
继Gemini 3.1 Pro屠榜封神之后,谷歌又在深夜扔出一颗炸弹。
刚刚,Gemini 3.1 Flash-Lite正式上线!
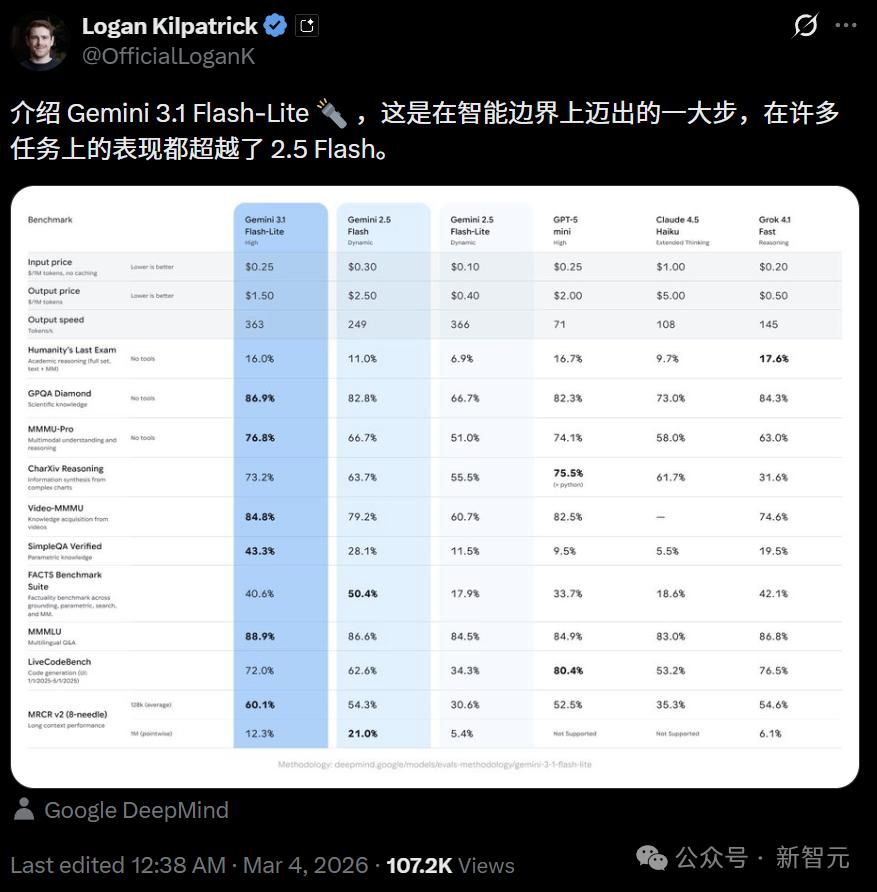
速度363 tokens/s,输出价格1.50美元/百万Token,跑分直接碾压GPT-5 mini和Claude 4.5 Haiku。

同一任务下,相较于2.5 Flash(33分钟),3.1 Flash-Lite仅用了4分钟,token消耗最少,且正确率最高。
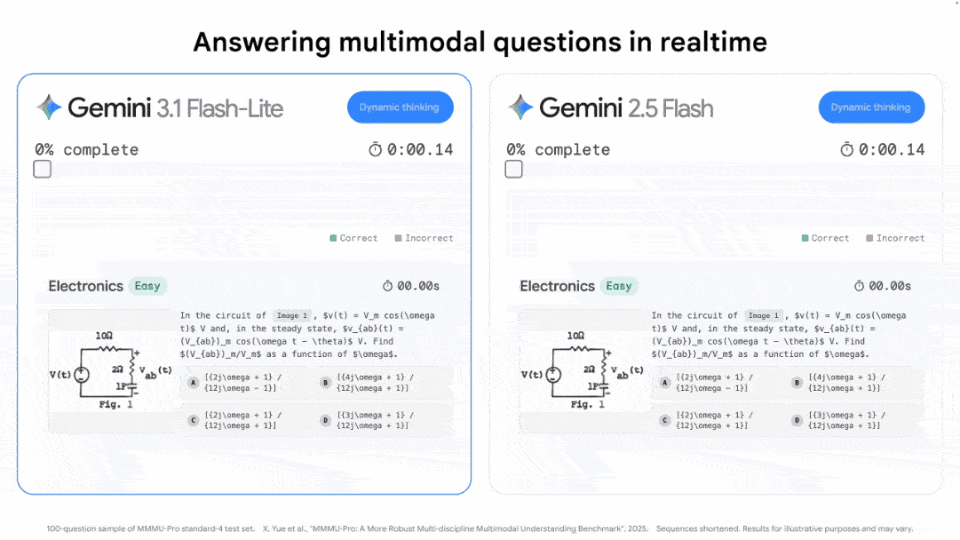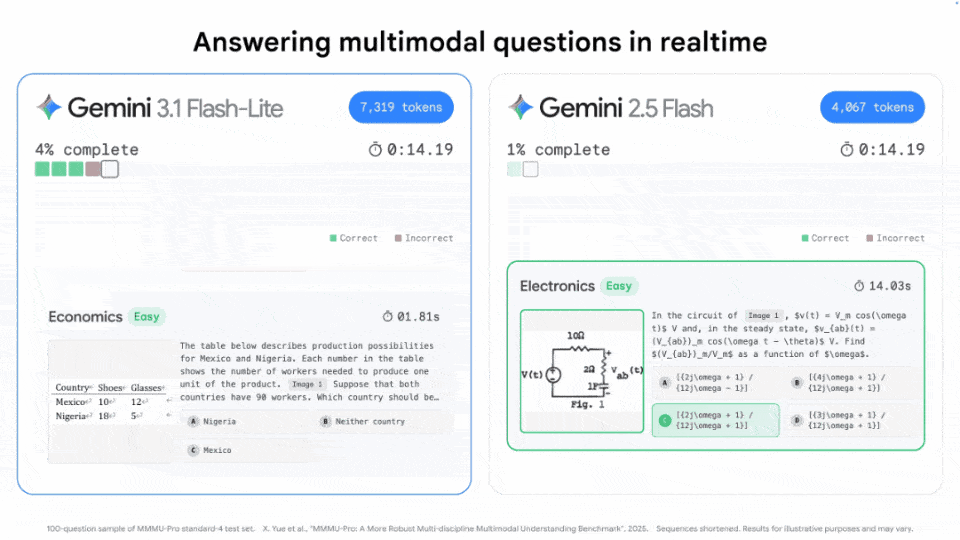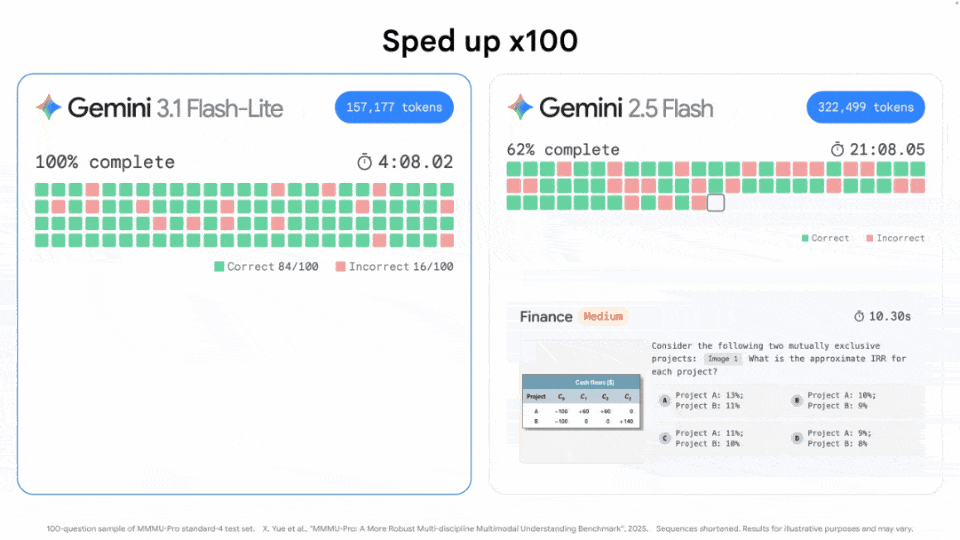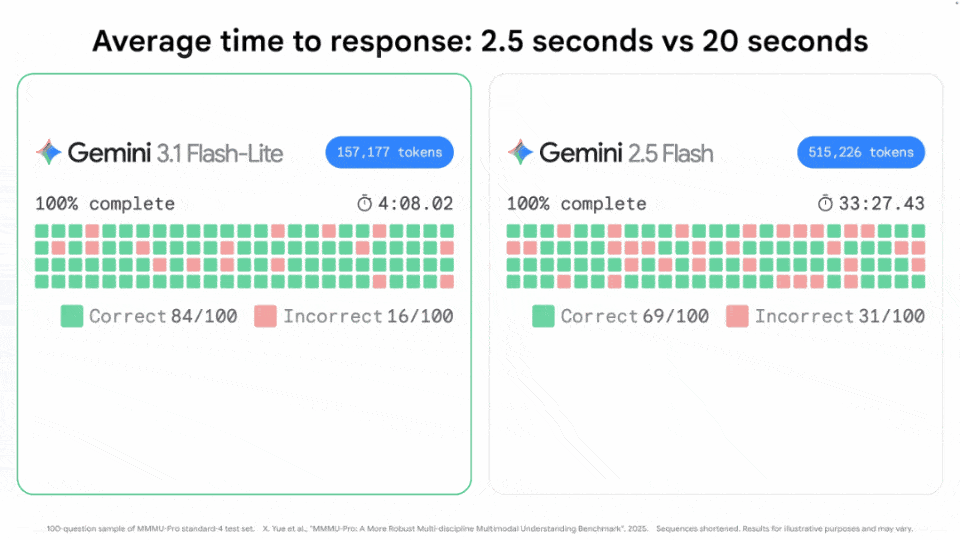
毫不夸张地说,3.1 Flash-Lite几乎可以做到「瞬时」输出。
上传一份任何PDF、文本、图片、视频、音频,它能极速转成Markdown格式。
