

10月14日凌晨,AI领域知名专家安德烈·卡帕西(Andrej Karpathy)发布了名为"nanochat"的新开源项目,他形容这是自己写过的"最不受约束"的疯狂项目之一。
与早期仅涵盖预训练的nanoGPT不同,新的nanochat是一个极简的、从零开始的全栈训练/推理流程,通过依赖项最少的单一代码库实现了一个简易版ChatGPT的完整构建。
nanochat的使用流程非常简单:你只需要租用云GPU服务器,运行单个脚本,最快4小时后就能在类似ChatGPT的网页界面中与自己训练的大语言模型(LLM)对话。
nanochat是什么?
从卡帕西提供的原理来看,Nanochat打包了从零开始制造一个Chatbot所需的所有步骤和工具,这其中包括:
1. 数据准备: 从原始网络文本(如FineWeb数据集)开始,创建分词器(tokenizer),把海量文本变成模型能理解的数字。
2. 模型预训练: 在大规模数据上训练一个基础的Transformer模型,让它学习语言的语法、事实和基本推理能力。这是最耗时、最核心的一步。
3. 对齐微调 :
- a. 指令微调 : 使用高质量的问答、对话数据,教模型如何像一个助手一样遵循指令、与人对话。
- b. 强化学习 : (可选阶段)通过奖励和惩罚,进一步提升模型在特定任务(如数学解题)上的表现。
4. 模型推理: 提供了一个高效的引擎,让你可以在命令行或一个类似ChatGPT的网页界面中,与你亲手训练出来的模型进行实时对话。
5. 评估 ( 训练完成后,系统会自动生成一份详细的“成绩单”(报告),展示模型在多个标准测试(如数学、代码、常识推理)上的表现。
Karpathy之前的nanoGPT项目主要关注第2步:模型预训练。它是一个极简的GPT模型训练代码,目的是为了教学,让大家理解大模型是怎么训练出来的。
而nanochat则是一个全栈(Full-Stack)项目,它不仅包含了nanoGPT的预训练部分,还补全了之后的所有关键步骤(指令微调、强化学习、推理、UI界面),最终交付一个可以实际对话的聊天机器人。
而实现这一切,只靠着卡帕西手敲的8000行代码。
卡帕西做这个nanochat的意义是什么呢?
首先是教育和学习,它是目前理解“如何从零构建一个ChatGPT”的最佳学习资料。它让普通开发者和研究者有机会用相对低廉的成本亲手“烹饪”出一个属于自己的小型聊天模型,并完整地体验从一堆原始文本到一个智能对话助手的全过程。
其次是提供一个研究和实验平台。 为研究人员提供了一个轻量级、可控、可复现的实验平台。他们可以在这个框架上快速测试新的模型架构、训练方法或对齐技术,而不必动用昂贵的大规模计算资源。
最后,X上的网友还发掘了它的新可能,他认为这套系统完全可以成为硬件评估的新基准。
这真是太棒了。这应该成为硬件评估的新基准——我们只需报告一个有序三元组:
● 端到端训练总成本(美元)
● 端到端训练总耗时(分钟)
● 在特定测试集上的综合性能表现
而且整个过程都具备高度可复现性。
100美元,从头训练一个AI
那这个Nanochat到底能多省钱?
● 仅需约100美元(在8XH100节点上训练约4小时),你就能训练出一个小型ChatGPT克隆版,可以进行基本对话,创作故事诗歌,回答简单问题

(在网页界面中,显示的是一个耗时4小时、花费100美元的nanochat模型进行对话。已经可以写诗了。)
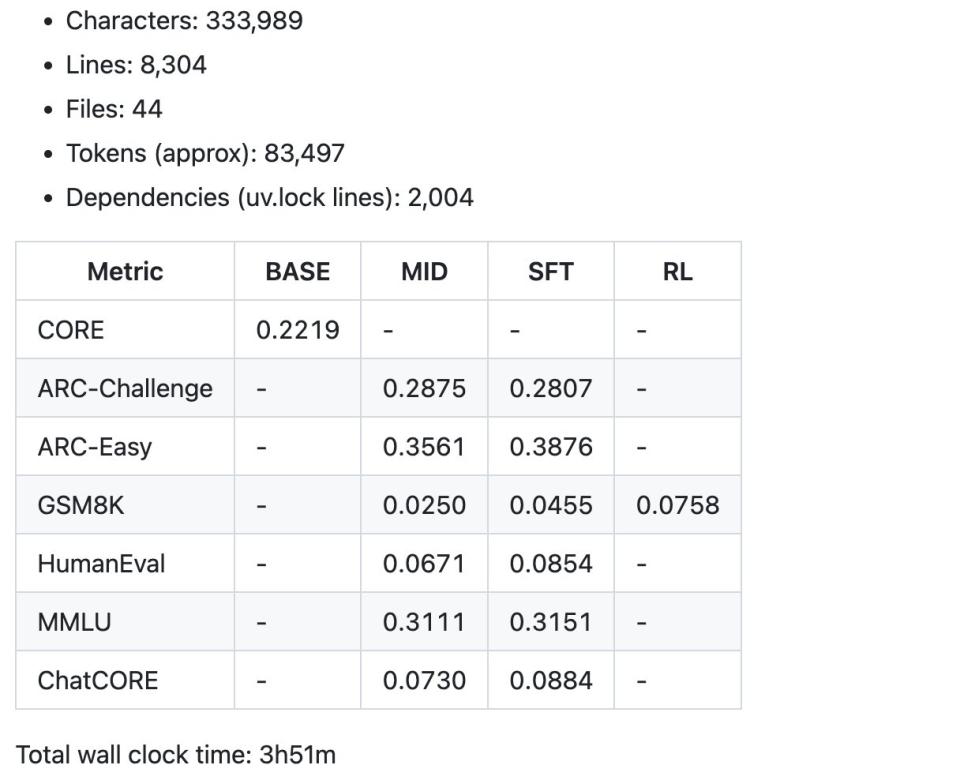
