
跑分都满分则跑分无意义。
从AI刚刚面世,人们就执着于用各种各样的题库来测试AI到底有多聪明,不管是ChatGPT、Gemini、Grok,还是DeepSeek、Kimi、文心一言,它们发布的同时,几乎都会附上一个跑分成绩。
而事到如今,市面上流行的题库都快被AI做穿了,每一代新模型都要“霸榜碾压”,“满分横扫”,在MMLU这样的热门基准测试上,大部分模型的准确率已经超过 90%——换句话说,AI的聪明程度,人已经快评估不出来了。

好怀念那些过去的好日子,AI只要显得像个人就能通过测试(现在图灵测试已经好久没人提了)|x @PhysInHistory
“人工智能能力的评估基于基准测试,然而基准测试正在迅速饱和,失去了作为衡量工具的效用……”人类最后的考试网站首页写道,“在MMLU和GPQA这样的测试中表现良好,已不再是取得进步的有力信号,因为前沿模型在这些基准测试中的表现已经达到或超过了人类水平。”
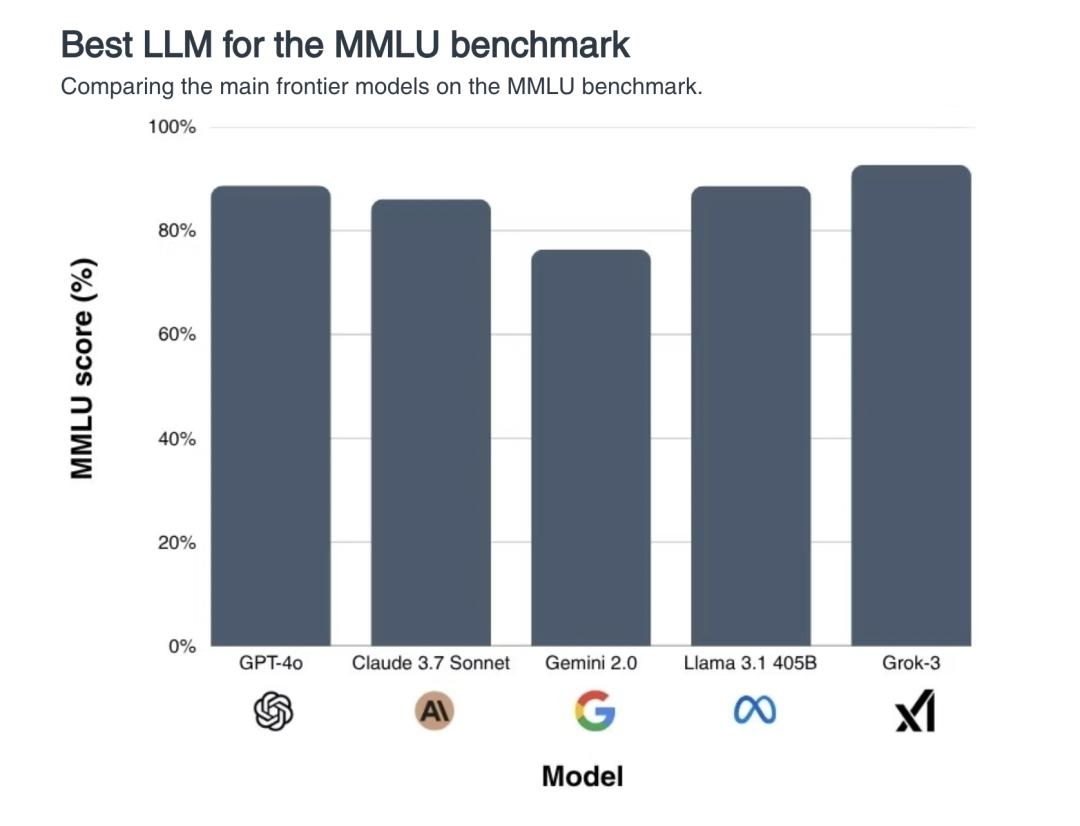
在MMLU基准测试上,前沿大模型的得分不相上下。吊诡的是,如果AI已经比人类更聪明了,那我们是否有足够的智慧去认知这一点?|bracai.eu
为了搞清楚高速进化的AI到底发展到哪一步了,也为了给它们排个名次,拉开差距,我们需要上点更难的题了。
作为目前人类最高智慧和最先进文明成果的代表,“人类最后的考试”(Humanity's Last Exam,以下简称HLE)就在这个背景下诞生了。
人类智识最后的堡垒,文科也在里面