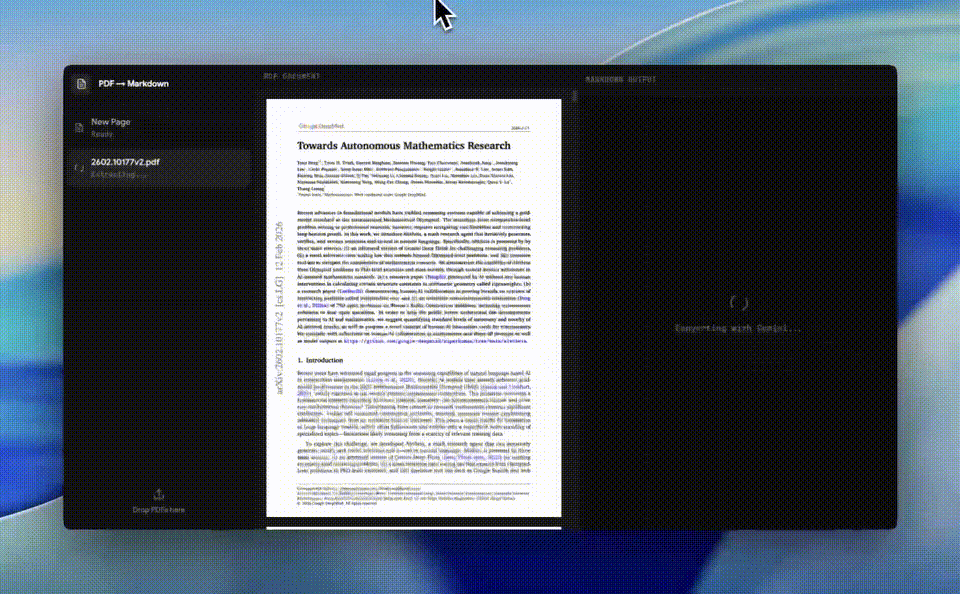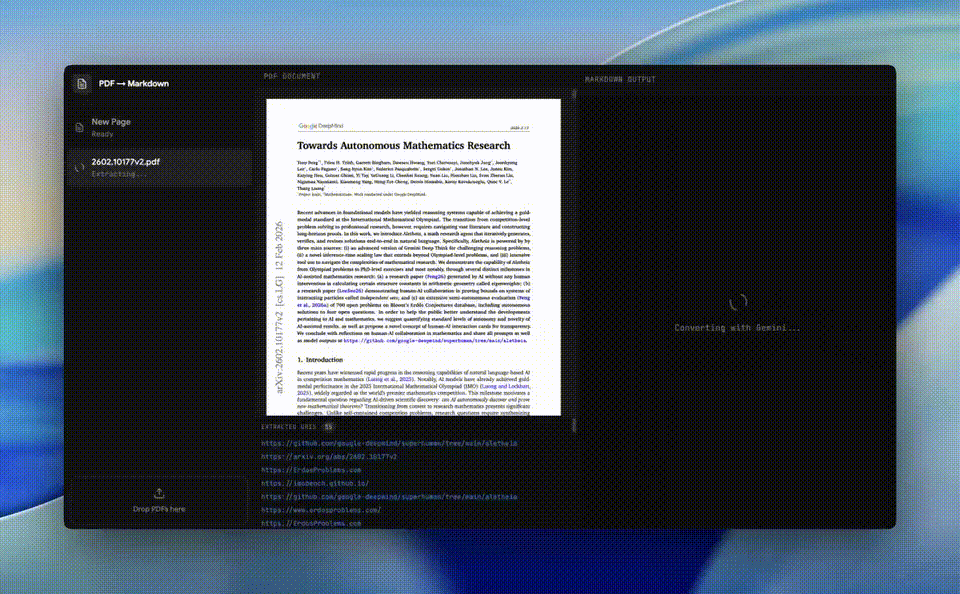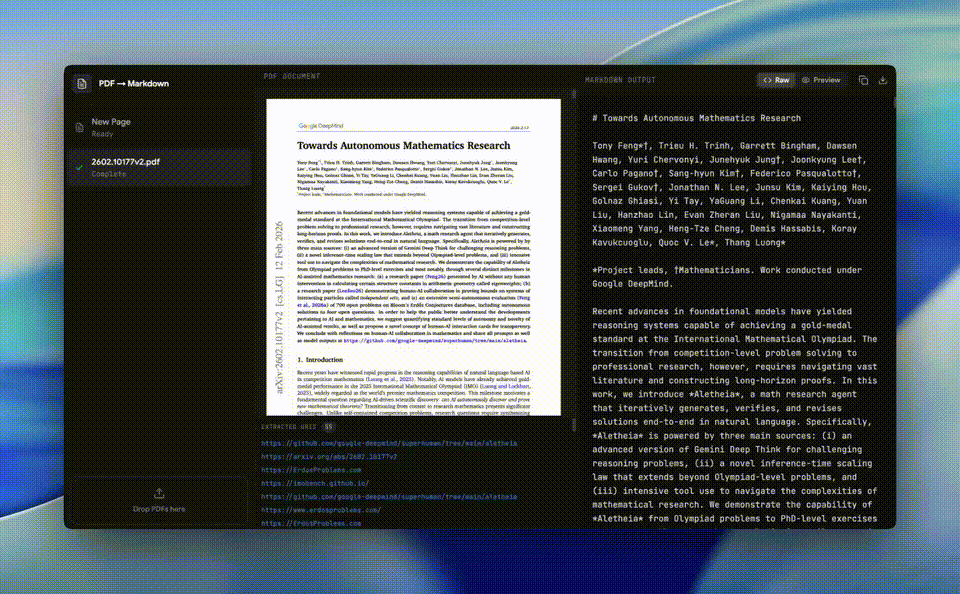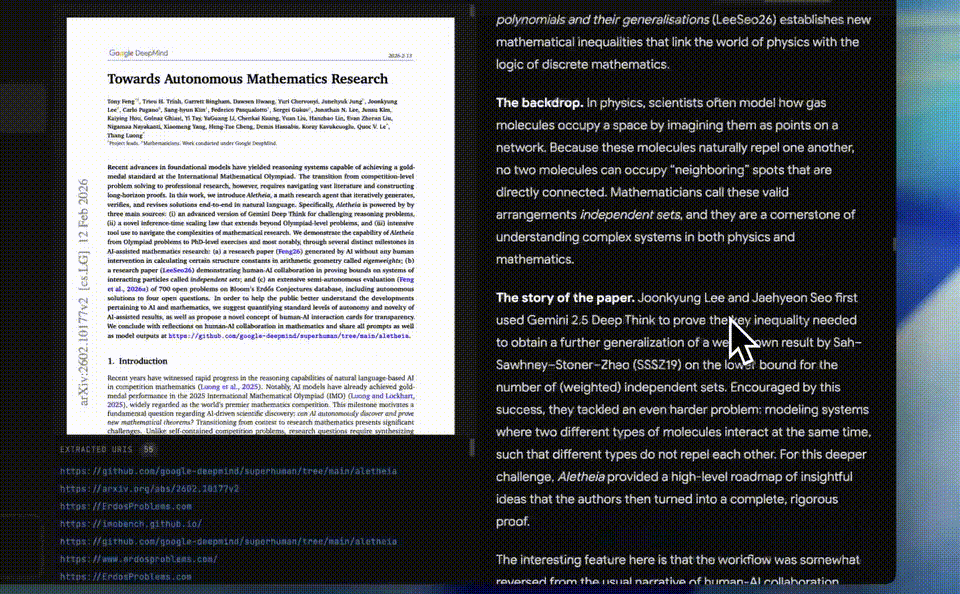
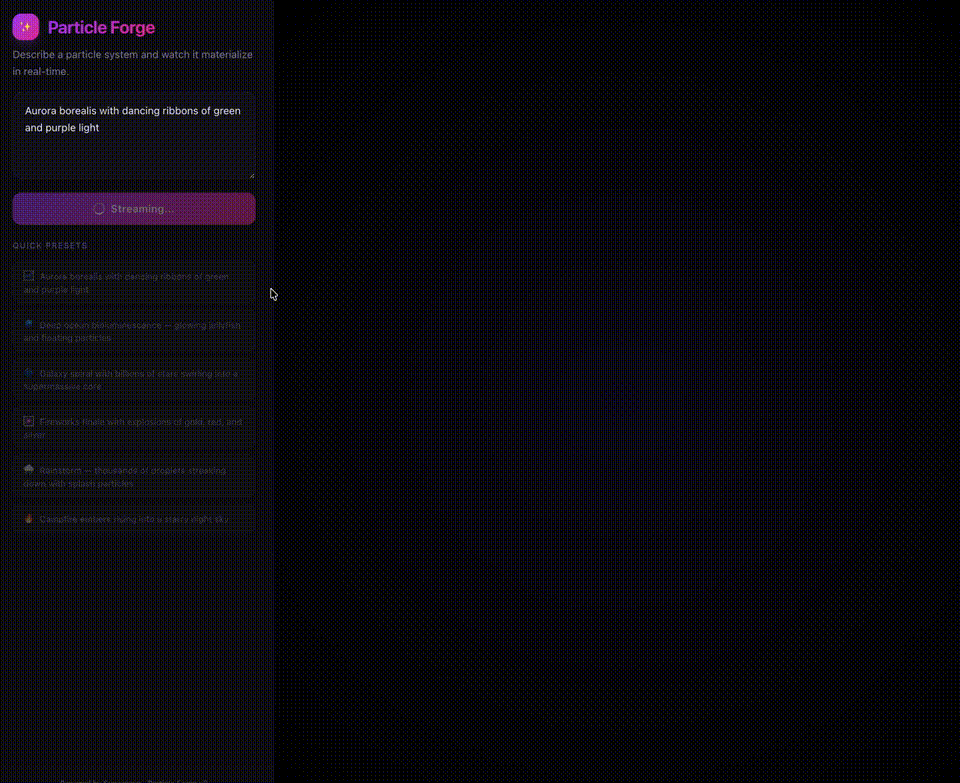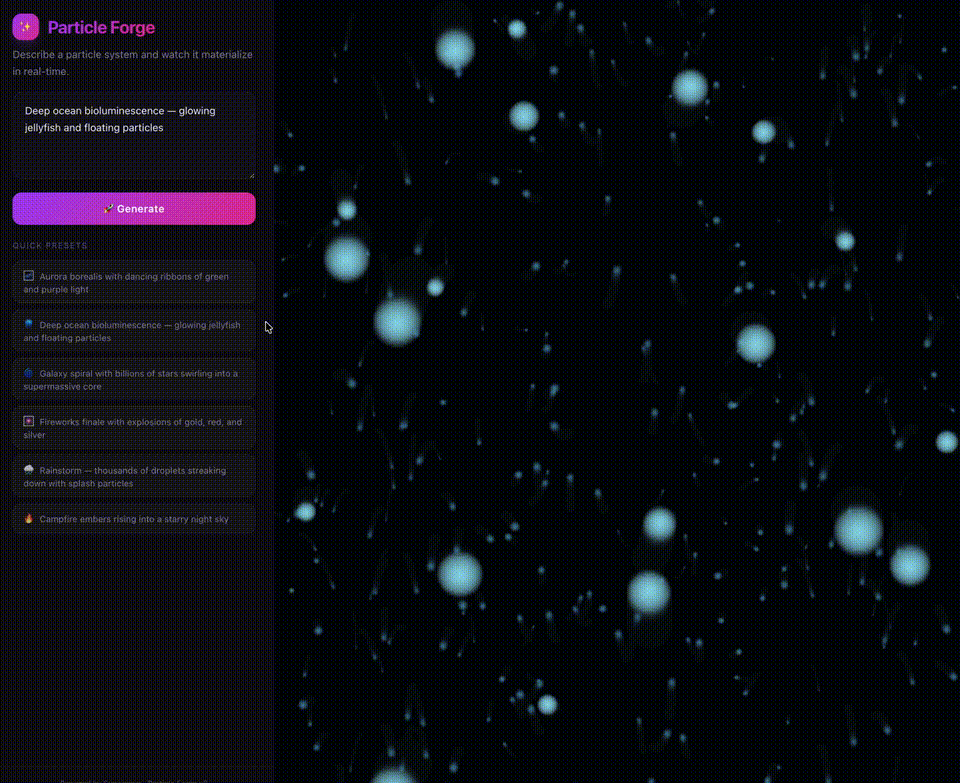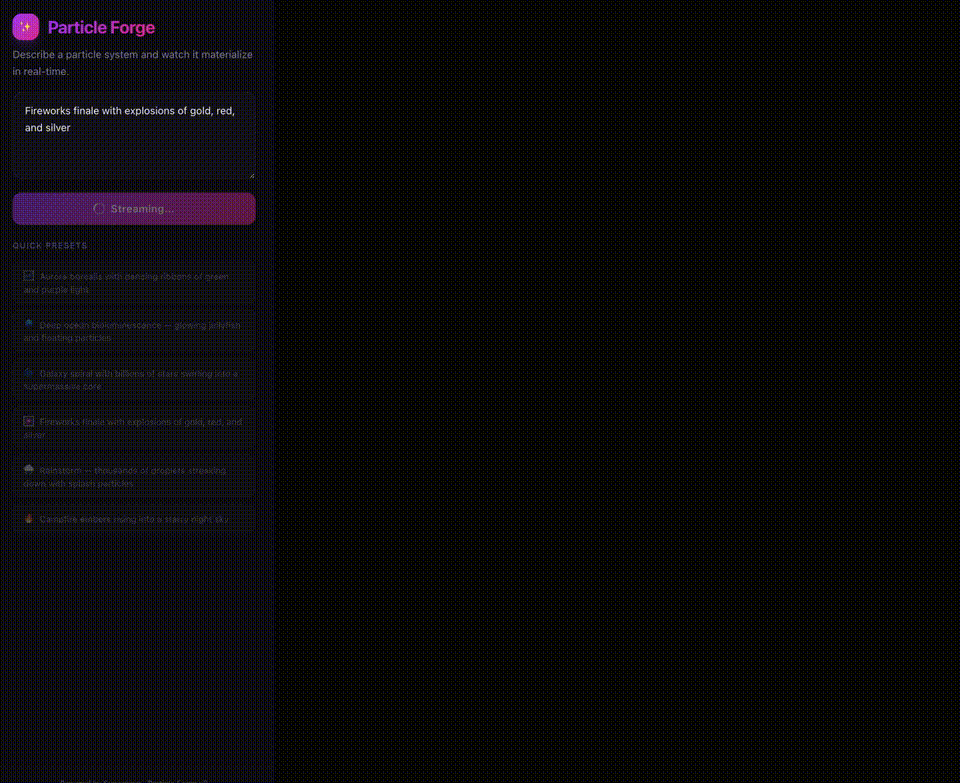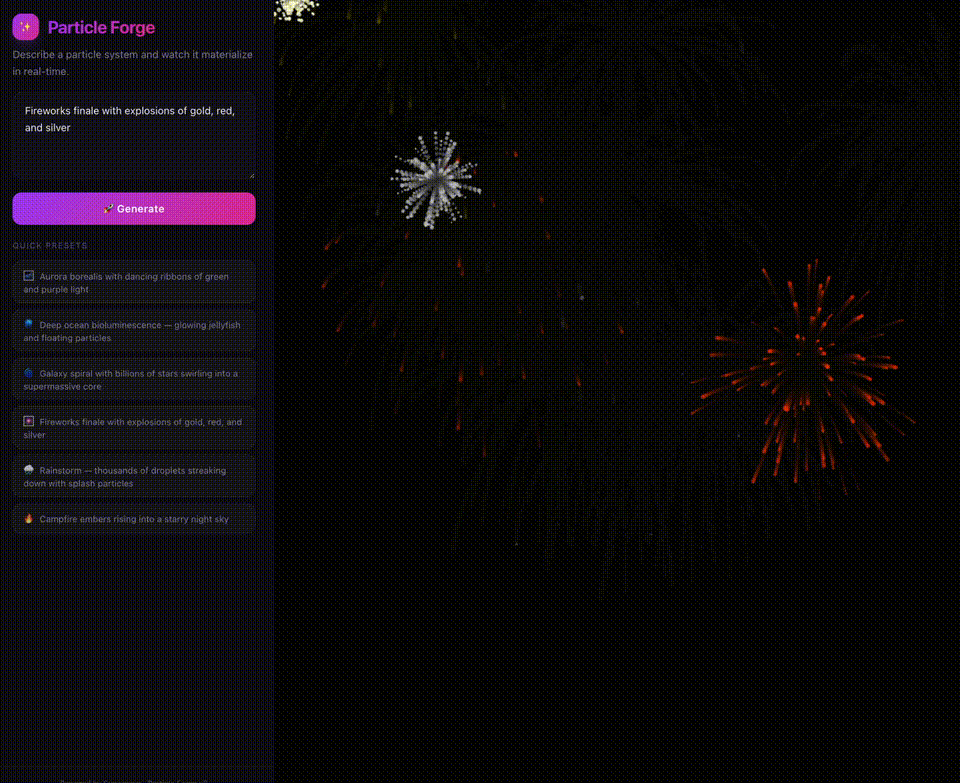
又或是,3.1 Flash-Lite「粒子锻造器」,迅速出模拟不同的动态效果,堪称惊艳。
目前,开发者已经可以通过Google AI Studio的Gemini API体验预览版,企业用户可通过Vertex AI接入。
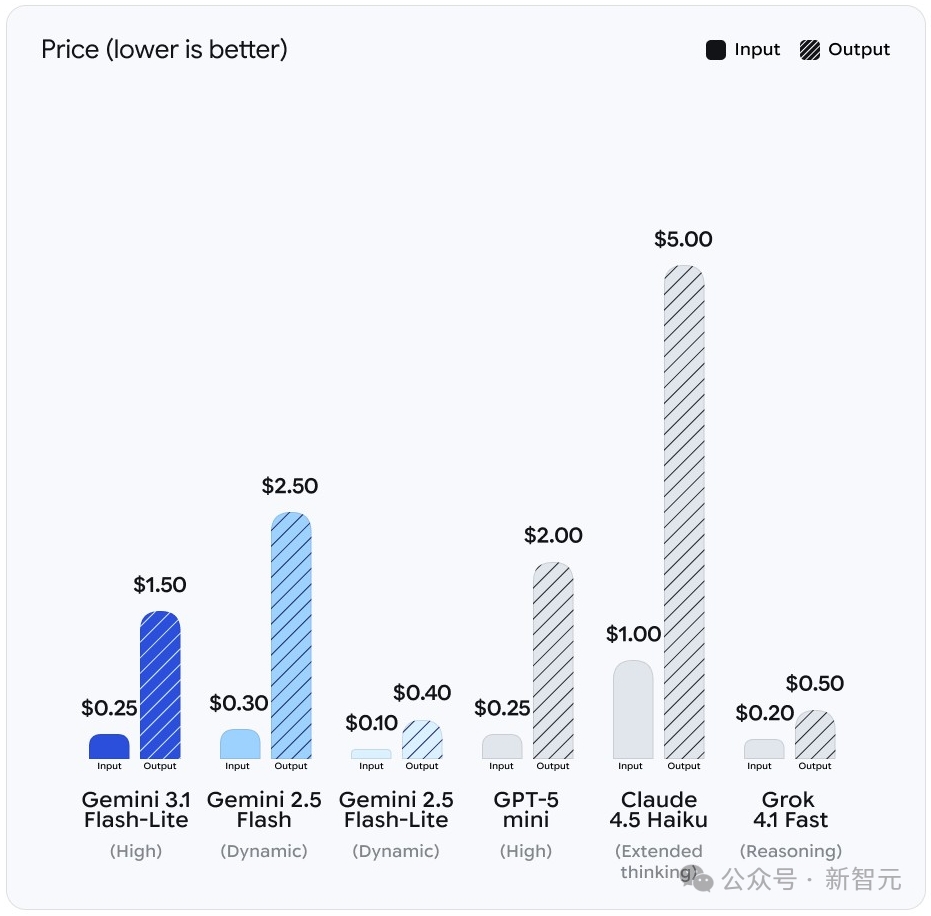
用1/4的价格,跑出5倍的速度
先看最直观的数字。
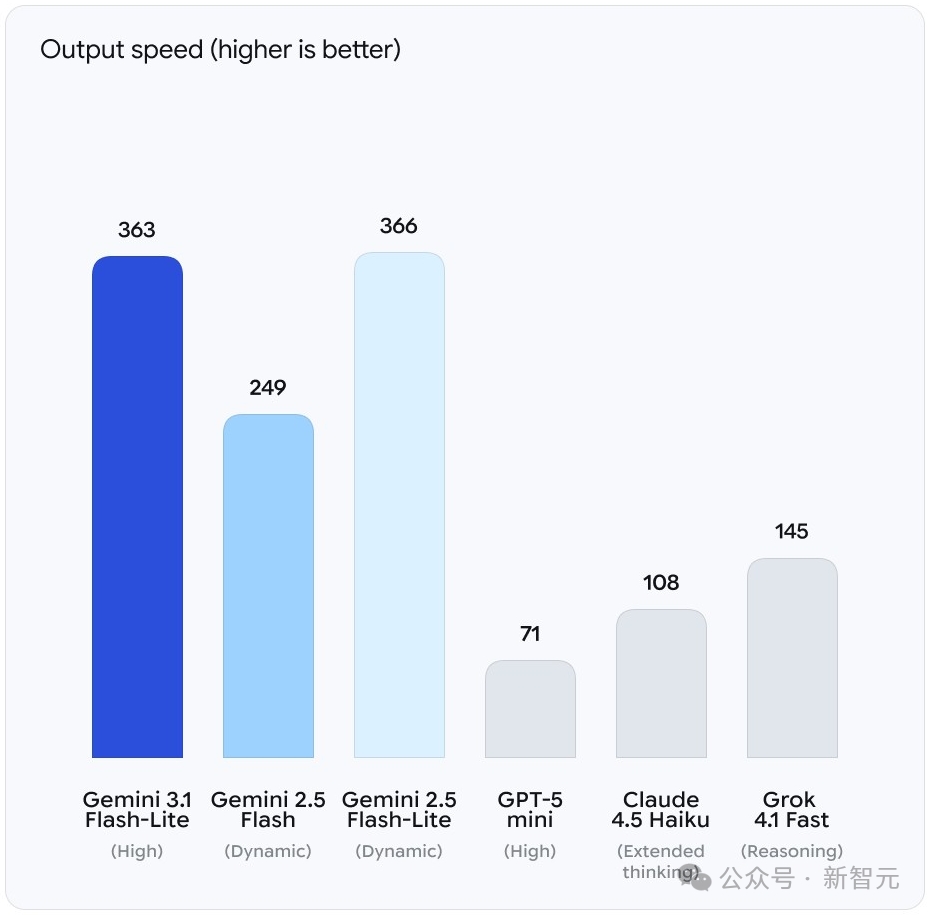
