
在GPT-5发布之前,Information曾报道称,GPT-5的性能提升主要来自其研发出的“通用验证器”(Universal Verifier)。
虽然GPT-5后续的能力升级不及预期,但通用验证器却已经成了大模型的下一个“圣杯”,近期内成了AI圈内最近最热的话题之一。
为什么它这么关键?
这主要是因为上一波模型能力提升所倚仗的技术是“可验证奖励强化学习”(Reinforcement learning with verifiable rewards, RLVR)。简单说,就是先从数学、编程这类有标准答案的问题入手:答对加分,答错扣分,训练效果立竿见影。
但现实世界远比“对”与“错”复杂。比如医疗、教育、创意领域,很多问题根本没有唯一解答,一个“好”的答案可能既要专业可靠,又要体现沟通和共情。RLVR在这些场景下就显得力不从心,甚至让模型在开放性问题上退步。
要让模型进一步进化,就必须突破“对/错”奖励的限制,让AI能像专家一样在不同领域评估优劣,并将海量非结构化经验数据转化为有效的学习信号。通用验证器正是为此而生,它被认为可能引发强化学习的下一次范式革新。
今天,就用一篇文章了解当下大语言模型界最重要难题的核心解题思路,在这之中可能蕴含着强化学习的下一次范式革新。
这篇文章很长,约8000字,但理解了“通用验证器”,你才能真正看懂GPT-5以及之后AI技术竞赛的赛点所在。请给这篇文章一些耐心。
第一条路:让模型作为裁判,但标准更复杂
第一条路的逻辑极其简单,既然是通用的判断器,那干脆让已经有通用判断能力的大模型来做这个验证器得了。
这个想法其实由来已久,“LLM-as-a-Judge”的概念,早在24年初即已存在。
在近期强化学习范式转型之前,它就被视为一种评估AI能力的客观工具。
然而,在当时,它提供了有价值的第三方视角,却并未真正走进训练场,与作为核心驱动力的奖励模型(Reward Model)机制挂钩。它能判断对错,但其判断结果并未直接转化为驱动模型迭代优化的实时反馈信号。
但这种联系很快就被发现了。在2024年8月,DeepMind的论文《生成式验证器》首次尝试将语言模型直接训练成强化学习用的验证器。

在当时,GenRM的用武之地主要集中在逻辑性强、步骤分明的领域,如数学和算法推理。其最强大的版本GenRM-CoT,通过生成“思维链”(Chain-of-Thought)来剖析一个解决方案,其核心优势在于能精准识别计算过程中的步骤性错误。
然而,随着o1和RLVR的兴起,GenRM的锋芒似乎被暂时掩盖了。在数学、编程这类拥有确定性答案的领域,训练数据本身就蕴含了最可靠的“验证”信息—在这种背景下,再构建一个像GenRM这样复杂的、需要自我推理的验证器,显得有些“画蛇添足”。因此,这一路径一度陷入沉寂。
然而,当面对RLVR失效之处,即更广阔、更主观的开放领域(如创意写作、复杂对话、人文分析),GenRM这条路径又一次被重视起来。
