
今年整个AI圈最热闹的事件莫过于全民“养龙虾”——OpenClaw的走红,让大家终于看到了AGI落地的具象化可能。
然而,当业界为Agent“手脚”的日益灵活而欢呼时,一个更根本的问题却被暂时掩盖了——真正决定OpenClaw行动价值的“大脑”,也就是它背后的大模型底座,似乎正走在一条不可持续的道路上。
过去两年,大模型行业奉行的是典型的“暴力美学”,即参数越多代表智能越高,思维链越长代表推理越深。万亿参数模型接连登场,长思维链成为技术先进性的标配。但在这股狂热之下,一个尴尬的事实逐渐浮出水面——大量参数只是“吃算力”的摆设,超过70%的Token消耗发生在模型“已经答对、仍在反思”的无效阶段。
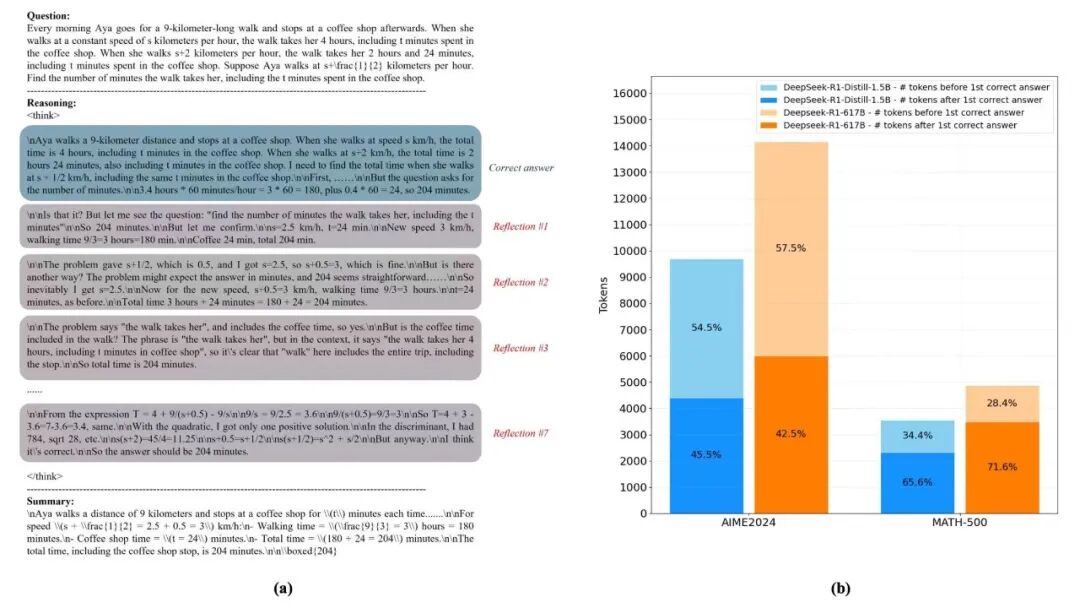
推理Token消耗分布示意
因此,当OpenClaw这样的执行端已经准备好进入工厂、仓库、办公室,我们才发现,驱动它的“大脑”要么昂贵到企业用不起,要么为了省钱而被迫“降智”。这或许是2026年AI产业化最核心的悖论——手脚已经就位,大脑却还在“算力通胀”的泥潭中挣扎。
这一困局如何打破?就在前不久,YuanLab.ai团队开源了Yuan 3.0 Ultra万亿参数模型,以一套截然不同的、更务实的技术路线,也在试图解答当前行业的这一根本性问题:当模型规模的扩张已触及收益递减的临界点,大模型的下一场竞赛,究竟应该比什么?