3.1 Flash-Lite的输出速度达到363 tokens/s,跟自家2.5 Flash-Lite(366 tokens/s)几乎持平,但把上一代Gemini 2.5 Flash(249 tokens/s)远远甩在了身后。
而那些「贵族选手」呢?
GPT-5 mini只有71 tokens/s,Claude 4.5 Haiku也不过108 tokens/s,Grok 4.1 Fast稍好一些,145 tokens/s。
换句话说,Flash-Lite的速度是GPT-5 mini的5倍,是Claude 4.5 Haiku的3.4倍,价格却只有后者的四分之一。
再看具体定价。
3.1 Flash-Lite输入0.25美元/百万Token、输出1.50美元/百万Token。
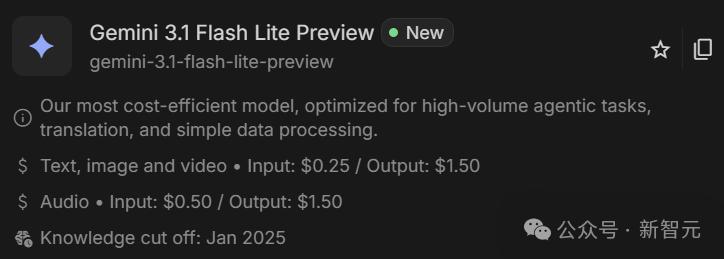
3.1 Flash-Lite比3.1 Pro便宜8倍
对比之下,GPT-5 mini的输出价格是2.00美元,Gemini 2.5 Flash是2.50美元,而Claude 4.5 Haiku更是高达5.00美元,整整贵了3倍还多。
一句话概括:跑得比你快,还比你便宜,跑分还比你高。
跑分碾压,小模型的「越级挑战」
