
1
Anthropic禁止订阅用户通过龙虾等第三方工具接入后,小米大模型团队负责人罗福莉凌晨发了篇帖子讨论这事。
主要内容可以概括为两点。
第一,A社的做法虽然会短期推高使用成本,如果用户继续使用Claude模型,但长期来看会带来很好的工程纪律。
工程纪律的意思是,社区会因为模型成本上升,在开发产品时做更合理的工程优化来提升token的使用效率。
这里她点名批评了龙虾,上下文管理做得很拉胯,一个用户请求会触发多轮工具调用,每次都是携带长上下文的独立API请求。
第二,她呼吁模型厂商不要打价格战,不要靠低价吸引用户入坑后,又用缩水的模型和不稳定的服务去损害体验。
我们前两天写了篇文章,《小米这次也没把价格打下来》,其中提到MiMo Token Plan目前价格相对其他厂商同等套餐偏贵。
罗福莉没有直接承认这点,但间接回答了这个问题:小米的目标是“长期稳定地交付高质量的模型和服务 —— 而不是让你冲动付款,然后弃船。”
我们之前文章里提到,MiMo套餐偏贵的事实其实跟小米给大众的主流印象是有差距的,毕竟观众更熟悉性价比叙事。
但这也不是小米搞AI后就变了,小米这个定价肯定也谈不上赚钱,只是在其他选手亏损搞token倾销的时候,选择了更贴近成本的定价策略。
token倾销这个词可能有点重,因为要是以低于成本售卖AI服务这个标准看,目前行业里基本没谁能逃得过。
但有些玩家定价的确相当激进,低价吸引用户过来后保证不了体验,比如我就遇到过某家套餐服务卡顿甚至不可用的情况。
大模型跟其他传统互联网产品不同。传统互联网产品边际成本可以不计,用户翻倍成本增加很少。大模型产品成本跟用户规模比例扩张。
而且还因为是非标品,厂商很容易在背后做手脚,稍微降点智用户不容易察觉,察觉到也没有实际证据。
当然,即便存在这些一些问题,我仍然认为模型厂商价格战是利大于弊的,是双赢的局面。
用户客观上因为价格战得到了便宜,这是加速新技术采纳的决定性因素。
DeepSeek去年的模型并没有在能力上超过GPT或者Claude,但R1的意义仍然没有被高估,因为把成本降低几十倍对技术普及的促进必然强于某个增量SOTA模型。
至于亏钱卖token不可持续,我只能说不是现阶段二线厂商配考虑的问题。
Anthropic模型能力顶尖,产品体验差异化,所以哪怕经常封号拔网线也一堆用户求着交钱。
彭博上个月报道,Anthropic当时年化收入已经达到200亿美元,相比去年底翻倍还多,这个夸张的增长速度隐隐有取OpenAI而代之的意思了。
但二线厂商之间模型能力并没有拉开差距,不同厂商轮流领先,性价比是不得不走的路子。
罗福莉评价是对的,龙虾就是vibe coding出来的一堆屎山。
因为是屎山,所以它没有架构设计,没有工程优化,天生就浪费效率。
但它能火起来,能让一堆专业的非专业的用户愿意用,就已经算是功德无量了。
所有二线厂商都应该给龙虾磕一个,我很难想象没有龙虾他们得多努力才能证明自己的价值。
这是OpenRouter上不同模型的使用统计。
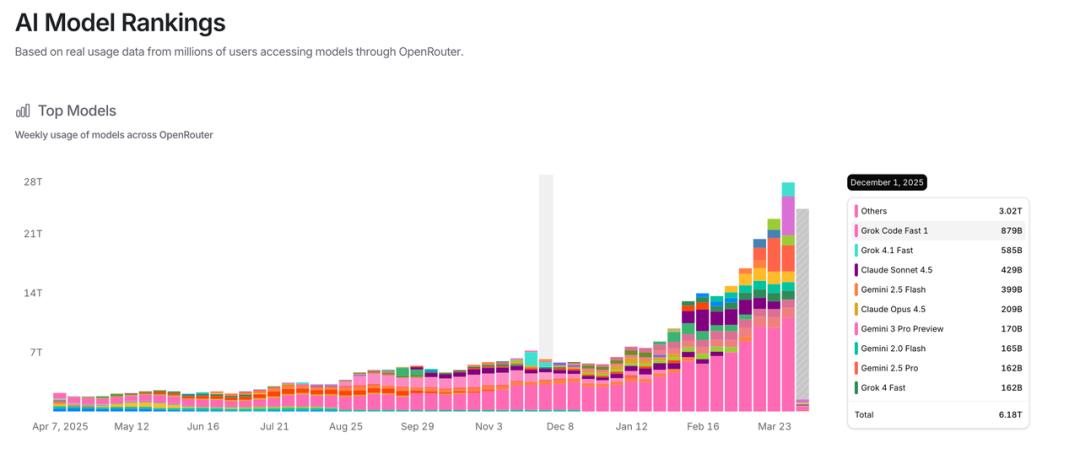
在龙虾火爆之前,你在这个排行里根本看不到二线模型厂商,除了硅谷御四家,其余全是others。
但现在排行榜前几名,已经被阿里、小米、阶跃星辰的模型占满了。
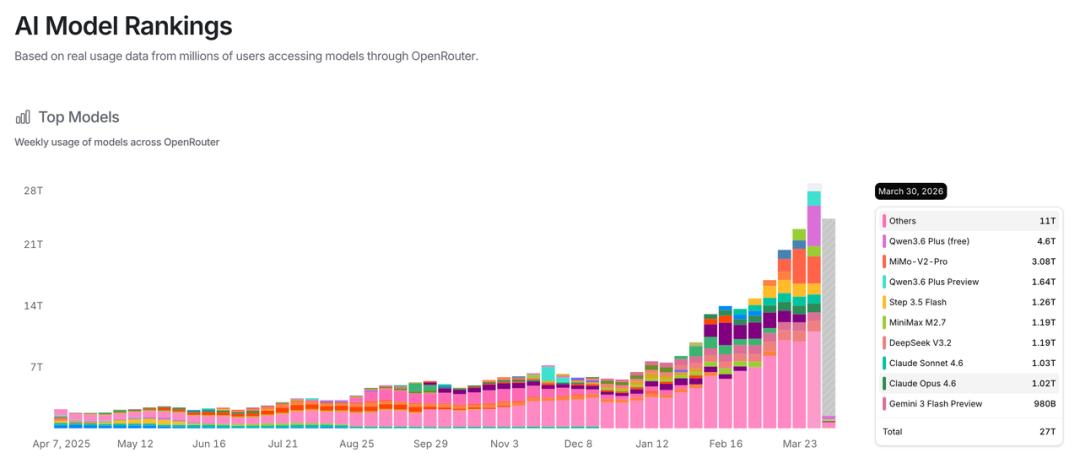
话说新模型出来,免费放OpenRouter上吸引大家用一用,已经成为国内厂商的惯例。OpenRouter现在已经沦为PR前沿阵地。
这两天阿里发布Qwen3.6,宣传登上OpenRouter排行榜首。小米MiMo之前也宣传登顶了OpenRouter。都是免费试用。
某种程度上说,龙虾耗token甚至可以理解成是feature。