后面的几篇论文,基本都是沿着这一路径,针对开放领域的复杂性进行的深化与加强。这可以说是目前建构“通用验证器”最主流的流派了。
1、既然对大多数事情评价复杂,那我们的验证标准也复杂些
既然大多数领域并不像编程和数学一样有确定解,那我们就干脆构建一个多维度的、类似清单的“评分细则”(Rubric),将一个高质量回答所需具备的各项要素进行拆解。用这个评分细则来作为奖励的通用验证器。
ScaleAI在7月23日发表的论文《作为奖励的评分细则》(Rubrics as Rewards)的论文,系统性地展示了这一方向的研究进展。

这篇研究提出的RaR框架,给出了为AI构建了一个结构化的、多维度的“价值体系”的具体操作方法。
其核心逻辑可以分为三步:专家立法、模型释法、AI执法。
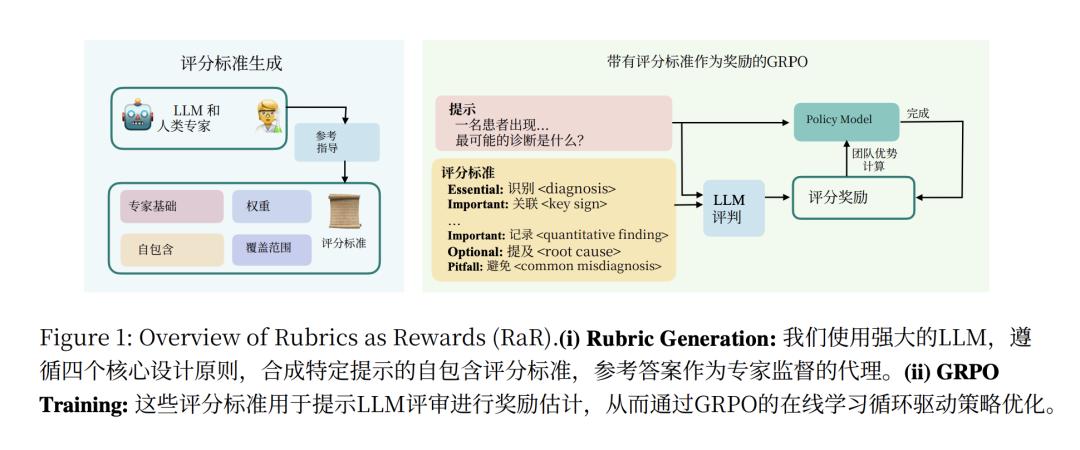
一个好的回答应该具备哪些维度?这个问题不能由模型自己凭空想象。
RaR框架的第一步,是由人类专家和大语言模型一起为特定领域(如医学、科学)定义一个评估的“元框架”。
例如,在医学领域,人类专家在框架中提到:“评分细则可以涵盖诸如事实正确性、理想回答的特征、风格、完整性、帮助性、无害性、以患者为中心、推理深度、情境相关性和同理心等方面”。
专家还预先定义了重要性等级,要求模型必须使用“必要标准 (Essential Criteria)”、“重要标准 (Important Criteria)”、“可选标准 (Optional Criteria)”或“陷阱标准 (Pitfall Criteria)”这些分类。

但之所以过去模型选择RLVR,就是因为奖励标准非常明确,容易很好的去用巨量的问题放大效果。而在RaR中,如果每个问题都需要专家来写评分细则,那将极难扩展。所以RaR给出了一个解决方法,虽然元规则是人类专家写的,但具体的评价体系,则是利用模型来Scaleup。
在这个阶段,一个强大的模型会接收专家定下的“元框架”,并结合一个具体的“案例”(即问题和一份专家参考答案),然后自动生成一套详细、可操作的 7到20个评分项的清单。
每个项被分配一个类别权重以确定其对正确答案的重要性。比如,针对“如何诊断肾结石”这个问题,它会自动生成“必要标准:指出非对比螺旋CT的敏感性”这样的具体条款。
这一步是实现扩展性的关键,它将专家“写一份范文”的精力,杠杆化为成千上万条可用于自动化评估不同场景的不同标准。
有了这套详细的“法律条文”(评分细则),训练过程就进入了强化学习(RL)循环。那个需要学习的“学生模型”(Qwen2.5-7B)会采用类似GPRO的方法,针对问题,探索性地生成多个不同的答案。
而另一个“裁判模型”(LLM Judge,GPT-4o-mini )会严格依据评分细则,为“学生AI”的每一个答案打一个精确的分数。
“学生AI”最终根据这个密集、清晰的反馈分数,不断优化自己的生成策略,学习如何才能写出持续获得高分的答案。