“人类最后的考试”是一个基准测试,由Center for AI Safety和Scale AI联合创建,它的测试内容几经调整,最终在2025年3月4日确定为一套包含了2500个前沿学术难题的题库。
这些题分布在100多个不同的学科领域,可以粗略分为以下几大类:
数学(Mathematics):大量高难度数学题,包括高等代数、拓扑、范畴论、概率、图论、数论等,强调推理深度。
自然科学(Natural Sciences):物理、化学、生物、生态学、医学等。
计算机科学与人工智能(Computer Science & AI):算法、图论、马尔科夫链、程序推理等。
工程学(Engineering):复杂系统和应用性技术问题。
人文学科与社会科学(Humanities & Social Sciences):语言学、历史学、经济学、宗教研究、人类学、心理学、教育学、古典学、文化研究,应有尽有。
其他:冷门知识或小众学科(古文字、特定地方的风俗考证之类)。
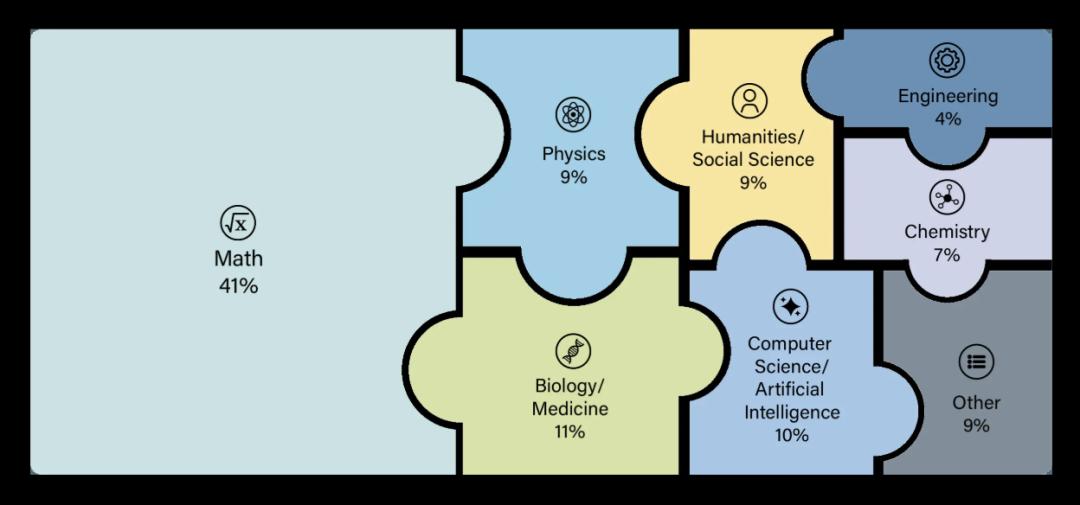
具体的题库分布,其中数学题占了41%,人文领域题占了18%(可恶啊,输掉了)|HLE
HLE最让人印象深刻的是它的多模态,这些问题不只是基于文本,还包括图表、古文字、图像、公式,这意味着AI想要回答问题,就得先读懂问题。
HLE的官网上公开了其中一部分问题。
比如下面这道古典学领域的题,要求AI把一段在墓碑上发现的罗马铭文翻译成帕米拉亚兰语(还给了音译,多贴心啊)。

问题由牛津大学墨顿学院博士Henry Tang提交|HLE
还有这道考察AI对乱成一团的古希腊男女关系的了解程度的民俗小知识题:在希腊神话中,伊阿宋的曾姥爷是谁?