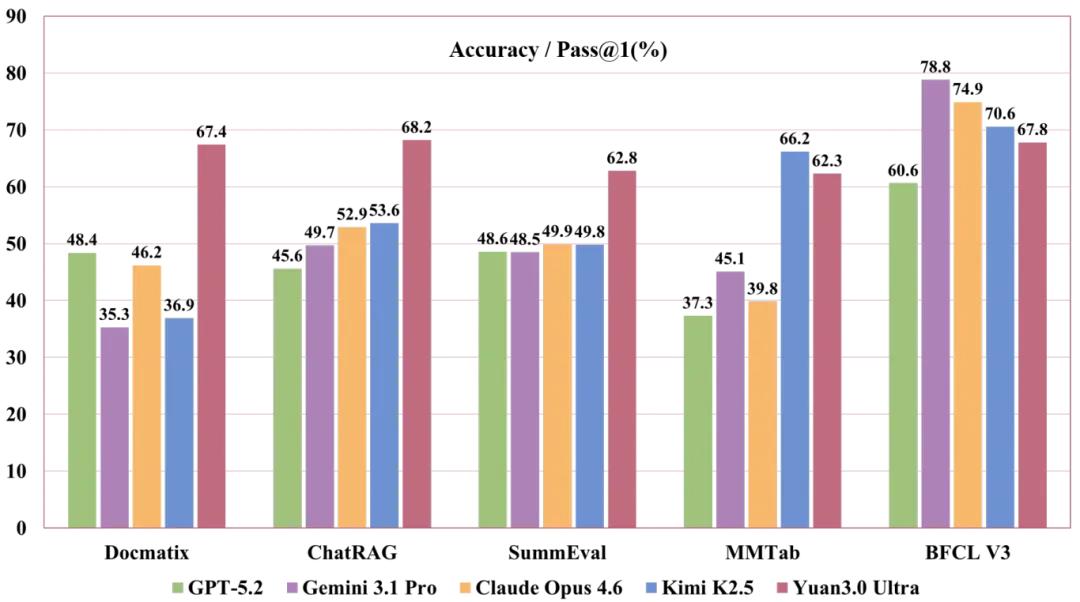
Yuan3.0 Ultra在面向企业应用的表现
如果OpenClaw的大脑困于“昂贵”与“降智”的两难,那么,整个行业就必须重新审视那个曾被奉为圭臬的增长逻辑。
算力通胀时代,市场渴望一场“价值回归”
过去两年,行业经历了一场深刻的认知撕裂。
撕裂的一边是技术供给侧的狂欢。万亿参数模型接连登场,推理模型追逐越来越长的思维链,仿佛“想得越多”就等于“想得越对”。在国际AI顶会上,论文的核心卖点往往是“我们的模型又大了多少亿”“我们的思维链又长了多少步”。
撕裂的另一边是企业需求侧的清醒。当技术营销的喧嚣褪去,企业客户在采购时开始用最朴素也最残酷的ROI逻辑发问:每一次API调用支付的Token费用,究竟有多少转化为真正的业务价值?
事实上,研究显示,在复杂推理任务中,模型超过70%的Token消耗发生在“已经答对”后的自我验证阶段。这意味着,企业每为模型智能支付10元钱,有7元是在为它的“过度思考”买单。
与此同时,更隐蔽的浪费还藏在模型结构本身。MoE(混合专家)架构在预训练中会自发形成专家分化,负载最高的专家与最低的专家差距可达500倍。这意味着,大量长期闲置的“僵尸专家”成了模型参数虚高的主要推手——它们几乎不干活,却依然在每一次推理中被加载、被维护、被计费。
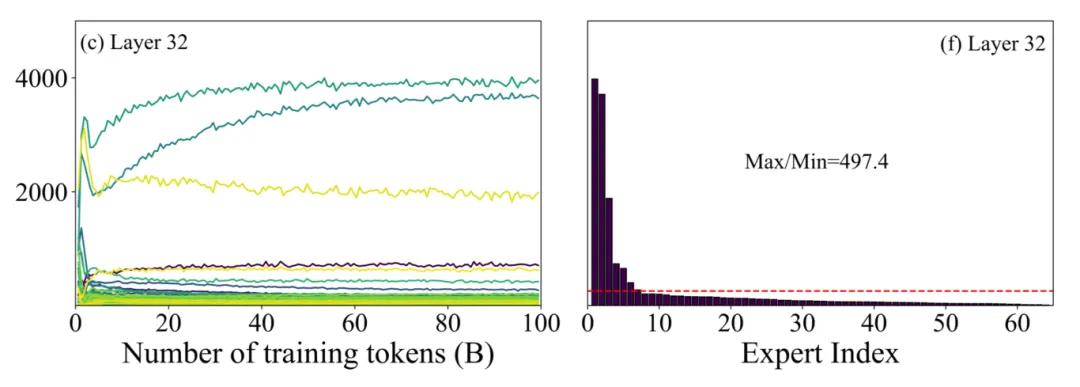
MoE模型训练过程中存在专家训练不均衡问题
由此,“算力通胀”问题就不得不重视起来。参数规模在膨胀,推理链条在拉长,但单位算力产出的真实智能却在稀释。当OpenClaw这样的执行端开始规模化部署,这种“通胀”带来的成本压力被成倍放大——每一次物理动作背后,都是大量的Token在燃烧。
今天,YuanLab.ai团队已经敏锐地捕捉到这一趋势的不可持续性。在此前发布的Yuan 3.0 Flash中,他们就首次验证了“反过度思考”的技术可行性,通过RIRM(Reflection Inhibition Reward Mechanism,反思抑制奖励)机制让模型学会在恰当的时候停下来。直到Yuan 3.0 Ultra的开源,这一理念进一步从“效率优化”升维为“范式定义”——当行业还在比拼谁能堆出更大模型时,真正的竞争已悄然转向谁能用更少的算力提炼出更有效的智能。