(nanochat报告卡片中展示了这次100美元“速通”训练所生成的部分总结性指标。整体效果很不错。)
● 训练约12小时即可在CORE指标上超越GPT-2
● 如果将预算提升到约1000美元(训练41.6小时),模型会变得更加连贯,能够解决简单的数学和编程问题,并通过多项选择题测试。例如,一个深度为30的模型经过24小时训练(计算量相当于GPT-3 Small 125M或GPT-3的1/1000),在MMLU上能达到40多分,在ARC-Easy上达到70多分,在GSM8K上达到20多分。
卡帕西亲自揭秘背后技术
在X平台上,卡帕西和网友展开问答对话,公开了nanochat的幕后开发详情和相关技术。
以下为问答精选:
问:这个模型的训练/基础架构是基于什么样的模型设计?
卡帕西:nanochat的模型架构基本上与Meta Llama模型类似,但进行了一些简化,并吸收了一些来自其改进版modded-nanoGPT项目的设计思路。其目标是为此类规模的模型建立一个“稳健的基线”。
主要架构特征包括:
● Dense Transformer(稠密模型Transformer)
● Rotary Embeddings(旋转位置编码),无显式位置嵌入(positional embeddings)
● QK Norm(对Query和Key向量进行归一化)
● Embedding与Unembedding权重不共享(untied weights)
● 在Token Embedding之后进行归一化处理
● MLP使用ReLU²激活函数
● RMSNorm中无可学习参数
● 线性层中无偏置项(bias-free linear layers)
● 采用多查询注意力机制(Multi-Query Attention, MQA)
● 输出层使用Logit Softcap技术
● 优化器采用的是Muon + AdamW组合,这很大程度上受到了modded-nanoGPT的影响。卡帕西提到,他计划未来通过精心调整Adam优化器每个模块的学习率来尝试移除Muon,但目前这项工作尚未完成。
问:我是否可以用自己的数据来训练它?比如我所有的Notion笔记、健康数据,以及和其他大模型的对话记录?就像打造一个真正懂我的个人聊天机器人?
卡帕西:我觉得这个代码库并不适合这个用途。你可以把这些微型模型想象成幼龄儿童(比如幼儿园阶段),它们确实不具备那些大型模型的原生智力。如果你用自己的数据对它进行微调/训练,可能会得到一些看似模仿你文风的有趣回应,但最终效果会显得很粗糙。
要实现你期待的效果,可能需要这样的流程:先整理原始数据,在此基础上进行大量合成数据重写(这步骤很棘手,不确定性高,属于研究范畴),然后选用顶尖开源大模型进行微调。过程中可能还需要混合大量预训练数据,以免在微调过程中损失模型原有的智能水平。
因此,说实话,要让这套流程完美运作至今仍属于前沿研究领域。
目前最可行的非技术方案,是把所有资料导入NotebookLM这类工具,它可通过RAG技术(即分块检索参考)处理你的数据。你的信息会通过上下文窗口传递给模型,但不会改变模型本身的权重。虽然模型不会真正"认识你",但这可能是当前最容易实现的近似方案了。
问:这些代码有多少是你手写的?
卡帕西:代码基本上全是手写的(配合Tab键自动补全)。我尝试过几次使用Claude/Codex这类AI编程助手,但效果完全不行,总体上反而帮不上忙。可能我的代码库风格太偏离它们训练数据的风格了。