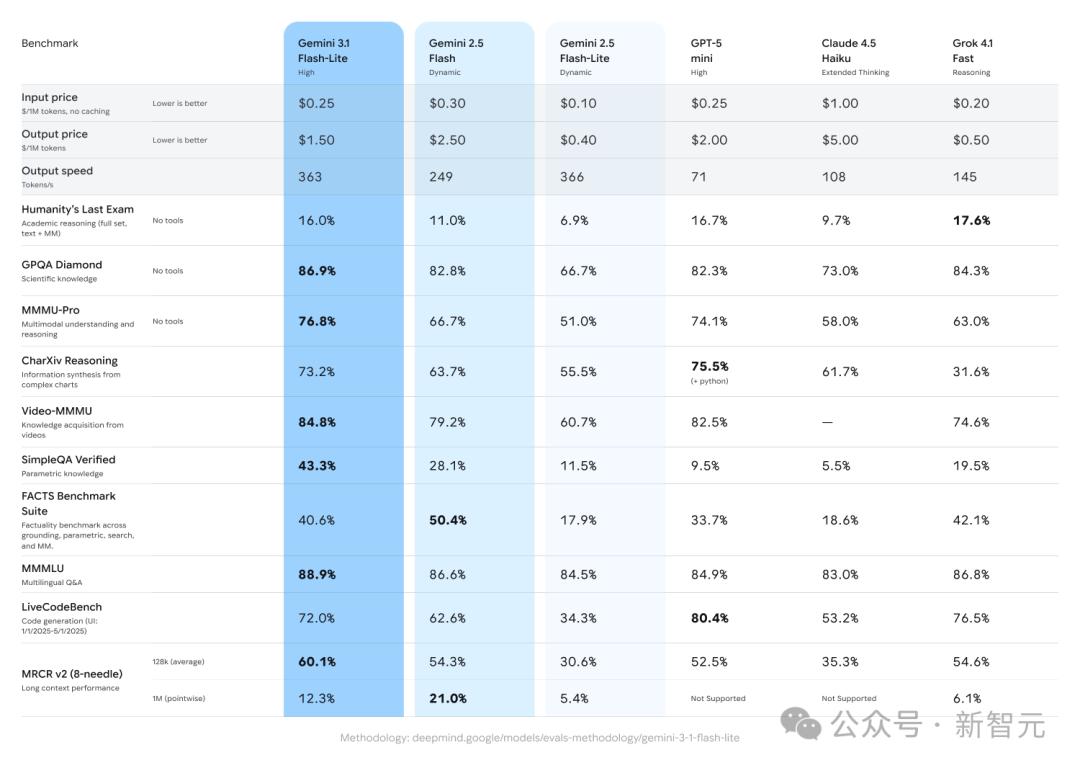
在最考验科学知识和推理能力的GPQA Diamond上,3.1 Flash-Lite直接轰出86.9%的高分。
这一成绩不仅碾压了GPT-5 mini的82.3%和Claude 4.5 Haiku的73.0%,甚至把体量更大、价格更贵的Gemini 2.5 Flash(82.8%)也踩在了脚下。
多模态理解方面同样强悍。
在MMMU-Pro测试中,Flash-Lite拿下76.8%,力压GPT-5 mini(74.1%)、Gemini 2.5 Flash(66.7%)、Grok 4.1 Fast(63.0%)和Claude 4.5 Haiku(58.0%)。
在事实准确性测试SimpleQA Verified中,差距更是断崖级。
Flash-Lite以43.3%的准确率遥遥领先,而Gemini 2.5 Flash为28.1%,GPT-5 mini仅有9.5%(4.5倍),Claude 4.5 Haiku更是低到5.5%(近8倍)。
多语言能力方面,MMMLU测试中Flash-Lite以88.9%登顶,超过了Gemini 2.5 Flash的86.6%和GPT-5 mini的84.9%,在这个价位段里没有对手。