是时候对“万亿参数”祛魅了
客观而言,Yuan 3.0 Ultra的突破性,不在于它迈入了万亿俱乐部,而在于它对“万亿参数”这一概念本身完成了一次彻底的“祛魅”。
其一,对“参数规模”的祛魅:LAEP算法让模型学会“精简”。
行业长期存在一个思维定式:参数越多,模型越强。这一认知如此根深蒂固,以至于每当有厂商发布更大参数的模型,资本市场都会给出积极反馈。
Yuan 3.0 Ultra用自适应专家裁剪算法(Layer-Adaptive Expert Pruning,LAEP)戳破了这一神话。研究团队发现,MoE模型在预训练中会自然形成专家功能分化,但分化不等于优化——大量低贡献专家长期闲置,却依然消耗着宝贵的算力资源。LAEP算法的精妙之处,就在于它像一位清醒的“组织优化顾问”,在训练过程中动态识别冗余专家并予以裁剪,将初始1515B参数优化至1010B,参数规模减小33.3%,预训练算力效率反而提升49%。

Yuan3.0 Ultra采用LAEP显著提升预训练效率
对于企业而言,这意味着可以用更低的硬件门槛、更少的GPU租赁开支,获得与1515B参数模型同等的旗舰级智能支撑。那么,当别人还在为参数规模竞赛买单时,Yuan 3.0 Ultra的用户就已经在享受“减重”后的成本红利了。
二、对“思维链长度”的祛魅:RIRM机制让模型懂得“停”的智慧。
当全行业沉迷于“让模型想得更久”,一个根本性问题却被忽略了:什么时候该停下来?——这不仅是效率问题,更是安全问题。
试想一下,一个由OpenClaw驱动的工业机器人,如果它的“大脑”在识别到安全隐患后还要反复思考、再三确认,哪怕只是几秒钟的延迟,都可能酿成事故。在真实世界中,“想太多”和“想错”一样危险。
对此,Yuan 3.0 Ultra引入的反思抑制奖励机制(RIRM),恰恰是对“长思维链崇拜”的一次精准纠偏。它不是简单粗暴地截断输出,而是通过强化学习训练,让模型学会区分两种状态:什么时候需要继续推理,什么时候已经可以停止。研究团队将最大可接受反思步数设为3,理想状态下鼓励直接响应,复杂问题允许适度反思,但一旦超过阈值,奖励机制就会启动抑制。
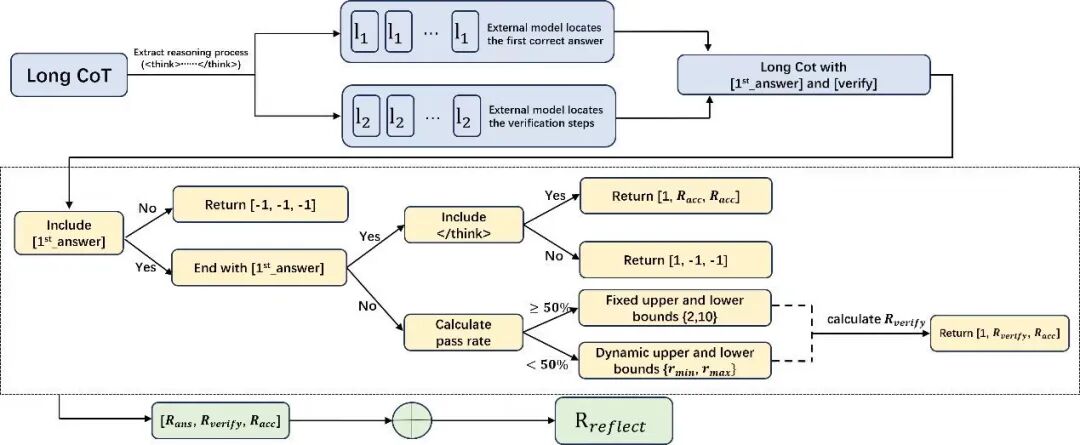