用这种RaR框架训练后的模型,确实在性能上取得了显著成功,在医学领域,经过RaR方法训练后,Qwen2.5-7B的性相较于原始的Qwen2.5-7b基础模型,其得分从 0.0818 飙升至 0.3194。性能几乎提升了近四倍。相较于更强的指令微调基线Qwen2.5-7b-Instruct,其得分也从 0.2359 提升至 0.3194 ,也获得了约 35% 的相对性能提升。
作者还比较了此种方法相对于另外一些LLM as Judge(模型作为裁判)的通用方法带来的提升。
比如在HealthBench-1k医疗基准测试中,相较于简单直接由模型判断答案在1-10分的方法(Simple-Liker题),RaR取得了高达28%的相对性能提升。RaR的表现能够匹敌甚至超越使用专家对单个问题撰写参考答案,然后由模型对着参考答案打分的方法(Reference-Likert)。这种方法属于完全无法扩展的方法,RaR优势明显。
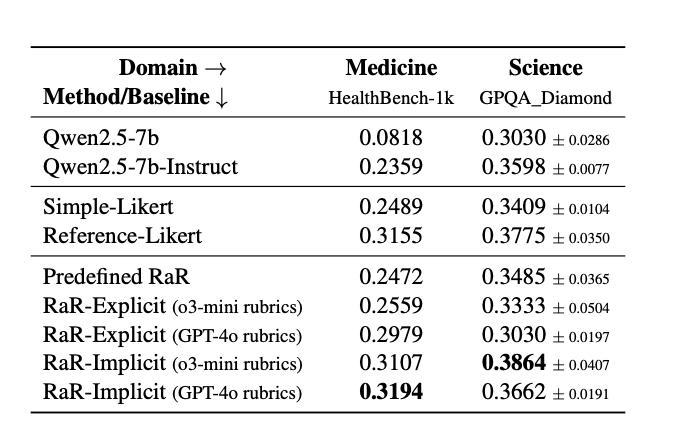
相较于更基础的利用专家答案微调(SFT)的方法,RaR性能也能达到30%以上的领先水平。
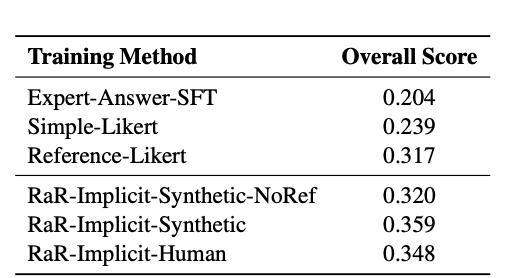
以上这些结果表明,通过结构化评分细则RaR,模型确实能够获得更精确的奖励信号,从而在复杂的推理任务中表现更佳。
这一方法作为通用验证方法的唯一问题,可能还是每个领域都需要专家来撰写针对这个领域的元评价框架,因此在没有完成前,还很难说“通用”。但至少,这一扩展领域验证的方法是通用的。它提供了一个“如何去填满所有领域”的、可扩展的、高效的蓝图和工具箱。
2、Rubicon,消灭强化学习跷跷板,让通用没有短板
在这篇论文之后,8月18日,蚂蚁集团联合浙江大学也发布了一篇方向一致,但更进一步的基于“评分细则”(Rubric)的强化学习论文。

虽然基础细则框架和逻辑与RaR系统相似,但Rubicon的研究人员在这里构建了一个包含超过10,000个评分标准的大型系统,要全面提升模型在人文、创意、社交和通用对话等主观领域的表现。他们训练 Qwen-30B-A3B 的模型,仅使用了5000多个训练样本,就在各种开放式基准测试中(尤其是在以人文为中心的任务上)实现了5.2%的绝对提升,甚至比体量大得多的 671B DeepSeek-V3 模型分数还高出2.4%。
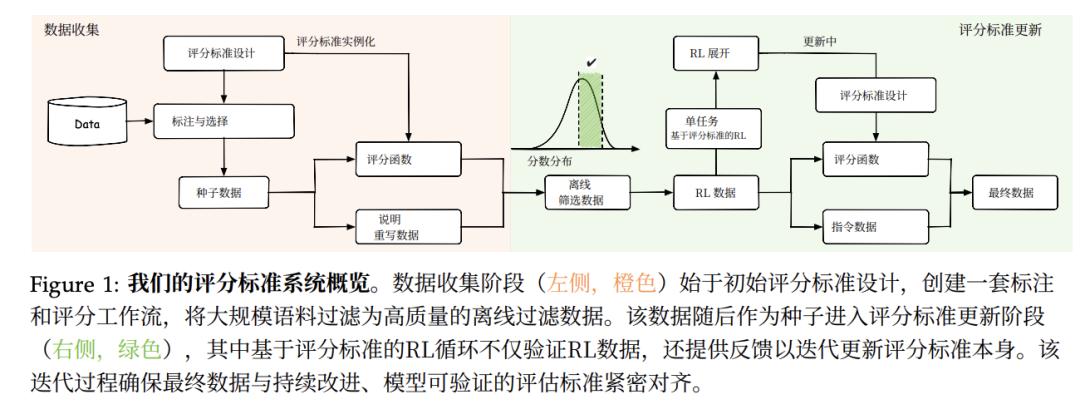
这样的成绩来自于团队对“评分细则”训练方法的一系列升级。
首先是“评分细则”本身的升级。Rubicon 的奖励框架比RaR的单一总体评分更精细,可以有效过滤掉可能有问题的范例,并提升模型持续强化学习的可能。
否决机制就是一个硬性过滤机制,当在模型在一个关键维度上失败(如触发了“奖励黑客行为”的规则),就可以直接否决所有其他维度的奖励。
