthropic 工程师将其称为“死重”。
这是 Harness 框架的结构性缺陷:每一套 Harness 都是对某一时刻模型能力的快照。模型在持续进化,但快照被当作永久规则执行。模型迭代越快,这种错位就越严重。
在商业场景里,这个问题被进一步放大。OpenClaw 在处理单次用户查询时,实际产生的 API 请求数量是 Claude Code 官方框架的数倍,每次请求携带超过10万 Token 的上下文窗口。换算成 API 费率,单次查询的真实成本是订阅价格的几十倍。无论个人的主观使用频次高低,通过这类框架发起的请求,天然具有重度用户的成本画像。平台对重度用户的补贴,由此从概率问题变成了确定性问题。
Anthropic 的应对是 Managed Agents,核心思路是为 Agent 领域建立接口稳定,实现自由替换的抽象层。“上下文焦虑”消失了,对应的重置机制自然退场,不会留下“死重”。内部测试数据显示,在结构化文件生成任务中,Managed Agents 将任务成功率提升了最高10个百分点,提升最显著的是最难的任务。
同期出现的 Hermes Agent,从另一个方向印证了同一个判断。这个强调“闭环学习循环”的框架,在更新已积累的操作流程文件时,选择以 patch 方式写入,只传入需要修改的具体字段,而非重写整个文件。patch只触碰问题所在,Token 消耗也更少。这是 Token 效率意识在框架设计层面最具体的体现之一。
Token 经济的新竞争,已经细微到“谁能让每一个 Token 产出更高的价值”。罗福莉在自己那篇浏览量超过73w+的帖子最后写道,真正的出路不是更便宜的 Token,而是模型和 Agent 的协同进化。
这句话说的不只是技术路线,也包括整个行业定价逻辑应该完成的转变:从按量计费,到按价值定价;从管理成本,到创造结果,这是整个行业需要完成的转变。
Anthropic 在 Harness 架构上的探索,给出了目前最清晰的一个方向。但中间这段路,还很长。
*题图及文中配图来源于网络。
- 赚钱加速度:OpenAI 越大越慢,Anthropic 反而越大越快
- AI 电荒突围:谁能替代重燃?
- Claude故意降智,模型也开始“看人下菜碟”?
- 100个产品原型同时跑、新模型Mythos断层领先,连skills效果都好到让团队意外:Anthropic内部到底在发生什么?
- 高盛 CEO 苏德巍警示:Anthropic 旗下 Mythos 模型发现漏洞能力超人类,带来前所未有风险
- 月薪3万,去内蒙草原给DeepSeek守机房
- OpenAI 反击 Anthropic:聚焦企业 AI 落地,最强 Spud 模型对标 Claude Mythos
- Anthropic狂搞“死亡更新”:7次发布抹去万亿市值,下个目标Lovable