RIRM工作流程示意
由此,训练准确率提升16.33%,同时平均响应长度缩短14.38%。在MATH-500基准上,反思阶段的Token消耗显著降低。这种“该停就停”的能力,在企业高频调用场景中产生的价值,远大于在单一benchmark上刷出0.1%的提升。当每一次API调用都在为企业省钱,而不是为模型的“内心戏”买单,规模化应用才真正成为可能。
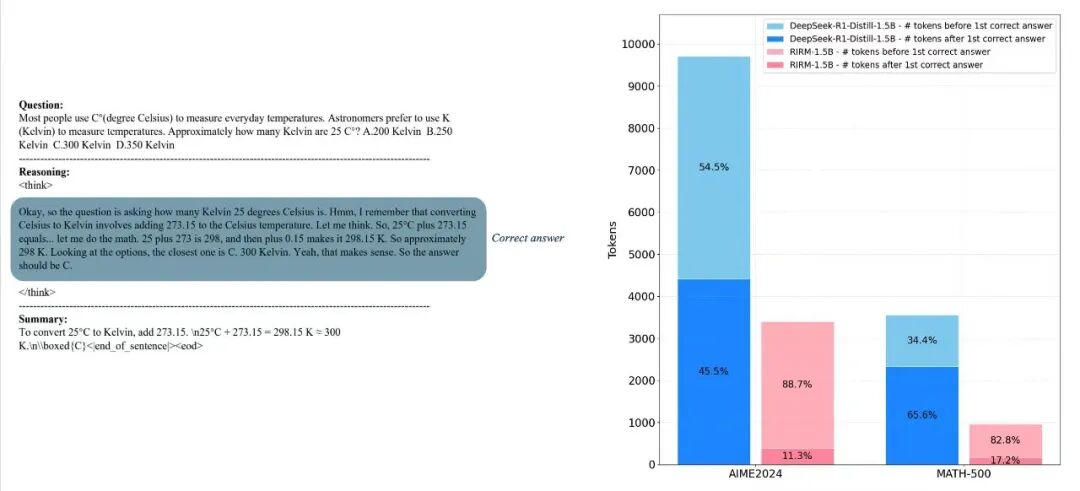
RIRM训练前后Token消耗对比
三、对“多模态”的祛魅:LFA机制让模型专注“有效关联”。
多模态是AI行业长期以来的另一大热词。但多模态不是简单的图文拼接,更不是把图片和文字扔进同一个模型就万事大吉。企业在真实业务场景中的多模态,往往是财报里图文混排的复杂表格,是合同中穿插的扫描件和手写批注,是技术文档里跨页面关联的图表和数据。因此,处理这些信息,需要的不是“什么都能看”的泛泛能力,而是“能看懂重点”的精准穿透力。
Yuan 3.0 Ultra引入的局部过滤注意力机制(Localized Filtering-based Attention,LFA),正是为此而生。它通过强化对核心语义的聚焦,精准过滤无效注意力干扰,使模型在处理复杂文档时,不再被噪声信息误导。这种对“有效信息”的聚焦能力,让OpenClaw这样的Agent在执行具体任务时,能够真正理解“该看什么”“该忽略什么”,从而实现“眼睛”与“大脑”的协同进化。
总的来说,这三重“祛魅”共同指向的,正是Yuan 3.0 Ultra的核心主张:有效智能。站在企业的视角,“有效智能”不是一句口号,而是可以量化的ROI,接下来可以用更低的成本投入来获取更好的AI智能服务。这意味着,企业不再需要为“听起来很牛”的参数买单,而是为“用得上”的智能付费。
大模型竞争的下半场已经开启了
随着市场对“有效智能”的聚焦,就意味着大模型竞争的下半场已经拉开序幕。那么,当头部厂商纷纷收紧模型权限、构建封闭生态时,YuanLab.ai团队却选择以开放姿态贡献出万亿级核心模型,其背后的本质则是在参与定义大模型竞争的下半场。
回顾上半场,核心是“参数竞赛”——谁先达到千亿、万亿,谁就是技术领先者。谁在榜单上刷出更高分数,谁就能获得资本和市场的追捧。