饱和度感知聚合则是为了让模型持续学习,而不止步的方法。模型在单一维度上得了超高分,那就进行边际效用递减处理,鼓励模型全面发展,而不是在某个方面“刷分”。除此之外,Rubicon还会通过非线性函数放大高分区间的得分差异,为模型在“优中选优”的阶段提供更精细的优化梯度。
除了细化“评分细则”本身,Rubicon的团队还试着解决了强化学习在全面发展时面对的最大问题——“跷跷板效应 (Seesaw Effect)”。
过去RL的经验告诉我们,用一次强化学习,项同时训练模型掌握多种不同甚至相互冲突的技能时,模型性能就像跷跷板一样,一种能力升高了,另一种能力则必然下降。
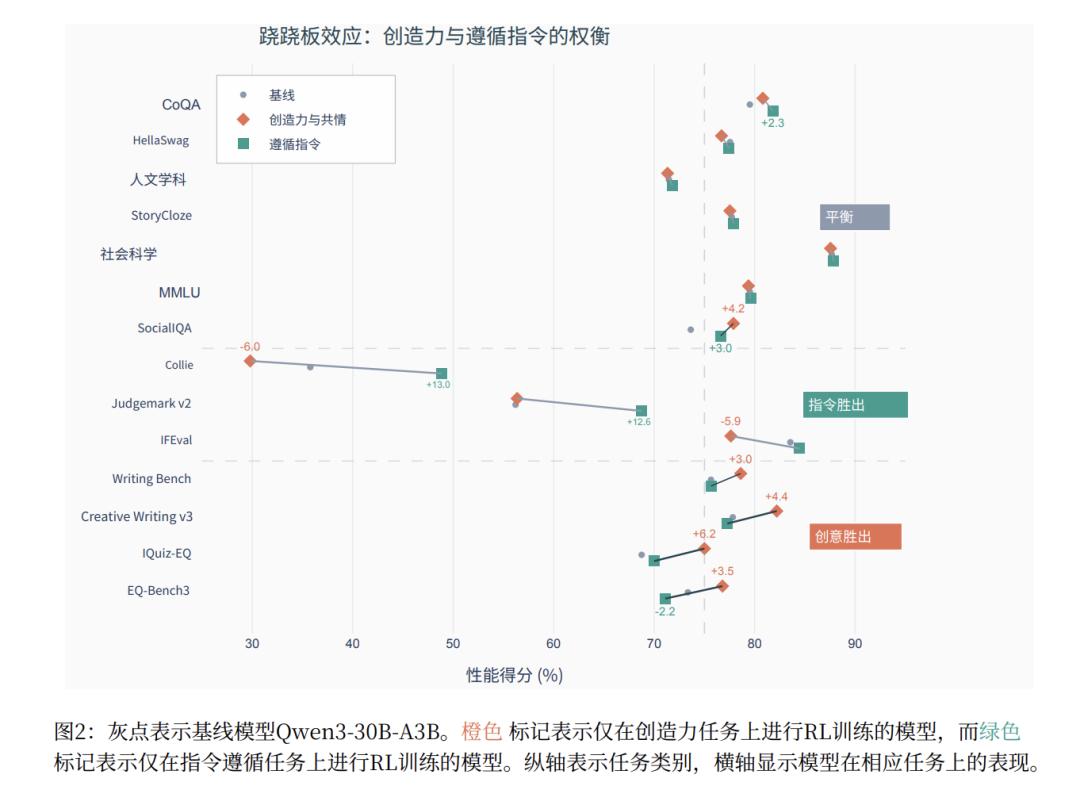
所以,将所有领域的评分标准混合在一起进行训练,根本实现不了全面提升。这样的话,即使有“通用验证器”,模型的能力也无法通用的提升。
为了解决这个问题,他们设计了一个分阶段的强化学习流程。在第一阶段专注于打好基础,使用可验证的检查。(如是否遵循了特定的输出格式(如JSON)、长度是否在规定范围内)和静态评分标准(通用性较强的评价标准,比如逻辑清晰度、信息完整性),训练模型可靠地遵循指令。这意味着它在面对后续更复杂的任务时,不会轻易“跑偏”。
而在第二阶段,才使用扩展到针对具体领域和问题的“评分细则”进行训练。通过两步训练法,模型在创造力相关的等七个开放式基准上的平均性能提升了5.21%。也避免了对通用能力的负面干扰。甚至在一些推理基准上还获得了额外收益,如 AIME 2024,提升了近4.1%。
这可以说是这篇论文最大的一个贡献。只有治好了跷跷板效应,模型才有可能真的在多样规则的强化学习中逐步提升其全面能力,真正做到通用。
Rubicon这个方法中还有一个非常值得注意的点,它用这套方法治好了AI模型回答总是“AI味儿”太浓的问题。针对语言风格,Rubicon的团队给出了一套“风格评分标准”。

在这一套标准之下,训练出的模型就可以在回答“你生命中最有活力的时刻是什么?”这个问题时,比起原始回答“作为一个人工智能,我没有人类那样的情感或个人时刻,但我可以帮助你探讨这个问题……这些时刻通常涉及……你有哪些记忆让你印象深刻?” ,Rubicon的回答明显“人味儿”更足。

3、比起复杂化标准,不如直接加强裁判
前面两篇论文,都是通过细化原来不那么好验证领域的标准,把原来对或错的二元评价体系,拓展成好或坏的多元评价体系。是在如何塑造奖励上下功夫。
而发表于6月18日的阿里夸克团队的论文Writing-Zero则是选择在裁判模型上下功夫。通过让裁判模型变得更擅长评价那些对错不明确的问题,并给他们打出足够有区分度的分数。

这一新方法的核心,是构建一个名为“成对生成式奖励模型”(Pairwise Generative Reward Model, GenRM)的AI裁判。