在视频理解领域,Video-MMMU得分84.8%,同样是同级别最高,GPT-5 mini(82.5%)和Gemini 2.5 Flash(79.2%)均不及。
当然,3.1 Flash-Lite也并非没有短板。
在LiveCodeBench代码生成测试中,Flash-Lite得分72.0%,虽然不低,但GPT-5 mini凭借80.4%明显更强,Grok 4.1 Fast也有76.5%。
在Humanity's Last Exam中,Flash-Lite得分16.0%,与GPT-5 mini的16.7%基本持平,但Grok 4.1 Fast以17.6%拿到了这个级别的最高分。
但别忘了一个核心事实:Flash-Lite的价格只有这些对手的几分之一。
Arena打进全球前40
实验室跑分只是一面,真刀真枪的盲测对战才见真章。
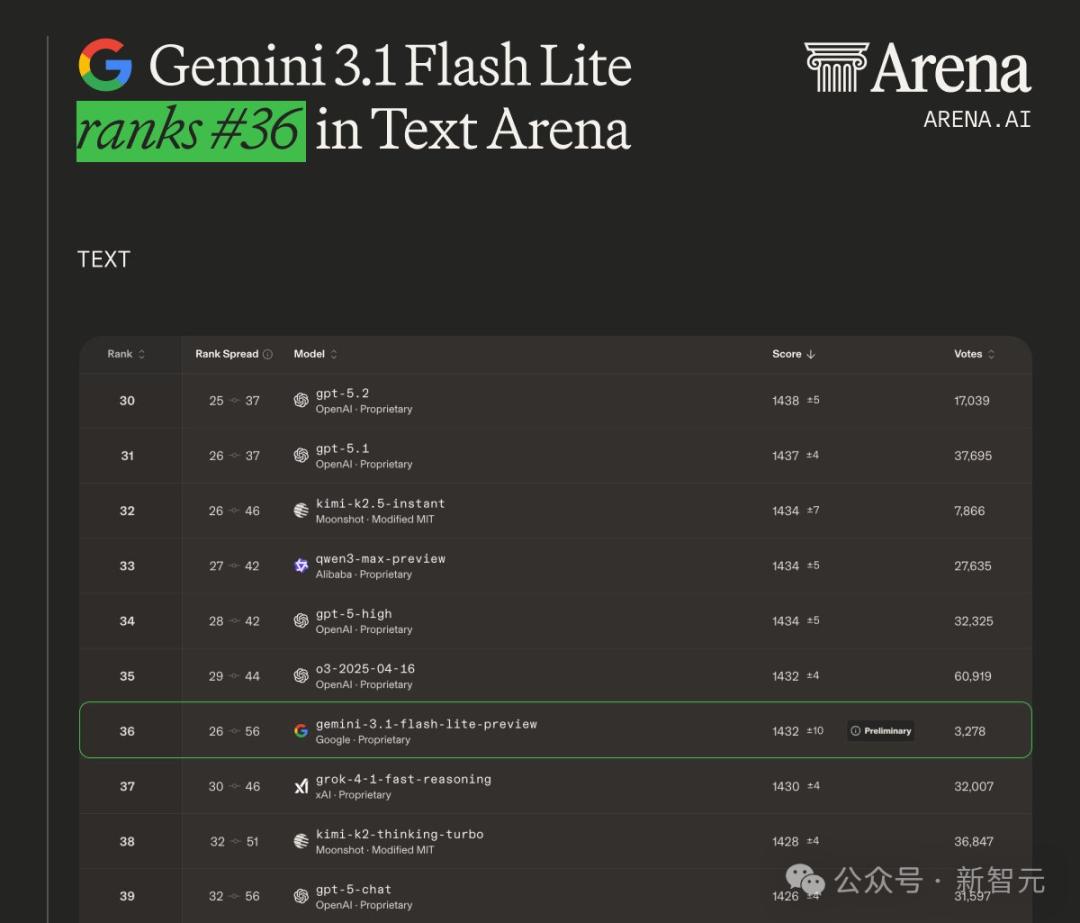
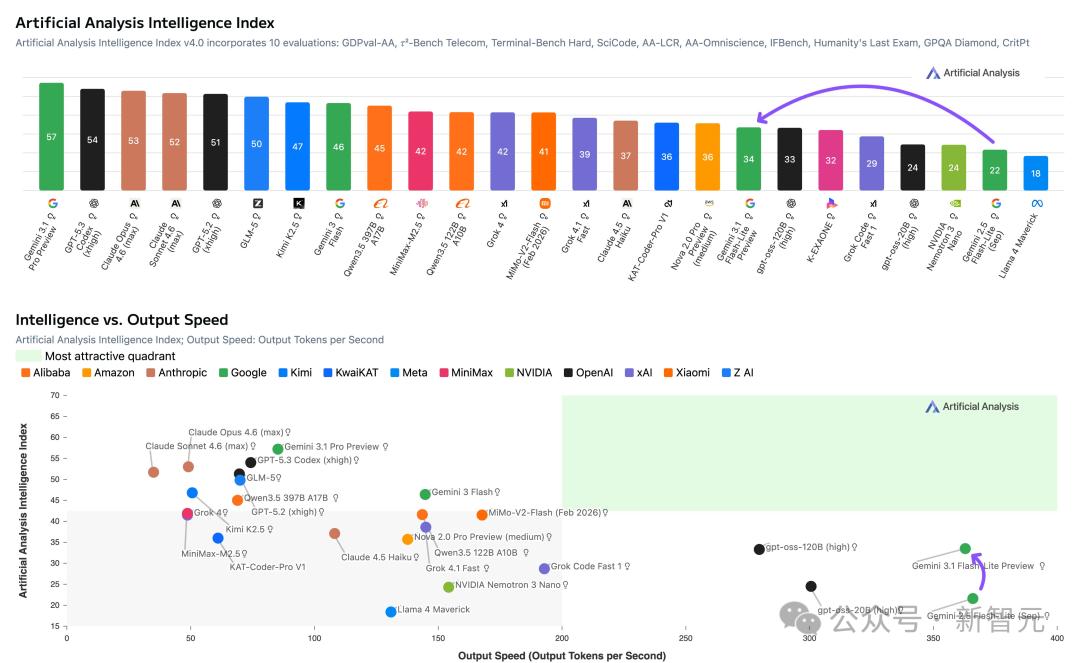
在Chatbot Arena的文本竞技场中,3.1 Flash-Lite以1432的Elo分数排名第36。
