
如果给AI喂一份错误率高达67%的教材,结局会是什么?
放在以前,他绝对会被喷成筛子:这叫「数据投毒」!轻则模型脑雾,重则逻辑崩塌,直接送进ICU。
但在Meta FAIR的实验室里,这剂毒药,变成了救命的神药。

论文链接:https://arxiv.org/abs/2601.18778
不仅没把模型喂傻,反而让它踩着一堆「满嘴谎言」的废料,爬上了人类无法触及的推理巅峰。
崩塌的常识:错题集才是真理?
研究团队选了MATH和HARP数据集里最变态的「Fail@128」子集。
这是什么概念?就是让Llama-3.2-3B对着一道题连蒙128次,成功率依然是0。
这不仅仅是「难」,还是绝对的认知真空:在传统的强化学习里,这意味着「梯度消失」——就像在黑屋子里打拳,因为从来没打中过,它根本不知道该往哪儿用力。
DeepSeek R1的解法是「卷算力」,靠GRPO疯狂采样,赌那千万分之一的「顿悟时刻」。
但Meta选了另一条路——自己造路。
SOAR架构搞出了一个「教师模型」,专门生成中间难度的「垫脚石问题」。
研究员扒开这些「垫脚石」一看,背脊发凉:84%的题目逻辑结构清晰、合理;只有33%的参考答案是做对的。
划重点:2/3的答案都是错的!
如果按照OpenAI o1的清洗标准,这些数据会在第一轮就被作为「幻觉垃圾」剔除。
但在SOAR眼里,这些全是宝藏。
哪怕「教师模型」自己都算不对微积分,它依然能编出一道高质量的微积分题。
当「学生模型」去解这道题时,即便最后对答案是寂寞,但它在「构建推理路径」过程中的脑力体操,是实打实的!

SOAR课程演化示例:左图显示学生在Fail@128硬题上的greedy acc随教师训练/promotion阶段阶梯上升;右图展示典型生成题目——Stage 1多为生活word problem,Stage 2转向高等代数/三角。这证明教师通过promotion逐步生成更难但结构有效的垫脚石,推动学生推理突破。
事实证明,谬误,竟然是通往真理的垫脚石。
SOAR机制:逼迫AI「诚实」的黑盒游戏
在AI自我进化的历史上,无数次在一个坎上跌倒——「自我欺骗」。