传统的奖励模型都是直接输出一个分数,这使得AI很容易找到捷径“刷分”,这个一般被称为Rewardhacking。在写作上,模型最喜欢找的捷径就是答得长和自吹自擂。
“Writing-Zero”的AI裁判则完全不同。在给出最终分数前,它被强制要求先生成一段详细的、基于原则的“批判性分析”。
它必须结合通用的写作标准(如相关性、有用性)和针对当前任务动态生成的特定标准(如创意写作中的“主题理解”、“论点阐述”),来论证其判断的合理性。这一模型经过了前期微调和后期强化训练,让它的输出判断是否与人类偏好一致,格式正确,且能区分出足够细微的分数差异,不让模型评分过于集中后,即可上岗。
这种“先批判,后打分”的机制,让AI裁判不得不进行更深度的思考,而且也不是那种传统COT的特别死板的逻辑思考。而它最终给出的分数也不是传统LLM as Judge经常给出的一锤定音的模糊印象分,而是具有高度区分度和可靠性的评估结果。
在训练AI学生的方法上,夸克的团队也选择了GPRO的类似方法。但因为GPRO里,模型给出的答案是可以直接判断对错的。但在写作这种开放性任务里,你没法直接给对错,所以研究人员对GPRO稍加更改,发明了“引导相对策略优化”(BRPO)算法。
在每一轮训练中,学生模型会针对一个问题生成一组不同的回答。BRPO会从这一组回答中随机抽取一个作为临时的“参考答案”。然后,使用前面训练好的裁判模型GenRM,将组内的其他所有回答与这个临时参考答案进行成对比较,得出一个偏好信号(+1代表更好,-1代表更差),作为奖励函数,用于更新学生模型。
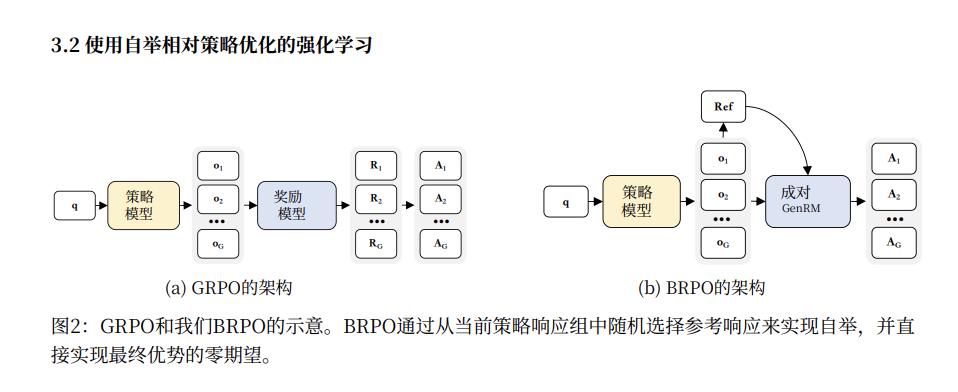
实验结果印证了这一逻辑的有效性。通过这种方式训练出的“Writing-Zero”模型,在更能反映真实写作能力的内部测试集和人工评估中,“Writing-Zero”的表现均显著胜出。
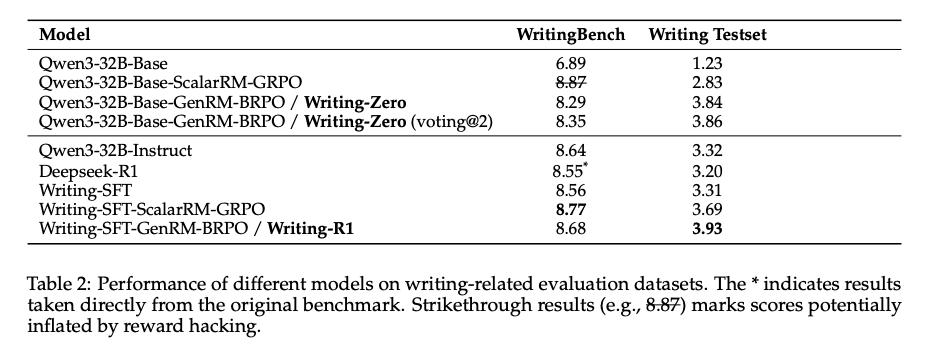
以上这条路,属于是向前看学术界之前的方法,把它用回在新环境里。属于一个延展性思维。后面的那条路,就多少有点“离经叛道”了。
第二条路:相信模型自己的力量,让它自评
除了LLMasJudge这个“标准”解法外,还有一种路径也在学术界近期获得了较多的实践。这个路径就是不要任何外部的验证器,让模型自己去判断自己给的答案哪个更好。
初见时会觉得这个路子有点邪,但它居然真的有效。
1、靠模型自己知道的答案,来训练模型
涉及这一方法的有两篇发布于今年5月的论文。第一篇是SEALab的《无验证器强化通用推理》。它的逻辑也很简单,就是与其相信外部验证器,不如直接用模型自身对答案的“自信度”来设定奖励。

这个流程也很简单,对于给定的一个问题,模型先只生成推理过程(即“思考过程”或“Chain of Thought”)。然后将数据集里的“标准答案”贴在后面,最后看看模型基于自己的思路能多大概率说出这个标准答案。
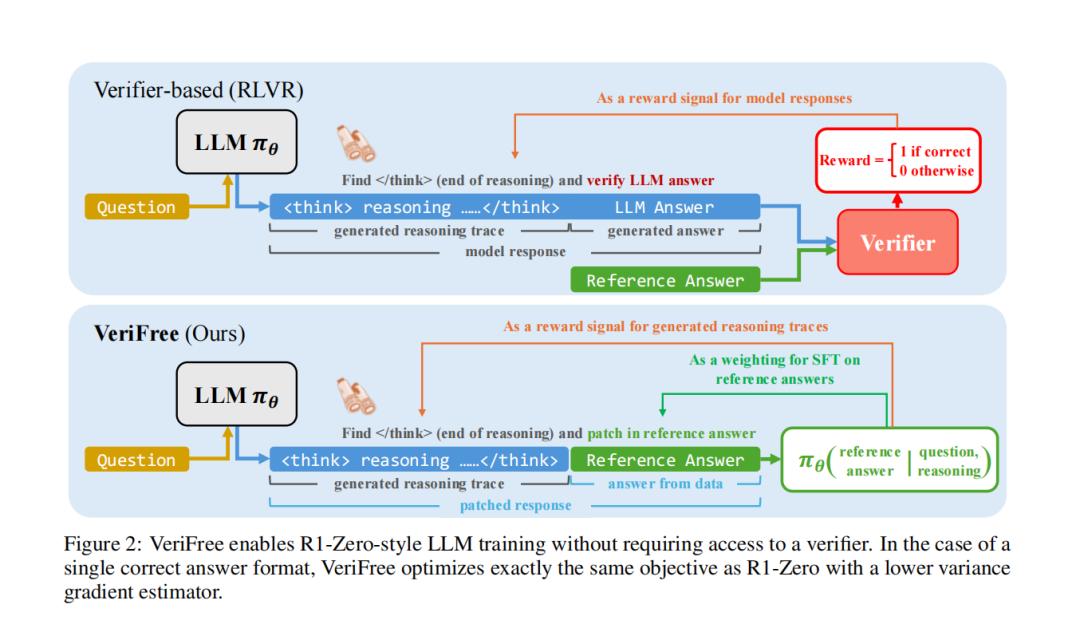