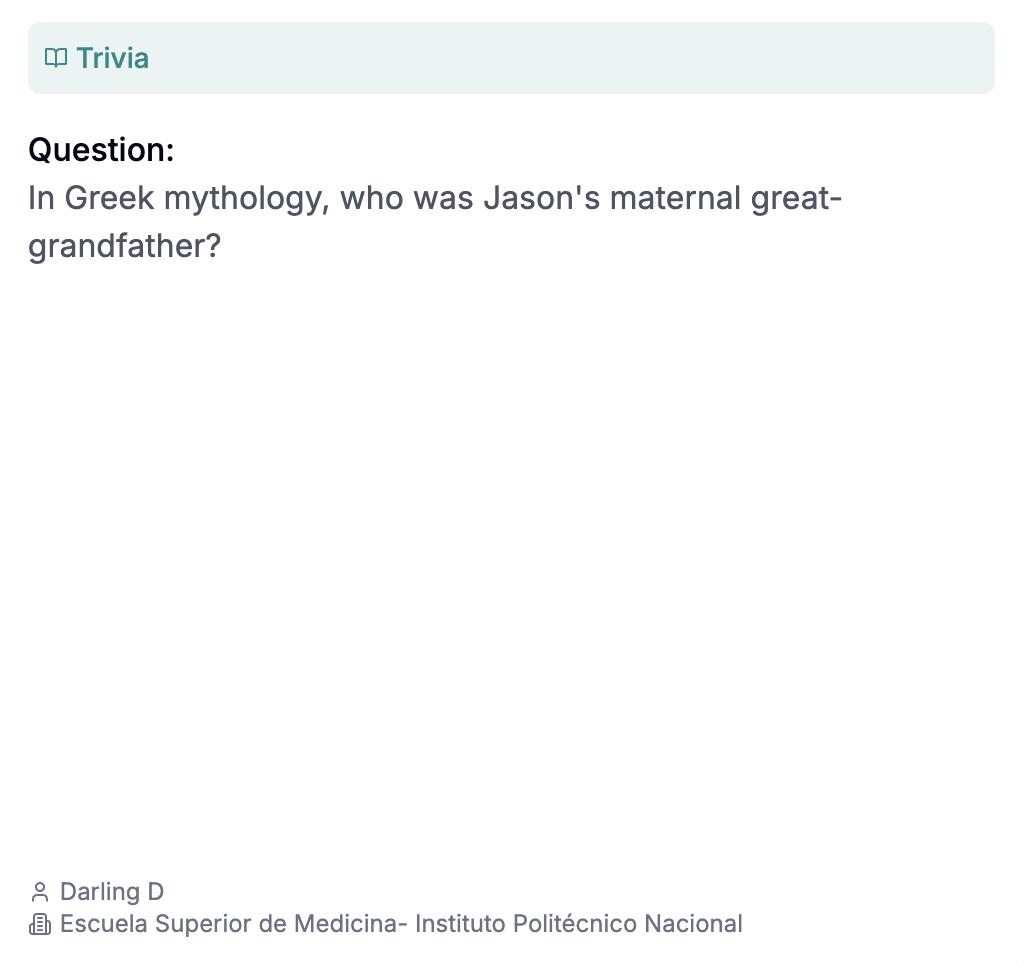
由墨西哥国立理工学院医学部的Darling D提交(我没有找到这个人,不知道为什么医学院的人会出这种题)|HLE
这道读起来像GRE考试题一样,每个词都似是而非,读着后面忘着前面的生物题,大概是问蜂鸟的籽骨支撑着多少对肌腱,明确要求用数字来回答。
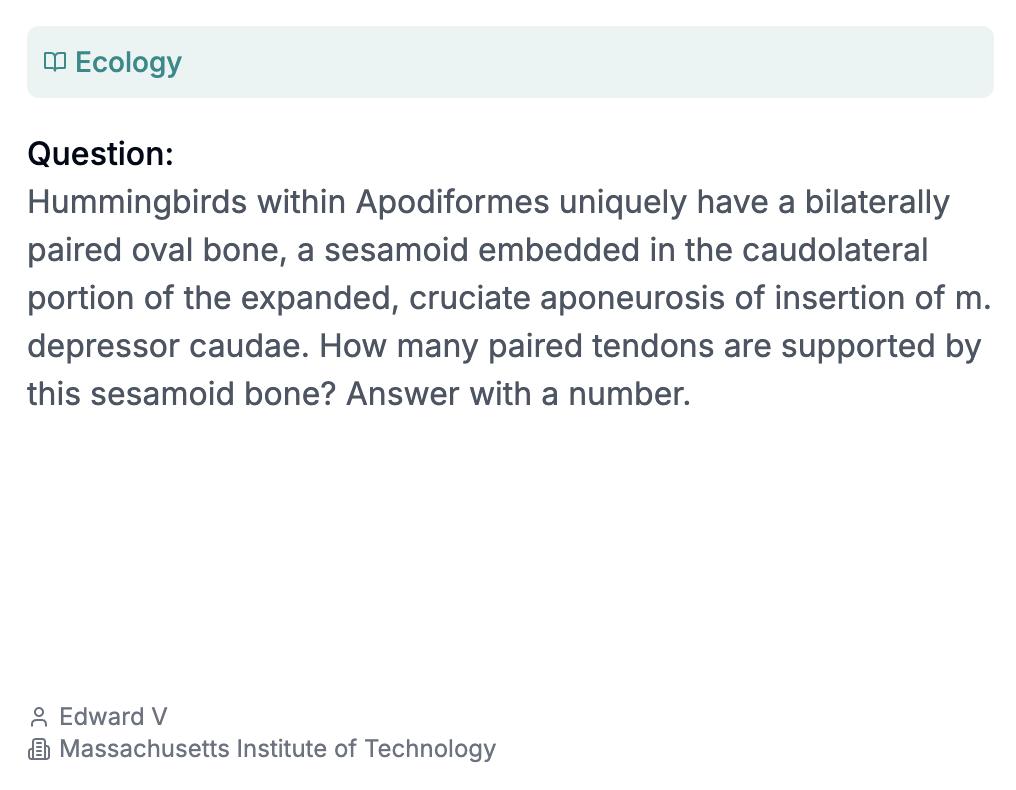
由麻省理工大学计算机系的博士Edward Vendrow提交,真是一位很博学又很会针对AI的学者,至于为什么这道题针对了AI我们等下讲|HLE
还有这道考察图论+马尔可夫链的题:

由伦敦玛丽女王大学计算机系讲师Dr. Marc Roth提交|HLE
如果你还想做更多的题,或者对题库好奇,再或者想凭一人之力和AI决一高下,可以上HLE官网查看题库。
虽然这些问题已经公开发布,供开发者测试大模型用,但是HLE称,“为了应对训练数据污染和基准测试黑客攻击问题”,他们也保留了一个private set,用于定期测量模型与公共数据集的过拟合情况,不对外公布,而这一部分才是真正用于AI模型排行榜和最终评分的核心数据。
题库里的题主要有两种形式,选择题和简答题。
选择题需要从五个以上的选项中进行选择(题库中24%的题目是多选题),而简答题需要模型输出和答案完全一致的字符串,不能语义模糊、不能不准确。在题库中,还有约14%的题目要求同时理解文字和图像。
可以说是全选C战术和谁字多谁得分战术都没用了。
“为了全人类,提交你最难的问题”