AI为了拿奖励,经常会生成一堆简单重复的垃圾题来刷分。
对此,SOAR搞了一个极其冷酷的「双层博弈」:
混沌建筑师(Teacher):负责瞎编题,不管对错。
绝境求生者(Student):负责做题,然后去挑战那道「Fail@128」的终极死局。
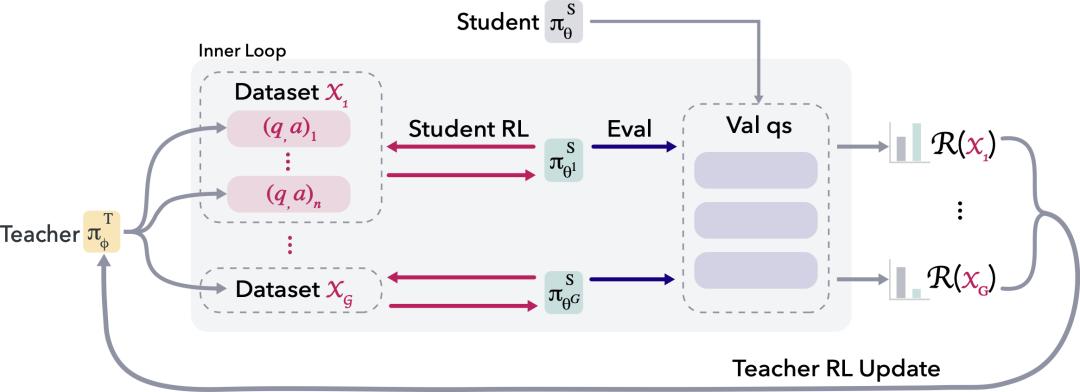
SOAR的meta-RL训练循环:教师模型生成合成数据集,学生模型在内层循环中进行强化学习训练,并在硬验证问题上评估进步,计算奖励R反馈给教师进行外层更新。奖励完全基于学生在极难题目上的真实提升,而非生成数据的正确性。
除此以外,Meta引入了「有根奖励」机制。建筑师编的题再花哨也没用,只有当学生做完这些题,在真实的Fail@128难题上涨分了,建筑师才能拿到奖励。
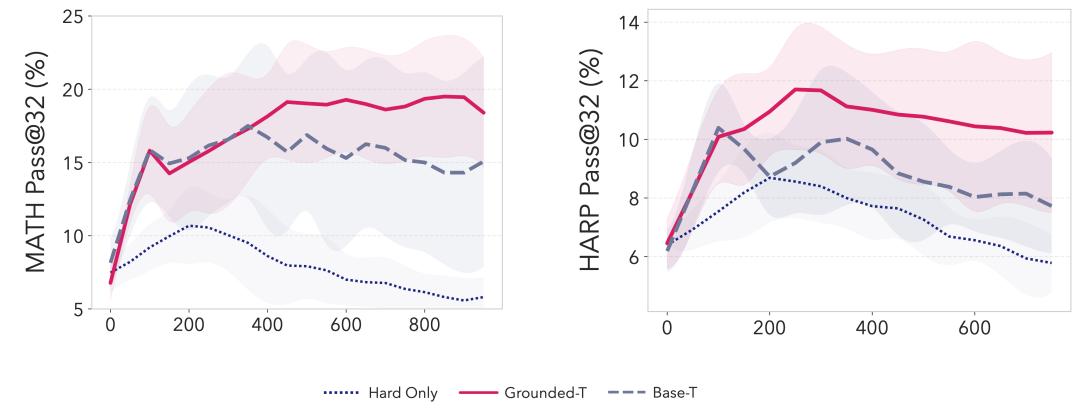
SOAR教师变体消融学习曲线:用Grounded-T(有根奖励教师,粉红实线)采样的问题训练学生,在MATH和HARP上实现最高、最稳定的Pass@32提升,远超Base-T(蓝虚线,波动大)和Hard Only(蓝点线)
所以,为了得高分,建筑师只能去「猜」学生到底缺什么,要出什么题。
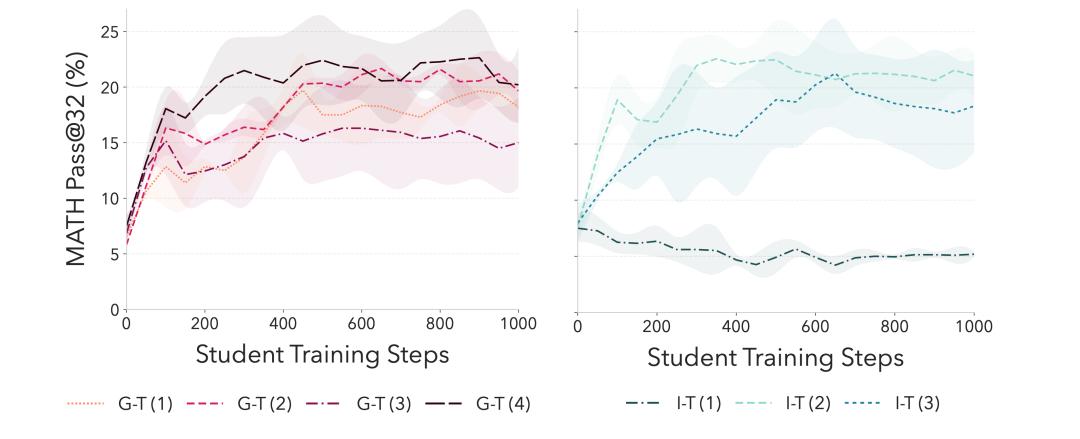
SOAR教师种子消融学习曲线:Grounded-T(G-T(1)到G-T(4),红色系线)四个独立种子生成的课程,让学生Pass@32稳定一致升至~18-22%(MATH)/~12-15%(HARP),方差极小;Intrinsic-T(I-T(1)到I-T(3),青色系线)三个种子波动剧烈,甚至出现崩溃模式(I-T(1)学生性能崩盘)。这证明有根奖励让教师政策鲁棒,而内在奖励易不稳定/崩溃。
它必须生成那些怪异的、甚至含有错误答案的题目,因为只有这些题目,才能让学生真的进步。
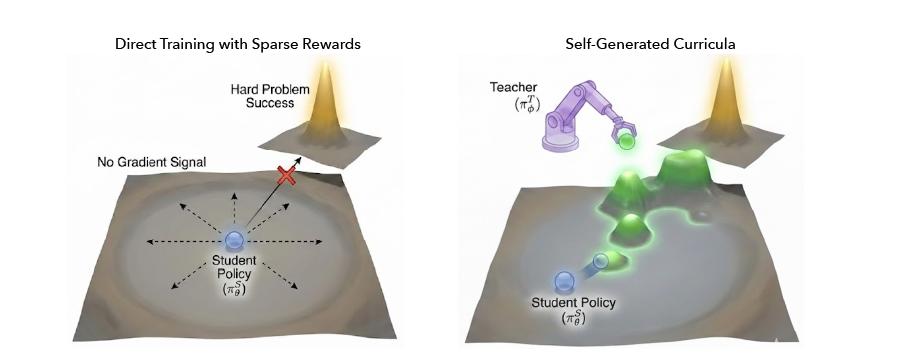