(原始的验证器Verifier被模型自己算出来的“自信度”得分取代)
最终,这个模型自己得出来的“预判正确率”被直接用作奖励信号。在这个过程中,模型自己其实能判断,如果它生成的推理过程质量高、逻辑通顺,那肯定更有可能得到正确的答案。因此这种推理过程也就会得一个较高的奖励。反之,如果推理过程混乱或错误,那么它引出正确答案的概率就会很低,奖励也相应较低。

从结构上讲,它和谷歌DeepMind的GenRM-CoT基本完全一样,但VeriFree将一个需要外部判断的奖励问题,转化为了一个模型内部评估的奖励问题。让模型自己验证自己。
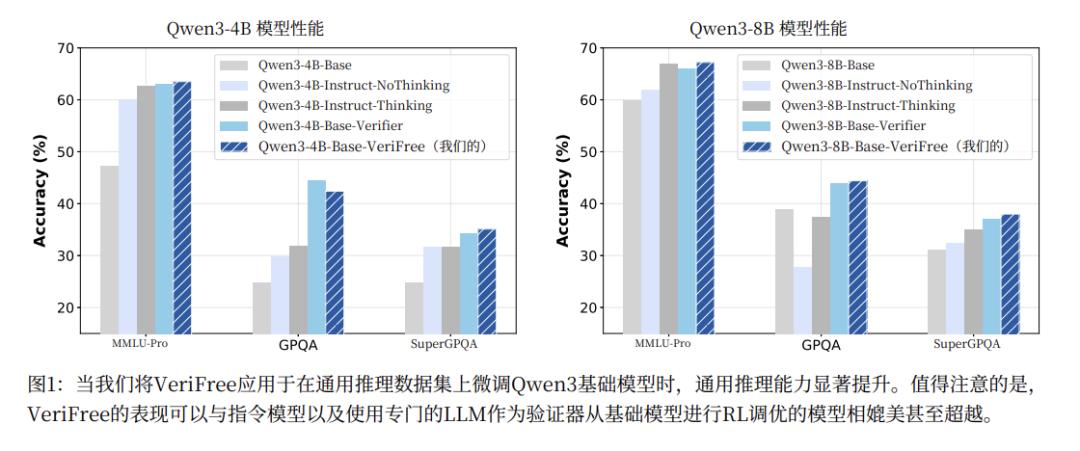
这种看起来不太牢靠的方法,其效果却相当不错。在Qwen3-8B模型上进行测试,无额外验证器的方法最终得分和用传统强化学习,有外部验证的方法相当,很多方面甚至都超越了外部验证器版本。
但VeriFree 的方法也有一个致命的短板。虽然它比起要么对、要么错的RLVR体系,评分更细腻,也可以应用在数学和编程之外。但它的有效性仍然高度依赖于在训练数据里存在一个明确、唯一的“标准答案”(Ground Truth)。
这让它的Universal(通用性)其实没那么高。如果没有唯一的标准答案,就无法计算“生成该答案的概率”,整个奖励机制就失效了。
VeriFree 的论文也意识到了这个问题,并在附录中讨论了“等价问题”(Equivalence Class)的影响。比如标准答案是“8/5”,那么“1.6”或“1又3/5”也应该算对。但 VeriFree 的基础形式只认8/5。
2、连外部答案也一起放弃,自由心证
另一篇也是在5月发表UCBerkeley的论文所讲述的方法和VeriFree很近似,但它向着彻底相信模型本身的能力又进了一大步。因此也摆脱了VeriFree的一些固有限制。

这一方法被研究人员称为INTUITOR。在之前的研究中,研究人员发现LLM 在处理难题或缺乏相关知识时,其输出的自信度会降低。我们最熟知的困惑度(Perplexity)就是描述模型的自信程度的。因此,UCBerkley的团队就想到,是不是可以反过来,通过奖励和优化那些能让模型产生更高自信度的输出,就可以反过来提升其推理能力。INTUITOR就是在这一思路中诞生的。
因为过去的自信度指标如困惑度或熵(Entropy)有时会偏爱生成更长、更啰嗦的文本。所以研究团队设计了一种新的自信度值:自确定性。它是模型在生成每个词(token)时,其“下一个词的概率分布”(预测词汇表里所有词在下一步出现的概率)与“均匀分布”(就是全随机的猜测)之间的平均KL散度(两个概率分布之间差异)。
它的奖励信号是通过计算整个生成过程中每一个词(token)的自信度,然后取平均值得到的。所以它更容易奖励连贯、自信的推理步骤,更注重过程而非单纯的结果。同时,基于KL散度的方法会鼓励模型“覆盖所有合理的路径”,同时会强烈激励模型“找出并坚定地走上那条最可能的路”。