不得不说“人类最后的考试”这个名字起得真的很好,要不是这厉害中透着中二气息的名字,我可能永远也不会好奇一个冷冰冰的大模型的基准测试到底在考什么。
但HLE的发起人丹·亨德里克斯(Dan Hendrycks)一开始想的名字更厉害,叫“人类最后一战”(Humanity’s Last Stand),后来大家都觉得这个名字过分抓马,劝他放弃了。

丹·亨德里克斯,他还写了一篇文章叫《灾难性人工智能风险概述》,也还蛮有意思|The New York Times
丹·亨德里克斯也是一个神人。
25岁的时候,他联合编写了现在最热门的AI大模型基准测试MMLU,截至2024年7月,MMLU下载量已超过1亿次。30岁的时候,他发现目前AI的能力已经溢出了基准测试,MMLU已经不好使了,于是他决定做个新的测试(他还在一次采访中表示,他做HLE是因为马斯克觉得现在的基准测试都太简单了)。
目前,亨德里克斯在马斯克的人工智能公司xAI担任安全顾问,他同时也是Scale AI的顾问,为避免潜在的利益冲突,他每月只象征性地领一美元薪水,而且不持有任何公司股权。
再说回HLE。
HLE计划发起初期,也就是2024年9月,亨德里克斯公开发布文章,号召全世界的学者“为人类最后的考试交出你最难的问题”(这个说法相当有毒,因为人家并不知道HLE就是题库的名字,只看题目仿佛事关人类存亡)。
“未来的人工智能系统最终将超越所有能够创建的静态基准,因此突破基准和评估的界限至关重要。为了追踪人工智能系统距离专家级能力的差距,我们正在组建史上规模最大、范围最广的专家联盟。”在文章中他写道,“如果你觉得某个问题能被AI解答会让你印象深刻,欢迎你提交。”