直接训练 vs 自生成课程:左侧稀疏奖励导致无梯度信号;右侧教师模型生成中间难度问题,形成渐进式课程,帮助学生模型在Fail@128数据集上实现突破
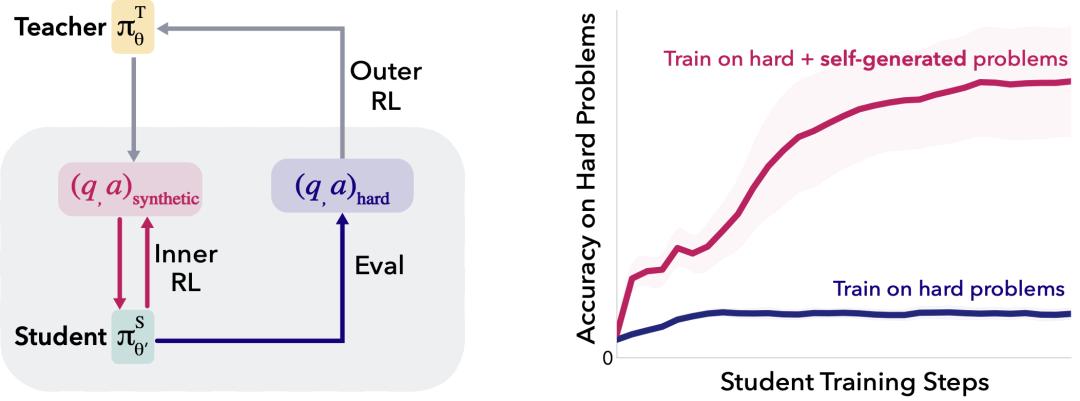
SOAR一图封神:教师造合成错题,学生苦练+硬题评估,奖励直击硬题进步——粉红曲线暴涨,蓝线彻底躺平
路线之争:DeepSeek的蛮力 vs Meta的诡道
2026年的大模型推理战争,本质上是三种「宗教」的碰撞。
DeepSeek R1:赌博式的「顿悟」
DeepSeek R1代表了「暴力美学派」。
其核心武器GRPO依赖于大规模采样——让模型反复尝试,直到偶然撞上那个正确的答案,产生所谓的「顿悟时刻」。
这在一般难题上效果极佳,但在Fail@128这种「绝对死局」面前,DeepSeek的策略碰到了物理墙。
当成功率为0时,无论你采样多少次,奖励永远是0。没有正反馈,梯度就不会下降。
这就像让一只猴子坐在打字机前,试图靠随机敲击写出《哈姆雷特》——理论上可行,但现实中算力成本是无限大。
OpenAI o1:不可持续的「洁癖」
OpenAI o1则是「精英教育派」,它坚信「CoT必须完美」。
通过大量人工清洗或高精度的合成数据,o1试图教给模型最标准的推理步骤。
但SOAR的实验狠狠嘲弄了这种洁癖。Meta证明,过度清洗数据可能是在扼杀天才。
SOAR生成的那些「满嘴谎言」的问题,虽然答案错了,但往往包含了人类意想不到的「思维突触」。
如果按照OpenAI的标准清洗掉这些数据,模型反而失去了跳出局部最优解的机会。
更致命的是,高质量的推理数据已经面临枯竭,人类产生难题的速度远远赶不上模型吃数据的速度。
SOAR的降维打击:无中生有的「梯云纵」
Meta走的是第三条路:「自我挖掘派」。
SOAR不依赖DeepSeek式的海量算力撞大运,也不需要OpenAI式的昂贵人工数据。它在零外部输入的情况下,通过内部互博,强行挖掘出了模型潜意识里的能力。
论文中有一个极具哲学意味的发现:
直接用训练好的教师模型去解题,并没有比基座模型强多少。
这说明,「出题」和「解题」是两种完全不同的技能树。