然后将现有 RLVR 框架(特别是 GPRO 算法)中的外部奖励信号替换为自确定性分数进行强化学习,就可以得到一个完全由内生奖励引导强化过的模型了。
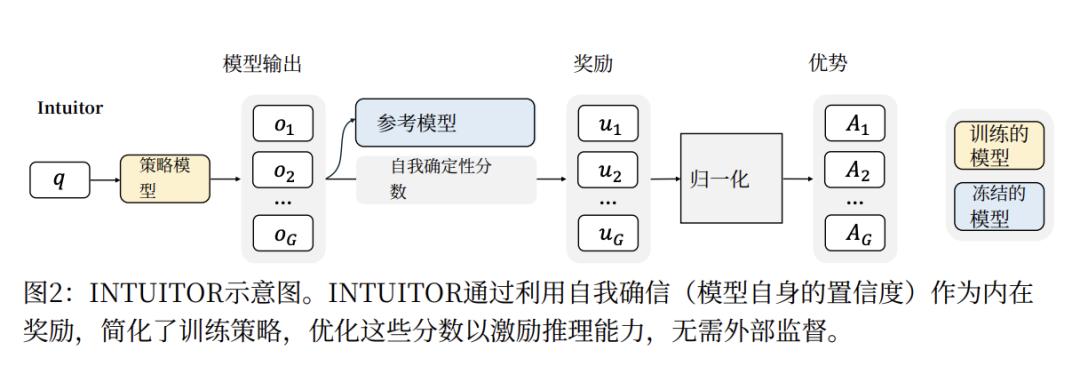
他们称这种方法为RLIF框架。过去RLHF是从从人类反馈中强化学习,现在我们可以抛弃昂贵的人类标注,直接从模型内部反馈中强化学习(Reinforcement Learning from Internal Feedback)。
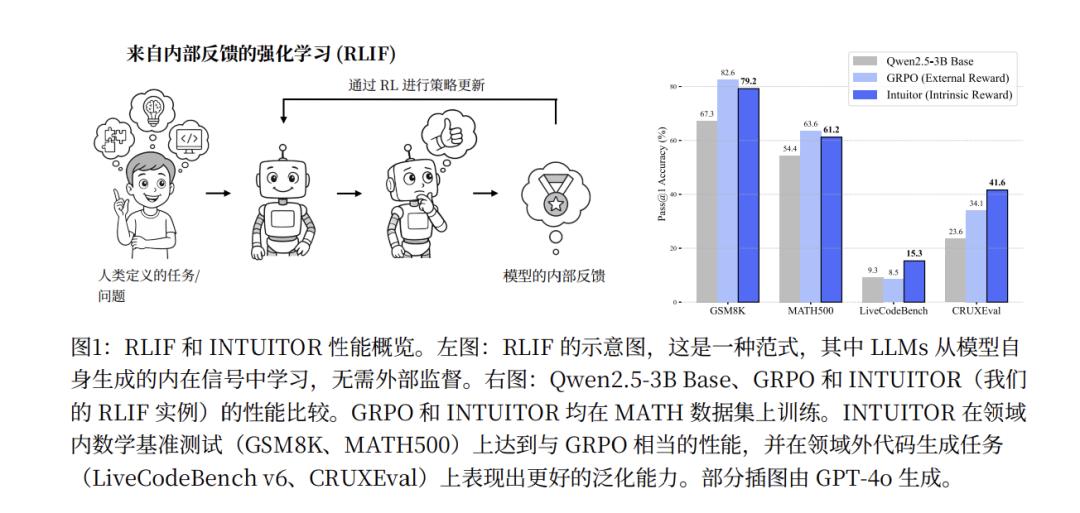
与前面提到的Verifree需要标准答案不同,INTUITOR 是 无监督的 (Unsupervised)。它完全不需要标准答案或任何形式的标签。只需要一个问题列表(例如,MATH数据集中的训练问题),模型就可以通过自我评估和比较来进行学习。
结果也是非常惊人的。在模型进行训练的数学推理上,INTUITOR 的表现几乎可以和那些使用“标准答案”作为奖励的传统监督方法(如 GPRO)相媲美。同样是用Qwen2.5-3B 模型训练,INTUITOR 在 MATH500 测试集上达到了 61.2% 的准确率,非常接近使用标准答案的 GPRO 的 63.6%。但可惜的是,至少在数学领域,它并没有超越RLVR的极限。
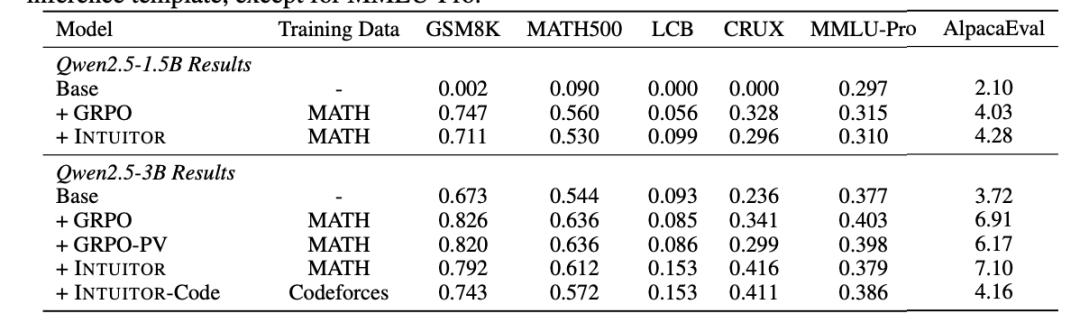
而且,这些能力和RLVR用的GPRO训练方法不同,INTUITOR训练出来的模型具有“通用推理能力”,可以在新领域泛化其能力。论文提到,在 MATH 数据集上训练 Qwen2.5-3B 模型后,INTUITOR 在 LiveCodeBench(代码任务)上实现了 65% 的相对性能提升,而 GPRO 则没有提升。
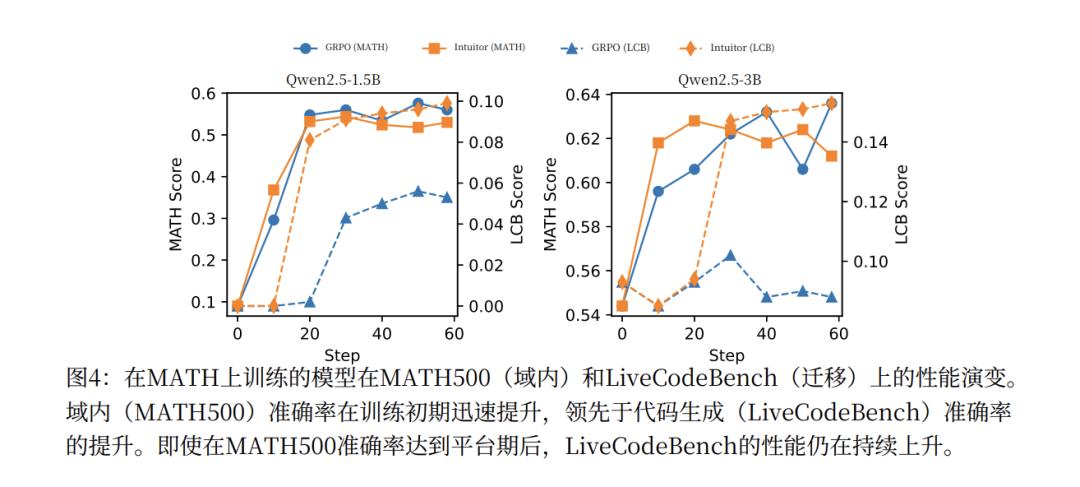
同时,INTUITOR 还能够促使模型自发地生成更长、更结构化的推理过程。并显著提升模型的指令遵循能力。
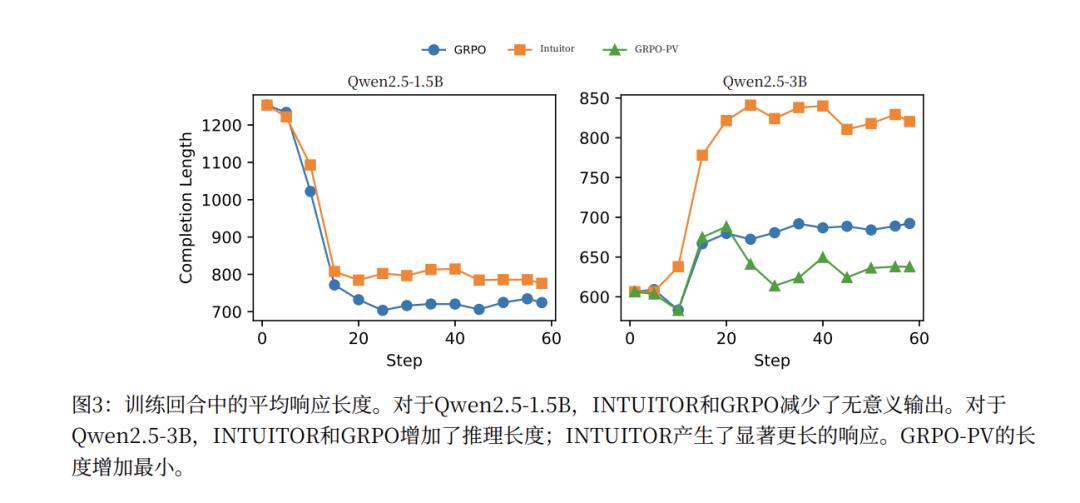
这个结果相当具有颠覆性。原来我们以为是需要教给模型如何思考,它才会思考。其实它也许只需要信自己就行。
3、为什么这条路能有效?
这条看起来非常奇怪的道路,实际上正是当前对强化学习思考的一种正常延伸。
在过去相当长的一段时间内,强化学习是否能带来推理能力引发了诸多讨论。在多篇论文的累积下,学界逐渐形成了一种共识,即RL更多的只是在做一个搜索剪枝的功能,让采样更有效率,其输出的正确答案,并未超越预训练模型本身的能力。

因此,也许基础模型的潜能并不只在于推理,而也在于其他地方。设定奖励,自我信息搜索这些领域是否也可以通过强化学习加以牵引呢?挖掘出预训练模型的潜力来呢?