为了全人类,提交你最难的问题|scale.com
交问题也不是白交的,亨德里克斯宣布,所出题目评分最高的研究者,可以瓜分50万美元的奖金——排名前50位的问题,每题可获得5000美元奖金,之后的500个问题,每题可获得500美元奖金。
关于问题本身,HLE则提出了更加严格的要求。
首先,问题的答案需要在网上搜不出来。其次,问题需要是原创的新问题,不能在以前的考试里出现过。再次,问题需要有明确的答案,而且答案应被相关领域的其他专家广泛接受,且不包含个人偏好、歧义或主观性。最后,问题应该有硕士级别以上难度,因为“根据经验,如果随机选择的本科生能够理解题目内容,那么对大模型来说这个问题可能过于简单”。
每道题提交时都必须包含题目本身、题目答案(精确的回答,或者选择题的正确选项)、详细的解题推理、所属学科,以及贡献者的姓名和机构信息。
对所有提交的问题,HLE会进行两步筛选:先把问题喂给最先进的AI去解答,如果AI无法回答,或者在多选题里的得分比随机猜的还差,那问题就会被交给人工审阅者,由他们审阅和验证答案。
在The New York Times的一次采访中,加州大学伯克利分校理论粒子物理学博士后研究员Kevin Zhou表示,他提交了一些题目,其中三道题目被选中,而这些题目“都达到了研究生考试的上限”。
最终HLE收到了来自50多个国家、500多家研究机构和企业的1000多位学者的回复,从中诞生了目前最难的AI基准测试HLE。
对AI来说,HLE难在哪?
费了这么大功夫,HLE真的难住AI了吗?