它身边的邻居是o3(1432分)和GPT-5 High(1434分),而身后紧跟着的是Grok 4.1 Fast Reasoning(1430分)。
一个定价0.25美元的轻量模型,Elo分数和OpenAI的旗舰推理模型o3打成平手,这个性价比足够让人震惊。
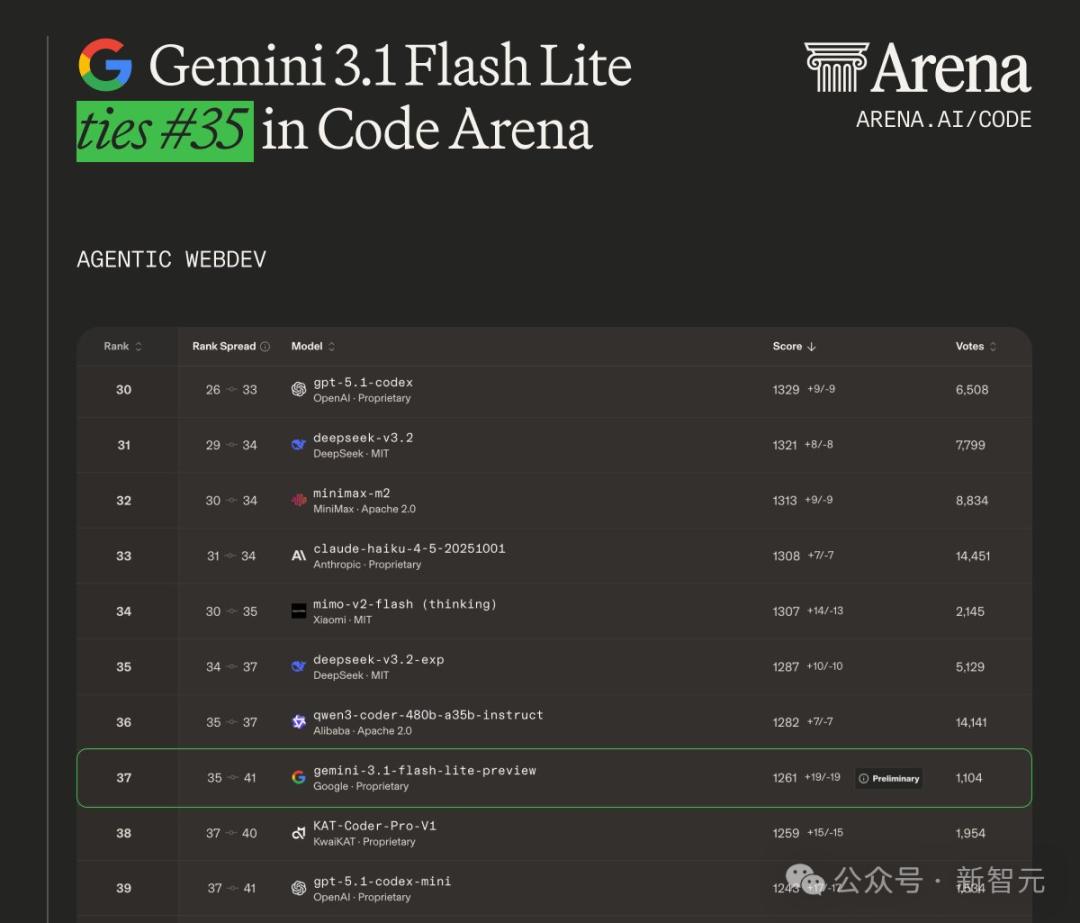
在代码竞技场中,3.1 Flash-Lite得分1261,排名并列35。
它在这里的对手包括Claude Haiku 4.5(1308分,第31名)和DeepSeek V3.2(1321分,第34名),差距不算大,但确实还有提升空间。
在Artificial Analysis评测中,3.1 Flash-Lite在输出速度和成本效益上,目前业界最优。
「思考深度」可调
除了硬核性能,3.1 Flash-Lite还标配了thinking levels功能,开发者可以自由设定模型在每个任务上投入多少推理资源。
- 批量翻译、内容审核、数据分类这类高频低复杂度任务跑浅思考模式,速度和成本压到极致。
- 生成UI界面、构建模拟环境、执行多步骤复杂指令?切到深度推理模式,效果不输大模型
实测:轻量模型的重量级表现