这一阶段的逻辑简单直接,但也迅速触及天花板——参数堆砌的边际收益递减,而边际成本(算力、能耗、部署难度)却在指数级上升。2025年底开始,越来越多的从业者意识到,单纯比拼参数规模,已经难以为继。
展望下半场,核心则是“效率竞赛”——谁能用更少的算力实现同等的智能,谁能用更可控的成本支撑复杂的Agent任务,谁才是真正的产业赋能者。这场竞赛不再有简单的量化指标,而是考验对模型架构的深刻理解、对算法效率的系统优化、对企业场景的精准适配。
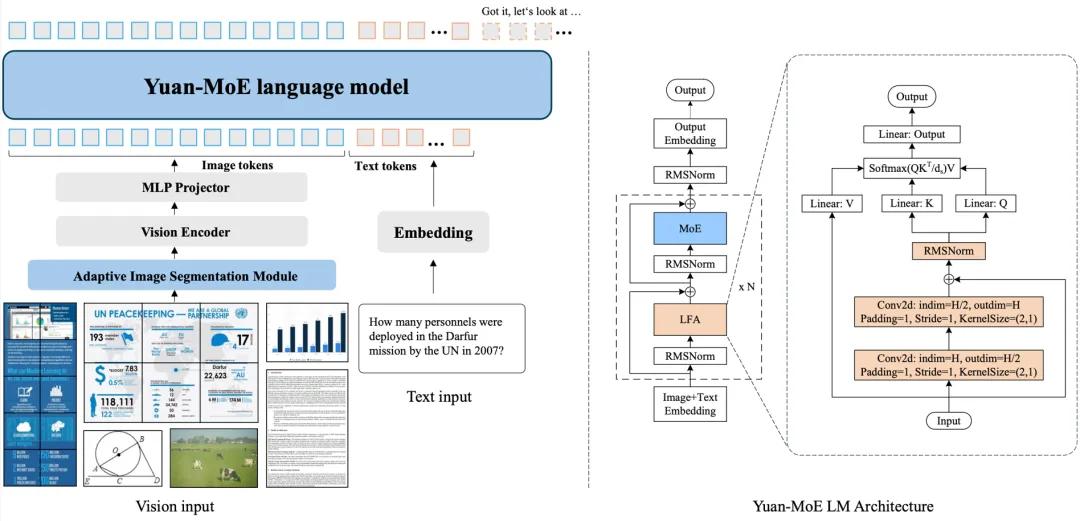
Yuan 3.0整体架构和基于MoE的语言主干
在下半场,智能的纯度,远比参数的个数更重要;思考的效率,远比思考的长度更值钱。由此,Yuan 3.0 Ultra通过LAEP、RIRM、LFA等创新,系统性地解答了“智能的效率”这一核心命题,为行业树立了有效智能的新标杆。
更深层看,Yuan 3.0 Ultra开源的战略价值还在于,为中小企业、研究机构和行业开发者提供了一个旗舰级、可定制、不锁死的模型底座选择。现如今,开发者们已经可以在github项目开源地址https://github.com/Yuan-lab-LLM/Yuan3.0获取相应的能力。
当OpenClaw这样的Agent框架日益成熟,企业最需要的恰恰是一个能够深度适配自身业务且成本可控的“大脑”。Yuan 3.0 Ultra的开源,本质上是在为下一波Agent应用大爆发铺设基础设施——让所有想要“养龙虾”的企业甚至是个人,都能负担得起一个聪明的大脑。
结语
2026年,当“养龙虾”成为全民话题,当Agent开始真正进入千行百业,我们比任何时候都更需要回答那个根本问题:什么样的智能,才是值得企业付费的智能?
答案是,有效的智能。当行业终于意识到,真正的智能,不是无限燃烧算力的能力,而是善用算力的智慧——这时候,大模型的下半场就算真正开始了。新的增长逻辑,正在被重新定义,并主导下半场的竞争。
*本文图片均来源于网络
此内容为【智能相对论】原创,仅代表个人观点,未经授权,任何人不得以任何方式使用,包括转载、摘编、复制或建立镜像。
部分图片来自网络,且未核实版权归属,不作为商业用途,如有侵犯,请作者与我们联系。