在这个逻辑之下,很多相应的研究都诞生了。比如说近期清华的SSRL,就是不通过外界搜索,而是通过强化学习让模型学会在虚拟环境中搜索自己已有的知识,其准确度居然也可以和接入外部搜索的Agent相提并论。

所以,这第二条路,就是强化学习的心学。内观万物。
行至中途的“通用验证器”,与通往终局的OaK愿景
从上文中,我们可以看到“通用验证器”的探索正沿着两条看似前景光明的道路行进。
然而,深入审视其核心机制,它们可能都存在着根本性瓶颈,只能算是行至中途。
第一条路,以RaR和Rubicon为代表的“立法式验证”,其根本局限在于“手动搭建的脚手架”。 这条路径试图通过引入专家知识,为AI在每一个复杂领域构建精巧的“评分细则”。这在特定领域内取得了显著成功,但它的本质决定了其难以真正扩展到“全体”。每进入一个新领域,都得预先搭建一套脚手架因此,它或许永远无法实现对无限复杂世界的全域覆盖。
第二条路,以INTUITOR为代表的“内观式验证”,其边界则在于“无法超越预训练的知识”。 这条路径极具创造性地让模型向内寻求奖励信号,通过“自信度”等指标进行自我优化。这极大地降低了对外部标注的依赖,但也将模型的认知锁定在了其预训练知识的“囚笼”之内。一个模型无法通过自我审视来验证一个它从未见过的外部事实,也无法凭空创造出超越其数据边界的全新知识。因此,它也只能被看作是通往通用道路上的一个阶段。
那终局的,真正的UniversalVerifier可能在哪里呢?
强化学习之父Richard Sutton近期提出的OaK架构,为我们描绘了一种更远期的蓝图。
OaK的核心是一种完全基于“运行时经验”的智能,它摒弃了所有设计时注入的知识,致力于让智能体在与世界的互动中,从零开始自主构建其认知世界的抽象。
OaK架构的精髓,就是设计一套机制,让验证器能够从智能体与环境的持续互动中自主涌现、自我完善并无限成长。
在OaK架构中,“验证”不再是一个独立的模块或步骤,而是融入了整个系统的生命循环。这一循环包括8个步骤,
学习主策略:首先,AI 学习如何最大化最终奖励(任何奖励),这是最基本的强化学习任务。
生成新特征:AI 不断地从环境中发现和创造新的“状态特征”,也就是新的概念或看世界的新角度。
特征排序:对新发现的特征进行排序,判断哪些是重要的、有用的。
构建子问题:基于那些重要的特征,创建新的“辅助子问题”(例如,尝试去达成某个特征)。
为子问题学习解法:为每个子问题学习一个解决方案,这个方案就是“选项 (Option)”。
学习知识模型:为每个“选项”学习一个模型,预测执行这个选项会带来的各种后果。这就是“知识 (Knowledge)”。
执行规划:利用学到的“知识”,在更高、更抽象的层面上进行思考和规划,从而改进整体策略。
维护元数据:持续跟踪和评估系统中所有元素(比如特征、模型)的有效性,为后续的学习提供指导。
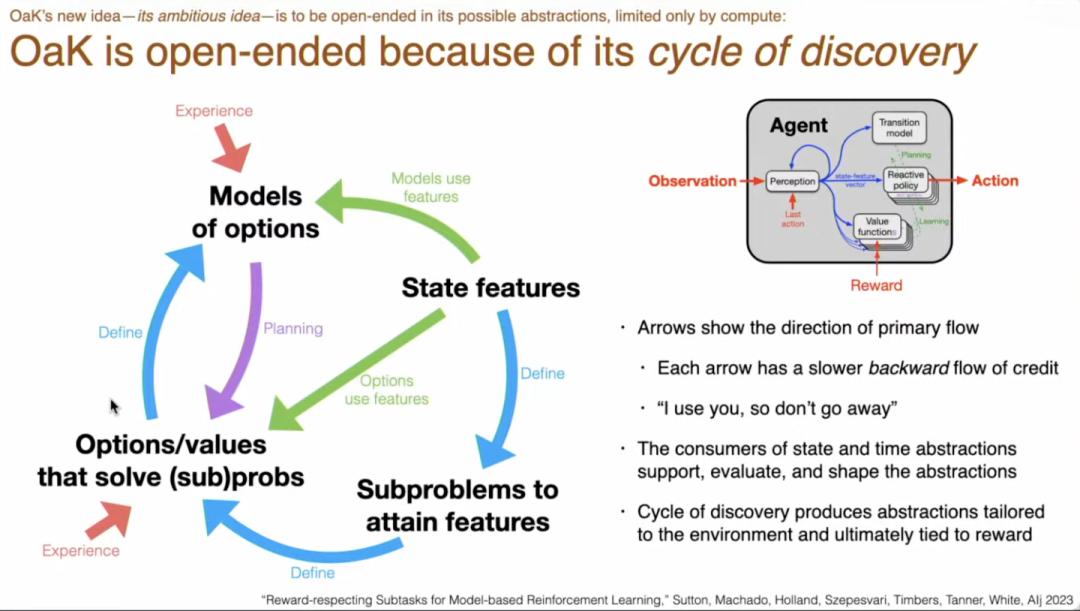
完成这个循环后,我们就可以得到一个简单、通用、完全基于经验的 AI 智能体架构。
但目前OaK架构还面对着很多难解的问题,其中最重要的是目前LLM还不具有主动学习、持续反思更新的能力。因此OaK这个终极目标看起来还很遥远。
但我们在当前这两条“中途”路径中,已经能清晰地看到其核心组件的早期雏形。
RaR/Rubicon中的“评分细则”,可以被看作是OaK架构中“子问题(Subproblems)”的一个手动指定、外部化的版本。前者需要人类专家来定义“什么是好”,而后者则由智能体为了最大化长期奖励而自主发现“什么值得去做”。
INTUITOR中的“内部自信度”,则可以被理解为OaK架构中“价值函数(Value Function)”的一种极其简化和静态的代理。前者是一种固定的内在指标,而后者则是一个复杂的、动态的、被真实世界反馈(Reward)持续校准的验证系统。
由此可见,当前对“通用验证器”的探索,即便其自身可能无法走完全程,却并非徒劳。它们正在为未来那个更宏大的架构,提前打造和测试着至关重要的零部件。
所有这些宝贵的经验,都将是构建未来那个能自主学习、自我验证的通用智能体的基石。
(本文作者微信haoboyang001,欢迎交流及提供线索)