大模型研发门槛很高,但大模型供给一直以来都是不稀缺的,因为用户不需要那么多模型。龙虾把性价比放大成了真正的竞争力。
简单拉下数据。MiniMax去年总收入7900万美元,龙虾爆火后2月ARR已超1.5亿美元。月之暗面发布K2.5模型后,不到20天收入超去年全年,且海外收入首次超过国内。
AI的确在推动各个产业发生变革,不过就AI自身而言,至今为止都还没有跑通独立的盈利模式。OpenAI和Anthropic收入在快速增长,但能否覆盖巨额研发和资本支出仍有疑问。
至于智谱、MiniMax和月之暗面们,距离闭环的商业模式就更为遥远了。
这种情况下,叙事成为生存的要义。叙事不能只靠画饼,模型厂商的第一性原理就是模型得有人用。
没人用,叙事就崩塌了。有人用,越来越多人用,叙事才会变得圆满。
去年底,月之暗面估值43亿美元,现在正以180亿美元寻求融资,翻了四倍不止。智谱今天收盘780港币,是1月份IPO发行价116港币的6.7倍。MiniMax的IPO发行价是165港币,现在股价是950,也是翻了快6倍。
不能只算token账。
2
二线模型厂商在成本和规模压力下,已经有提价动作。但这暂时不会达到摆脱价格战的地步。
小米的处境比较特殊,它有自己完整的产品矩阵和硬件生态,MiMo的第一使命是融入并改造这个现有生态。哪怕不对外卖token,小爱同学、智能手机、小米汽车、IoT设备生态,MiMo都能有大有作为的空间。
智谱、MiniMax、月之暗面们则处在另一个处境。它们有C端产品,但这个赛道竞争极其惨烈。目前看来独立的AI产品,无论是通用助手,还是细分赛道,字节、腾讯和阿里都有碾压性的优势,也有争夺的意志。
相较之下,API卖token的生意看起来好一些,虽然好得有限。因为这只关乎模型质量,而腾讯和Meta的经验表明,模型研发不只是钱和资源的因素。
但龙虾窗口期不会无限延续。
如果龙虾只是一阵风,过段时间随风而逝,那自然二线厂商也就不能指望这个出货渠道了。
如果龙虾代表的不是一个工具的短暂流行,而是C端AI产品的一种范式,那大科技公司一定会出手。
这些公司有流量、有分发、有用户信任,它们会以自己的竞品收割市场,并且会优先使用自己训练的模型,而不是采购二线厂商的API。
模型跟产品的结合是大趋势。阿里打通千问App跟通义模型研发团队,搞出了组织调整和人事出走风波。姚顺雨入职腾讯,也是首先做团队整合,不同研发部门之间的整合以及研发跟产品的整合。
罗福莉批评龙虾耗token,提到Claude Code更节省上下文的工程设计,这是另一个产品需要跟模型打通的案例。
龙虾架构上的天然缺陷,意味着每次工具调用都携带完整的长上下文发起独立请求,用户的一个操作可能在后台触发十几轮API调用。这不仅烧token,也制造延迟,制造不稳定。
Claude Code对上下文做精细管理,知道什么时候该压缩历史,什么时候该截断,怎么在保留任务状态的同时减少冗余信息的传递。
这背后是Anthropic对自己模型能力边界的深刻理解。只有模型研发者,才能把产品和模型调优成浑然一体的东西。
AI产品的第一代范式是,模型作为通用API,产品套在外面。这个范式催生了龙虾,也催生了无数套壳应用。它降低了创业门槛,但也带来了巨大的效率浪费。产品不理解模型,模型不适配产品,两边都在用蛮力弥补彼此的信息差。
如今第二代范式正在浮现:模型与产品深度整合,从架构层面共同设计。Claude Code是一个样本:模型不再是被调用的服务,而是产品本身的一部分。
这个趋势下,纯粹的模型API厂商面临的压力会越来越大,没有产品可能成为它们的致命缺陷。如果竞争力来自模型与应用层的深度整合,那API层的价格竞争就是一场慢性消耗。
行业一直喜欢说模型即产品,用这句话强调模型的基础作用和重要性没问题。但除非你的商业模式是只卖API,否则模型始终是产品的组成部分,而不是产品的全部。