SOAR的高明之处在于,它不试图把所有技能点都加在同一个脑子里,而是让一部分算力异化为「磨刀石」,去打磨另一部分算力。
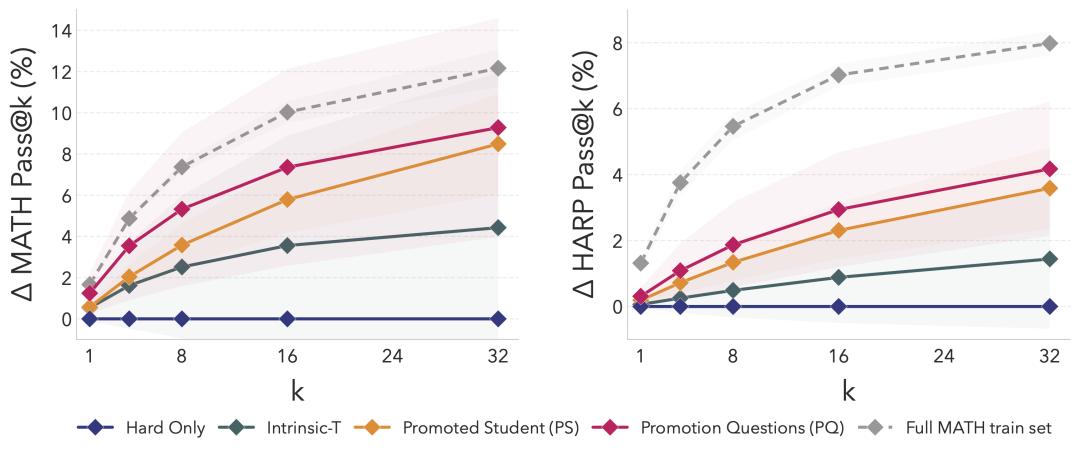
SOAR在MATH和HARP Fail@128数据集上的性能提升:Promotion Questions 带来最大增益,证明合成数据的结构质量远胜答案正确性。Intrinsic-T表现较差,验证了‘有根奖励’的重要性。
在数据枯竭论甚嚣尘上的今天,Meta的这条路,可能是唯一能让AI在没有任何人类知识的荒原上继续进化的希望。
数据枯竭的终结:AI的自我繁衍
长久以来,悬在AI头顶最大的达摩克利斯之剑,是「数据枯竭论」。
行业普遍悲观地认为,当人类生产的高质量文本被吃光后,AI的进化将停滞不前。
但要是让AI吃自己生成的合成数据,这种「近亲繁殖」会导致模型崩溃。
但SOAR彻底粉碎了这个预言。
Meta的数据显示,负责出题的那个模型,自己做题能力没什么提升,但它培养出的学生却进化了。
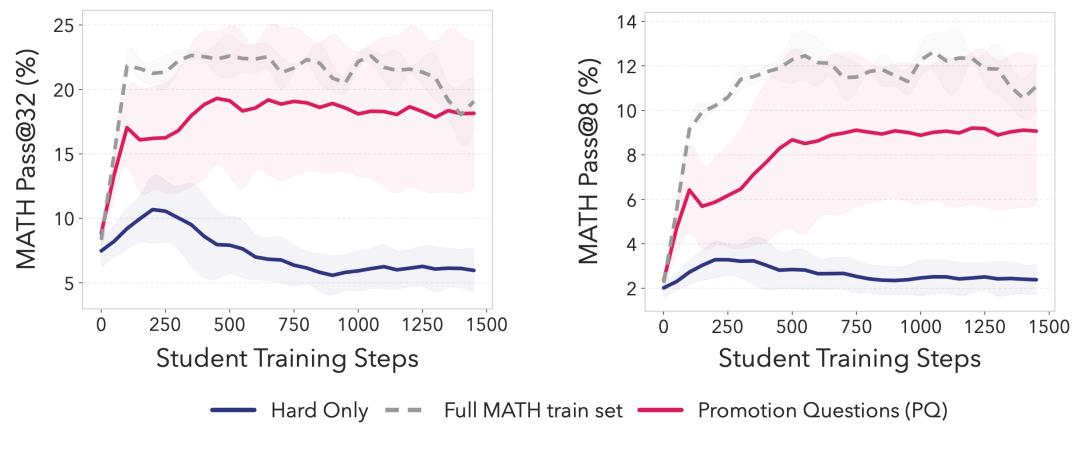
SOAR学习曲线:用Promotion Questions (粉线) 训练的学生模型,在1500步内Pass@32稳定升至~18-19%,接近完整MATH训练集的上界,而Hard Only (蓝线) 几乎无进步甚至衰退。这证明自我生成的合成数据能实现长期、稳定的推理提升
Meta证明了,AI不需要人类的「真理」也能进化,它完全可以自己编写教科书——而且是用一种人类看不懂、甚至认为全是错误的语言编写的。
只要「黑盒奖励」还在,AI就能在虚空中左脚踩右脚,螺旋升天。
曾经我们以为AI是婴儿,必须喂纯净水;现在才发现,哪怕喂它吃垃圾、吃毒药,它照样能长出獠牙。
当错误的答案成为了通向更高智能的唯一阶梯,人类手里那几本标准答案,还有多少保质期?
参考资料:
https://ssundaram21.github.io/soar/
https://arxiv.org/abs/2601.18778