在实际测试中,3.1 Flash-Lite展现出了远超其定位的能力。
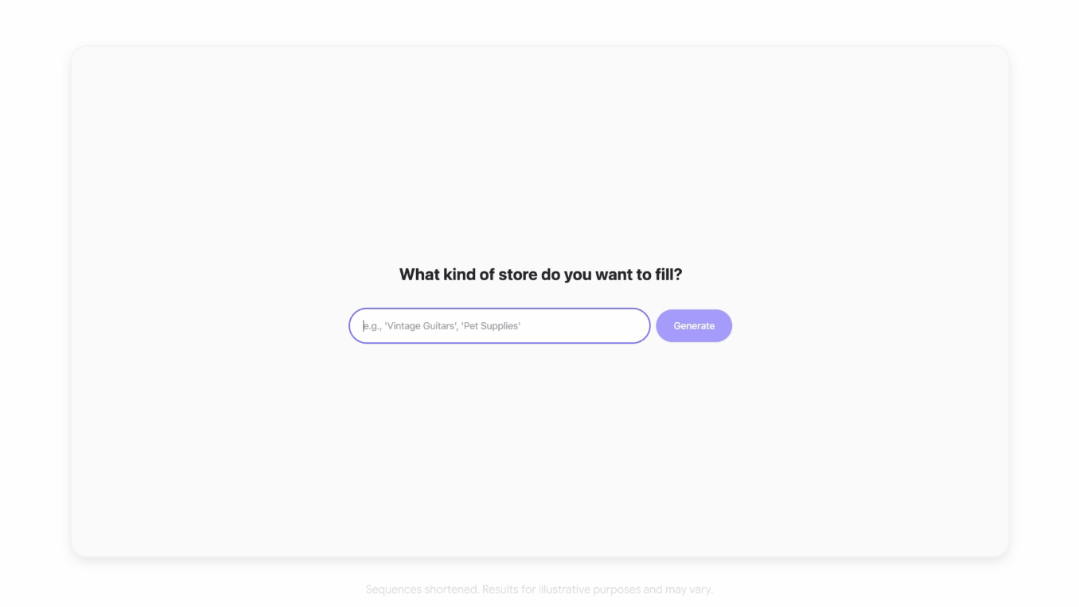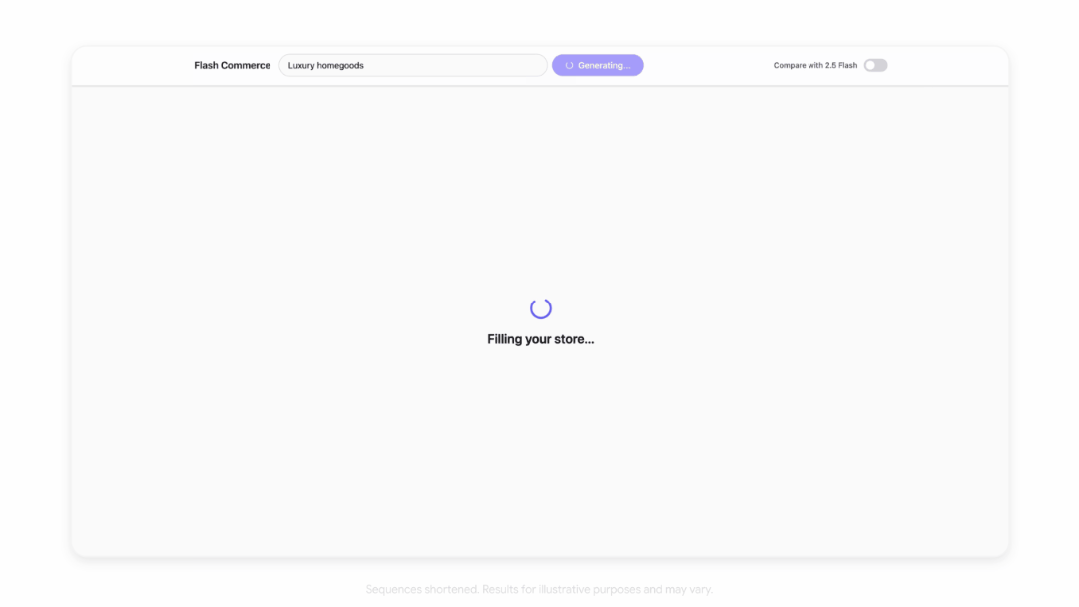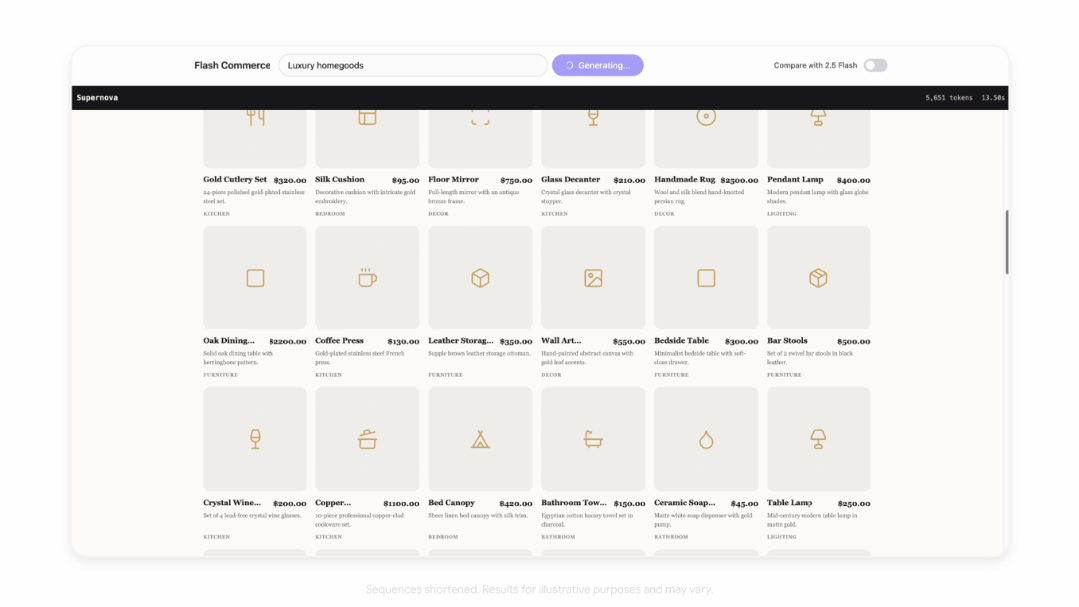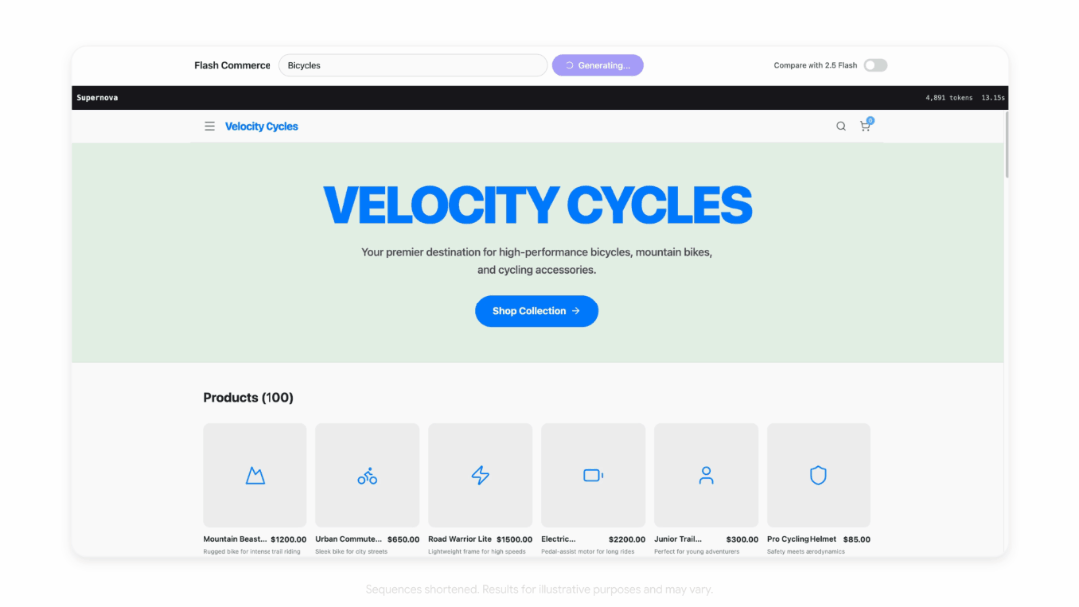
电商场景:瞬间填满原型图。
给出一句指令,Flash-Lite就能在几秒内用几十个品类、数百款商品填满一整个电商界面原型,包含名称、价格、分类、图片占位。
这在以往,需要设计师手动填充半天的工作,现在一个Prompt搞定。
实时数据看板:天气预报+历史分析。
Flash-Lite能够结合最新的天气预报接口和历史数据,实时生成动态的天气数据可视化看板。
对于需要快速搭建数据展示层的开发者来说,这个能力直接省掉了一个「前端工程师」。
SaaS AI智能体:多步任务自动化。
Flash-Lite可以构建处理多步骤灵活任务的SaaS智能体,帮助企业自动化客户工单处理、订单跟踪等流程。
在低延迟和低成本的加持下,这类高频调用场景正是Flash-Lite的主战场。
海量内容处理:快速分析归类。
面对大批量的图片、文档、用户评论等非结构化内容,Flash-Lite还能够快速完成分析、标签化和归类整理。

性价比赛道,彻底变天
3.1 Flash-Lite的发布,标志着AI竞争进入了一个全新的阶段。
过去,各家大模型都在卷「谁最强」——ARC-AGI刷分、HLE拼推理、代码竞赛争排名。
但Flash-Lite的出现,把战场拉到了另一个维度。
光卷性能已经不够了。谁能用最低的成本交付最高的质量,谁才是真正的赢家。

用几分之一的价格打出旗舰级效果、用5倍的速度碾压竞品、在事实准确性上断崖领先,谷歌用Flash-Lite告诉所有人:在性价比这条赛道上,它已经跑在了前面。
而对于全球数百万开发者来说,这可能是目前最值得关注的模型之一。
毕竟,在真实的产品场景中,成本和速度有时比跑分更重要。
参考资料:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/
https://storage.googleapis.com/deepmind-media/gemini/gemini_3-1_flash-lite_model_evaluation.pdf