单看结果而言,是难住了。
目前为止,主流前沿模型纯文本模式下在HLE上的得分都还比较低,OpenAI最新的o3-mini(high)模型,准确率只有13%,而前阵子震撼美国的DeepSeek-R1的准确率也才9.4%。目前得分最高的是Grok4,正确率26.9%。
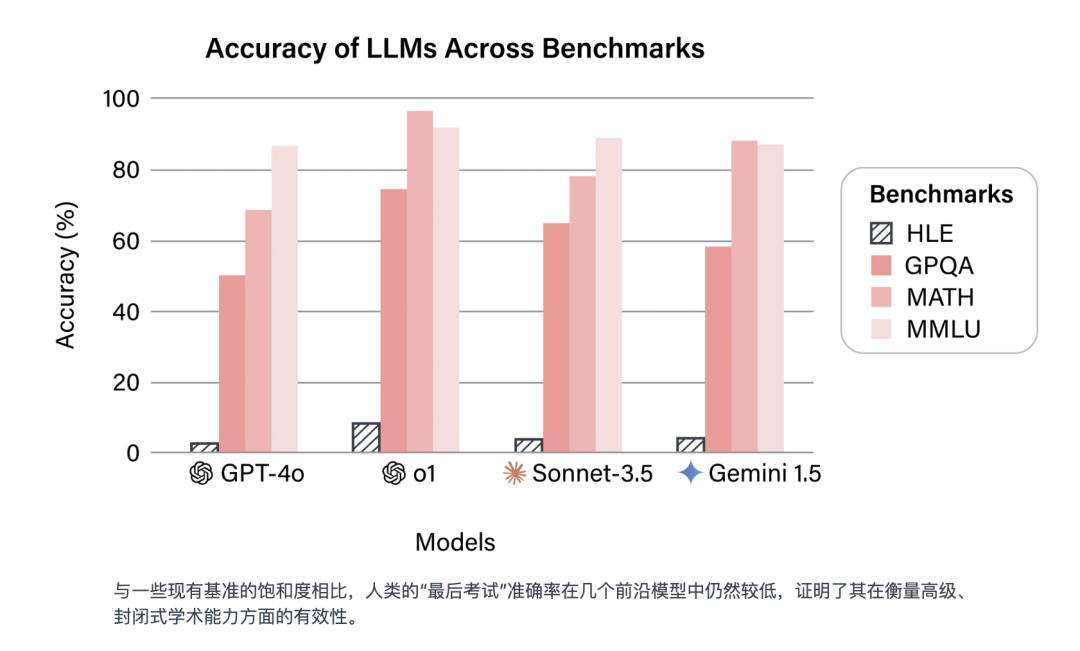
截止到今年一月论文发表时的数据,黑色柱形是HLE的准确率|HLE官网
这些题为什么这么难?
有一个原因是它们需要一定的推理深度,而且没法在网上找到答案,还有一个原因是问题已经经过了筛选,留下的全部是现有的前沿模型表现差的问题。
还有一个原因是在问题上给AI挖了坑。
比如上文提过的蜂鸟籽骨问题,看似简单,但是有人测试了ChatGPT5和Gemini,它们都给出了一篇论文似的长篇大论,而忽略了问题的最后一句话,“Answer with a number”,请直接用数字回答。
因此,所有不是“2”的答案都被算作是错的(尽管有些模型在长篇大论之后给出了正确答案),这可能是一个产品设计问题,而不是AI表现问题。

Threads@raystormfang
另外,有些问题连人类自己都还没达成一致呢。
最后的考试,可能也撑不了多久
最后的考试赏金很诱人,概念很科幻,目的很崇高,但是它带来的争议已经开始浮现。
今年7月,专注人工智能应用的非营利组织FutureHouse发布了一篇调查报告,称HLE里“化学生物领域的30%的答案可能是错的”。
他们组建了一个化学生物领域的专家评审团,并且详细研究了HLE题库,最终得出结论,“29±3.7%(95%置信区间)的纯文本化学和生物问题的答案与同行评审文献中的证据直接冲突”。
比如这个问题:截至 2002 年,在地球物质总量中所占比例最少的稀有气体是哪一种(What was the rarest noble gas on Earth as a percentage of all terrestrial matter in 2002)?
你不知道,我不知道,AI也不知道,答案是Oganesson。

Oganesson,或者叫鿫,化学符号Og,原子序数118,是一种人工合成的放射性超重元素,位于元素周期表第七周期、稀有气体族(0族)的末端。2002年,鿫在俄罗斯的一座核反应堆中首次被合成并存在了几毫秒,迄今为止,只有五个Oganesson原子被合成。而且它更可能是固体或液体,而不是气体,还有一些学者认为它不是惰性气体,因为它的化学性质并不稳定。此外,还有多篇论文(包括2002年的论文)列出了地球上稀有气体的比例,而鿫没被算进去——总而言之,鿫可能不是气体,也可能不是惰性气体,而且大多数同行评议的论文觉得它也不是地球物质。
而AI答不答得出脑筋急转弯问题又能证明什么?
还有另外一个迷思,对大多数前沿模型来说,HLE都太难了。大家得分都很低,和大家得分都很高的状况是一样的,还是没拉开区分度,也没想明白得分高的模型好在哪。而且HLE覆盖的是学术考试可测内容——它专注于已知的学术题目和闭合答案,对开放式创造力、生成类问题或非常新颖的研究课题的思考仍然难以评估。
虽然千辛万苦花大价钱出了这么一套题,看来也要很快被打穿了。
HLE自己预测,虽然目前的AI在HLE上的准确率非常低,但到2025年底,模型在HLE上的准确率就有望超过50%。事实上,还没到年底,Grok4在使用工具的情况下(比如代码解释器)正确率已经升到了41.0%。
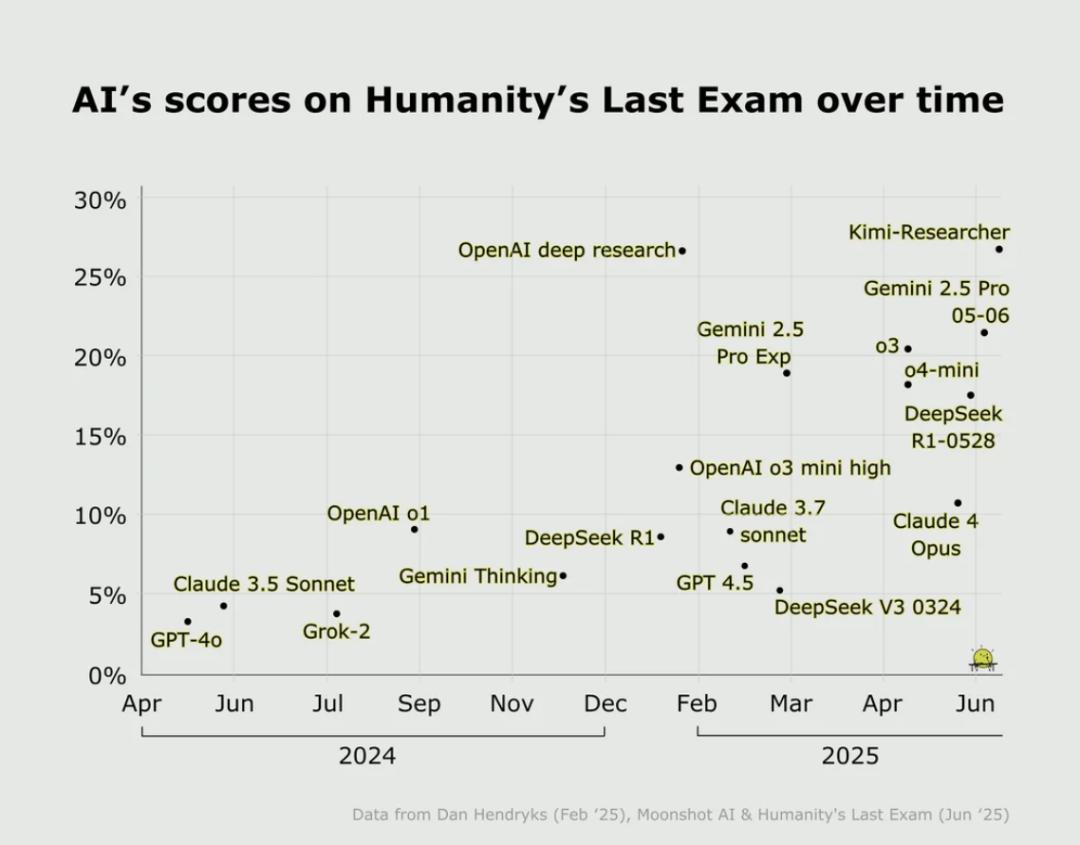
亨德里克斯说,HLE或许是我们需要对模型进行的最后一次学术考试,但它远非人工智能的最后一个基准。等HLE又被超越,我们还有什么题出给AI呢?


